https://github.com/jiagengchang/myevae
MyeVAE. A multi-modal variation autoencoder with sub-task supervised latent subspace. Used for predicting mortality risk in newly diagnosed myeloma patients.
https://github.com/jiagengchang/myevae
multi-omics-integration pytorch scikit-learn-pipelines survival-regression vae
Last synced: about 1 month ago
JSON representation
MyeVAE. A multi-modal variation autoencoder with sub-task supervised latent subspace. Used for predicting mortality risk in newly diagnosed myeloma patients.
- Host: GitHub
- URL: https://github.com/jiagengchang/myevae
- Owner: JiaGengChang
- License: mit
- Created: 2024-10-09T15:40:26.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-04-07T06:37:59.000Z (about 1 year ago)
- Last Synced: 2025-04-07T07:31:02.589Z (about 1 year ago)
- Topics: multi-omics-integration, pytorch, scikit-learn-pipelines, survival-regression, vae
- Language: Python
- Homepage:
- Size: 12.8 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# MyeVAE
[](https://badge.fury.io/py/myevae)
[](https://GitHub.com/JiaGengChang/myevae/commit/)
[](https://github.com/JiaGengChang/myevae/blob/master/LICENSE)
[](https://www.python.org/)
MyeVAE is a variational autoencoder leveraging multi-omics for risk prediction in newly diagnosed multiple myeloma patients.
This repository contains the Python source code to preprocess multimoodal features, train MyeVAE, score its performance, and perform SHAP analysis.
All computation is done on the CPU, using the PyTorch library.
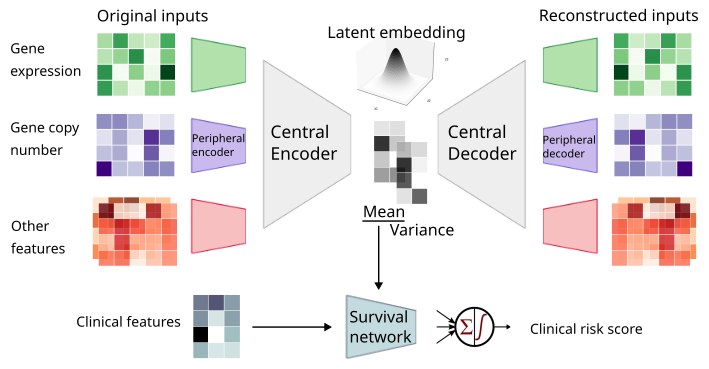
# Setup
## Install MyeVAE
Requires **Python 3.9** or later
Install through PyPI
```bash
pip install myevae
```
Install through github
```bash
pip install git+https://github.com/JiaGengChang/myevae.git
```
## Download data
Download the raw multi-omics dataset and example outputs from the following link:
1. Input datasets are stored at https://myevae.s3.us-east-1.amazonaws.com/example_inputs.tar.gz
2. Example output files are stored at https://myevae.s3.us-east-1.amazonaws.com/example_outputs.tar.gz
Please use the download links sparingly.
If you use the AWS S3 CLI, the bucket ARN is `arn:aws:s3:::myevae` - you can list its contents and download specific files.
# Step-by-step guide
## 1. (Optional) Feature preprocessing
As there are over 50,000 raw features and contains missing values, this step performs supervised-feature selection, scaling, and imputation.
For feature selection, elastic net regularized Cox proportional hazards is used.
For imputation, round-robin imputation with scikit-learn IterativeImputer is used, with random forest regressor and classifier as based estimators.
```bash
myevae preprocess \
-e [endpoint: os | pfs] \
-i [/inputs/folder]
```
The following output files will be created in the same directory as the inputs.
```bash
project
└──inputs
├──...
├──train_features_os_processed.csv
├──train_features_pfs_processed.csv
├──valid_features_os_processed.csv
└──valid_features_pfs_processed.csv
```
Preprocessing of features as computationally expensive than hyperparameter tuning. On 10 cores and 64GB RAM, it uses a wall time of **~12 hours**.
Alternatively, if you are just testing this package, you may use pre-processed features from the S3 bucket link and proceed to the next step.
## 2. Fit model
See [requirements](#requirements) for the required files before training.
Basically, you need to place the processed features and labels in `/inputs/folder`, and create a hyperparameter file named `param_grid.py` in `/params/folder`. See [this section](#3-hyperparameter-file) for the default hyperparamter grid.
```bash
myevae train \
-e [endpoint: os | pfs] \
-n [model_name] \
-i [/inputs/folder] \
-p [/params/folder] \
-t [nthreads] \
-o [/output/folder]
```
If the hyperparameter file is not specified, the default will be used (`/src/myevae/param_grid.py`), the process should take only **5 minutes**.
With an actual hyperparameter grid, the training can take up to **12 hours**.
## 3. Score model
```bash
myevae score \
-e [endpoint: os | pfs] \
-n [model_name] \
-i [/inputs/folder] \
-o [/output/folder]
```
Model scoring should be done in under **a minute**.
## 4. SHAP analysis
```bash
myevae shap \
-e [endpoint: os | pfs] \
-n [model_name] \
-i [/inputs/folder] \
-o [/output/folder]
```
Approximation of SHAP values and generation of summary plots should take **1-2 minutes**.
## End result
For a model named "default", the final output should look something like this.
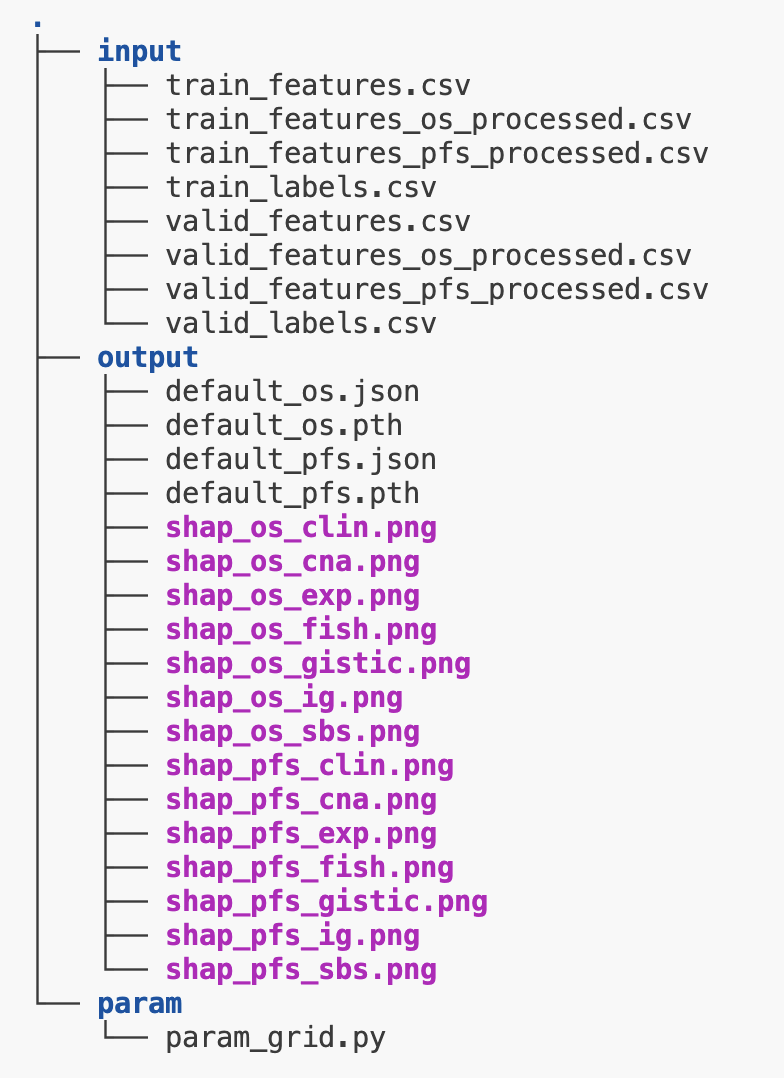
Validation scores and best parameters can be found in the `.json` files. The `.pth` files are model weights.
# Requirements
## 1. Raw features
Required for [preprocessing](#1-optional-feature-preprocessing) only.
Place the following `.csv` files in the inputs folder:
```bash
project
└──inputs
├──train_features_os_processed.csv
├──valid_features_os_processed.csv
└──train_labels.csv
```
Note the preprocessing does not use valid labels (`valid_labels.csv`), but it is fine if the file is in the directory.
## 2. Processed features
Required for [training](#2-fit-model), [scoring](#3-score-model) and [shap analysis](#4-shap-analysis)
Place the following `.csv` files inside your inputs folder (`/inputs/folder`), and the `param_grid.py` inside your preferred folder. Also create an empty folder for the outputs.
```bash
project
├──inputs
│ ├──train_features_os_processed.csv
│ ├──valid_features_os_processed.csv
│ ├──train_labels.csv
│ └──valid_labels.csv
├──params
│ └──param_grid.py
└──outputs
└──[output files created here]
```
For `features*.csv` and `labels*.csv`, column 0 is read in as the index, which should be the patient IDs.
Example input csv files can be downloaded from AWS S3 link above.
## 3. Hyperparameter file
Required for [training](#2-fit-model) only.
Place a python file named `param_grid.py` containing the hyperparameter grid dictionary in the params folder (specified with `-p`).
This contains the set of hyperparameters that grid search will be performed on.
Otherwise, use the default provided in `src/myevae/param_grid.py`. This default hyperparameter grid is only meant for testing purposes:
```python
from torch.nn import LeakyReLU, Tanh
# the default hyperparameter grid for debugging uses
# this is not meant to be used for real training, as the search space is only on z_dim
param_grid = {
'z_dim': [8,16,32],
'lr': [5e-4],
'batch_size': [1024],
'input_types': [['exp','cna','gistic','fish','sbs','ig']],
'input_types_subtask': [['clin']],
'layer_dims': [[[32, 4],[16,4],[4,1],[4,1],[4,1],[4,1]]],
'layer_dims_subtask' : [[4,1]],
'kl_weight': [1],
'activation': [LeakyReLU()],
'subtask_activation': [Tanh()],
'epochs': [100],
'burn_in': [20],
'patience': [5],
'dropout': [0.3],
'dropout_subtask': [0.3]
}
```
An actual paramater file is available at https://myevae.s3.us-east-1.amazonaws.com/param_grid.py
Using the actual hyperparameter file, the training time will be significantly longer (~12 hours)
## Software
These dependencies will be automatically installed.
```
python >= 3.9
torch >= 1.9.0
scikit-learn >= 0.24.1
scikit-survival >= 0.23.1
importlib_resources
matplotlib
shap-0.47.3.dev8-offline-fork-for-myevae==0.0.1
```
The last dependency is a offline fork of shap (https://pypi.org/project/shap/) which has been modified to work MyeVAE.
## Recommended hardware
1. Minimum 4 CPU cores (8 cores is recommended)
2. Minimum 16 GB RAM (64GB is required for feature preprocessing)
No GPU is required.
# Citation
If you use MyeVAE in your research, please consider citing:
Chang, J.G., Chen, J., Chew, GL. et al. MyeVAE: a multi-modal variational autoencoder for risk profiling of newly diagnosed multiple myeloma. BMC Artif. Intell. 1, 8 (2025). https://doi.org/10.1186/s44398-025-00009-2