https://github.com/johnlui/DIYSearchEngine
🔍 Go 开发的开源互联网搜索引擎,附教程《自己动手开发互联网搜索引擎》
https://github.com/johnlui/DIYSearchEngine
Last synced: about 1 year ago
JSON representation
🔍 Go 开发的开源互联网搜索引擎,附教程《自己动手开发互联网搜索引擎》
- Host: GitHub
- URL: https://github.com/johnlui/DIYSearchEngine
- Owner: johnlui
- Created: 2023-07-01T17:48:26.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-04-07T00:53:07.000Z (about 2 years ago)
- Last Synced: 2024-04-07T02:16:15.966Z (about 2 years ago)
- Language: Go
- Homepage: https://pphc.lvwenhan.com/tech-epic/2023/diy-search-engine
- Size: 4.11 MB
- Stars: 434
- Watchers: 4
- Forks: 67
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Go 开发的开源互联网搜索引擎
DIYSearchEngine 是一个能够高速采集海量互联网数据的开源搜索引擎,采用 Go 语言开发。
> #### 想运行本项目请拉到项目底部,有[教程](#本项目运行方法)。
《两万字教你自己动手开发互联网搜索引擎》
## 写在前面
本文是一篇教你做“合法搜索引擎”的文章,一切都符合《网络安全法》和 robots 业界规范的要求,如果你被公司要求爬一些上了反扒措施的网站,我个人建议你马上离职,我已经知道了好几起全公司数百人被一锅端的事件。
## 《爬乙己》
搜索引擎圈的格局,是和别处不同的:只需稍作一番查考,便能获取一篇又一篇八股文,篇篇都是爬虫、索引、排序三板斧。可是这三板斧到底该怎么用代码写出来,却被作者们故意保持沉默,大抵可能确实是抄来的罢。
从我年方二十,便开始在新浪云计算店担任一名伙计,老板告诉我,我长相过于天真,无法应对那些难缠的云计算客户。这些客户时刻都要求我们的服务在线,每当出现故障,不到十秒钟电话就会纷至沓来,比我们的监控系统还要迅捷。所以过了几天,掌柜又说我干不了这事。幸亏云商店那边要人,无须辞退,便改为专管云商店运营的一种无聊职务了。
我从此便整天的坐在电话后面,专管我的职务。虽然只需要挨骂道歉,损失一些尊严,但总觉得有些无聊。掌柜是一副凶脸孔,主顾也没有好声气,教人活泼不得;只有在午饭后,众人一起散步时闲谈起搜索引擎,才能感受到几许欢笑,因此至今仍深刻铭记在心。
由于谷歌被戏称为“哥”,本镇居民就为当地的搜索引擎取了一个绰号,叫作度娘。
度娘一出现,所有人都笑了起来,有的叫到,“度娘,你昨天又加法律法规词了!”他不回答,对后台说,“温两个热搜,要一碟文库豆”,说着便排出九枚广告。我们又故意的高声嚷道,“你一定又骗了人家的钱了!”度娘睁大眼睛说,“你怎么这样凭空污人清白……”“什么清白?我前天亲眼见你卖了莆田系广告,第一屏全是。”度娘便涨红了脸,额上的青筋条条绽出,争辩道,“广告不能算偷……流量!……互联网广告的事,能算偷么?”接连便是难懂的话,什么“免费使用”,什么“CPM”之类,引得众人都哄笑起来:店内外充满了快活的空气。
## 本文目标
三板斧文章遍地都是,但是真的自己开发出来搜索引擎的人却少之又少,其实,开发一个搜索引擎没那么难,数据量也没有你想象的那么大,倒排索引也没有字面上看着那么炫酷,BM25 算法也没有它的表达式看起来那么夸张,只给几个人用的话也没多少计算压力。
突破自己心灵的枷锁,只靠自己就可以开发一个私有的互联网搜索引擎!
本文是一篇“跟我做”文章,只要你一步一步跟着我做,最后就可以得到一个可以运行的互联网搜索引擎。本文的后端语言采用 Golang,内存数据库采用 Redis,字典存储采用 MySQL,不用费尽心思地研究进程间通信,也不用绞尽脑汁地解决多线程和线程安全问题,也不用自己在磁盘上手搓 B+ 树致密排列,站着就把钱挣了。
## 目录
把大象装进冰箱,只需要三步:
1. 编写高性能爬虫,从互联网上爬取网页
2. 使用倒排索引技术,将网页拆分成字典
3. 使用 BM25 算法,返回搜索结果
## 第一步,编写高性能爬虫,从互联网上爬取网页
Golang 的协程使得它特别适合拿来开发高性能爬虫,只要利用外部 Redis 做好“协程间通信”,你有多少 CPU 核心 go 都可以吃完,而且代码写起来还特别简单,进程和线程都不需要自己管理。当然,协程功能强大,代码简略,这就导致它的 debug 成本很高:我在写协程代码的时候感觉自己像在炼丹,修改一个字符就可以让程序从龟速提升到十万倍,简直比操控 ChatGPT 还神奇。
在编写爬虫之前,我们需要知道从互联网上爬取内容需要遵纪守法,并遵守`robots.txt`,否则,可能就要进去和前辈们切磋爬虫技术了。robots.txt 的具体规范大家可以自行搜索,下面跟着我开搞。
新建 go 项目我就不演示了,不会的可以问一下 ChatGPT~
### 爬虫工作流程
我们先设计一个可以落地的爬虫工作流程。
#### 1. 设计一个 UA
首先我们要给自己的爬虫设定一个 UA,尽量采用较新的 PC 浏览器的 UA 加以改造,加入我们自己的 spider 名称,我的项目叫“Enterprise Search Engine” 简称 ESE,所以我设定的 UA 是 `Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4280.67 Safari/537.36 ESESpider/1.0`,你们可以自己设定。
需要注意的是,部分网站会屏蔽非头部搜索引擎的爬虫,这个需要你们转动聪明的小脑袋瓜自己解决哦。
#### 2. 选择一个爬虫工具库
我选择的是 [PuerkitoBio/goquery](https://github.com/PuerkitoBio/goquery),它支持自定义 UA 爬取,并可以对爬到的 HTML 页面进行解析,进而得到对我们的搜索引擎十分重要的页面标题、超链接等。
#### 3. 设计数据库
爬虫的数据库倒是特别简单,一个表即可。这个表里面存着页面的 URL 和爬来的标题以及网页文字内容。
```sql
CREATE TABLE `pages` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`url` varchar(768) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '网页链接',
`host` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '域名',
`dic_done` tinyint DEFAULT '0' COMMENT '已拆分进词典',
`craw_done` tinyint NOT NULL DEFAULT '0' COMMENT '已爬',
`craw_time` timestamp NOT NULL DEFAULT '2001-01-01 00:00:00' COMMENT '爬取时刻',
`origin_title` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '上级页面超链接文字',
`referrer_id` int NOT NULL DEFAULT '0' COMMENT '上级页面ID',
`scheme` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'http/https',
`domain1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '一级域名后缀',
`domain2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '二级域名后缀',
`path` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'URL 路径',
`query` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'URL 查询参数',
`title` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '页面标题',
`text` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '页面文字',
`created_at` timestamp NOT NULL DEFAULT '2001-01-01 08:00:00' COMMENT '插入时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
```
#### 4. 给爷爬!
爬虫有一个极好的特性:自我增殖。每一个网页里,基本都带有其他网页的链接,这样我们就可以道生一,一生二,二生三,三生万物了。
此时,我们只需要找一个导航网站,手动把该网站的链接插入到数据库里,爬虫就可以开始运作了。各位可以自行挑选可口的页面链接服用。
我们正式进入实操阶段,以下都是可以运行的代码片段,代码逻辑在注释里面讲解。
我采用`joho/godotenv`来提供`.env`配置文件读取的能力,你需要提前准备好一个`.env`文件,并在里面填写好可以使用的 MySQL 数据库信息,具体可以参考项目中的`.env.example`文件。
```go
func main() {
fmt.Println("My name id enterprise-search-engine!")
// 加载 .env
initENV() // 该函数的具体实现可以参考项目代码
// 开始爬
nextStep(time.Now())
// 阻塞,不跑爬虫时用于阻塞主线程
select {}
}
// 循环爬
func nextStep(startTime time.Time) {
// 初始化 gorm 数据库
dsn0 := os.Getenv("DB_USERNAME0") + ":" +
os.Getenv("DB_PASSWORD0") + "@(" +
os.Getenv("DB_HOST0") + ":" +
os.Getenv("DB_PORT0") + ")/" +
os.Getenv("DB_DATABASE0") + "?charset=utf8mb4&parseTime=True&loc=Local"
gormConfig := gorm.Config{}
db0, _ := gorm.Open(mysql.Open(dsn0), &gormConfig)
// 从数据库里取出本轮需要爬的 100 条 URL
var pagesArray []models.Page
db0.Table("pages").
Where("craw_done", 0).
Order("id").Limit(100).Find(&pagesArray)
tools.DD(pagesArray) // 打印结果
// 限于篇幅,下面用文字描述
1. 循环展开 pagesArray
2. 针对每一个 page,使用 curl 工具类获取网页文本
3. 解析网页文本,提取出标题和页面中含有的超链接
4. 将标题、一级域名后缀、URL 路径、插入时间等信息补充完全,更新到这一行数据上
5. 将页面上的超链接插入 pages 表,我们的网页库第一次扩充了!
fmt.Println("跑完一轮", time.Now().Unix()-startTime.Unix(), "秒")
nextStep(time.Now()) // 紧接着跑下一条
}
```

我已经事先将 hao123 的链接插入了 pages 表,所以我运行`go build -o ese *.go && ./ese`命令之后,得到了如下信息:
```ruby
My name id enterprise-search-engine!
加载.env : /root/enterprise-search-engine/.env
APP_ENV: local
[[{1 0 https://www.hao123.com 0 0 2001-01-01 00:00:00 +0800 CST 2001-01-01 08:00:00 +0800 CST 0001-01-01 00:00:00 +0000 UTC}]]
```

《递龟》
上面的代码中,我们第一次用到了~~递龟~~递归:自己调用自己。
#### 5. 合法合规:遵守 robots.txt 规范
我选择用`temoto/robotstxt`这个库来探查我们的爬虫是否被允许爬取某个 URL,使用一张单独的表来存储每个域名的 robots 规则,并在 Redis 中建立缓存,每次爬取 URL 之前,先进行一次匹配,匹配成功后再爬,保证合法合规。
### 制造真正的生产级爬虫
《怎样画马》
有了前面这个理论上可以运行的简单爬虫,下面我们就要给这匹马补充亿点细节了:生产环境中,爬虫性能优化是最重要的工作。
从某种程度上来说,搜索引擎的优劣并不取决于搜索算法的优劣,因为算法作为一种“特定问题的简便算法”,一家商业公司比别家强的程度很有限,搜索引擎的真正优劣在于哪家能够以最快的速度索引到互联网上层出不穷的新页面和已经更新过内容的旧页面,在于哪家能够识别哪个网页是价值最高的网页。
识别网页价值方面,李彦宏起家的搜索专利,以及谷歌大名鼎鼎的 PageRank 都拥有异曲同工之妙。但本文的重点不在这个领域,而在于技术实现。让我们回到爬虫性能优化,为什么性能优化如此重要呢?我们构建的是互联网搜索引擎,需要爬海量的数据,因此我们的爬虫需要足够高效:中文互联网有 400 万个网站,3500 亿个网页,哪怕只爬千分之一,3.5 亿个网页也不是开玩笑的,如果只是单线程阻塞地爬,消耗的时间恐怕要以年为单位了。
爬虫性能优化,我们首先需要规划一下硬件。
#### 硬件要求
首先计算磁盘空间,假设一个页面 20KB,在不进行压缩的情况下,一亿个页面就需要 `20 * 100000000 / 1024 / 1024 / 1024 = 1.86TB` 的磁盘空间,而我们打算使用 MySQL 来存储页面文本,需要的空间会更大一点。
我的爬虫花费了 2 个月的时间,爬到了大约 1 亿个 URL,其中 3600 万个爬到了页面的 HTML 文本存在了数据库里,共消耗了超过 600GB 的磁盘空间。
除了硬性的磁盘空间,剩下的就是尽量多的 CPU 核心数和内存了:CPU 拿来并发爬网页,内存拿来支撑海量协程的消耗,外加用 Redis 为爬虫提速。爬虫阶段对内存的要求还不大,但在后面第二步拆分字典的时候,大内存容量的 Redis 将成为提速利器。
所以,我们对硬件的需求是这样的:一台核心数尽量多的物理机拿来跑我们的 ese 二进制程序,外加高性能数据库(例如16核64GB内存,NVME磁盘),你能搞到多少台数据库就准备多少台,就算你搞到了 65536 台数据库,也能跑满,理论上我们可以无限分库分表。能这么搞是因为网页数据具有离散性,相互之间的关系在爬虫和字典阶段还不存在,在查询阶段才比较重要。
顺着这个思路,有人可能就会想,我用 KV 数据库例如 MongoDB 来存怎么样呢?当然是很好的,但是MongoDB 不适合干的事情实在是太多啦,所以你依然需要 Redis 和 MySQL 的支持,如果你需要爬取更大规模的网页,可以把 MongoDB 用起来,利用进一步推高系统复杂度的方式获得一个显著的性能提升。
下面我们开始进行软件优化,我只讲述关键步骤,各位有什么不明白的地方可以参考项目代码。
#### 重用 HTTP 客户端以防止内存泄露
这个点看起来很小,但当你瞬间并发数十万协程的时候,每个协程 1MB 的内存浪费累积起来都是巨大的,很容易造成 OOM。
我们在 tools 文件夹下创建`curl.go`工具类,专门用来存放[全局 client](https://req.cool/zh/docs/tutorial/best-practices/#%e9%87%8d%e7%94%a8-client) 和 curl 工具函数:
```go
package tools
import ... //省略,具体可以参考项目代码
// 全局重用 client 对象,4 秒超时,不跟随 301 302 跳转
var client = req.C().SetTimeout(time.Second * 4).SetRedirectPolicy(req.NoRedirectPolicy())
// 返回 document 对象和状态码
func Curl(page models.Page, ch chan int) (*goquery.Document, int) {
... //省略,具体可以参考项目代码
}
```
#### 基础知识储备:goroutine 协程
我默认你已经了解 go 协程是什么了,它就是一个看起来像魔法的东西。在这里我提供一个理解协程的小诀窍:每个协程在进入磁盘、网络等“只需要后台等待”的任务之后,会把当前 CPU 核心(可以理解成一个图灵机)的指令指针 goto 到下一个协程的起始。
需要注意的是,协程是一种特殊的并发形式,你在并发函数内调用的函数必须都支持并发调用,类似于传统的“线程安全”,如果你一不小心写了不安全的代码,轻则卡顿,重则 crash。
#### 一次取出一批需要爬的 URL,使用协程并发爬
协程代码实操来啦!
```go
// tools.DD(pagesArray) // 打印结果
// 创建 channel 数组
chs := make([]chan int, len(pagesArray))
// 展开 pagesArray 数组
for k, v := range pagesArray {
// 存储 channel 指针
chs[k] = make(chan int)
// 阿瓦达啃大瓜!!
go craw(v, chs[k], k)
}
// 注意,下面的代码不可省略,否则你上面 go 出来的那些协程会瞬间退出
var results = make(map[int]int)
for _, ch := range chs {
// 神之一手,收集来自协程的返回数据,并 hold 主线程不瞬间退出
r := <-ch
_, prs := results[r]
if prs {
results[r] += 1
} else {
results[r] = 1
}
}
// 当代码执行到这里的时候,说明所有的协程都已经返回数据了
fmt.Println("跑完一轮", time.Now().Unix()-startTime.Unix(), "秒")
```
`craw`函数协程化:
```go
// 真的爬,存储标题,内容,以及子链接
func craw(status models.Page, ch chan int, index int) {
// 调用 CURL 工具类爬到网页
doc, chVal := tools.Curl(status, ch)
// 对 doc 的处理在这里省略
// 最重要的一步,向 chennel 发送 int 值,该动作是协程结束的标志
ch <- chVal
return
}
```
协程优化做完了,CPU 被吃满了,接下来数据库要成为瓶颈了。
### MySQL 性能优化
做到这里,在做普通业务逻辑的时候非常快的 MySQL 已经是整个系统中最慢的一环了:pages 表一天就要增加几百万行,MySQL 会以肉眼可见的速度慢下来。我们要对 MySQL 做性能优化。
#### 何以解忧,唯有索引
首先,收益最大的肯定是加索引,这句话适用于 99% 的场景。
在你磁盘容量够用的情况下,加索引通常可以获得数百倍到数万倍的性能提升。我们先给 url 加个索引,因为我们每爬到一个 URL 都要查一下它是否已经在表里面存在了,这个动作的频率是非常高的,如果我们最终爬到了一亿个页面,那这个对比动作至少会做百亿次。
#### 部分场景下很好用的分库分表
非常幸运,爬虫场景和分库分表非常契合:只要我们能根据 URL 将数据均匀地分散开,不同的 URL 之间是没有多少关系的。那我们该怎么将数据分散开呢?使用散列值!
每一个 URL 在 MD5 之后,都会得到一个形如`698d51a19d8a121ce581499d7b701668`的 32 位长度的 16 进制数。而这些数字在概率上是均等的,所以理论上我们可以将数亿个 URL 均匀分布在多个库的多个表里。下面问题来了,该怎么分呢?
#### 只有一台数据库,应该分表吗?
如果你看过我的[《高并发的哲学原理(八)-- 将 InnoDB 剥的一丝不挂:B+ 树与 Buffer Pool
》](https://lvwenhan.com/tech-epic/506.html)的话,就会明白,只要你能接受分表的逻辑代价,那在任何大数据量场景下分表都是有明显收益的,因为随着表容量的增加,那棵 16KB 页块组成的 B+ 树的复杂度增加是超线性的,用牛逼的话说就是:二阶导数持续大于 0。此外,缓存也会失效,你的 MySQL 运行速度会降低到一个令人发指的水平。
所以,即便你只有一台数据库,那也应该分表。如果你的磁盘是 NVME,我觉得单机拿出 MD5 的前两位数字,分出来 16 x 16 = 256 个表是比较不错的。
当然,如果你能搞到 16 台数据库服务器,那拿出第一位 16 进制数字选定物理服务器,再用二三位数字给每台机器分 256 个表也是极好的。
#### 我的真实硬件和分表逻辑
由于我司比较节俭~~贫穷~~,机房的服务器都是二手的,实在是拿不出高性能的 NVME 服务器,于是我找 IT 借了两台 ThinkBook 14 寸笔记本装上了 CentOS Stream 9:
1. 把内存扩充到最大,形成了 8GB 板载 + 32GB 内存条一共 40GB 的奇葩配置
2. CPU 是 AMD Ryzen 5 5600U,虽然是低压版的 CPU,只有六核十二线程,但是也比 Intel 的渣渣 CPU 快多了(Intel:牙膏真的挤完了,一滴都没有了)
3. 磁盘就用自带的 500GB NVME,实测读写速度能跑到 3GB/2GB,十分够用
由于单台机器只有 6 核,我就各给他们分了 128 个表,在每次要执行 SQL 之前,我会先用 URL 作为参数获取一下它对应的数据库服务器和表名。表名获取逻辑如下:
1. 计算此 URL 的 MD5 散列值
2. 取前两位十六进制数字
3. 拼接成类似`pages_0f`样子的表名
```go
tableName := table + "_" + tools.GetMD5Hash(url)[0:2]
```
### 爬虫数据流和架构优化
上面我们已经使用协程把 CPU 全部利用起来了,又使用分库分表技术把数据库硬件全部利用起来了,但是如果你这个时候直接用上面的代码开始跑,会发现速度还是不够快:因为某些工作 MySQL 还是不擅长做。
此时,我们就需要对数据流和架构做出优化了。
#### 拆分仓库表和状态表
原始的 pages 表有 16 个字段,在我们爬的过程中,只用得到五个:`id` `url` `host` `craw_done` `craw_time`。而看过我上面的 InnoDB 文章的小伙伴还知道,在页面 HTML 被填充进`text`字段之后,pages 表的 16KB 页块会出现频繁的调整和指针的乱飞,对 InnoDB 的“局部性”性能涡轮的施展非常不利,会造成 buffer pool 的频繁失效。
所以,为了爬的更快,为 pages 表打造一个性能更强的“影子”就十分重要。于是,我为`pages_0f`表打造了只包含上面五个字段的`status_0f`兄弟表,数据从 pages 表里面复制而来,承担一些频繁读写任务:
1. 检查 URL 是否已经在库,即如果以前别的页面上已经出现了这个 URL 了,本次就不需要再入库了
2. 找出下一批需要爬的页面,即`craw_done=0`的 URL
3. craw_time 承担日志的作用,用于统计过去一段时间的爬虫效率
除了这些高频操作,存储页面 HTML 和标题等信息的低频操作是可以直接入`paqes_0f`仓库表的。
#### 实时读取 URL 改为后台定时读取
随着单表数据量的逐渐提升,每一轮开始时从数据库里面批量读出需要爬的 URL 成了一个相对耗时的操作,即便每张表只需要 500ms,那轮询 256 张表总耗时也达到了 128 秒之多,这是无法接受的,所以这个流程也需要异步化。你问为什么不异步同时读取 256 张表?因为 MySQL 最宝贵的就是连接数,这样会让连接数直接爆掉,大家都别玩了,关于连接数我们下面还会有提及。
我们把流程调整一下:每 20 秒从 status 表中搜罗一批需要爬的 URL 放进 Redis 中积累起来,爬的时候直接从 Redis 中读一批。这么做是为了把每一秒的时间都利用起来,尽力填满协程爬虫的胃口。
```go
// 在 main() 中注册定时任务
c := cron.New(cron.WithSeconds())
// 每 20 秒执行一次 prepareStatusesBackground 函数
c.AddFunc("*/20 * * * * *", prepareStatusesBackground)
go c.Start()
// prepareStatusesBackground 函数中,使用 LPush 向有序列表的头部插入 URL
for _, v := range _statusArray {
taskBytes, _ := json.Marshal(v)
db.Rdb.LPush(db.Ctx, "need_craw_list", taskBytes)
}
// 每一轮都使用 RPop 从有序列表的尾部读取需要爬的 URL
var statusArr []models.Status
maxNumber := 1 // 放大倍数,控制每一批的 URL 数量
for i := 0; i < 256*maxNumber; i++ {
jsonString := db.Rdb.RPop(db.Ctx, "need_craw_list").Val()
var _status models.Status
err := json.Unmarshal([]byte(jsonString), &_status)
if err != nil {
continue
}
statusArr = append(statusArr, _status)
}
```
#### 十分重要的爬虫压力管控
过去十年,中国互联网每次有搜索引擎新秀崛起,我都要被新爬虫 DDOS 一遍,想想就气。这帮大厂的菜鸟程序员,以为随便一个网站都能承受住 2000 QPS,实际上互联网上 99.9% 网站的极限 QPS 到不了 100,超过 10 都够呛。对了,如果有 YisouSpider 的人看到本文,请回去推动一下你们的爬虫优化,虽然你们的爬虫不会持续高速爬取,但是你们在每分钟的第一秒并发 10 个请求的方法更像是 DDOS,对系统的危害更大...
我们要像谷歌那样,做一个压力均匀的文明爬虫,这就需要我们把每一个域名的爬虫频率都记录下来,并实时进行调整。我基于 Redis 和每个 URL 的 host 做了一个计数器,在每次真的要爬某个 URL 之前,调用一次检测函数,看是否对单个域名的爬虫压力过大。
此外,由于我们的 craw 函数是协程调用的,此时 Redis 就显得更为重要了:它能提供宝贵的“线程安全数据读写”功能,如果你也是`sync.Map`的受害者,我相信你一定懂我😭
> #### 我认为,单线程的 Redis 是 go 协程最佳的伙伴,就像 PHP 和 MySQL 那样。
具体代码我就不放了,有需要的同学可以自己去看项目代码哦。
#### 疯狂使用 Redis 加速频繁重复的数据库调用
我们使用协程高速爬到数据了,下一步就是存储这些数据。这个操作看起来很简单,更新一下原来那一行,再插入 N 行新数据不就行了吗,其实不行,还有一个关键步骤需要使用 Redis 来加速:新爬到的 URL 是否已经在数据库里存在了。这个操作看起来简单,但在我们解决了上面这些性能问题以后,庞大的数量就成了这一步最大的问题,每一次查询会越来越慢,查询字数还特别多,这谁顶得住。
如果我们拿 Redis 来存 URL,岂不是需要把所有 URL 都存入 Redis 吗,这内存需求也太大了。这个时候,我们的老朋友,`局部性`又出现了:由于我们的爬虫是按照顺序爬的,那“朋友的朋友也是朋友”的概率是很大的,所以我们只要在 Redis 里记录一下某条 URL 是否存在,那之后一段时间,这个信息被查到的概率也很大:
```go
// 我们使用一个 Hash 来存储 URL 是否存在的状态
statusHashMapKey := "ese_spider_status_exist"
statusExist := db.Rdb.HExists(db.Ctx, statusHashMapKey, _url).Val()
// 若 HashMap 中不存在,则查询或插入数据库
if !statusExist {
··· 代码省略,不存在则创建这行 page,存在则更新信息 ···
// 无论是否新插入了数据,都将 _url 入 HashMap
db.Rdb.HSet(db.Ctx, statusHashMapKey, _url, 1).Err()
}
```
这段代码看似简单,实测非常好用,唯一的问题就是不能运行太长时间,隔一段时间得清空一次,因为随着时间的流逝,局部性会越来越差。
细心的小伙伴可能已经发现了,既然爬取状态已经用 Redis 来承载了,那还需要区分 pages 和 status 表吗?需要,因为 Redis 也不是全能的,它的基础数据依然是来自 MySQL 的。目前这个架构类似于复杂的三级火箭,看起来提升没那么大,但这小小的提速可能就能让你爬三亿个网页的时间从 3 个月缩减到 1 个月,是非常值的。
另外,如果通过扫描 256 张表中 craw_time 字段的方式来统计“过去 N 分钟爬了多少个 URL、有效页面多少个、因为爬虫压力而略过的页面多少个、网络错误的多少个、多次网络错误后不再重复爬取的多少个”的数据,还是太慢了,也太消耗资源了,这些统计信息也需要使用 Redis 来记录:
```go
// 过去一分钟爬到了多少个页面的 HTML
allStatusKey := "ese_spider_all_status_in_minute_" + strconv.Itoa(int(time.Now().Unix())/60)
// 计数器加 1
db.Rdb.IncrBy(db.Ctx, allStatusKey, 1).Err()
// 续命 1 小时
db.Rdb.Expire(db.Ctx, allStatusKey, time.Hour).Err()
// 过去一分钟从新爬到的 HTML 里面提取出了多少个新的待爬 URL
newStatusKey := "ese_spider_new_status_in_minute_" + strconv.Itoa(int(time.Now().Unix())/60)
// 计数器加 1
db.Rdb.IncrBy(db.Ctx, newStatusKey, 1).Err()
// 续命 1 小时
db.Rdb.Expire(db.Ctx, newStatusKey, time.Hour).Err()
```
### 生产爬虫遇到的其他问题
在我们不断提高爬虫速度的过程中,爬虫的复杂度也在持续上升,我们会遇到玩具爬虫遇不到的很多问题,接下来我分享一下我的处理经验。
#### 抑制暴增的数据库连接数
在协程这个大杀器的协助之下,我们可以轻易写出超高并行的代码,把 CPU 全部吃完,但是,并行的协程多了以后,数据库的连接数压力也开始暴增。MySQL 默认的最大连接数只有 151,根据我的实际体验,哪怕是一个协程一个连接,我们这个爬虫也可以轻易把连接数干到数万,这个数字太大了,即便是最新的 CPU 加上 DDR5 内存,受制于 MySQL 算法的限制,在连接数达到这个级别以后,处理海量连接数所需要的时间也越来越多。这个情况和[《高并发的哲学原理(二)-- Apache 的性能瓶颈与 Nginx 的性能优势》](https://lvwenhan.com/tech-epic/500.html)一文中描述的 Apache 的 prefork 模式比较像。好消息是,最近版本的 MySQL 8 针对连接数匹配算法做了优化,大幅提升了大量连接数下的性能。
除了协程之外,分库分表对连接数的的暴增也负有不可推卸的责任。为了提升单条 SQL 的性能,我们给单台数据库服务器分了 256 张表,这种情况下,以前的一个连接+一条 SQL 的状态会突然增加到 256 个连接和 256 条 SQL,如果我们不加以限制的话,可以说协程+分表一启动,你就一定会收到海量的`Too many connections`报错。我的解决方法是,在 gorm 初始化的时候,给他设定一个“单线程最大连接数”:
```go
dbdb0, _ := _db0.DB()
dbdb0.SetMaxIdleConns(1)
dbdb0.SetMaxOpenConns(100)
dbdb0.SetConnMaxLifetime(time.Hour)
```
根据我的经验,100 个够用了,再大的话,你的 TCP 端口就要不够用了。
#### 域名黑名单
我们都知道,内容农场是一种专门钻搜索引擎空子的垃圾内容生产者,爬虫很难判断哪些网站是内容农场,但是人一点进去就能判断出来。而这些域名的内部链接做的又特别好,这就导致我们需要手动给一些恶心的内容农场域名加黑名单。我们把爬到的每个域名下的 URL 数量统计一下,搞一个动态的排名,就能很容易发现头部的内容农场域名了。
#### 复杂的失败处理策略
> 生产代码和教学代码最大的区别就是成吨的错误处理!—— John·Lui(作者自己)
如果你真的要搞一个涵盖数亿页面的可以用的搜索引擎,你会碰到各种各样的奇葩失败,这些失败都需要拿出特别的处理策略,下面我分享一下我遇到过的问题和我的处理策略。
1. 单页面超时非常重要:如果你想尽可能地在一段时间内爬到尽量多的页面的话,缩短你 curl 的超时时间非常重要,经过摸索,我把这个时间设定到了 4 秒,既能爬到绝大多数网页,也不会浪费时间在一些根本就无法响应的 URL 上。
2. 单个 URL 错误达到一定数量以后,需要直接拉黑,不然一段时间后,你的爬虫整天就只爬那些被无数次爬取失败的 URL 上啦,一个新页面也爬不到。这个次数我设定的是 3 次。
3. 如果某个 URL 返回的 HTML 无法被解析,果断放弃,没必要花费额外资源重新爬。
4. 由于我们的数据流已经是三级火箭形态,所以在各种地方加上“动态锁”就很必要,因为很多时候我们需要手动让其他级火箭发动机暂停运行,手动检修某一级发动机。我一般拿 MySQL 来做这件事,创建一个名为`kvstores`的表,只有 key value 两个字段,需要的时候我会手动修改特定 key 对应的 value 值,让某一级发动机暂停一下。
5. 由于 curl 的结果具有不确定性,务必需要保证任何情况下,都要给 channel 返回信号量,不然你的整个应用会直接卡死。
6. 一个页面内经常会有同一个超链接重复出现,在内存里保存已经见过的 URL 并跳过重复值可以显著节约时间。
7. 我建了一个 MySQL 表来存储我手动插入的黑名单域名,这个非常好用,可以在爬虫持续运行的时候随时“止损”,停止对黑名单域名的新增爬取。
至此,我们的爬虫终于构建完成了。
### 爬虫运行架构图
现在我们的爬虫运行架构图应该是下面这样的:
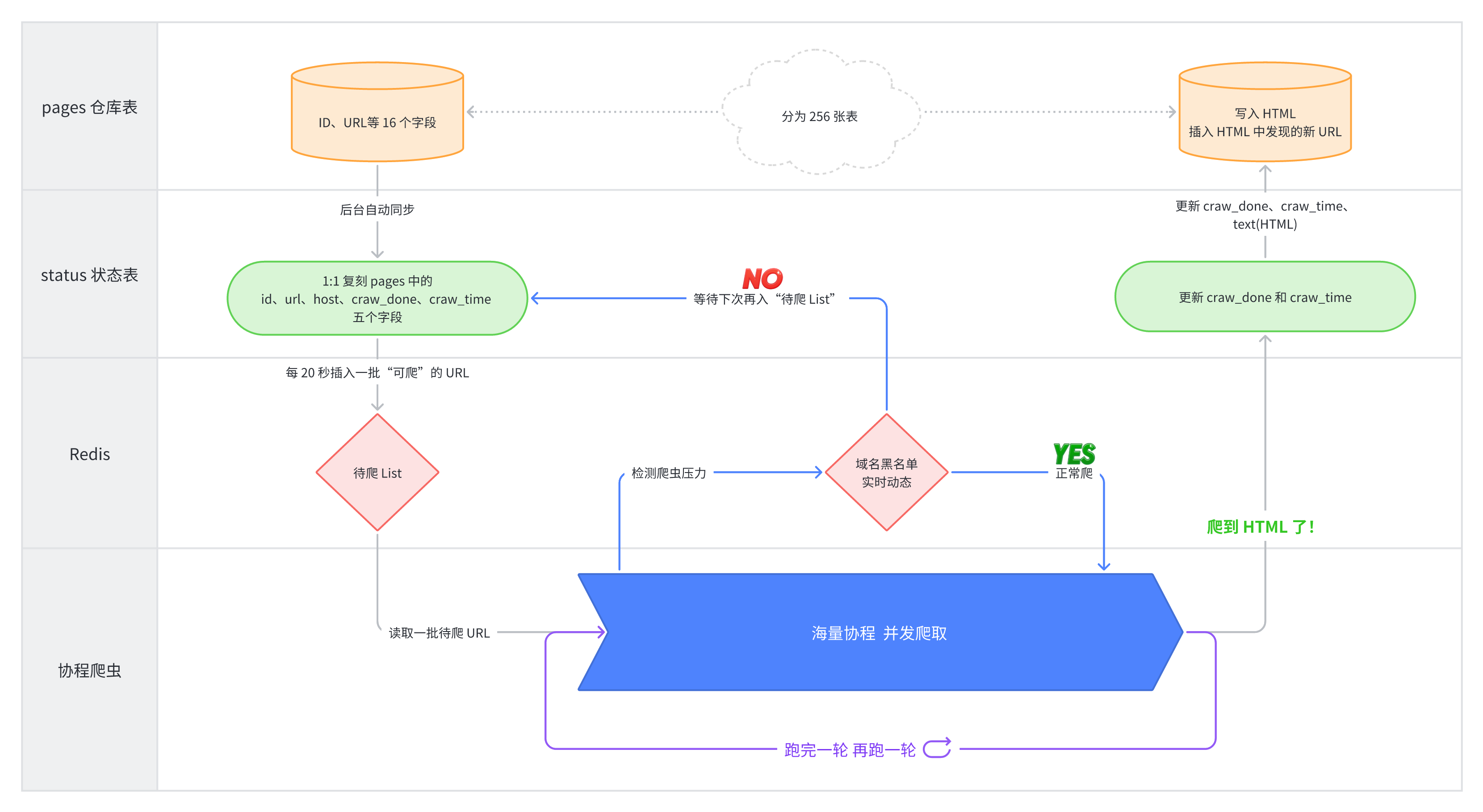
爬虫搞完了,让我们进入第二大部分。
## 第二步,使用倒排索引生成字典
那个~~男人~~一听就很牛逼的词出现了:倒排索引。
对于没搞过倒排索引的人来说,这个词听起来和“生态化反”一样牛逼,其实它非常简单,简单程度堪比 HTTP 协议。
### 倒排索引到底是什么
下面这个例子可以解释倒排索引是个什么东西:
1. 我们有一个表 titles,含有两个字段,ID 和 text,假设这个表有 100 行数据,其中第一行 text 为“爬虫工作流程”,第二行为“制造真正的生产级爬虫”
2. 我们对这两行文本进行分词,第一行可以得到“爬虫”、“工作”、“流程”三个词,第二行可以得到“制造”、“真正的”、“生产级”、“爬虫”四个词
3. 我们把顺序颠倒过来,以词为 key,以①`titles.id` ②`,` ③`这个词在 text 中的位置` 这三个元素拼接在一起为一个`值`,不同 text 生成的`值`之间以 - 作为间隔,对数据进行“反向索引”,可以得到:
1. 爬虫: 1,0-2,8
2. 工作:1,2
3. 流程:1,4
4. 制造:2,0
5. 真正的:2,2
6. 生产级:2,5
倒排索引完成了!就是这么简单。说白了,就是把所有内容都分词出来,再反向给每个词标记出“他出现在哪个文本的哪个位置”,没了,就是这么简单。下面是我生成的字典中,“辰玺”这个词的字典值:
```text
110,85,1,195653,7101-66,111,1,195653,7101-
```
你问为什么我不找个常见的词?因为随便一个常见的词,它的字典长度都是以 MB 为单位的,根本没法放出来...
#### 还有一个牛逼的词,最小完美哈希,可以用来排布字典数据,加快搜索速度,感兴趣的同学可以自行学习
### 生成倒排索引数据
理解了倒排索引是什么以后,我们就可以着手把我们爬到的 HTML 处理成倒排索引了。
我使用`yanyiwu/gojieba`这个库来调用结巴分词,按照以下步骤对我爬到的每一个 HTML 文本进行分词并归类:
1. 分词,然后循环处理这些词:
2. 统计词频:这个词在该 HTML 中出现的次数
3. 记录下这个词在该 HTML 中每一次出现的位置,从 0 开始算
4. 计算该 HTML 的总长度,搜索算法需要
5. 按照一定格式,组装成倒排索引值,形式如下:
```go
// 分表的顺序,例如 0f 转为十进制为 15
strconv.Itoa(i) + "," +
// pages.id 该 URL 的主键 ID
strconv.Itoa(int(pages.ID)) + "," +
// 词频:这个词在该 HTML 中出现的次数
strconv.Itoa(v.count) + "," +
// 该 HTML 的总长度,BM25 算法需要
strconv.Itoa(textLength) + "," +
// 这个词出现的每一个位置,用逗号隔开,可能有多个
strings.Join(v.positions, ",") +
// 不同 page 之间的间隔符
"-"
```
我们按照这个规则,把所有的 HTML 进行倒排索引,并且把生成的索引值拼接在一起,存入 MySQL 即可。
### 使用协程 + Redis 大幅提升词典生成速度
不知道大家感受到了没有,词典的生成是一个比爬虫高几个数量级的 CPU 消耗大户,一个 HTML 动辄几千个词,如果你要对数亿个 HTML 进行倒排索引,需要的计算量是非常惊人的。我爬到了 3600 万个页面,但是只处理了不到 800 万个页面的倒排索引,因为我的计算资源也有限...
并且,把词典的内容存到 MySQL 里难度也很大,因为一些常见词的倒排索引会巨长,例如“没有”这个词,真的是到处都有它。那该怎么做性能优化呢?还是我们的老朋友,协程和 Redis。
#### 协程分词
两个 HTML 的分词工作之间完全没有交集,非常适合拿协程来跑。
但是,MySQL 举手了:我顶不住。所以协程的好朋友 Redis 也来了。
#### 使用 Redis 做为词典数据的中转站
我们在 Redis 中针对每一个词生成一个 List,把倒排出来的索引插入到尾部:
```go
db.Rdb10.RPush(db.Ctx, word, appendSrting)
```
#### 使用协程从 Redis 搬运数据到 MySQL 中
你没看错,这个地方也需要使用协程,因为数据量实在是太大了,一个线程循环跑会非常慢。经过我的不断尝试,我发现每次转移 2000 个词,对 Redis 的负载比较能够接受,E5-V4 的 CPU 单核能够跑满,带宽大概 400Mbps。
从 Redis 到 MySQL 的高性能搬运方法如下:
1. 随机获取一个 key
2. 判断该 key 的长度,只有大于等于 2 的进入下一步
3. 把最后一个索引值留下,前面的元素一个一个`LPop`(弹出头部)出来,拼接在一起
4. 汇集一批 2000 个随机词的结果,append 到数据库该词现有索引值的后面
有了协程和 Redis 的协助,分词加倒排索引的速度快了起来,但是如果你选择一个词一个词地 append 值,你会发现 MySQL 又双叒叕变的超慢,又要优化 MySQL 了!🙊
### 事务的妙用:MySQL 高速批量插入
由于需要往磁盘里写东西,所以只要是一个一个 update,怎么优化都会很慢,那有没有一次性 update 多行数据的方法呢?有!那就是事务:
```go
tx.Exec(`START TRANSACTION`)
// 需要批量执行的 update 语句
for w, s := range needUpdate {
tx.Exec(`UPDATE word_dics SET positions = concat(ifnull(positions,''), ?) where name = ?`, s, w)
}
tx.Exec(`COMMIT`)
```
这么操作,字典写入速度一下子起来了。但是,每次执行 2000 条 update 语句对磁盘的要求非常高,我进行这个操作的时候,可以把磁盘写入速度瞬间提升到 1.5GB/S,如果你的数据库存储不够快,可以减少语句数量。
### 世界的参差:无意义的词
这个世界上的东西并不都是有用的,一个 HTML 中的字符也是如此。
首先,一般不建议索引整个 HTML,而是把他用 DOM 库处理一下,提取出文本内容,再进行索引。
其次,即便是你已经过滤掉了所有的 html 标签、css、js 代码等,还是有些词频繁地出现:它们出现的频率如此的高,以至于反而失去了作为搜索词的价值。这个时候,我们就需要把他们狠狠地拉黑,不处理他们的倒排索引。我使用的黑名单词如下,表名为`word_black_list`,只有两个字段 id、word,需要的自取:
```ruby
INSERT INTO `word_black_list` (`id`, `word`)
VALUES
(1, 'px'),
(2, '20'),
(3, '('),
(4, ')'),
(5, ','),
(6, '.'),
(7, '-'),
(8, '/'),
(9, ':'),
(10, 'var'),
(11, '的'),
(12, 'com'),
(13, ';'),
(14, '['),
(15, ']'),
(16, '{'),
(17, '}'),
(18, '\''),
(19, '\"'),
(20, '_'),
(21, '?'),
(22, 'function'),
(23, 'document'),
(24, '|'),
(25, '='),
(26, 'html'),
(27, '内容'),
(28, '0'),
(29, '1'),
(30, '3'),
(31, 'https'),
(32, 'http'),
(33, '2'),
(34, '!'),
(35, 'window'),
(36, 'if'),
(37, '“'),
(38, '”'),
(39, '。'),
(40, 'src'),
(41, '中'),
(42, '了'),
(43, '6'),
(44, '。'),
(45, '<'),
(46, '>'),
(47, '联系'),
(48, '号'),
(49, 'getElementsByTagName'),
(50, '5'),
(51, '、'),
(52, 'script'),
(53, 'js');
```
至此,字典的处理告一段落,下面让我们一起 Just 搜 it!
## 第三步,使用 BM25 算法给出搜索结果
网上关于 BM25 算法的文章是不是看起来都有点懵?别担心,看完下面这段文字,我保证你能自己写出来这个算法的具体实现,这种有具体文档的工作是最好做的了,比前面的性能优化简单多了。
### 简单介绍一下 BM25 算法
BM25 算法是现代搜索引擎的基础,它可以很好地反映一个词和一堆文本的相关性。它拥有不少独特的设计思想,我们下面会详细解释。
这个算法第一次被生产系统使用是在 1980 年代的伦敦城市大学,在一个名为 Okapi 的信息检索系统中被实现出来,而原型算法来自 1970 年代 Stephen E. Robertson、Karen Spärck Jones 和他们的同伴开发的概率检索框架。所以这个算法也叫 Okapi BM25,这里的 BM 代表的是`best matching`(最佳匹配),非常实在,和比亚迪的“美梦成真”有的一拼(Build Your Dreams)😂
### 详细讲解 BM25 算法数学表达式的含义
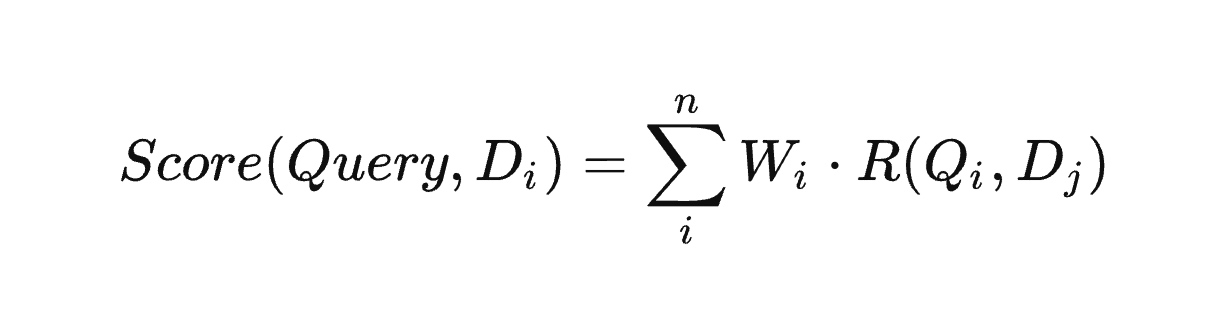
我简单描述一下这个算法的含义。
首先,假设我们有 100 个页面,并且已经对他们分词,并全部生成了倒排索引。此时,我们需要搜索这句话“BM25 算法的数学描述”,我们就需要按照以下步骤来计算:
1. 对“BM25 算法的数学描述”进行分词,得到“BM25”、“算法”、“的”、“数学”、“描述”五个词
2. 拿出这五个词的全部字典信息,假设包含这五个词的页面一共有 50 个
3. 逐个计算这五个词和这 50 个页面的`相关性权重`和`相关性得分`的乘积(当然,不是每个词都出现在了这 50 个网页中,有多少算多少)
4. 把这 50 页面的分数分别求和,再倒序排列,即可以获得“BM25 算法的数学描述”这句话在这 100 个页面中的搜索结果
`相关性权重`和`相关性得分`名字相似,别搞混了,它们的具体定义如下:
#### 某个词和包含它的某个页面的“相关性权重”
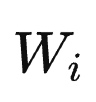
上图中的`Wi`指代的就是相关性权重,最常用的是`TF-IDF`算法中的`IDF`权重计算法:
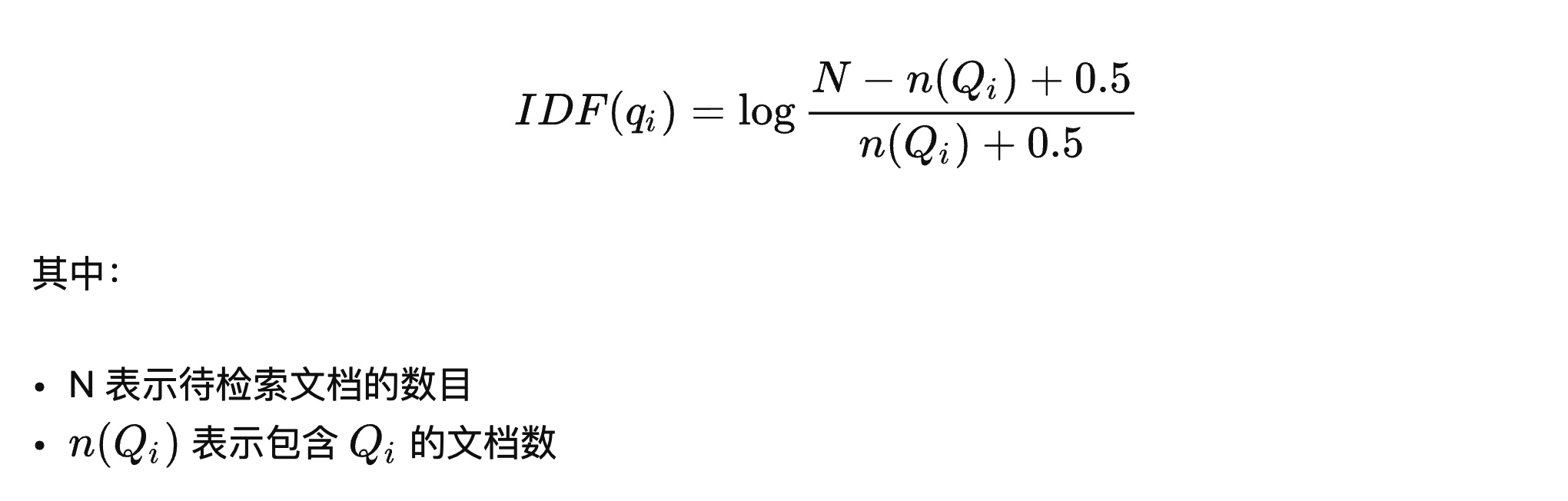
这里的 N 指的是页面总数,就是你已经加入字典的页面数量,需要动态扫描 MySQL 字典,对我来说就是 784 万。而`n(Qi)`就是这个词的字典长度,就是含有这个词的页面有多少个,就是我们字典值中`-`出现的次数。
这个参数的现实意义是:如果一个词在很多页面里面都出现了,那说明这个词不重要,例如百分百空手接白刃的“的”字,哪个页面都有,说明这个词不准确,进而它就不重要。
词以稀为贵。
我的代码实现如下:
```go
// 页面总数
db.DbInstance0.Raw("select count(*) from pages_0f where dic_done = 1").Scan(&N)
N *= 256
// 字典的值中`-`出现的次数
NQi := len(partsArr)
// 得出相关性权重
IDF := math.Log10((float64(N-NQi) + 0.5) / (float64(NQi) + 0.5))
```
#### 某个词和包含它的某个页面的“相关性得分”

这个表达式看起来是不是很复杂,但是它的复杂度是为了处理查询语句里面某一个关键词出现了多次的情况,例如“八百标兵奔北坡,炮兵并排北边跑。炮兵怕把标兵碰,标兵怕碰炮兵炮。”,“炮兵”这个词出现了 3 次。为了能快速实现一个能用的搜索引擎,我们放弃支持这种情况,然后这个看起来就刺激的表达式就可以简化成下面这种形式:
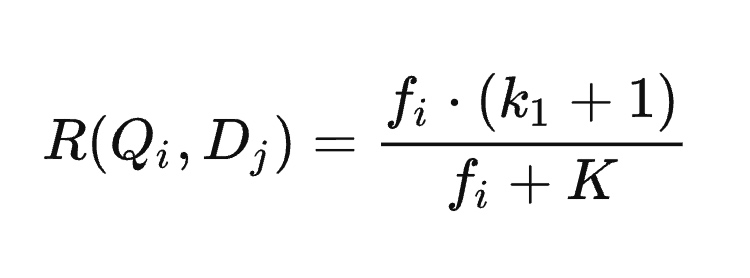
需要注意的是,这里面的大写的 K 依然是上面那个略微复杂的样式。我们取 k1 为 2,b 为 0.75,页面(文档)平均长度我自己跑了一个,13214,你们可以用我这个数,也可以自己跑一个用。
我的代码实现如下:
```go
// 使用 - 切分后的值,为此页面的字典值,形式为:
// 110,85,1,195653,7101
ints := strings.Split(p, ",")
// 这个词在这个页面中出现总次数
Fi, err := strconv.Atoi(ints[2])
// 这个页面的长度
Dj, _ := strconv.Atoi(ints[3])
k1 := 2.0
b := 0.75
// 页面平均长度
avgDocLength := 13214.0
// 得到相关性得分
RQiDj := (float64(Fi) * (k1 + 1)) / (float64(Fi) + k1*(1-b+b*(float64(Dj)/avgDocLength)))
```
#### 怎么样,是不是比你想象的简单?
### 检验搜索结果
我在我搞的“翰哥搜索”页面上搜了一下“BM25 算法的数学描述”,结果如下:

我搜索“住范儿”,结果如下:

第一个就是我们官网,可以说相当精准了。
看起来效果还不错,要知道这只是在 784 万的网页中搜索的结果哦,如果你有足够的服务器资源,能搞定三亿个页面的爬取、索引和查询的话,效果肯定更加的好。
### 如何继续提升搜索准确性?
目前我们的简化版 BM25 算法的搜索结果已经达到能用的水平了,还能继续提升搜索准确性吗?还可以:
1. 本文全部是基于分词做的字典,你可以再做一份基于单字的,然后把单字的搜索结果排序和分词的搜索结果进行结合,搜索结果可以更准。
2. 相似的原理,打造更加合理、更加丰富的分词方式,构造不同倾向的词典,可以提升特定领域的搜索结果表现,例如医学领域、代码领域等。
3. 打造你自己的 PageRank 技术,从 URL 之间关系的角度,给单个 URL 的价值进行打分,并将这个价值分数放进搜索结果的排序参数之中。
4. 引入 proximity 相似性计算,不仅考虑精确匹配的关键词,还要考虑到含义相近的关键词的搜索结果。
5. 特殊查询的处理:修正用户可能的输入错误,处理中文独特的“拼音匹配”需求等。
### 参考资料
1. 【NLP】非监督文本匹配算法——BM25 https://zhuanlan.zhihu.com/p/499906089
2. 《自制搜索引擎》—— [日]山田浩之、末永匡
文章结束了,你学废了吗?欢迎到下列位置留下你的评论:
1. Github:https://github.com/johnlui/DIY-Search-Engine
2. 博客:https://pphc.lvwenhan.com/tech-epic/2023/diy-search-engine
【全文完】
# 本项目运行方法
首先,给自己准备一杯咖啡。
1. 把本项目下载到本地
2. 编译:`go build -o ese *.go`
3. 修改配置文件:`cp .env.example .env`,然后把里面的数据库和 Redis 配置改成你的
4. 执行`./ese art init`创建数据库
5. 手动插入一个真实的 URL 到 pages_00 表中,只需要填充 url 和 host 两个字段
6. 执行`./ese`,静待好事发生 ☕️
过一段时间,等字典数据表`word_dics`里面填充了数据之后,打开[http://127.0.0.1:10086](http://127.0.0.1:10086),尝试搜一下吧!🔍
#### 更多项目运行信息,请见 [wiki](https://github.com/johnlui/DIY-Search-Engine/wiki)
#### 网页直接阅读:https://pphc.lvwenhan.com/tech-epic/2023/diy-search-engine
### 作者信息:
1. 姓名:吕文翰
2. GitHub:[johnlui](https://github.com/johnlui)
3. 职位:住范儿 CTO

### 文章版权声明
本文权归属于[吕文翰](https://github.com/johnlui),采用 [CC BY-NC-ND 4.0](https://creativecommons.org/licenses/by-nc-nd/4.0/legalcode.zh-Hans) 协议开源,供 GitHub 平台用户免费阅读。

### 代码版权
本项目代码采用 MIT 协议开源。