https://github.com/joenano/rpscrape
Scrape horse racing results data and racecards.
https://github.com/joenano/rpscrape
horse-racing python scraper
Last synced: 5 months ago
JSON representation
Scrape horse racing results data and racecards.
- Host: GitHub
- URL: https://github.com/joenano/rpscrape
- Owner: joenano
- Created: 2018-11-29T18:01:00.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2026-02-12T09:30:50.000Z (5 months ago)
- Last Synced: 2026-02-12T12:09:46.156Z (5 months ago)
- Topics: horse-racing, python, scraper
- Language: Python
- Homepage:
- Size: 2.54 MB
- Stars: 203
- Watchers: 40
- Forks: 79
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# rpscrape
Horse racing data has been hoarded by a few companies, enabling them to effectively extort the public for access to any worthwhile historical amount. Compared to other sports where historical data is easily and freely available to use and query as you please, racing data in most countries is far harder to come by and is often only available with subscriptions to expensive software.
The aim of this tool is to provide a way of gathering large amounts of historical data at no cost.
#### Table of Contents
- [Requirements](#requirements)
- [Install](#install)
- [Examples](#examples)
- [Scrape Racecards](#scrape-racecards)
- [Settings](#settings)
- [Authentication](#authentication)
### Requirements
You must have Python 3.13 or greater, and GIT installed. You can download the latest Python release [here](https://www.python.org/downloads/). You can download GIT [here](https://git-scm.com/downloads).
- [curl_cffi](https://pypi.org/project/curl-cffi/)
- [jarowinkler](https://pypi.org/project/jarowinkler/)
- [LXML](https://lxml.de/)
- [orjson](https://pypi.org/project/orjson/1.3.0/)
- [python-dotenv](https://pypi.org/project/python-dotenv/)
- [tomli](https://pypi.org/project/tomli/)
- [TQDM](https://pypi.org/project/tqdm/)
The above Python modules are required, they can be installed using PIP(_included with Python_):
```
pip3 install curl_cffi jarowinkler lxml orjson python-dotenv tomli tqdm
```
### Install
```
git clone https://github.com/joenano/rpscrape.git
```
#### Command-Line Options
```
-d, --date Single date or date range YYYY/MM/DD-YYYY/MM/DD.
-y, --year Year or year range (YYYY or YYYY-YYYY).
-r, --region Region code (e.g., gb, ire).
-c, --course Numeric course code.
-t, --type Race type: flat or jumps.
--date-file File containing dates (one per line, YYYY/MM/DD).
--clean Clear cache and data before running request.
--regions List or search regions.
--courses List/search courses or list courses in a region.
```
##### Notes
--date and --year are mutually exclusive.
You cannot specify both --region and --course at the same time.
When scraping jumps data, the year refers to the season start. For example, the 2019 Cheltenham Festival is in the 2018-2019 season: use 2018.
### Examples
All races on a specific date:
```
./rpscrape.py -d 2020/10/01
```
Only races from Great Britain:
```
./rpscrape.py -d 2020/10/01 -r gb
```
Date range:
```
./rpscrape.py -d 2019/12/15-2019/12/18
```
Flat races in Ireland (2019):
```
./rpscrape.py -r ire -y 2019 -t flat
```
Jump races at Ascot (1999–2018):
```
./rpscrape.py -c 2 -y 1999-2018 -t jumps
```
##### Date File Mode
Scrape using a file with dates:
```
./rpscrape.py --date-file dates.txt
```
one date per line, format: YYYY/MM/DD.
```
2020/10/01
2020/11/02
2020/12/03
```
##### Searching
List all regions:
```
./rpscrape.py --regions
```
Search regions:
```
./rpscrape.py --regions gb
```
List all courses:
```
./rpscrape.py --courses
```
Search courses:
```
./rpscrape.py --courses Ascot
```
List courses in a region:
```
./rpscrape.py --courses gb
```
##### Settings
The [user_settings.toml](https://github.com/joenano/rpscrape/blob/master/user_settings.toml) file contains the data fields that can be scraped. You can turn fields on and off by setting them true or false. The order of fields in that file will be maintained in the output csv. The [default_settings.toml](https://github.com/joenano/rpscrape/blob/master/default_settings.toml) file should not be edited, its there as a backup and to introduce any new fields without changing user settings.
## Scrape Racecards
You can scrape racecards using racecards.py which saves a file containing a json object of racecard information.
There are only three parameter options, --day N, --days N where N is a number 1-2, and --region N where N is a region (gb, ire, etc).
##### Examples
Scrape today's racecards.
```
./racecards.py --day 1
```
Scrape tomorrow's racecards.
```
./racecards.py --day 2
```
Scrape today's and tomorrow's racecards.
```
./racecards.py --days 2
```
Scrape today's and tomorrow's racecards by region.
```
./racecards.py --days 2 --region gb
```
##### Settings
You can customize which data is included in racecards using the settings file. The scraper uses `settings/user_racecard_settings.toml` if it exists, otherwise falls back to `settings/default_racecard_settings.toml`.
To customize:
1. Copy `default_racecard_settings.toml` to `user_racecard_settings.toml`
2. Edit the settings to enable/disable field groups and data collection options
The settings file lets you control:
- **Data Collection**: Whether to fetch stats and profiles
- **Field Groups**: Which groups of runner fields to include (core, basic_info, performance, jockey, trainer, etc.)
#### Authentication
Credentials are stored in a .env file in the root directory. Make sure .env is added to .gitignore.
```
EMAIL=your@email.com
AUTH_STATE=your_auth_state
ACCESS_TOKEN=your_access_token
```
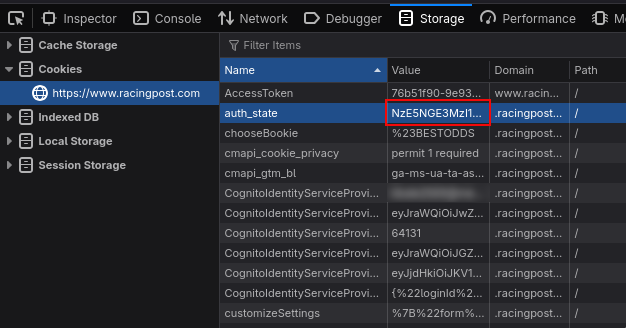
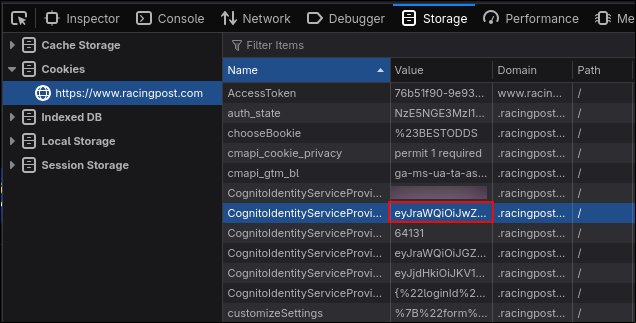
To find your tokens, login to the site and open the cookies section in the storage tab of your browser's developer tools.
You need the values for auth_state and cognito access token (not to be confused with the AccessToken cookie).
There will be multiple keys beginning with `CognitoIdentityServiceProvider`, you want the value for the one that ends with `.accessToken`. It should be directly under email if keys are sorted by name.