https://github.com/jiahuann/easyspider
GET ALL of the WriteUp of ctfhub dot com
https://github.com/jiahuann/easyspider
Last synced: 3 months ago
JSON representation
GET ALL of the WriteUp of ctfhub dot com
- Host: GitHub
- URL: https://github.com/jiahuann/easyspider
- Owner: JiaHuann
- License: gpl-2.0
- Created: 2021-11-16T02:12:25.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2022-12-17T04:32:34.000Z (over 2 years ago)
- Last Synced: 2025-01-20T20:30:41.720Z (4 months ago)
- Language: Python
- Homepage:
- Size: 41 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: readme.md
- License: LICENSE
Awesome Lists containing this project
README
关于 ctfhub, 消耗 "金币" 打开一个 wp 后可以不停的切换到下一个,于是找到了放 wp 的网站,获取到了所有的 ctfhub 的目录,于是以此业务逻辑为切入点
首先对所有需要的知识点进行分析
爬虫整体逻辑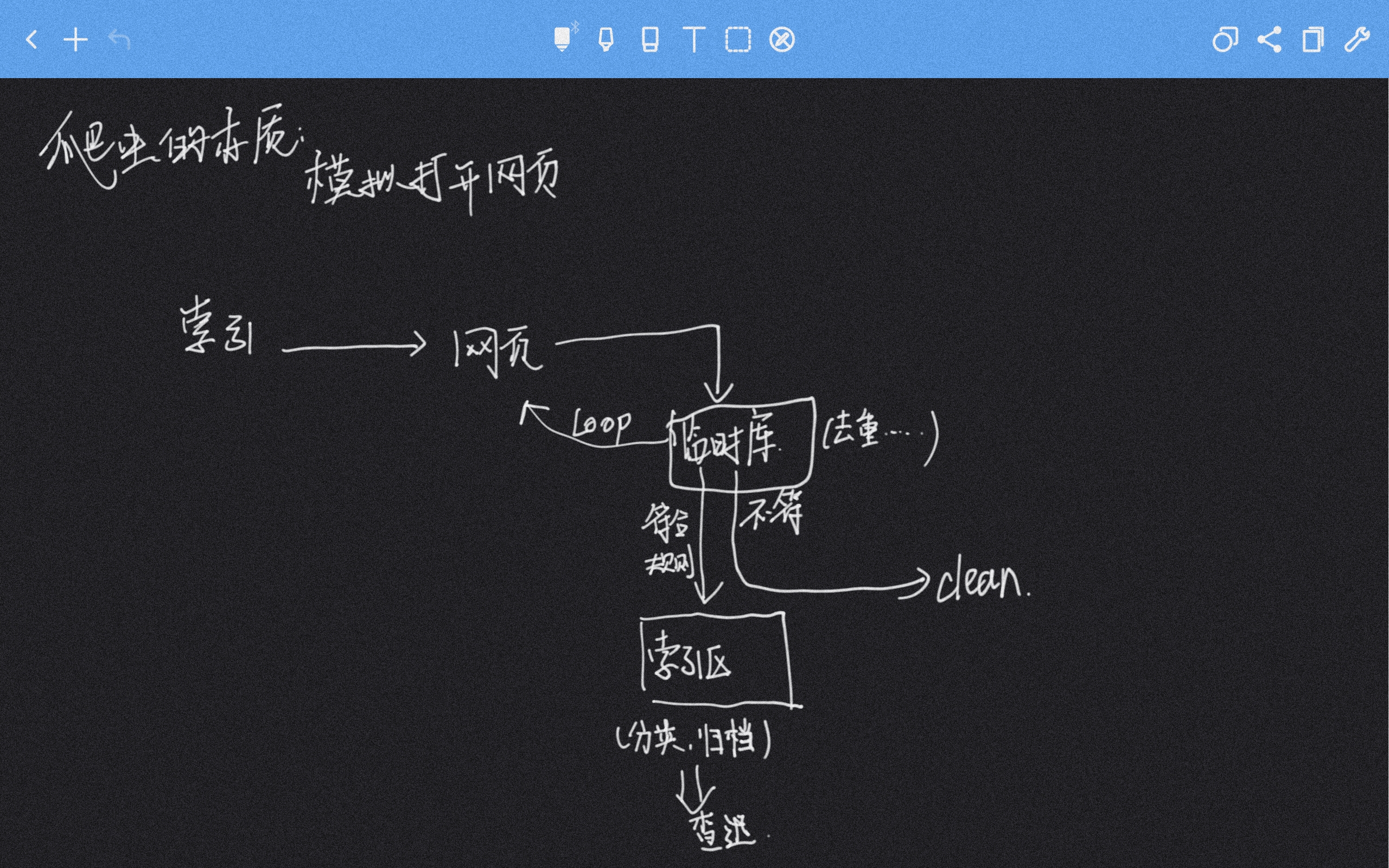
# 0x01urllib库
技术文档资料:[https://www.runoob.com/python3/python-urllib.html](https://www.runoob.com/python3/python-urllib.html)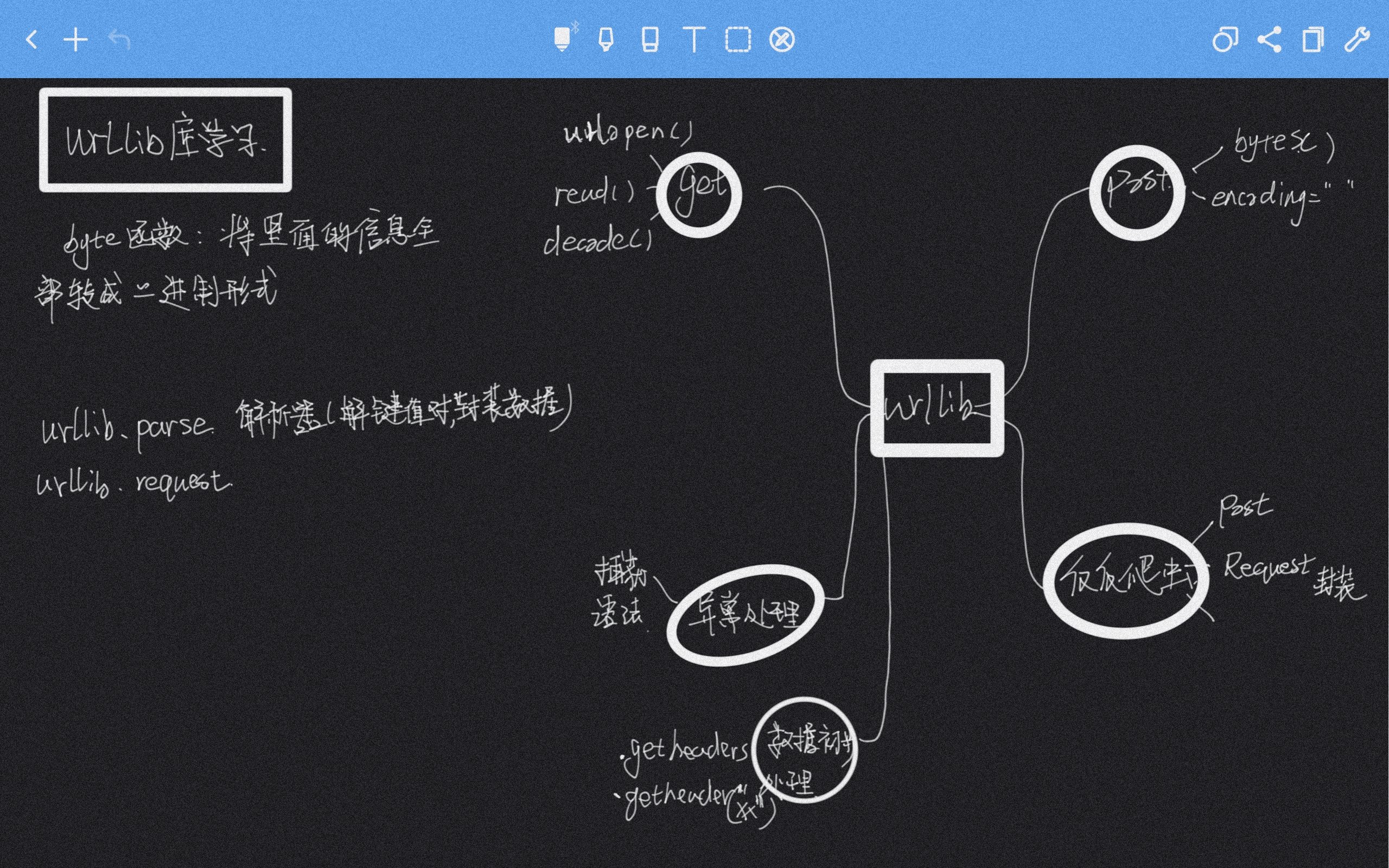
## 1.urlopen 打开网页函数
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下:
```python
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
```
- **url**:url 地址。
- **data**:发送到服务器的其他数据对象,默认为 None。
- **timeout**:设置访问超时时间。
- **cafile 和 capath**:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
- **cadefault**:已经被弃用。
- **context**:ssl.SSLContext类型,用来指定 SSL 设置。
#### 实例
使用 urlopen 打开一个 URL,然后使用 read() 函数获取网页的 HTML 实体代码。
```python
from urllib.request import urlopen
myURL = urlopen("https://www.baidu.com/")
print(myURL.read())
```
## 2.读取网页内容函数
**readline()** - 读取文件的一行内容
```python
from urllib.request import urlopen
myURL = urlopen("https://www.baidu.com/")
print(myURL.readline()) #读取一行内容
```
**readlines()** - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
```python
from urllib.request import urlopen
myURL = urlopen("https://www.baidub.com/")
lines = myURL.readlines()
for line in lines:
print(line)
```
## 3.网页状态判断&&错误捕获函数
## 实例
```python
import urllib.request
myURL1 = urllib.request.urlopen("https://www.baidu.com/")
print(myURL1.getcode()) # 200
try:#错误捕获函数
myURL2 = urllib.request.urlopen("https://www.baidu.com/no.html")
except urllib.error.HTTPError as e:
if e.code == 404:
print(404)
```
*urllib.error.HTTPError*
## 4.URL 的编码与解码
使用 **urllib.request.quote()** 与 **urllib.request.unquote()** 方法:
```python
import urllib.request
encode_url = urllib.request.quote("https://www.baidu.com/") # 编码
print(encode_url)
unencode_url = urllib.request.unquote(encode_url) # 解码
print(unencode_url)
#output
#https%3A//www.runoob.com/
#https://www.runoob.com/
```
## 5.Header请求头模拟
这时候需要使用到 urllib.request.Request 类:
```python
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
```
- **url**:url 地址。
- **data**:发送到服务器的其他数据对象,默认为 None。
- **headers**:HTTP 请求的头部信息,字典格式。
- **origin_req_host**:请求的主机地址,IP 或域名。
- **unverifiable**:很少用整个参数,用于设置网页是否需要验证,默认是False。。
- **method**:请求方法, 如 GET、POST、DELETE、PUT等
## 知识点1-5实战
```python
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/?s=' # 搜索页面
keyword = 'Python 教程'
key_code = urllib.request.quote(keyword) # 对请求进行编码
url_all = url+key_code #拼接url
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
request = urllib.request.Request(url_all,headers=header) #模拟请求头
reponse = urllib.request.urlopen(request).read() #读取网页内容
fh = open("./urllib_test_baidu_search.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()
```
## POST传数据(Python+PHP+html联动)
HTML+PHP
```php
菜鸟教程(runoob.com) urllib POST 测试
Name:
Tag:
```
Python
```php
import urllib.request
import urllib.parse
url = 'https://www.runoob.com/try/py3/py3_urllib_test.php' # 提交到表单页面
data = {'name':'RUNOOB', 'tag' : '菜鸟教程'} # 提交数据
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
data = urllib.parse.urlencode(data).encode('utf8') # 对参数进行编码,解码使用 urllib.parse.urldecode
request=urllib.request.Request(url, data, header) # 请求处理
reponse=urllib.request.urlopen(request).read() # 读取结果
fh = open("./urllib_test_post_runoob.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()
```
实验结果,如图:
url.errorcode等更多用法暂时不说,下面进入另外一个库的学习
# 0x02BeautifulSoup4
bs4官方文档
[https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/](https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/)
我总结的,目前需要用的东西如图,由于展开来讲文档更好,我就不展开赘述了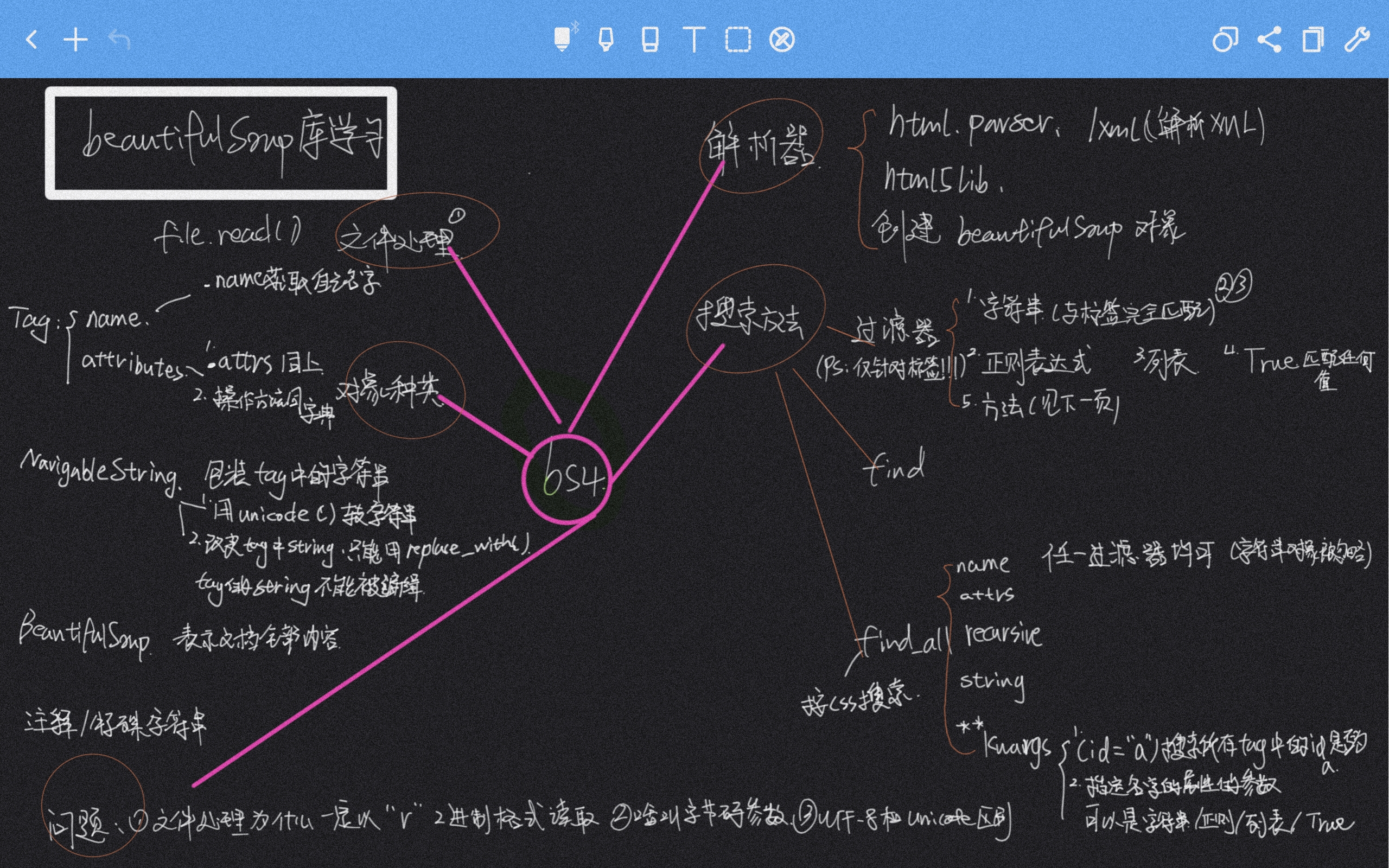
# 0x03TinyBetaSpider代码剖析
```python
from bs4 import BeautifulSoup
import requests
import re
import sys
import urllib.request,urllib.error
for i in range(2,29):
a="https://writeup.ctfhub.com/archives/page/"+str(i)+"/"
print(a)
html = requests.get(a)
print(html)
html.encoding = "utf-8"
myhtml = html.text
#print(myhtml)
f = open("test.html",'w')
f.write(myhtml)
file = open("test.html","r") #打开-html文档 rb以二进制格式读取
html = file.read() #对file文件进行读取,读到内存里
bs = BeautifulSoup(html,"html.parser")#用html.parser解析器对这个进行一个解析,形成了一个文件树
t_list=bs.find_all("a", class_="post-title-link")
for tag in t_list:
link = 'https://writeup.ctfhub.com'+tag.get('href')+' '+tag.span.string
f = open("spider.txt",'a')
f.write(link)
f.write('\r')
print(link)
```
# 1.处理部分
由于博客有很多页,所以我们先把每一页的url打印到一个文件
```python
for i in range(2,29):
a="https://writeup.ctfhub.com/archives/page/"+str(i)+"/" #遍历
html = requests.get(a) #获取响应
html.encoding = "utf-8" #转换编码,防止中文乱码
myhtml = html.text
#如果不调用.text会报错TypeError: write() argument must be str, not Response
f = open("test.html",'w') #写入
f.write(myhtml)
```
# 2.调用bs4部分
```python
file = open("test.html","r") #打开-html文档 rb以二进制格式读取
html = file.read() #对file文件进行读取,读到内存里
bs = BeautifulSoup(html,"html.parser")#用html.parser解析器对这个进行一个解析,形成了一个文件树
t_list=bs.find_all("a", class_="post-title-link")#找到所有指定class的标签
```
# 3.资源整合
```python
for tag in t_list:
link = 'https://writeup.ctfhub.com'+tag.get('href')+' '+tag.span.string
f = open("spider.txt",'a')
f.write(link)
f.write('\r')
print(link)
```