https://github.com/jhuckaby/megahash
A super-fast C++ hash table with Node.js wrapper, tested up to 1 billion keys.
https://github.com/jhuckaby/megahash
djb2 hash hashtable
Last synced: about 1 year ago
JSON representation
A super-fast C++ hash table with Node.js wrapper, tested up to 1 billion keys.
- Host: GitHub
- URL: https://github.com/jhuckaby/megahash
- Owner: jhuckaby
- License: other
- Created: 2019-10-07T04:18:00.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2024-02-04T19:35:43.000Z (over 2 years ago)
- Last Synced: 2025-04-04T00:11:30.915Z (about 1 year ago)
- Topics: djb2, hash, hashtable
- Language: JavaScript
- Homepage:
- Size: 195 KB
- Stars: 411
- Watchers: 18
- Forks: 31
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
Table of Contents
- [Overview](#overview)
* [MegaHash Features](#megahash-features)
* [Performance](#performance)
- [Installation](#installation)
- [Usage](#usage)
* [Setting and Getting](#setting-and-getting)
+ [Buffers](#buffers)
+ [Strings](#strings)
+ [Objects](#objects)
+ [Numbers](#numbers)
+ [BigInts](#bigints)
+ [Booleans](#booleans)
+ [Null](#null)
* [Deleting and Clearing](#deleting-and-clearing)
* [Iterating over Keys](#iterating-over-keys)
* [Error Handling](#error-handling)
* [Hash Stats](#hash-stats)
- [API](#api)
* [set](#set)
* [get](#get)
* [has](#has)
* [delete](#delete)
* [clear](#clear)
* [nextKey](#nextkey)
* [length](#length)
* [stats](#stats)
- [Internals](#internals)
* [Limits](#limits)
* [Memory Overhead](#memory-overhead)
* [Benchmark Script](#benchmark-script)
- [Caveats](#caveats)
- [Future](#future)
- [License](#license)
# Overview
**MegaHash** is a super-fast C++ [hash table](https://en.wikipedia.org/wiki/Hash_table) with a Node.js wrapper, capable of storing over 1 billion keys, has read/write speeds above 500,000 keys per second (depending on CPU speed, key/value size, and total keys in hash), and low memory overhead (~30 bytes per key). However, please note that there are some [caveats](#caveats).
I do know of the [hashtable](https://www.npmjs.com/package/hashtable) module on NPM, and have used it in the past. The problem is, that implementation stores everything on the V8 heap, so it runs into serious performance dips with tens of millions of keys. Also, it seems like the author may have abandoned it (open issues are going unanswered), and it doesn't compile on Node v12+.
## MegaHash Features
- Very fast reads, writes, deletes and key iteration.
- Stable, predictable performance.
- Low memory overhead.
- All data is stored off the V8 heap.
- Buffers, strings, numbers, booleans and objects are supported.
- Tested up to 1 billion keys.
- Mostly compatible with the basic [ES6 Map API](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map).
## Performance
See the chart below, which fills up a hash with 1 billion keys while measuring both read and write performance. This is an "ideal" case, with very small keys and values, simply to illustrate the maximum possible speed and hash overhead:
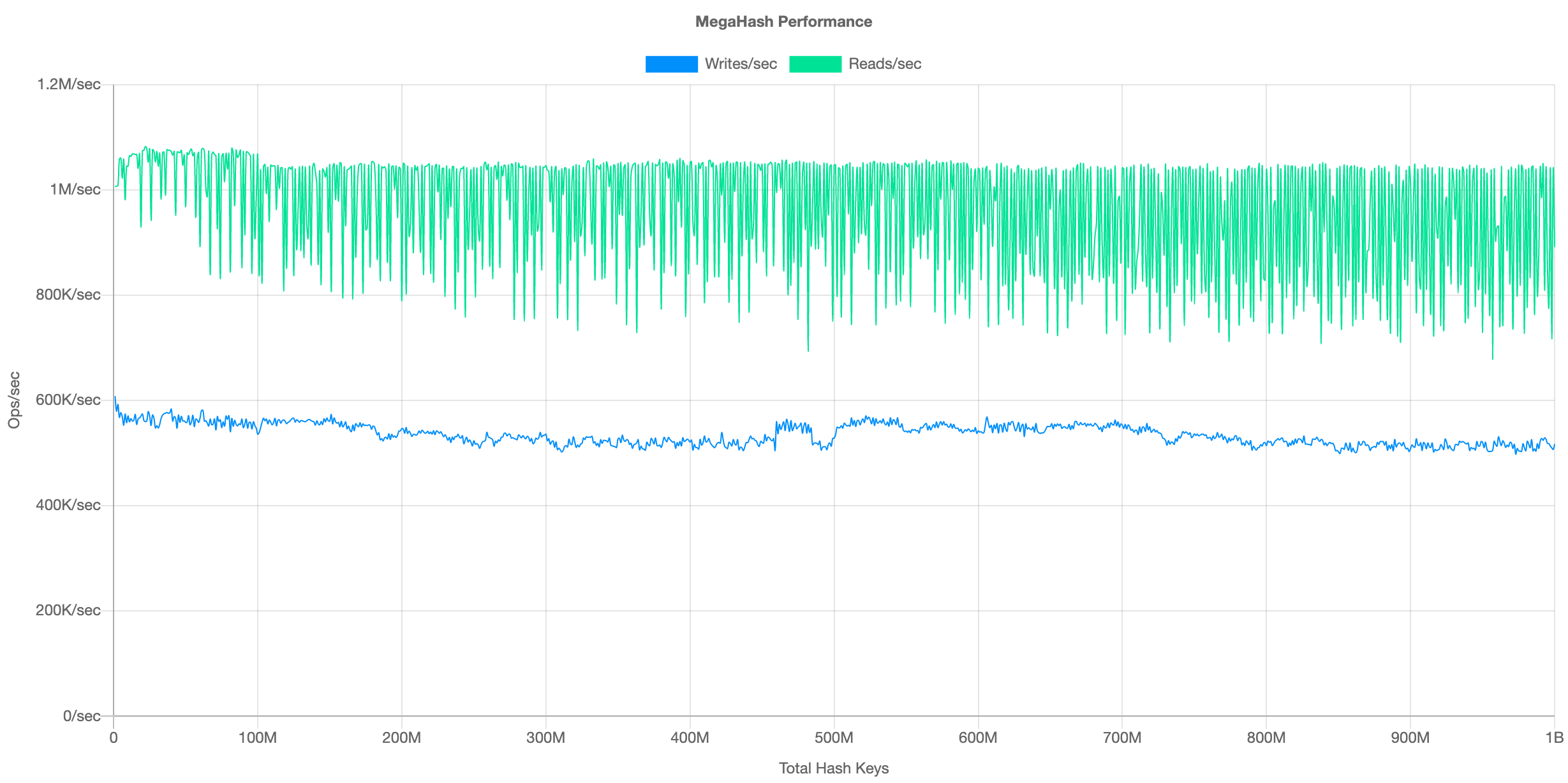
The average writes/sec was 535,261, and reads/sec was 961,852. This was on an AWS EC2 c5a.16xlarge VM. The performance is fairly consistent regardless of the total number of keys. As for memory usage, here is the chart:
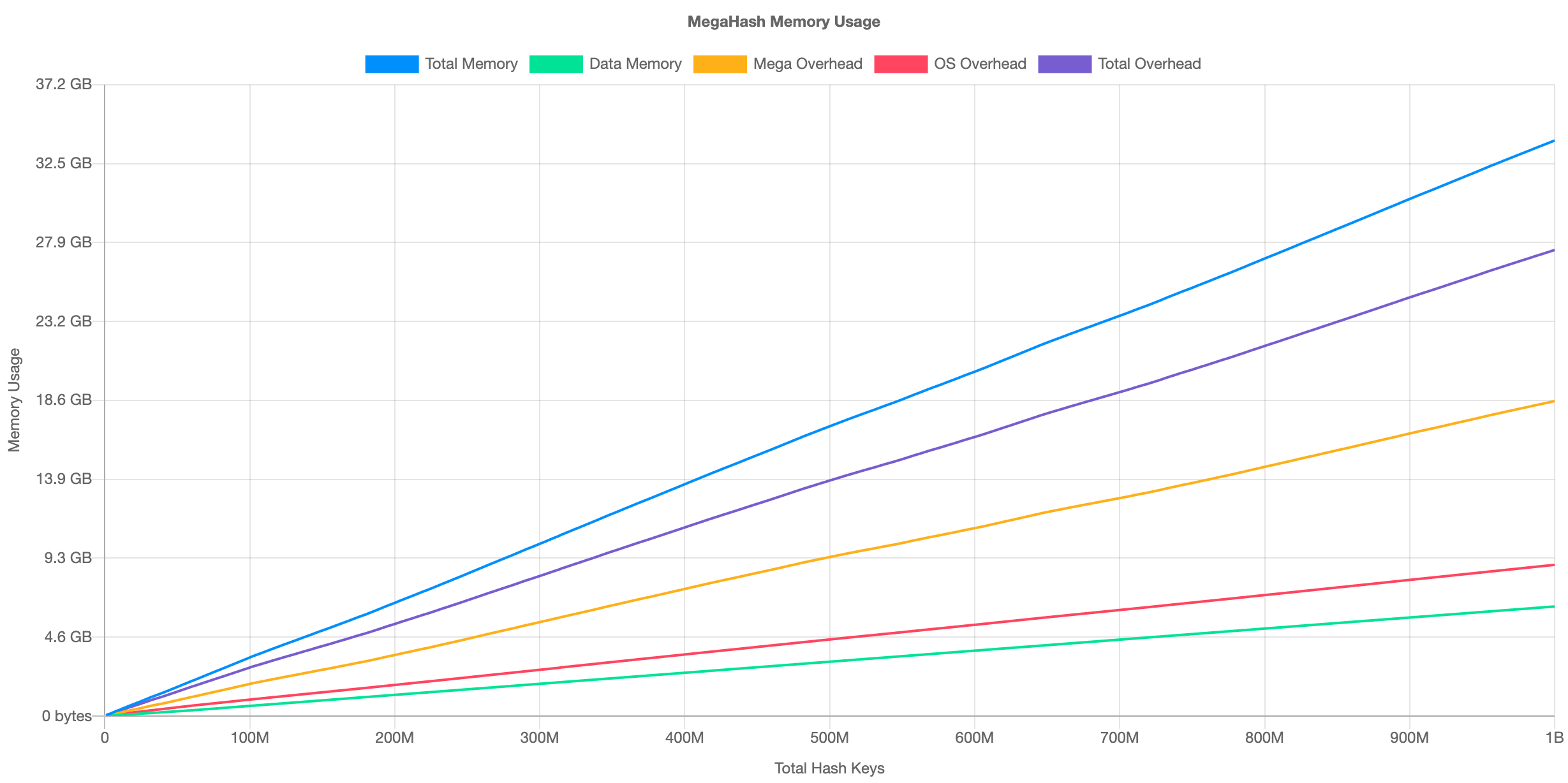
At 1 billion keys, MegaHash requires about 27.4 GB memory overhead. This divides out to approximately 30 bytes per key. Here is the overhead per key illustrated:
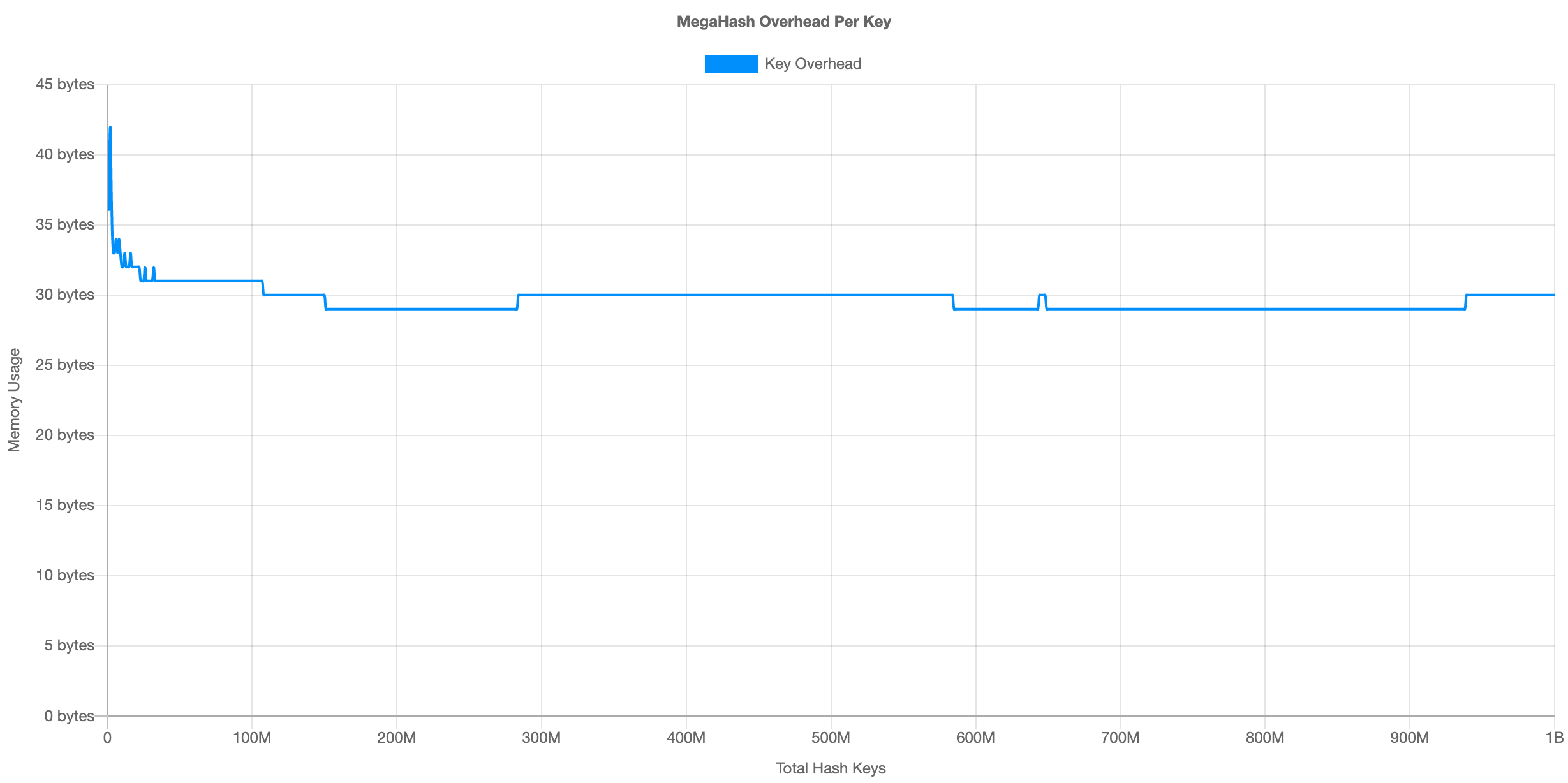
For more benchmark results, see the table below:
| Test Description | Record Size | Hardware | OS | Link |
|------------------|-------------|----------|----|------|
| Mac Standard 100M Keys | 96 - 128 chars | 2020 MacBook Pro 16" | macOS 10.15.7 | [View Results](https://pixlcore.com/software/megahash/v1.0.5/results/v1.0.5-darwin-100M.html) |
| Mac Ideal 100M Keys | 1 char | 2020 MacBook Pro 16" | macOS 10.15.7 | [View Results](https://pixlcore.com/software/megahash/v1.0.5/results/v1.0.5-darwin-ideal-100M.html) |
| Linux Standard 100M Keys | 96 - 128 chars | AWS EC2 c5a.16xlarge | AWS Linux 2021 | [View Results](https://pixlcore.com/software/megahash/v1.0.5/results/v1.0.5-linux-c5a-100M.html) |
| Linux Standard 100M Keys | 96 - 128 chars | AWS EC2 c5.metal | AWS Linux 2021 | [View Results](https://pixlcore.com/software/megahash/v1.0.5/results/v1.0.5-linux-c5metal-100M.html) |
| Linux Ideal 1B Keys | 1 char | AWS EC2 c5a.16xlarge | AWS Linux 2021 | [View Results](https://pixlcore.com/software/megahash/v1.0.5/results/v1.0.5-linux-ideal-1B.html) |
All results were produced using the included [Benchmark Script](#benchmark-script).
# Installation
Use [npm](https://www.npmjs.com/) to install the module locally:
```
npm install megahash
```
You will need a C++ compiler toolchain to build the source into a shared library:
| Platform | Instructions |
|----------|--------------|
| **Linux** | Download and install [GCC](https://gcc.gnu.org). On RedHat/CentOS, run `sudo yum install gcc gcc-c++ libstdc++-devel pkgconfig make`. On Debian/Ubuntu, run `sudo apt-get install build-essential`. |
| **macOS** | Download and install [Xcode](https://developer.apple.com/xcode/download/). You also need to install the `XCode Command Line Tools` by running `xcode-select --install`. Alternatively, if you already have the full Xcode installed, you can find them under the menu `Xcode -> Open Developer Tool -> More Developer Tools...`. This step will install `clang`, `clang++`, and `make`. |
| **Windows** | Install all the required tools and configurations using Microsoft's [windows-build-tools](https://github.com/felixrieseberg/windows-build-tools) using `npm install --global --production windows-build-tools` from an elevated PowerShell or CMD.exe (run as Administrator). |
Once you have that all setup, use `require()` to load MegaHash in your Node.js code:
```js
const MegaHash = require('megahash');
```
# Usage
Here is a simple example:
```js
let hash = new MegaHash();
hash.set( "hello", "there" );
console.log( hash.get("hello") );
hash.delete("hello");
hash.clear();
```
## Setting and Getting
To add or replace a key in a hash, use the [set()](#set) method. This accepts two arguments, a key and a value:
```js
hash.set( "hello", "there" );
hash.set( "hello", "REPLACED!" );
```
To fetch an existing value given a key, use the [get()](#get) method. This accepts a single argument, the key:
```js
let value = hash.get("hello");
```
The following data types are supported for values:
### Buffers
Buffers are the internal type used by the hash, and will give you the best performance. This is true for both keys and values, so if you can pass them in as Buffers, all the better. All other data types besides buffers are auto-converted. Example use:
```js
let buf = Buffer.allocSafe(32);
buf.write("Hi");
hash.set( "mybuf", buf );
let bufCopy = hash.get("mybuf");
```
It should be noted here that memory is **copied** when it enters and exits MegaHash from Node.js land. So if you insert a buffer and then retrieve it, you'll get a brand new buffer with a fresh copy of the data.
### Strings
Strings are converted to buffers using UTF-8 encoding. This includes both keys and values. However, for values MegaHash remembers the original data type, and will reverse the conversion when getting keys, and return a proper string value to you. Example:
```js
hash.set( "hello", "there" );
console.log( hash.get("hello") );
```
Keys are returned as strings when iterating using [nextKey()](#nextkey).
### Objects
Object values are automatically serialized to JSON, then converted to buffers using UTF-8 encoding. The reverse procedure occurs when fetching keys, and your values will be returned as proper objects. Example:
```js
hash.set( "user1", { name: "Joe", age: 43 } );
let user = hash.get("user1");
console.log( user.name, user.age );
```
### Numbers
Number values are auto-converted to double-precision floating point decimals, and stored as 64-bit buffers internally. Number keys are converted to strings, then to UTF-8 buffers which are used internally. Example:
```js
hash.set( 1, 9.99999999 );
let value = hash.get(1);
```
### BigInts
MegaHash has support for [BigInt](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/BigInt) numbers, which are automatically detected and converted to/from 64-bit signed integers. Example:
```js
hash.set( "big", 9007199254740993n );
let value = hash.get("big");
```
Note that BigInts are only supported in Node 10.4.0 and up.
### Booleans
Booleans are internally stored as a 1-byte buffer containing `0` or `1`. These are auto-converted back to Booleans when you fetch keys. Example:
```js
hash.set("bool1", true);
let test = hash.get("bool1");
```
### Null
You can specify `null` as a hash value, and it will be preserved as such. Example:
```js
hash.set("nope", null);
```
You cannot, however, use `undefined` as a value. Doing so will result in undefined behavior (get it?).
## Deleting and Clearing
To delete individual keys, use the [delete()](#delete) method. Example:
```js
hash.delete("key1");
hash.delete("key2");
```
To delete **all** keys, call [clear()](#clear) (or just delete the hash object -- it'll be garbage collected like any normal Node.js object). Example:
```js
hash.clear();
```
## Iterating over Keys
To iterate over keys in the hash, you can use the [nextKey()](#nextkey) method. Without an argument, this will give you the "first" key in undefined order. If you pass it the previous key, it will give you the next one, until finally `undefined` is returned. Example:
```js
let key = hash.nextKey();
while (key) {
// do something with key
key = hash.nextKey(key);
}
```
Please note that if new keys are added to the hash while an iteration is in progress, it may *miss* some keys, due to indexing (i.e. reshuffling the position of keys).
## Error Handling
If a hash operation fails (i.e. out of memory), then [set()](#set) will return `0`. You can check for this and bubble up your own error. Example:
```js
let result = hash.set( "hello", "there" );
if (!result) {
throw new Error("Failed to write to MegaHash: Out of memory");
}
```
## Hash Stats
To get current statistics about the hash, including the number of keys, raw data size, and other internals, call [stats()](#stats). Example:
```js
let stats = hash.stats();
console.log(stats);
```
Example stats:
```js
{
"numKeys": 10000,
"dataSize": 217780,
"indexSize": 87992,
"metaSize": 300000,
"numIndexes": 647
}
```
The response object will contain the following properties:
| Property Name | Description |
|---------------|-------------|
| `numKeys` | The total number of keys in the hash. You can also get this by calling [length()](#length). |
| `dataSize` | The total data size in bytes (all of your raw keys and values). |
| `indexSize` | Internal memory usage by the MegaHash indexing system (i.e. overhead), in bytes. |
| `metaSize` | Internal memory stored along with your key/value pairs (i.e. overhead), in bytes. |
| `numIndexes` | The number of internal indexes currently in use. |
To compute the total overhead, add `indexSize` to `metaSize`. For total memory usage, add `dataSize` to that. However, please note that the OS adds its own memory overhead on top of this (i.e. byte alignment, malloc overhead, etc.). All the benchmarking scripts account for this by measuring the total process size.
# API
Here is the API reference for the MegaHash instance methods:
## set
```
NUMBER set( KEY, VALUE )
```
Set or replace one key/value in the hash. Ideally both key and value are passed as Buffers, as this provides the highest performance. Most built-in data types are supported of course, but they are converted to buffers one way or the other. Example use:
```js
hash.set( "key1", "value1" );
```
The `set()` method actually returns a number, which will be `0`, `1` or `2`. They each have a different meaning:
| Result | Description |
|--------|-------------|
| `0` | An error occurred (out of memory). |
| `1` | A key was added to the hash (i.e. unique key). |
| `2` | An existing key was replaced in the hash. |
## get
```
MIXED get( KEY )
```
Fetch a value given a key. Since the value data type is stored internally as a flag with the raw data, this is used to convert the buffer back to the original type when the key is fetched. So if you store a string then fetch it, it'll come back as a string. Example use:
```js
let value = hash.get("key1");
```
If the key is not found, `get()` will return `undefined`.
## has
```
BOOLEAN has( KEY )
```
Check if a key exists in the hash. Return `true` if found, `false` if not. This is faster than a [get()](#get) as the value doesn't have to be serialized or sent over the wall between C++ and Node.js. Example use:
```js
if (hash.has("key1")) console.log("Exists!");
```
## delete
```
BOOLEAN delete( KEY )
```
Delete one key/value pair from the has, given the key. Returns `true` if found, `false` if not. Example use:
```js
hash.delete("key1");
```
## clear
```
VOID clear()
```
Delete *all* keys from the hash, effectively freeing all memory (except for indexes). Example use:
```js
hash.clear();
```
You can also optionally pass in one or two 8-bit unsigned integers to this method, to clear an arbitrary "slice" of the total keys. This is an advanced trick, only used for clearing out extremely large hashes in small chunks, as to not hang the main thread. Pass in one number between 0 - 256 to clear a "thick slice" (approximately 1/256 of total keys). Example:
```js
hash.clear( 34 );
```
Pass in *two* numbers between 0 - 256 to clear a "thin slice" (approximately 1/65536 of total keys). Example:
```js
hash.clear( 84, 191 );
```
## nextKey
```
STRING nextKey()
STRING nextKey( KEY )
```
Without an argument, fetch the *first* key in the hash, in undefined order. With a key specified, fetch the *next* key, also in undefined order. Returns `undefined` when the end of the hash has been reached. Example use:
```js
let key = hash.nextKey();
while (key) {
// do something with key
key = hash.nextKey(key);
}
```
## length
```
NUMBER length()
```
Return the total number of keys currently in the hash. This is very fast, as it does not have to iterate over the keys (an internal counter is kept up to date on each set/delete). Example use:
```js
let numKeys = hash.length();
```
## stats
```
OBJECT stats()
```
Fetch statistics about the current hash, including the number of keys, total data size in memory, and more. The return value is a native Node.js object with several properties populated. Example use:
```js
let stats = hash.stats();
// Example stats:
{
"numKeys": 10000,
"dataSize": 217780,
"indexSize": 87992,
"metaSize": 300000,
"numIndexes": 647
}
```
See [Hash Stats](#hash-stats) for more details about these properties.
# Internals
MegaHash uses [separate chaining](https://en.wikipedia.org/wiki/Hash_table#Separate_chaining) to store data, which is a combination of an index and a linked list. However, our indexing system is unique in that the indexes themselves become links on the chain, when the linked lists reach a certain size. Effectively, the indexes are *nested*, using different bits of the key digest, and the index tree grows as more keys are added.
Keys are digested (a.k.a. hashed) using the 32-bit [DJB2](http://www.cs.yorku.ca/~oz/hash.html) algorithm, but then MegaHash splits the digest into 8 slices (4 bits each). Each slice becomes a separate index level (each with 16 slots). The indexes are dynamic and only create themselves as needed, so a hash starts with only one main index, utilizing only the first 4 bits of the key digest. When lists grow beyond a fixed size (plus a scatter factor), a "reindex" occurs, where new indexes nest inside themselves, using additional slices of the digest.
This design allows MegaHash to grow and reindex without losing much performance or stalling / lagging. Effectively a reindex event only has to move a handful of keys each time.
MegaHash is currently hard-coded to use between 8 and 24 buckets (key/value pairs) per linked list before reindexing (this number is varied to scatter the reindexes). In my testing, this range seems to strike a good balance between speed and memory overhead. In the future, these values may be configurable.
## Limits
- Keys can be up to 65K bytes each (16-bit unsigned int).
- Values can be up to 2 GB each (32-bit signed, the size limit of Node.js buffers).
- There is no predetermined total key limit.
- All keys are buffers (strings are encoded with UTF-8), and must be non-zero length.
- Values may be zero length, and are also buffers internally.
- String values are automatically converted to/from UTF-8 buffers.
- Numbers are converted to/from double-precision floats.
- BigInts are converted to/from 64-bit signed integers.
- Object values are automatically serialized to/from JSON.
## Memory Overhead
Each MegaHash index record is 128 bytes (16 pointers, 64-bits each), and each bucket adds 24 bytes of overhead. The tuple (key + value, along with lengths) is stored as a single blob (single `malloc()` call) to reduce memory fragmentation from allocating the key and value separately.
At 100 million keys, the total memory overhead is approximately 2.7 GB. At 1 billion keys, it is 27.4 GB. This equates to approximately 30 bytes per key.
## Benchmark Script
The script used to produce the graphs and benchmark results above is included in the repo. See the `test` directory, and run either `bench-perf-mem.js` for a standard test (with 96 - 128 byte values), or `bench-ideal.js` for an "ideal" test (with 1 byte values). The scripts accept the following command-line arguments:
| Argument | Description |
|----------|-------------|
| `--max` | The total number of keys to write into the hash, defaults to `100000000` (100M). |
| `--name` | Name of the test, which affects the result filenames written into the `test/results/` directory. |
Example use:
```
cd megahash/test
node bench-perf-mem.js --name MYTEST --max 100000000
```
See the `test/results/` directory for the output files. The script produces a HTML file and a JS file (and one loads the other in the browser). Make sure you have **lots** of available RAM for this test. A 100M test requires 14GB RAM!
# Caveats
Please note that MegaHash is **not** a complete drop-in replacement for [ES6 Maps](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map). Specifically:
- Objects are serialized to JSON when passed as values to MegaHash, and unserialized when fetched. This is because data is stored outside the V8 heap in C++ memory, so everything is internally converted to/from Buffers. That means object serialization.
- Only a subset of the ES6 Map interface is implemented currently. Specifically [get](#get), [set](#set), [has](#has), [delete](#delete), [clear](#clear) and [length](#length).
- Also note that [length](#length) is a method, not a property.
# Future
- Precompiled binaries
- Reduce per-key memory overhead
- Implement more of the ES6 Map interface
# License
**The MIT License (MIT)**
*Copyright (c) 2021 Joseph Huckaby*
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.