Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/jferard/csvinspector
A graphical interactive tool to inspect and process CSV files
https://github.com/jferard/csvinspector
Last synced: 1 day ago
JSON representation
A graphical interactive tool to inspect and process CSV files
- Host: GitHub
- URL: https://github.com/jferard/csvinspector
- Owner: jferard
- License: gpl-3.0
- Created: 2020-02-26T22:48:26.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2023-06-18T08:47:13.000Z (over 1 year ago)
- Last Synced: 2023-06-18T15:50:19.684Z (over 1 year ago)
- Language: Kotlin
- Size: 539 KB
- Stars: 0
- Watchers: 2
- Forks: 1
- Open Issues: 7
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
CSVInspector - A graphical interactive tool to inspect and process CSV files.
Copyright (C) 2020 J. Férard
License: GPLv3
# Quick start
CSVInspector needs JRE8 (with embedded JavaFX) or JRE11 and Python 3.8:
$ mvn clean install
$ PYTHONPATH=lang/python:$PYTHONPATH /path/to/jre8/java -jar target/csv_inspector-0.0.1-SNAPSHOT.jar
Code samples are in the menu Help > Snippets.
# What it looks like
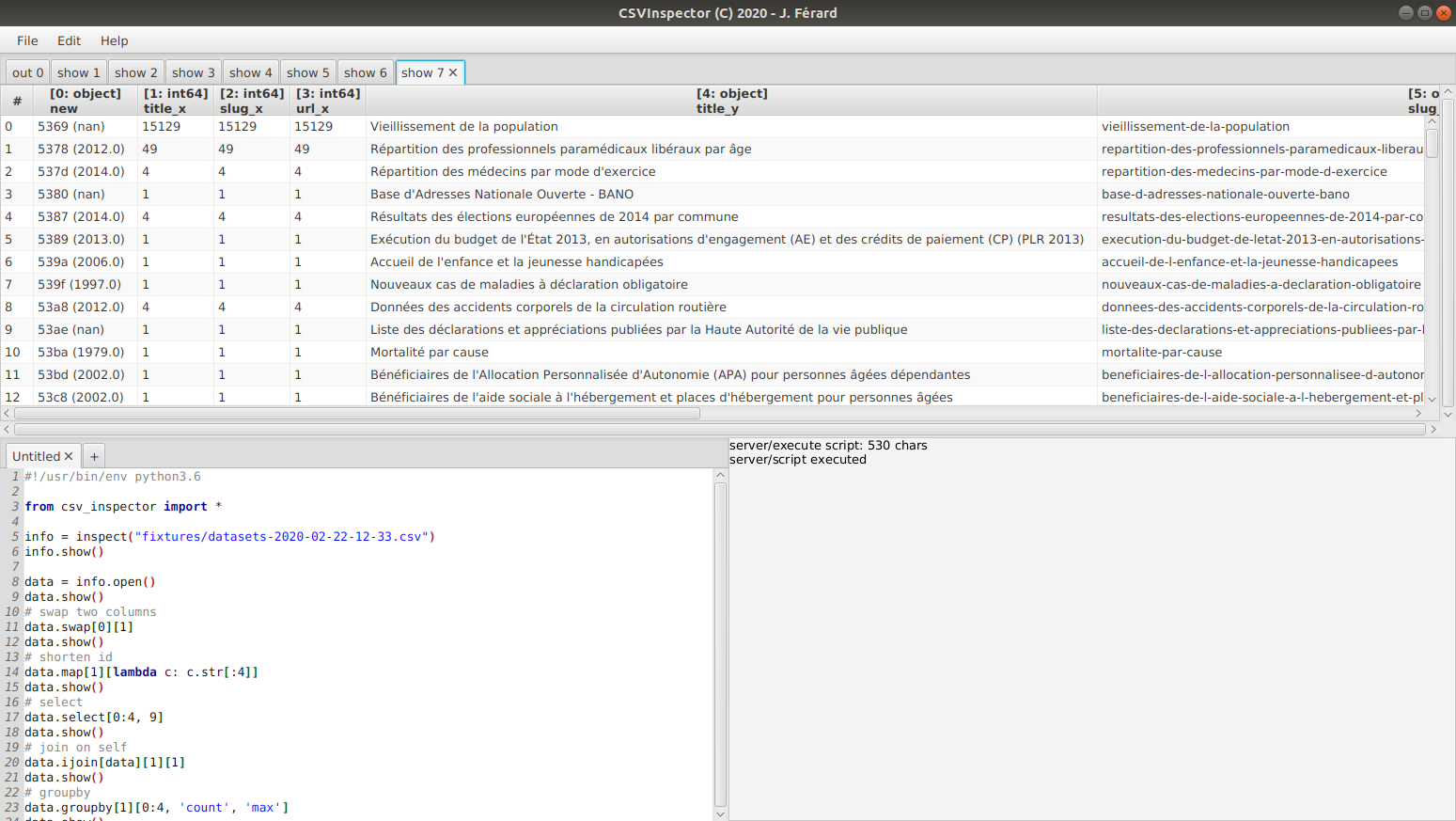
# Use case
CSVInspector main goal is to help user performing repetitive one shot tasks on small data sets. Those tasks may be data aggregation, table join, column selection or creation, ...
CSVInspector provides the `show` method that displays the current stat of a data set.
(If you work on stable data or if the data sets are big, you should consider using SQL.)
Typical use case is:
* load one or two light csv files (< 10 k lines);
* aggregate some columns in both tables;
* add some columns;
* join files;
* save the result.
# Overview
CSVInspector is a very basic client/server application:
* The server is a Python module that wraps some features of Pandas to handle CSV data.
* The client is a Kotlin/JavaFX GUI that sends Python scripts to the server and displays the results.
# Install & run
Python (won't work for now in a virtual env):
$ pushd lang/python
$ pip install --user -r requirements.txt
$ popd
Kotlin:
$ mvn clean install
$ /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -jar target/csv_inspector-1.0-SNAPSHOT.jar
# Usage
## Code sample
#!/usr/bin/env python3.8
from csv_inspector import *
data = read_csv("fixtures/datasets-2020-02-22-12-33.csv") # this will open a MetaCSV panel to create/save the .mcsv file
data.show() # show the data
# do whatever you want here
data.show()
data.save_as("fixtures/datasets-2020-02-22-12-33-new.csv")
## Main commands
The wrapper provides the following instructions:
### `read_csv(path.csv)`
* `path.csv` is the path to a csv file.
> If the MetaCSV file `path.mcsv` exists, return a `Data` object.
> Else, detects the encoding, csv format and column types of `path.csv` and generate a sample MetaCSV file that may be edited and saved. (Will return a `Data` object on next call.)
### `data.show()`
> Shows the `Data` object in a window.
### `data.stats()`
> Shows the stats of the `Data` object in a window.
### `data.copy()`
> Returns a copy of the `Data` object in a window.
### `data.save_as(path.csv)`
* `path.csv` is the path to a csv file.
> Saves the `Data` object to a file.
## Other Commands
Note the square brackets.
### `data[x].create(func, col_name, [col_type, [index]])`
> Create a new col
* `x` is an index, slice or tuple of slices/indices of column_index
* `func` is the function to apply to `x` values
* `col_name` is the name of the new column
* `col_type` is the type of the new column
* `index` is the index of the new column
### `data[x].drop()`
> Drop the indices of the handle and select the other indices.
* `x` is an index, slice or tuple of slices/indices
### `data[x].filter(func)`
> Filter data on a function.
* `x` is an index, slice or tuple of slices/indices.
* `func` is a function that takes the `x` values and returns a boolean
### `g = data[x].grouper()`
> Create a grouper on some rows.
>
> ```
> g = data[x].grouper()
> g[y].agg(func)
> g.group()
> ```
* `x` is the index, slice or tuple of slices/indices of the rows
* `y` is the index, slice or tuple of slices/indices of the aggregate columns
* `func` is aggregate function
### `data1[x].ijoin(data2[y], func)`
> Make an inner join between two data sets.
* `x` is the index, slice or tuple of slices/indices of the key
* `data2` is another `Data` object
* `y` is the index, slice or tuple of slices/indices of the other key
* `func` is the function to compare the `x` and `y` values
### `data1[x].ljoin(data2[y], func)`
> Make an inner join between two data sets.
* `x` is the index, slice or tuple of slices/indices of the key
* `data2` is another `Data` object
* `y` is the index, slice or tuple of slices/indices of the other key
* `func` is the function to compare the `x` and `y` values
### `data[x].merge(func, col_name, [col_type])`
> Create a new col by merging some columns. Those columns are
> consumed during the process.
* `x` is an index, slice or tuple of slices/indices of column_index
* `func` is the function to apply to `x` values
* `col_name` is the name of the new column
* `col_type` is the type of the new column
### `data[x].move_after(idx)`
> Move some column_group after a given index.
* `x` is an index, slice or tuple of slices/indices of column_index
* `idx` is the destination index
### `data[x].move_before(idx)`
> Move some column_group before a given index.
* `x` is an index, slice or tuple of slices/indices of column_index
* `idx` is the destination index
### `data1[x].ojoin(data2[y], func)`
> Make an outer join between two data sets.
* `x` is the index, slice or tuple of slices/indices of the key
* `data2` is another `Data` object
* `y` is the index, slice or tuple of slices/indices of the other key
* `func` is the function to compare the `x` and `y` values
### `data[x].rename(names)`
> Rename one or more columns
* `x` is the index, slice or tuple of slices/indices of the key
* `names` is a list of new names
### `data1[x].rjoin(data2[y], func)`
> Make an right join between two data sets.
* `x` is the index, slice or tuple of slices/indices of the key
* `data2` is another `Data` object
* `y` is the index, slice or tuple of slices/indices of the other key
* `func` is the function to compare the `x` and `y` values
### `data[x].rsort(func)`
> Sort the rows in reverse order.
* `x` is the index, slice or tuple of slices/indices of the key
* `func` is the key function
### `data[x].select()`
> Select the indices of the handle and drop the other indices.
* `x` is an index, slice or tuple of slices/indices
### `data[x].rsort(func)`
> Show the first rows of this DataHandle.
> Expected format: CSV with comma
>
> sort(self, func=None, reverse=False)
> Sort the rows.
* `x` is the index, slice or tuple of slices/indices of the key
* `func` is the key function
### `data.stats()`
> Show stats on the data
### `data1[x].swap(data2[y])
> swap(self, other_handle: 'DataHandle')
> Swap two handles. Those handles may be backed by the same data or not.
* `x` and `y` are indices, slices or tuples of slices/indices
### `data[x].update(func)`
> Update some column using a function.
* `x` is an index
* `func` is a function of `data[x]` (use numeric indices)