https://github.com/jokerdii/nlp-projects
Built text classifiers by fine-tuning pre-trained BERT models
https://github.com/jokerdii/nlp-projects
albert bert nlp sentiment-analysis text-similarity
Last synced: about 1 month ago
JSON representation
Built text classifiers by fine-tuning pre-trained BERT models
- Host: GitHub
- URL: https://github.com/jokerdii/nlp-projects
- Owner: JoKerDii
- Created: 2022-05-15T02:17:13.000Z (about 4 years ago)
- Default Branch: main
- Last Pushed: 2022-09-03T18:16:30.000Z (almost 4 years ago)
- Last Synced: 2025-11-16T21:05:39.887Z (8 months ago)
- Topics: albert, bert, nlp, sentiment-analysis, text-similarity
- Language: Jupyter Notebook
- Homepage: https://jokerdii.github.io/nlp-projects/
- Size: 2.15 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# NLP Project Collection
## 1 IMDB Sentiment Analysis with ELMo
[Project Notebook](https://nbviewer.org/github/JoKerDii/nlp-projects/blob/main/ELMo_from_scratch/IMDB_Sentiment_Analysis_with_ELMo.ipynb)
### Overview
For this sentiment analysis task we used IMDB dataset which is publicly available [here](http://ai.stanford.edu/~amaas/data/sentiment/). We aimed to classify movie reviews as positive and negative. The work can be split into three parts:
1. Build a language model to train a basic ELMo. Instead of using Character Embeddings, we used word embeddings.
2. Use the generated ELMo embeddings to performn sentiment analysis on IMDB dataset.
3. Evaluate the model with trained ELMo embedding with other two models without trained embedding and with a word2vec embedding.
### ELMo-like Model
We defined an ELMo-like language model using bi-directional LSTMs and residual connections without the character CNN. We used the word2vec embeddings instead of the character representations of the CNN. The structure of ELMo-like model is as follows.
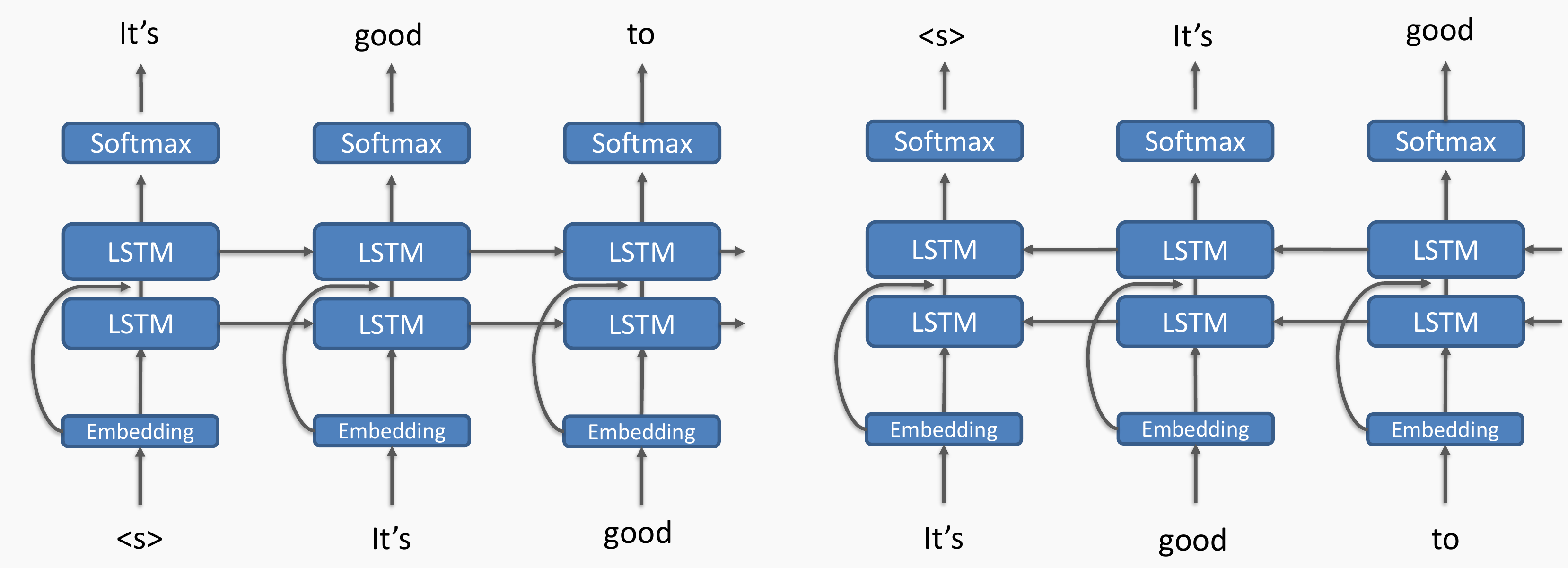
We built another model called `Toy_ELMo` to obtain the embeddings of the model. The embeddings are trained sufficiently and then used for sentiment analysis.
### Results
The Toy ELMo model built from scratch is successful and works normally. After training on a not very large dataset, compared to the baseline model with embedding from scratch and the model with word2vec embeddings, the accuracy of the model with ELMo embeddings is only about 0.5 lower.
| | Model with embeddings from scratch | Model with word2vec embeddings | Model with trained ELMo embeddings |
| -------- | ---------------------------------- | ------------------------------ | ---------------------------------- |
| Accuracy | 0.8722 | 0.8609 | 0.8177 |
### Discussion
The embeddings trained from scratch (baseline) performed surprisingly well, almost as good as the pretrained word2vec model. It is probably because the task is relatively easy. It is likely that the performance of the models would differ much more on a more sophisticated multi-class classification problem. Moreover, because we are dealing only with movie reviews, words have very specific connotations in that context. For example, the words "flop", "bomb", and "turkey" most likely mean "a bad movie" when appearing in a movie review. By training our own word embeddings we are able to focus on these idiomatic usages whereas the pretrained word2vec embeddings must represent a combination of all possible meanings of these words across all contexts. So if we were to use word2vec embeddings and keep the embeddings trainable and fine tune these original embeddings to our specific domain of movie reviews would likely give even better results.
The ELMo embedding model's performance is disappointing. One reason is that we have to limit teh amount of training data due to memory constraints. The max length argument to the IMDB data decreases and so the performance of the final suffers. Setting `maxlen` to be smaller reduces a large number of reviews that exceed this length. An under-trained ELMo model simply does not produce very useful contextual embeddings.
## 2 Text Binary Classification based on BERT
[Project Notebook](https://nbviewer.org/github/JoKerDii/nlp-projects/blob/main/Huggingface/text-binary-classification-based-on-BERT.ipynb)
### Overview
Stanford Sentiment Treebank (SST) is a crucial dataset for testing an NLP model's capability on predicting the sentiment of movie reviews.
The project goal is to use Huggingface pretrained BERT model, fine-tune it with the training set, and make sentiment predictions.
### Result
Due to the limitation of computational resources, we only used 12000 training data (originally more than 67000 training data). The accuracy on the test set is **0.9169**. A classification report is as follows:
| | precision | recall | f1-score | support |
| --------------------- | --------- | ------ | -------- | ------- |
| Label 0 | 0.89 | 0.93 | 0.91 | 529 |
| Label 1 | 0.94 | 0.90 | 0.92 | 650 |
| Accuracy | | | 0.92 | 1179 |
| Macro avg accuracy | 0.92 | 0.92 | 0.92 | 1179 |
| Weighted avg accuracy | 0.92 | 0.92 | 0.92 | 1179 |
## 3 Text Multiclass Classification based on BERT
[Project Notebook](https://nbviewer.org/github/JoKerDii/nlp-projects/blob/main/Huggingface/text-multiclass-classification-based-on-BERT.ipynb)
### Overview
The Toxic Comments dataset here is from wiki corpus dataset which was rated by human raters for toxicity. The corpus contains 63M comments from discussions relating to user pages and articles dating from 2004-2015. The comments were tagged in six categories: toxic, severe toxic, obscene, threat, insult, and identity hate.
The goal is to classify toxic online comments by fine-tuning a pretrained BERT model.
### Result
The accuracy on test set is **0.8694**. By searching f1 score threshold, we find the best macro threshold value 0.73 such that the f1 score is the highest. The improved accuracy on test set is **0.8837**.
## 4 Sentence Similarity Identification based on ALBERT
[Project Notebook](https://nbviewer.org/github/JoKerDii/nlp-projects/blob/main/Huggingface/sentence_similarity_based_on_ALBERT.ipynb)
### Overview
The General Language Understanding Evaluation (GLUE) benchmark (https://gluebenchmark.com/) is a collection of resources for training, evaluating, and analyzing natural language understanding systems. The Microsoft Research Paraphrase Corpus (MRPC) subset of GLUE dataset is a corpus of sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent.
The goal of this project is to identify whether two sentences are similar by fine tuning a pretrained ALBERT model.
### Result
| | precision | recall | f1-score | support |
| --------------------- | --------- | ------ | -------- | ------- |
| Label 0 | 0.81 | 0.79 | 0.80 | 129 |
| Label 1 | 0.90 | 0.91 | 0.91 | 279 |
| Accuracy | | | 0.88 | 408 |
| Macro avg accuracy | 0.86 | 0.85 | 0.85 | 408 |
| Weighted avg accuracy | 0.87 | 0.88 | 0.87 | 408 |