https://github.com/jorischau/gslnls
{gslnls}: GSL multi-start nonlinear least-squares fitting in R
https://github.com/jorischau/gslnls
gnu-scientific-library gsl levenberg-marquardt multi-start nonlinear-least-squares nonlinear-regression r r-package robust-regresssion
Last synced: about 1 year ago
JSON representation
{gslnls}: GSL multi-start nonlinear least-squares fitting in R
- Host: GitHub
- URL: https://github.com/jorischau/gslnls
- Owner: JorisChau
- Created: 2021-09-12T10:00:33.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2025-01-17T14:19:09.000Z (over 1 year ago)
- Last Synced: 2025-04-22T23:41:22.406Z (about 1 year ago)
- Topics: gnu-scientific-library, gsl, levenberg-marquardt, multi-start, nonlinear-least-squares, nonlinear-regression, r, r-package, robust-regresssion
- Language: R
- Homepage: https://CRAN.R-project.org/package=gslnls
- Size: 1.62 MB
- Stars: 16
- Watchers: 1
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Changelog: NEWS.md
Awesome Lists containing this project
README
# {gslnls}: GSL Multi-Start Nonlinear Least-Squares Fitting in R
[](https://cran.r-project.org/package=gslnls)
[](https://github.com/JorisChau/gslnls/actions)
[](https://app.codecov.io/gh/JorisChau/gslnls)
[](https://cran.r-project.org/package=gslnls)
The {gslnls}-package provides R bindings to nonlinear least-squares
optimization with the [GNU Scientific Library
(GSL)](https://www.gnu.org/software/gsl/). The function `gsl_nls()`
solves small to moderate sized nonlinear least-squares problems with the
`gsl_multifit_nlinear` interface with built-in support for multi-start
optimization and nonlinear robust regression. For large problems, where
factoring the full Jacobian matrix becomes prohibitively expensive, the
`gsl_nls_large()` function can be used to solve the system with the
`gsl_multilarge_nlinear` interface. The `gsl_nls_large()` function is
also appropriate for systems with sparse structure in the Jacobian
matrix.
The following trust region methods to solve nonlinear least-squares
problems are available in `gsl_nls()` (and `gsl_nls_large()`):
- [Levenberg-Marquardt](https://www.gnu.org/software/gsl/doc/html/nls.html#levenberg-marquardt)
- [Levenberg-Marquardt with geodesic
acceleration](https://www.gnu.org/software/gsl/doc/html/nls.html#levenberg-marquardt-with-geodesic-acceleration)
- [Dogleg](https://www.gnu.org/software/gsl/doc/html/nls.html#dogleg)
- [Double
dogleg](https://www.gnu.org/software/gsl/doc/html/nls.html#double-dogleg)
- [Two Dimensional
Subspace](https://www.gnu.org/software/gsl/doc/html/nls.html#two-dimensional-subspace)
- [Steihaug-Toint Conjugate
Gradient](https://www.gnu.org/software/gsl/doc/html/nls.html#steihaug-toint-conjugate-gradient)
(only available in `gsl_nls_large()`)
The [Tunable
parameters](https://www.gnu.org/software/gsl/doc/html/nls.html#tunable-parameters)
available for the trust method algorithms can be modified from R in
order to help accelerating convergence for a specific problem at hand.
See the [Nonlinear Least-Squares
Fitting](https://www.gnu.org/software/gsl/doc/html/nls.html#nonlinear-least-squares-fitting)
chapter in the GSL reference manual for a comprehensive overview of the
`gsl_multifit_nlinear` and `gsl_multilarge_nlinear` interfaces and the
relevant mathematical background.
## Installation from source
### System requirements
When installing the R-package from source, verify that GSL (\>= 2.3) is
installed on the system, e.g. on Ubuntu/Debian Linux:
gsl-config --version
If GSL (\>= 2.3) is not available on the system, install GSL from a
pre-compiled binary package (see the examples below) or install GSL from
source by downloading the latest stable release
() and following the installation
instructions in the included README and INSTALL files.
#### GSL installation examples
##### Ubuntu, Debian
sudo apt-get install libgsl-dev
##### macOS
brew install gsl
##### Fedora, RedHat, CentOS
yum install gsl-devel
##### Windows
Using Rtools \>= 42, GSL is available with the Rtools installation. For
earlier versions of Rtools, a binary version of GSL can be installed
using the Rtools package manager (see
e.g. ):
pacman -S mingw-w64-{i686,x86_64}-gsl
On windows, the environment variable `LIB_GSL` must be set to the parent
of the directory containing `libgsl.a`. Note that forward instead of
backward slashes should be used in the directory path
(e.g. `C:/rtools43/x86_64-w64-mingw32.static.posix`).
### R-package installation
With GSL available, install the R-package from source with:
``` r
## Install latest CRAN release:
install.packages("gslnls", type = "source")
```
or install the latest development version from GitHub with:
``` r
## Install latest GitHub development version:
# install.packages("devtools")
devtools::install_github("JorisChau/gslnls")
```
## Installation from binary
On windows and some macOS builds, the R-package can be installed from
CRAN as a binary package. In this case, GSL does not need to be
available on the system.
``` r
## Install latest CRAN release:
install.packages("gslnls")
```
## Example usage
### Example 1: Exponential model
#### Data
Below, we simulate
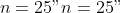
noisy observations

from an exponential model with additive (i.i.d.) Gaussian noise
according to:
 + b, & i = 1,\ldots, n \\
y_i & = f_i + \epsilon_i, & \epsilon_i \overset{\text{iid}}{\sim} N(0,\sigma^2)
\end{aligned}
\right.")
The exponential model parameters are set to
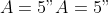,
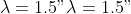,
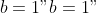, with
noise standard deviation
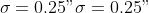.
``` r
set.seed(1)
n <- 25
x <- (seq_len(n) - 1) * 3 / (n - 1)
f <- function(A, lam, b, x) A * exp(-lam * x) + b
y <- f(A = 5, lam = 1.5, b = 1, x) + rnorm(n, sd = 0.25)
```

#### Model fit
The exponential model is fitted to the data using the function
`gsl_nls()` by passing the nonlinear model as a two-sided `formula` and
providing starting parameters for the model parameters

analogous to a standard `nls()` call.
``` r
library(gslnls)
ex1_fit <- gsl_nls(
fn = y ~ A * exp(-lam * x) + b, ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(A = 0, lam = 0, b = 0) ## starting values
)
ex1_fit
#> Nonlinear regression model
#> model: y ~ A * exp(-lam * x) + b
#> A lam b
#> 4.893 1.417 1.010
#> residual sum-of-squares: 1.316
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 9
#> Achieved convergence tolerance: 4.441e-16
```
Here, the nonlinear least squares problem is solved with the
Levenberg-Marquardt algorithm (default) in the `gsl_multifit_nlinear`
interface with `control` parameters:
``` r
## default control parameters
gsl_nls_control() |> str()
#> List of 23
#> $ maxiter : int 100
#> $ scale : chr "more"
#> $ solver : chr "qr"
#> $ fdtype : chr "forward"
#> $ factor_up : num 2
#> $ factor_down : num 3
#> $ avmax : num 0.75
#> $ h_df : num 1.49e-08
#> $ h_fvv : num 0.02
#> $ xtol : num 1.49e-08
#> $ ftol : num 1.49e-08
#> $ gtol : num 1.49e-08
#> $ mstart_n : int 30
#> $ mstart_p : int 5
#> $ mstart_q : int 3
#> $ mstart_r : num 4
#> $ mstart_s : int 2
#> $ mstart_tol : num 0.25
#> $ mstart_maxiter : int 10
#> $ mstart_maxstart: int 250
#> $ mstart_minsp : int 1
#> $ irls_maxiter : int 50
#> $ irls_xtol : num 0.000122
```
Check `?gsl_nls_control` or the [GSL reference
manual](https://www.gnu.org/software/gsl/doc/html/nls.html#tunable-parameters)
for details on the available tuning parameters to control the trust
region algorithms.
#### Object methods
The fitted model object returned by `gsl_nls()` is of class `"gsl_nls"`,
which inherits from class `"nls"`. For this reason, generic functions
such as `anova`, `coef`, `confint`, `deviance`, `df.residual`, `fitted`,
`formula`, `logLik`, `predict`, `print` `profile`, `residuals`,
`summary`, `vcov`, `hatvalues`, `cooks.distance` and `weights` are also
applicable for models fitted with `gsl_nls()`.
``` r
## model summary
summary(ex1_fit)
#>
#> Formula: y ~ A * exp(-lam * x) + b
#>
#> Parameters:
#> Estimate Std. Error t value Pr(>|t|)
#> A 4.8930 0.1811 27.014 < 2e-16 ***
#> lam 1.4169 0.1304 10.865 2.61e-10 ***
#> b 1.0097 0.1092 9.246 4.92e-09 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2446 on 22 degrees of freedom
#>
#> Number of iterations to convergence: 9
#> Achieved convergence tolerance: 4.441e-16
## asymptotic confidence intervals
confint(ex1_fit)
#> 2.5 % 97.5 %
#> A 4.5173851 5.268653
#> lam 1.1464128 1.687314
#> b 0.7832683 1.236216
```
The `predict` method extends the existing `predict.nls` method by
allowing for calculation of asymptotic confidence and prediction
(tolerance) intervals in addition to prediction of the expected
response:
``` r
## asymptotic prediction intervals
predict(ex1_fit, interval = "prediction", level = 0.95)
#> fit lwr upr
#> [1,] 5.902761 5.2670162 6.538506
#> [2,] 5.108572 4.5388041 5.678340
#> [3,] 4.443289 3.8987833 4.987794
#> [4,] 3.885988 3.3479065 4.424069
#> [5,] 3.419142 2.8812430 3.957042
....
```

The new `confintd` method can be used to evaluate asymptotic confidence
intervals of derived (or transformed) parameters based on the delta
method, i.e. a first-order (Taylor) approximation of the function of the
parameters:
``` r
## delta method confidence intervals
confintd(ex1_fit, expr = c("b", "A + b", "log(lam)"), level = 0.95)
#> fit lwr upr
#> b 1.0097419 0.7832683 1.2362155
#> A + b 5.9027612 5.5194278 6.2860945
#> log(lam) 0.3484454 0.1575657 0.5393251
```
#### Jacobian calculation
If the `jac` argument in `gsl_nls()` is undefined, the Jacobian to solve
the [trust region
subproblem](https://www.gnu.org/software/gsl/doc/html/nls.html#solving-the-trust-region-subproblem-trs)
is approximated numerically by (forward or centered) finite differences.
Instead, an analytic Jacobian can be passed to `jac` by defining a
function that returns the
")-dimensional
Jacobian matrix of the nonlinear model `fn`, where the first argument
must be the vector of parameters of length
.
In the above example, the Jacobian is a
")-matrix
![\[\boldsymbol{J}\_{ij}\]\_{ij}](https://latex.codecogs.com/png.latex?%5B%5Cboldsymbol%7BJ%7D_%7Bij%7D%5D_%7Bij%7D "[\boldsymbol{J}_{ij}]_{ij}")
with rows:
![\boldsymbol{J}\_i \\= \\\left\[ \frac{\partial f_i}{\partial A}, \frac{\partial f_i}{\partial \lambda}, \frac{\partial f_i}{\partial b} \right\] \\= \\\left\[ \exp(-\lambda \cdot x_i), -A \cdot \exp(-\lambda \cdot x_i) \cdot x_i, 1 \right\]](https://latex.codecogs.com/png.latex?%5Cboldsymbol%7BJ%7D_i%20%5C%20%3D%20%5C%20%5Cleft%5B%20%5Cfrac%7B%5Cpartial%20f_i%7D%7B%5Cpartial%20A%7D%2C%20%5Cfrac%7B%5Cpartial%20f_i%7D%7B%5Cpartial%20%5Clambda%7D%2C%20%5Cfrac%7B%5Cpartial%20f_i%7D%7B%5Cpartial%20b%7D%20%5Cright%5D%20%5C%20%3D%20%5C%20%5Cleft%5B%20%5Cexp%28-%5Clambda%20%5Ccdot%20x_i%29%2C%20-A%20%5Ccdot%20%5Cexp%28-%5Clambda%20%5Ccdot%20x_i%29%20%5Ccdot%20x_i%2C%201%20%5Cright%5D "\boldsymbol{J}_i \ = \ \left[ \frac{\partial f_i}{\partial A}, \frac{\partial f_i}{\partial \lambda}, \frac{\partial f_i}{\partial b} \right] \ = \ \left[ \exp(-\lambda \cdot x_i), -A \cdot \exp(-\lambda \cdot x_i) \cdot x_i, 1 \right]")
which can be encoded as:
``` r
## analytic Jacobian (1)
gsl_nls(
fn = y ~ A * exp(-lam * x) + b, ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(A = 0, lam = 0, b = 0), ## starting values
jac = function(par, x) with(as.list(par), cbind(A = exp(-lam * x), lam = -A * x * exp(-lam * x), b = 1)),
x = x ## argument passed to jac
)
#> Nonlinear regression model
#> model: y ~ A * exp(-lam * x) + b
#> A lam b
#> 4.893 1.417 1.010
#> residual sum-of-squares: 1.316
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 9
#> Achieved convergence tolerance: 6.661e-16
```
If the model formula `fn` can be derived with `stats::deriv()`, then the
analytic Jacobian in `jac` can be computed automatically using symbolic
differentiation and it suffices to set `jac = TRUE`:
``` r
## analytic Jacobian (2)
gsl_nls(
fn = y ~ A * exp(-lam * x) + b, ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(A = 0, lam = 0, b = 0), ## starting values
jac = TRUE ## symbolic derivation
)
#> Nonlinear regression model
#> model: y ~ A * exp(-lam * x) + b
#> A lam b
#> 4.893 1.417 1.010
#> residual sum-of-squares: 1.316
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 9
#> Achieved convergence tolerance: 6.661e-16
```
Alternatively, a self-starting nonlinear model (see `?selfStart`) can be
passed to `gsl_nls()`. In this case, the Jacobian matrix is evaluated
from the `"gradient"` attribute of the self-starting model object:
``` r
## self-starting model
ss_fit <- gsl_nls(
fn = y ~ SSasymp(x, Asym, R0, lrc), ## model formula
data = data.frame(x = x, y = y) ## model fit data
)
ss_fit
#> Nonlinear regression model
#> model: y ~ SSasymp(x, Asym, R0, lrc)
#> Asym R0 lrc
#> 1.0097 5.9028 0.3484
#> residual sum-of-squares: 1.316
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 1
#> Achieved convergence tolerance: 1.181e-13
```
The self-starting model `SSasymp()` uses a different model
parameterization (`A = R0 - Asym`, `lam = exp(lrc)`, `b = Asym`), but
the fitted models are equivalent. Also, when using a *self-starting*
model, no starting values need to be provided.
**Remark**: confidence intervals for the coefficients in the original
model parameterization can be evaluated with the `confintd` method:
``` r
## delta method confidence intervals
confintd(ss_fit, expr = c("R0 - Asym", "exp(lrc)", "Asym"), level = 0.95)
#> fit lwr upr
#> R0 - Asym 4.893019 4.5173851 5.268653
#> exp(lrc) 1.416863 1.1464128 1.687314
#> Asym 1.009742 0.7832683 1.236216
```
#### Multi-start optimization
In addition to single-start NLS optimization, the `gsl_nls()` function
has built-in support for multi-start optimization. For multi-start
optimization, instead of a list or vector of fixed start parameters,
pass a `list` or `matrix` of start parameter ranges to the argument
`start`:
``` r
gsl_nls(
fn = y ~ A * exp(-lam * x) + b, ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = list(A = c(-100, 100), lam = c(-5, 5), b = c(-10, 10)) ## multi-start
)
#> Nonlinear regression model
#> model: y ~ A * exp(-lam * x) + b
#> A lam b
#> 4.893 1.417 1.010
#> residual sum-of-squares: 1.316
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 3
#> Achieved convergence tolerance: 8.882e-16
```
The multi-start procedure is a modified version of the algorithm
described in Hickernell and Yuan (1997), see `?gsl_nls` for additional
details. If `start` contains missing (or infinite) values, the
multi-start algorithm is executed without fixed parameter ranges for the
missing parameters. More precisely, the ranges are initialized to the
unit interval and dynamically increased or decreased in each major
iteration of the multi-start algorithm.
``` r
gsl_nls(
fn = y ~ A * exp(-lam * x) + b, ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = list(A = NA, lam = NA, b = NA) ## dynamic multi-start
)
#> Nonlinear regression model
#> model: y ~ A * exp(-lam * x) + b
#> A lam b
#> 4.893 1.417 1.010
#> residual sum-of-squares: 1.316
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 3
#> Achieved convergence tolerance: 2.22e-16
```
**Remark**: the dynamic multi-start procedure is not expected to always
return a global minimum of the NLS objective. Especially when the
objective function contains many local optima, the multi-start algorithm
may be unable to select parameter ranges that include the global
minimizing solution.
#### Robust loss functions
The `loss` argument in `gsl_nls()` allows to specify a robust loss
function
")
other than the default squared loss
 = \frac{1}{2}x^2")
in the optimization objective:
\right)")
The (MM-)estimates in the robust regression problem are obtained by
iterative reweighted least squares (IRLS), see `?gsl_nls_loss` for the
available loss functions and their (optional) tuning parameters.
``` r
## Huber loss
gsl_nls(
fn = y ~ A * exp(-lam * x) + b, ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(A = 0, lam = 0, b = 0), ## starting values
loss = "huber"
)
#> Nonlinear regression model
#> model: y ~ A * exp(-lam * x) + b
#> A lam b
#> 4.796 1.463 1.092
#> weighted residual sum-of-squares: 0.8127
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of IRLS iterations to convergence: 8
#> Achieved IRLS tolerance: 0.0001023
#>
#> Number of NLS iterations to convergence: 9
#> Achieved NLS tolerance: 1.11e-16
```
### Example 2: Gaussian function
#### Data
The following code generates
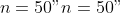
noisy observations

from a Gaussian function with multiplicative independent Gaussian noise
according to the model:
^2}{2c^2}\right), & i = 1,\ldots, n \\
y_i & = f_i \cdot \epsilon_i, & \epsilon_i \overset{\text{iid}}{\sim} N(1,\sigma^2)
\end{aligned}
\right.")
The parameters of the Gaussian model function are set to
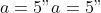,
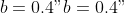,
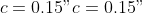,
with noise standard deviation
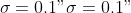
(see also
).
``` r
set.seed(1)
n <- 50
x <- seq_len(n) / n
f <- function(a, b, c, x) a * exp(-(x - b)^2 / (2 * c^2))
y <- f(a = 5, b = 0.4, c = 0.15, x) * rnorm(n, mean = 1, sd = 0.1)
```

#### Model fit
Using the default
[Levenberg-Marquardt](https://www.gnu.org/software/gsl/doc/html/nls.html#levenberg-marquardt)
algorithm (without geodesic acceleration), the nonlinear Gaussian model
can be fitted with a call to `gsl_nls()` analogous to the previous
example. Here, the `trace` argument is activated in order to trace the
sum of squared residuals (`ssr`) and parameter estimates (`par`) at each
iteration of the algorithm.
``` r
## Levenberg-Marquardt (default)
ex2a_fit <- gsl_nls(
fn = y ~ a * exp(-(x - b)^2 / (2 * c^2)), ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(a = 1, b = 0, c = 1), ## starting values
trace = TRUE ## verbose output
)
#> iter 1: ssr = 174.476, par = (2.1711, 3.31169, -4.12254)
#> iter 2: ssr = 171.29, par = (1.85555, 2.84851, -5.66642)
#> iter 3: ssr = 168.703, par = (1.93316, 2.34745, -6.33662)
#> iter 4: ssr = 167.546, par = (1.84665, 1.24131, -7.399)
#> iter 5: ssr = 166.799, par = (1.87948, 0.380487, -7.61723)
#> iter 6: ssr = 165.623, par = (1.90658, -2.00516, -7.19306)
#> iter 7: ssr = 163.944, par = (2.18675, -3.19622, -5.38805)
#> iter 8: ssr = 161.679, par = (2.41824, -3.1487, -5.03149)
#> iter 9: ssr = 159.955, par = (2.67373, -3.18704, -4.20168)
#> iter 10: ssr = 157.391, par = (3.10831, -2.84066, -3.10573)
#> iter 11: ssr = 153.131, par = (3.54614, -2.3807, -2.53824)
#> iter 12: ssr = 150.129, par = (4.028, -1.97822, -1.96376)
#> iter 13: ssr = 146.735, par = (4.49887, -1.35878, -1.39554)
#> iter 14: ssr = 142.928, par = (3.14454, -0.573011, -1.08117)
#> iter 15: ssr = 124.564, par = (2.14741, 0.465371, -0.443323)
#> iter 16: ssr = 102.171, par = (3.74447, 0.263284, 0.353778)
#> iter 17: ssr = 35.4992, par = (3.4995, 0.437365, 0.186149)
#> iter 18: ssr = 9.25455, par = (4.41259, 0.381433, 0.160233)
#> iter 19: ssr = 3.13721, par = (4.94369, 0.400412, 0.15032)
#> iter 20: ssr = 2.76231, par = (5.11738, 0.397815, 0.14729)
#> iter 21: ssr = 2.75831, par = (5.13785, 0.397886, 0.146865)
#> iter 22: ssr = 2.7583, par = (5.1389, 0.397884, 0.146831)
#> iter 23: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 24: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 25: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 26: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> *******************
#> summary from method 'multifit/levenberg-marquardt'
#> number of iterations: 26
#> initial ssr: 210.146
#> final ssr: 2.7583
#> ssr/dof: 0.0586872
#> ssr achieved tolerance: 1.33227e-15
#> function evaluations: 124
#> jacobian evaluations: 0
#> fvv evaluations: 0
#> status: success
#> *******************
ex2a_fit
#> Nonlinear regression model
#> model: y ~ a * exp(-(x - b)^2/(2 * c^2))
#> a b c
#> 5.1389 0.3979 0.1468
#> residual sum-of-squares: 2.758
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 26
#> Achieved convergence tolerance: 1.332e-15
```
#### Geodesic acceleration
The nonlinear model can also be fitted using the Levenberg-Marquardt
algorithm with [geodesic
acceleration](https://www.gnu.org/software/gsl/doc/html/nls.html#levenberg-marquardt-with-geodesic-acceleration)
by changing the default `algorithm = "lm"` to `algorithm = "lmaccel"`.
``` r
## Levenberg-Marquardt w/ geodesic acceleration
ex2b_fit <- gsl_nls(
fn = y ~ a * exp(-(x - b)^2 / (2 * c^2)), ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(a = 1, b = 0, c = 1), ## starting values
algorithm = "lmaccel", ## algorithm
trace = TRUE ## verbose output
)
#> iter 1: ssr = 158.039, par = (1.58476, 0.502555, 0.511498)
#> iter 2: ssr = 126.469, par = (1.8444, 0.366374, 0.403898)
#> iter 3: ssr = 77.0115, par = (2.5025, 0.392374, 0.272717)
#> iter 4: ssr = 26.4036, par = (3.64063, 0.394564, 0.205618)
#> iter 5: ssr = 5.35491, par = (4.63506, 0.396865, 0.163659)
#> iter 6: ssr = 2.82529, par = (5.05578, 0.397909, 0.149333)
#> iter 7: ssr = 2.75877, par = (5.13246, 0.397896, 0.147057)
#> iter 8: ssr = 2.7583, par = (5.13862, 0.397885, 0.146843)
#> iter 9: ssr = 2.7583, par = (5.13893, 0.397884, 0.14683)
#> iter 10: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 11: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 12: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> *******************
#> summary from method 'multifit/levenberg-marquardt+accel'
#> number of iterations: 12
#> initial ssr: 210.146
#> final ssr: 2.7583
#> ssr/dof: 0.0586872
#> ssr achieved tolerance: 3.19744e-14
#> function evaluations: 76
#> jacobian evaluations: 0
#> fvv evaluations: 0
#> status: success
#> *******************
ex2b_fit
#> Nonlinear regression model
#> model: y ~ a * exp(-(x - b)^2/(2 * c^2))
#> a b c
#> 5.1389 0.3979 0.1468
#> residual sum-of-squares: 2.758
#>
#> Algorithm: multifit/levenberg-marquardt+accel, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 12
#> Achieved convergence tolerance: 3.197e-14
```
With geodesic acceleration enabled the method converges after 12
iterations, whereas the method without geodesic acceleration required 26
iterations. This indicates that the nonlinear least-squares solver
benefits (substantially) from the geodesic acceleration correction.
##### Second directional derivative
By default, if the `fvv` argument is undefined, the second directional
derivative

used to calculate the geodesic acceleration correction is approximated
by forward (or centered) finite differences. To use an analytic
expression for
,
a function returning the
-dimensional vector of
second directional derivatives of the nonlinear model can be passed to
`fvv`. The first argument of the function must be the vector of
parameters of length 
and the second argument must be the velocity vector, also of length
.
For the Gaussian model function, the matrix of second partial
derivatives, i.e. the Hessian, is given by
(cf. ):
![\boldsymbol{H}\_{f_i} \\= \\
\left\[\begin{matrix}
\frac{\partial^2 f_i}{\partial a^2} & \frac{\partial^2 f_i}{\partial a \partial b} & \frac{\partial^2 f_i}{\partial a \partial c} \\
& \frac{\partial^2 f_i}{\partial b^2} & \frac{\partial^2 f_i}{\partial b \partial c} \\
& & \frac{\partial^2 f_i}{\partial c^2}
\end{matrix}\right\] \\= \\
\left\[\begin{matrix}
0 & \frac{z_i}{c} e_i & \frac{z_i^2}{c} e_i \\
& -\frac{a}{c^2} (1 - z_i^2) e_i & -\frac{a}{c^2} z_i (2 - z_i^2) e_i \\
& & -\frac{a}{c^2} z_i^2 (3 - z_i^2) e_i
\end{matrix}\right\]](https://latex.codecogs.com/png.latex?%5Cboldsymbol%7BH%7D_%7Bf_i%7D%20%5C%20%3D%20%5C%20%0A%5Cleft%5B%5Cbegin%7Bmatrix%7D%20%0A%5Cfrac%7B%5Cpartial%5E2%20f_i%7D%7B%5Cpartial%20a%5E2%7D%20%26%20%5Cfrac%7B%5Cpartial%5E2%20f_i%7D%7B%5Cpartial%20a%20%5Cpartial%20b%7D%20%26%20%5Cfrac%7B%5Cpartial%5E2%20f_i%7D%7B%5Cpartial%20a%20%5Cpartial%20c%7D%20%5C%5C%0A%26%20%5Cfrac%7B%5Cpartial%5E2%20f_i%7D%7B%5Cpartial%20b%5E2%7D%20%26%20%5Cfrac%7B%5Cpartial%5E2%20f_i%7D%7B%5Cpartial%20b%20%5Cpartial%20c%7D%20%5C%5C%0A%26%20%26%20%5Cfrac%7B%5Cpartial%5E2%20f_i%7D%7B%5Cpartial%20c%5E2%7D%0A%5Cend%7Bmatrix%7D%5Cright%5D%20%5C%20%3D%20%5C%20%0A%5Cleft%5B%5Cbegin%7Bmatrix%7D%0A0%20%26%20%5Cfrac%7Bz_i%7D%7Bc%7D%20e_i%20%26%20%5Cfrac%7Bz_i%5E2%7D%7Bc%7D%20e_i%20%5C%5C%0A%26%20-%5Cfrac%7Ba%7D%7Bc%5E2%7D%20%281%20-%20z_i%5E2%29%20e_i%20%26%20-%5Cfrac%7Ba%7D%7Bc%5E2%7D%20z_i%20%282%20-%20z_i%5E2%29%20e_i%20%5C%5C%0A%26%20%26%20-%5Cfrac%7Ba%7D%7Bc%5E2%7D%20z_i%5E2%20%283%20-%20z_i%5E2%29%20e_i%20%0A%5Cend%7Bmatrix%7D%5Cright%5D "\boldsymbol{H}_{f_i} \ = \
\left[\begin{matrix}
\frac{\partial^2 f_i}{\partial a^2} & \frac{\partial^2 f_i}{\partial a \partial b} & \frac{\partial^2 f_i}{\partial a \partial c} \\
& \frac{\partial^2 f_i}{\partial b^2} & \frac{\partial^2 f_i}{\partial b \partial c} \\
& & \frac{\partial^2 f_i}{\partial c^2}
\end{matrix}\right] \ = \
\left[\begin{matrix}
0 & \frac{z_i}{c} e_i & \frac{z_i^2}{c} e_i \\
& -\frac{a}{c^2} (1 - z_i^2) e_i & -\frac{a}{c^2} z_i (2 - z_i^2) e_i \\
& & -\frac{a}{c^2} z_i^2 (3 - z_i^2) e_i
\end{matrix}\right]")
where the lower half of the Hessian matrix is omitted since it is
symmetric and where we use the notation,

\end{aligned}")
Based on the Hessian matrix, the second directional derivative of
, with
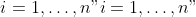,
becomes:
 e_i - 2v_bv_c \frac{a}{c^2} z_i (2 - z_i^2) e_i - v_c^2\frac{a}{c^2} z_i^2 (3 - z_i^2) e_i
\end{aligned}")
which can be encoded using `gsl_nls()` as follows:
``` r
## second directional derivative
fvv <- function(par, v, x) {
with(as.list(par), {
zi <- (x - b) / c
ei <- exp(-zi^2 / 2)
2 * v[["a"]] * v[["b"]] * zi / c * ei + 2 * v[["a"]] * v[["c"]] * zi^2 / c * ei -
v[["b"]]^2 * a / c^2 * (1 - zi^2) * ei - 2 * v[["b"]] * v[["c"]] * a / c^2 * zi * (2 - zi^2) * ei -
v[["c"]]^2 * a / c^2 * zi^2 * (3 - zi^2) * ei
})
}
## analytic fvv (1)
gsl_nls(
fn = y ~ a * exp(-(x - b)^2 / (2 * c^2)), ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(a = 1, b = 0, c = 1), ## starting values
algorithm = "lmaccel", ## algorithm
trace = TRUE, ## verbose output
fvv = fvv, ## analytic function
x = x ## argument passed to fvv
)
#> iter 1: ssr = 158.14, par = (1.584, 0.502802, 0.512515)
#> iter 2: ssr = 126.579, par = (1.84317, 0.365984, 0.404378)
#> iter 3: ssr = 77.1032, par = (2.50015, 0.392468, 0.272532)
#> iter 4: ssr = 26.4382, par = (3.63788, 0.394722, 0.205505)
#> iter 5: ssr = 5.36705, par = (4.63344, 0.396903, 0.16368)
#> iter 6: ssr = 2.82578, par = (5.05546, 0.39791, 0.149341)
#> iter 7: ssr = 2.75877, par = (5.13243, 0.397896, 0.147057)
#> iter 8: ssr = 2.7583, par = (5.13862, 0.397885, 0.146843)
#> iter 9: ssr = 2.7583, par = (5.13893, 0.397884, 0.14683)
#> iter 10: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 11: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 12: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> *******************
#> summary from method 'multifit/levenberg-marquardt+accel'
#> number of iterations: 12
#> initial ssr: 210.146
#> final ssr: 2.7583
#> ssr/dof: 0.0586872
#> ssr achieved tolerance: 3.10862e-14
#> function evaluations: 58
#> jacobian evaluations: 0
#> fvv evaluations: 18
#> status: success
#> *******************
#> Nonlinear regression model
#> model: y ~ a * exp(-(x - b)^2/(2 * c^2))
#> a b c
#> 5.1389 0.3979 0.1468
#> residual sum-of-squares: 2.758
#>
#> Algorithm: multifit/levenberg-marquardt+accel, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 12
#> Achieved convergence tolerance: 3.109e-14
```
If the model formula `fn` can be derived with `stats::deriv()`, then the
analytic Hessian and second directional derivatives in `fvv` can be
computed automatically using symbolic differentiation. Analogous to the
`jac` argument, to evaluate `fvv` by means of symbolic differentiation,
set `fvv = TRUE`:
``` r
## analytic fvv (2)
gsl_nls(
fn = y ~ a * exp(-(x - b)^2 / (2 * c^2)), ## model formula
data = data.frame(x = x, y = y), ## model fit data
start = c(a = 1, b = 0, c = 1), ## starting values
algorithm = "lmaccel", ## algorithm
trace = TRUE, ## verbose output
fvv = TRUE ## automatic derivation
)
#> iter 1: ssr = 158.14, par = (1.584, 0.502802, 0.512515)
#> iter 2: ssr = 126.579, par = (1.84317, 0.365984, 0.404378)
#> iter 3: ssr = 77.1032, par = (2.50015, 0.392468, 0.272532)
#> iter 4: ssr = 26.4382, par = (3.63788, 0.394722, 0.205505)
#> iter 5: ssr = 5.36705, par = (4.63344, 0.396903, 0.16368)
#> iter 6: ssr = 2.82578, par = (5.05546, 0.39791, 0.149341)
#> iter 7: ssr = 2.75877, par = (5.13243, 0.397896, 0.147057)
#> iter 8: ssr = 2.7583, par = (5.13862, 0.397885, 0.146843)
#> iter 9: ssr = 2.7583, par = (5.13893, 0.397884, 0.14683)
#> iter 10: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 11: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> iter 12: ssr = 2.7583, par = (5.13894, 0.397884, 0.146829)
#> *******************
#> summary from method 'multifit/levenberg-marquardt+accel'
#> number of iterations: 12
#> initial ssr: 210.146
#> final ssr: 2.7583
#> ssr/dof: 0.0586872
#> ssr achieved tolerance: 3.10862e-14
#> function evaluations: 58
#> jacobian evaluations: 0
#> fvv evaluations: 18
#> status: success
#> *******************
#> Nonlinear regression model
#> model: y ~ a * exp(-(x - b)^2/(2 * c^2))
#> a b c
#> 5.1389 0.3979 0.1468
#> residual sum-of-squares: 2.758
#>
#> Algorithm: multifit/levenberg-marquardt+accel, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 12
#> Achieved convergence tolerance: 3.109e-14
```
### Example 3: Branin function
As a third example, we compare the available trust region methods by
minimizing the Branin test function, a common optimization test problem.
For the Branin test function, the following bivariate expression is
used:
 & \ = \ f_1(x_1, x_2)^2 + f_2(x_1, x_2)^2 \\
f_1(x_1, x_2) & \ = \ x_2 + a_1 x_1^2 + a_2 x_1 + a_3 \\
f_2(x_1, x_2) & \ = \ \sqrt{a_4 \cdot (1 + (1 - a_5) \cos(x_1))}
\end{aligned}
\right.")
with known constants
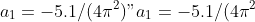"),
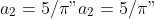,
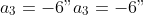,
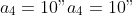,
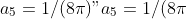")
(cf. ),
such that
")
has three local minima in the range
![(x_1, x_2) \in \[-5, 15\] \times \[-5, 15\]](https://latex.codecogs.com/png.latex?%28x_1%2C%20x_2%29%20%5Cin%20%5B-5%2C%2015%5D%20%5Ctimes%20%5B-5%2C%2015%5D "(x_1, x_2) \in [-5, 15] \times [-5, 15]").
The minimization problem can be solved with `gsl_nls()` by considering
the cost function
")
as a sum of squared residuals in which
")
and
")
are two residuals relative to two zero responses. Here, instead of
passing a `formula` to `gsl_nls()`, the nonlinear model is passed
directly as a `function`. The first parameter of the function is the
vector of parameters,
i.e. "),
and the function returns the vector of model evaluations,
i.e. , f_2(x_1, x_2))").
When passing a `function` instead of `formula` to `gsl_nls()`, the
vector of observed responses should be included in the `y` argument. In
this example, `y` is set to a vector of zeros. As starting values, we
use
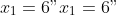
and
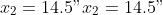
equivalent to the example in the GSL reference manual.
``` r
## Branin model function
branin <- function(x) {
a <- c(-5.1 / (4 * pi^2), 5 / pi, -6, 10, 1 / (8 * pi))
f1 <- x[2] + a[1] * x[1]^2 + a[2] * x[1] + a[3]
f2 <- sqrt(a[4] * (1 + (1 - a[5]) * cos(x[1])))
c(f1, f2)
}
## Levenberg-Marquardt minimization
ex3_fit <- gsl_nls(
fn = branin, ## model function
y = c(0, 0), ## response vector
start = c(x1 = 6, x2 = 14.5), ## starting values
algorithm = "lm" ## algorithm
)
ex3_fit
#> Nonlinear regression model
#> model: y ~ fn(x)
#> x1 x2
#> -3.142 12.275
#> residual sum-of-squares: 0.3979
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 20
#> Achieved convergence tolerance: 1.665e-16
```
**Note**: When using the `function` method of `gsl_nls()`, the returned
object no longer has class `"nls"`,
``` r
class(ex3_fit)
#> [1] "gsl_nls"
```
However, all generics `anova`, `coef`, `confint`, `deviance`,
`df.residual`, `fitted`, `formula`, `logLik`, `predict`, `print`,
`residuals`, `summary`, `vcov` and `weights` remain applicable to
objects (only) of class `"gls_nls"`.
#### Method comparisons
Solving the same minimization problem with all available trust region
methods, i.e. `algorithm` set to `"lm"`, `"lmaccel"`, `"dogleg"`,
`"ddogleg"` and `"subspace2D"` respectively, and tracing the parameter
values at each iteration, we can visualize the minimization paths
followed by each method.

Analogous to the
[example](https://www.gnu.org/software/gsl/doc/html/nls.html#comparing-trs-methods-example)
in the GSL reference manual, the standard Levenberg-Marquardt method
without geodesic acceleration converges to the minimum at
"),
all other methods converge to the minimum at
").
### Example 4: Large NLS example
To illustrate the use of `gsl_nls_large()`, we reproduce the large
nonlinear least-squares example
()
from the GSL reference manual. The nonlinear least squares model is
defined as:
, \quad i = 1,\ldots,p \\
f_{p + 1} & \ = \Vert \boldsymbol{\theta} \Vert^2 - \frac{1}{4}
\end{aligned}
\right.")
with given constant
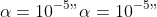
and unknown parameters
.
The residual

adds an
-regularization
constraint on the parameter vector and makes the model nonlinear. The
 \times p")-dimensional
Jacobian matrix is given by:
![\boldsymbol{J}(\boldsymbol{\theta}) \\= \\
\left\[ \begin{matrix}
\frac{\partial f_1}{\partial \theta_1} & \ldots & \frac{\partial f_1}{\partial \theta_p} \\
\vdots & \ddots & \vdots \\
\frac{\partial f\_{p+1}}{\partial \theta_1} & \ldots & \frac{\partial f\_{p+1}}{\partial \theta_p}
\end{matrix} \right\] \\=
\left\[ \begin{matrix}
\sqrt{\alpha} \boldsymbol{I}\_{p \times p} \\
2 \boldsymbol{\theta}'
\end{matrix} \right\]](https://latex.codecogs.com/png.latex?%5Cboldsymbol%7BJ%7D%28%5Cboldsymbol%7B%5Ctheta%7D%29%20%5C%20%3D%20%5C%20%0A%5Cleft%5B%20%5Cbegin%7Bmatrix%7D%20%0A%5Cfrac%7B%5Cpartial%20f_1%7D%7B%5Cpartial%20%5Ctheta_1%7D%20%26%20%5Cldots%20%26%20%5Cfrac%7B%5Cpartial%20f_1%7D%7B%5Cpartial%20%5Ctheta_p%7D%20%5C%5C%0A%5Cvdots%20%26%20%5Cddots%20%26%20%5Cvdots%20%5C%5C%0A%5Cfrac%7B%5Cpartial%20f_%7Bp%2B1%7D%7D%7B%5Cpartial%20%5Ctheta_1%7D%20%26%20%5Cldots%20%26%20%5Cfrac%7B%5Cpartial%20f_%7Bp%2B1%7D%7D%7B%5Cpartial%20%5Ctheta_p%7D%0A%5Cend%7Bmatrix%7D%20%5Cright%5D%20%5C%20%3D%20%0A%5Cleft%5B%20%5Cbegin%7Bmatrix%7D%0A%5Csqrt%7B%5Calpha%7D%20%5Cboldsymbol%7BI%7D_%7Bp%20%5Ctimes%20p%7D%20%5C%5C%0A2%20%5Cboldsymbol%7B%5Ctheta%7D%27%0A%5Cend%7Bmatrix%7D%20%5Cright%5D "\boldsymbol{J}(\boldsymbol{\theta}) \ = \
\left[ \begin{matrix}
\frac{\partial f_1}{\partial \theta_1} & \ldots & \frac{\partial f_1}{\partial \theta_p} \\
\vdots & \ddots & \vdots \\
\frac{\partial f_{p+1}}{\partial \theta_1} & \ldots & \frac{\partial f_{p+1}}{\partial \theta_p}
\end{matrix} \right] \ =
\left[ \begin{matrix}
\sqrt{\alpha} \boldsymbol{I}_{p \times p} \\
2 \boldsymbol{\theta}'
\end{matrix} \right]")
with

the
")-dimensional
identity matrix.
The model residuals and Jacobian matrix can be written as a function of
the parameter vector

as,
``` r
## model and jacobian
f <- function(theta) {
val <- c(sqrt(1e-5) * (theta - 1), sum(theta^2) - 0.25)
attr(val, "gradient") <- rbind(diag(sqrt(1e-5), nrow = length(theta)), 2 * t(theta))
return(val)
}
```
Here, the Jacobian is returned in the `"gradient"` attribute of the
evaluated vector (as in a `selfStart` model) from which it is detected
automatically by `gsl_nls()` or `gsl_nls_large()`.
First, the least squares objective is minimized with a call to
`gsl_nls()` analogous to the previous example by passing the nonlinear
model as a `function` and setting the response vector `y` to a vector of
zeros. The number of parameters is set to
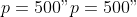
and as starting values we use
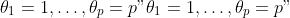
equivalent to the example in the GSL reference manual.
``` r
## number of parameters
p <- 500
## standard Levenberg-Marquardt
system.time({
ex4_fit_lm <- gsl_nls(
fn = f,
y = rep(0, p + 1),
start = 1:p,
control = list(maxiter = 500)
)
})
#> user system elapsed
#> 36.507 0.140 36.661
cat("Residual sum-of-squares:", deviance(ex4_fit_lm), "\n")
#> Residual sum-of-squares: 0.004778845
```
Second, the same model is fitted with a call to `gsl_nls_large()` using
the Steihaug-Toint Conjugate Gradient algorithm, which results in a much
smaller runtime:
``` r
## large-scale Steihaug-Toint
system.time({
ex4_fit_cgst <- gsl_nls_large(
fn = f,
y = rep(0, p + 1),
start = 1:p,
algorithm = "cgst",
control = list(maxiter = 500)
)
})
#> user system elapsed
#> 1.424 0.348 1.779
cat("Residual sum-of-squares:", deviance(ex4_fit_cgst), "\n")
#> Residual sum-of-squares: 0.004778845
```
#### Sparse Jacobian matrix
The Jacobian matrix
")
is very sparse in the sense that it contains only a small number of
nonzero entries. The `gsl_nls_large()` function also accepts the
calculated Jacobian as a sparse matrix of class `"dgCMatrix"`,
`"dgRMatrix"` or `"dgTMatrix"` (see the
[Matrix](https://cran.r-project.org/web/packages/Matrix/Matrix.pdf)
package). The following updated model function returns the sparse
Jacobian as a `"dgCMatrix"` instead of a dense numeric matrix:
``` r
## model and sparse Jacobian
fsp <- function(theta) {
val <- c(sqrt(1e-5) * (theta - 1), sum(theta^2) - 0.25)
attr(val, "gradient") <- rbind(Matrix::Diagonal(x = sqrt(1e-5), n = length(theta)), 2 * t(theta))
return(val)
}
```
As illustrated by the benchmarks below, besides a slight improvement in
runtimes, the required amount of memory is significantly smaller for the
model functions returning a sparse Jacobian than the model functions
returning a dense Jacobian:
``` r
## computation times and allocated memory
bench::mark(
"Dense LM" = gsl_nls_large(fn = f, y = rep(0, p + 1), start = 1:p, algorithm = "lm", control = list(maxiter = 500)),
"Dense CGST" = gsl_nls_large(fn = f, y = rep(0, p + 1), start = 1:p, algorithm = "cgst"),
"Sparse LM" = gsl_nls_large(fn = fsp, y = rep(0, p + 1), start = 1:p, algorithm = "lm", control = list(maxiter = 500)),
"Sparse CGST" = gsl_nls_large(fn = fsp, y = rep(0, p + 1), start = 1:p, algorithm = "cgst"),
check = FALSE,
min_iterations = 5
)
#> # A tibble: 4 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#>
#> 1 Dense LM 7.74s 7.8s 0.128 1.82GB 4.91
#> 2 Dense CGST 1.31s 1.32s 0.722 1.02GB 16.0
#> 3 Sparse LM 5.65s 5.67s 0.176 33.41MB 0.106
#> 4 Sparse CGST 149.31ms 158.18ms 6.44 23.04MB 3.86
```
## NLS test problems
The R-package currently contains a collection of 59 NLS test problems
originating primarily from the [NIST Statistical Reference Datasets
(StRD)](https://www.itl.nist.gov/div898/strd/nls/nls_main.shtml)
archive; Bates and Watts (1988); and Moré, Garbow, and Hillstrom (1981).
``` r
## avalable test problems
nls_test_list()
#> name class p n check
#> 1 Misra1a formula 2 14 p, n fixed
#> 2 Chwirut2 formula 3 54 p, n fixed
#> 3 Chwirut1 formula 3 214 p, n fixed
#> 4 Lanczos3 formula 6 24 p, n fixed
#> 5 Gauss1 formula 8 250 p, n fixed
#> 6 Gauss2 formula 8 250 p, n fixed
#> 7 DanWood formula 2 6 p, n fixed
#> 8 Misra1b formula 2 14 p, n fixed
#> 9 Kirby2 formula 5 151 p, n fixed
#> 10 Hahn1 formula 7 236 p, n fixed
#> 11 Nelson formula 3 128 p, n fixed
#> 12 MGH17 formula 5 33 p, n fixed
#> 13 Lanczos1 formula 6 24 p, n fixed
#> 14 Lanczos2 formula 6 24 p, n fixed
#> 15 Gauss3 formula 8 250 p, n fixed
#> 16 Misra1c formula 2 14 p, n fixed
#> 17 Misra1d formula 2 14 p, n fixed
#> 18 Roszman1 formula 4 25 p, n fixed
#> 19 ENSO formula 9 168 p, n fixed
#> 20 MGH09 formula 4 11 p, n fixed
#> 21 Thurber formula 7 37 p, n fixed
#> 22 BoxBOD formula 2 6 p, n fixed
#> 23 Ratkowsky2 formula 3 9 p, n fixed
#> 24 MGH10 formula 3 16 p, n fixed
#> 25 Eckerle4 formula 3 35 p, n fixed
#> 26 Ratkowsky3 formula 4 15 p, n fixed
#> 27 Bennett5 formula 3 154 p, n fixed
#> 28 Isomerization formula 4 24 p, n fixed
#> 29 Lubricant formula 9 53 p, n fixed
#> 30 Sulfisoxazole formula 4 12 p, n fixed
#> 31 Leaves formula 4 15 p, n fixed
#> 32 Chloride formula 3 54 p, n fixed
#> 33 Tetracycline formula 4 9 p, n fixed
#> 34 Linear, full rank function 5 10 p <= n free
#> 35 Linear, rank 1 function 5 10 p <= n free
#> 36 Linear, rank 1, zero columns and rows function 5 10 p <= n free
#> 37 Rosenbrock function 2 2 p, n fixed
#> 38 Helical valley function 3 3 p, n fixed
#> 39 Powell singular function 4 4 p, n fixed
#> 40 Freudenstein/Roth function 2 2 p, n fixed
#> 41 Bard function 3 15 p, n fixed
#> 42 Kowalik and Osborne function 4 11 p, n fixed
#> 43 Meyer function 3 16 p, n fixed
#> 44 Watson function 6 31 p, n fixed
#> 45 Box 3-dimensional function 3 10 p <= n free
#> 46 Jennrich and Sampson function 2 10 p <= n free
#> 47 Brown and Dennis function 4 20 p <= n free
#> 48 Chebyquad function 9 9 p <= n free
#> 49 Brown almost-linear function 10 10 p == n free
#> 50 Osborne 1 function 5 33 p, n fixed
#> 51 Osborne 2 function 11 65 p, n fixed
#> 52 Hanson 1 function 2 16 p, n fixed
#> 53 Hanson 2 function 3 16 p, n fixed
#> 54 McKeown 1 function 2 3 p, n fixed
#> 55 McKeown 2 function 3 4 p, n fixed
#> 56 McKeown 3 function 5 10 p, n fixed
#> 57 Devilliers and Glasser 1 function 4 24 p, n fixed
#> 58 Devilliers and Glasser 2 function 5 16 p, n fixed
#> 59 Madsen example function 2 3 p, n fixed
```
The function `nls_test_problem()` fetches the model definition and model
data required to solve a specific NLS test problem with `gsl_nls()` (or
`nls()` if the model is defined as a `formula`). This also returns the
vector of certified target values corresponding to the *best-available*
solutions and a vector of suggested starting values for the parameters:
``` r
## example regression problem
(ratkowsky2 <- nls_test_problem(name = "Ratkowsky2"))
#> $data
#> y x
#> 1 8.93 9
#> 2 10.80 14
#> 3 18.59 21
#> 4 22.33 28
#> 5 39.35 42
#> 6 56.11 57
#> 7 61.73 63
#> 8 64.62 70
#> 9 67.08 79
#>
#> $fn
#> y ~ b1/(1 + exp(b2 - b3 * x))
#>
#>
#> $start
#> b1 b2 b3
#> 100.0 1.0 0.1
#>
#> $target
#> b1 b2 b3
#> 72.4622376 2.6180768 0.0673592
#>
#> attr(,"class")
#> [1] "nls_test_formula"
with(ratkowsky2,
gsl_nls(
fn = fn,
data = data,
start = start
)
)
#> Nonlinear regression model
#> model: y ~ b1/(1 + exp(b2 - b3 * x))
#> data: data
#> b1 b2 b3
#> 72.46224 2.61808 0.06736
#> residual sum-of-squares: 8.057
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 10
#> Achieved convergence tolerance: 5.151e-14
## example optimization problem
madsen <- nls_test_problem(name = "Madsen")
with(madsen,
gsl_nls(
fn = fn,
y = y,
start = start,
jac = jac
)
)
#> Nonlinear regression model
#> model: y ~ fn(x)
#> x1 x2
#> -0.1554 0.6946
#> residual sum-of-squares: 0.7732
#>
#> Algorithm: multifit/levenberg-marquardt, (scaling: more, solver: qr)
#>
#> Number of iterations to convergence: 42
#> Achieved convergence tolerance: 2.22e-16
```
## Other R-packages
Other CRAN R-packages interfacing with GSL that served as inspiration
for this package include:
- [RcppGSL](https://cran.r-project.org/web/packages/RcppGSL/index.html)
by Dirk Eddelbuettel and Romain Francois
- [GSL](https://cran.r-project.org/web/packages/gsl/index.html) by Robin
Hankin and others
- [RcppZiggurat](https://cran.r-project.org/web/packages/RcppZiggurat/index.html)
by Dirk Eddelbuettel
Except for Barron’s family of loss functions, all robust loss functions
are credited to
[robustbase](https://cran.r-project.org/web/packages/robustbase/index.html)
by Martin Maechler and others.
## License
LGPL-3
# References
Bates, D.M., and D.G. Watts. 1988. *Nonlinear Regression Analysis and
Its Applications ISBN 0471816434*.
Galassi, M., J. Davies, J. Theiler, B. Gough, G. Jungman, M. Booth, and
F. Rossi. 2009. *GNU Scientific Library Reference Manual (3rd Ed.), ISBN
0954612078*. .
Hickernell, F.J., and Y. Yuan. 1997. “A Simple Multistart Algorithm for
Global Optimization.” *OR Transactions* 1(2).
Moré, J.J., B.S. Garbow, and K.E. Hillstrom. 1981. “Testing
Unconstrained Optimization Software.” *ACM Transactions on Mathematical
Software (TOMS)* 7(1).