Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/jmahabal/movie-diversity-cli
The CLI version of my movie diversity function.
https://github.com/jmahabal/movie-diversity-cli
cli diversity gender movies nodejs
Last synced: 9 days ago
JSON representation
The CLI version of my movie diversity function.
- Host: GitHub
- URL: https://github.com/jmahabal/movie-diversity-cli
- Owner: jmahabal
- Created: 2018-04-08T23:07:42.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2022-12-07T17:57:31.000Z (about 2 years ago)
- Last Synced: 2025-01-14T07:05:58.958Z (10 days ago)
- Topics: cli, diversity, gender, movies, nodejs
- Language: JavaScript
- Size: 655 KB
- Stars: 2
- Watchers: 2
- Forks: 0
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# [Movie Gender Diversity CLI](https://github.com/jmahabal/movie-diversity-cli)
This is a CLI tool for determining the breakdown by gender of a movie. I
grab the data from [the Movie DB](themoviedb.org), a website similar to IMDB but
with an API.
# How to use it
You can install the application globally on your system from npm with the command `npm install movie-diversity-cli -g`.

Then to actually use the script you can call it by `movie-diversity get "movie name"`.
If you're searching for a movie with multiple words in the title you'll need to
surround the title with quotes.

Here's an example response you might get:
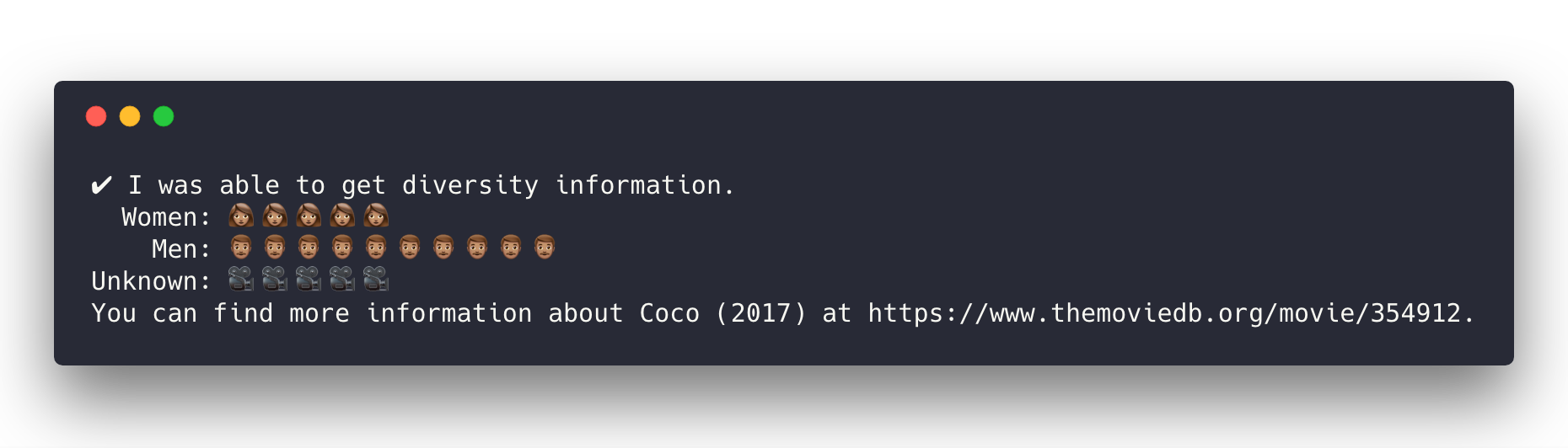
You can also get a random movie by `movie-diversity random`. Omitting arguments
to the function will also result in this call.

If you don't want to install it globally you can use `npx` to create a temporary
install: `npx movie-diversity-cli`.

# How it works
The process of creating an 'analysis' kicks off with a movie title. This title
is fed into the MovieDB search API after which the bot selects the first movie
listed. Once there is a movie associated with the request, the program grabs the
cast members and aggregates the genders of the first 20 cast members.
This is done in an Amazon Lambda function. You can see code for that process
under `lambda/`. If you want to run the Lambda code yourself, you'll need to grab
your own API key from the MovieDB.
The cast members are billed according to importance, so choosing the top 20
should lead to a accurate study, as minor characters with little screen time
are not as relevant (though definitely still important!) The output distribution
is then displayed to the user.
For picking a random movie the program makes a call to a
[Datasette](https://github.com/simonw/datasette) JSON API with a list of a 100
popular movies. From there it filters the list to only movies from after 1975, in
order to make sure that we have enough data for an analysis. It then picks a random
movie from that list and feeds it into the main function.
# The future
* Expand analysis to include ethnicity information as well, in addition to other
groups
* Have more detailed error messages, including ones for when the movie was
actually found, but did not have enough cast members for an analysis
# Credits
I'd like to thank Tim Pettersen for their
[tutorial](https://developer.atlassian.com/blog/2015/11/scripting-with-node/) on
how to build a CLI tool in Node, [The Movie DB](https://www.themoviedb.org/documentation/api)
for providing such a useful API, and [Carbon](https://carbon.now.sh/) for providing an easy way to
create instruction images.
