https://github.com/jpleorx/detectron2-publaynet
Trained Detectron2 object detection models for document layout analysis based on PubLayNet dataset
https://github.com/jpleorx/detectron2-publaynet
artificial-intelligence computer-vision deep-learning detectron2 document-analysis document-classification document-layout document-layout-analysis faster-rcnn instance-segmentation layout-analysis machine-learning neural-network neural-networks object-detection publaynet python python3 pytorch
Last synced: about 1 year ago
JSON representation
Trained Detectron2 object detection models for document layout analysis based on PubLayNet dataset
- Host: GitHub
- URL: https://github.com/jpleorx/detectron2-publaynet
- Owner: JPLeoRX
- License: other
- Created: 2021-09-14T23:07:56.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2023-04-16T19:14:05.000Z (over 3 years ago)
- Last Synced: 2025-03-31T21:42:31.401Z (over 1 year ago)
- Topics: artificial-intelligence, computer-vision, deep-learning, detectron2, document-analysis, document-classification, document-layout, document-layout-analysis, faster-rcnn, instance-segmentation, layout-analysis, machine-learning, neural-network, neural-networks, object-detection, publaynet, python, python3, pytorch
- Language: Python
- Homepage:
- Size: 7.76 MB
- Stars: 48
- Watchers: 3
- Forks: 7
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE.txt
Awesome Lists containing this project
README
# Warning!!!
This repository is no longer maintained, as it was moved to another GitHub. Please see [CaseDrive](https://github.com/CaseDrive/publaynet-models) GitHub profile for any updates related to this research.
---
Here I present [Detectron2](https://github.com/facebookresearch/detectron2) object detection models trained on [PubLayNet](https://developer.ibm.com/exchanges/data/all/publaynet/) dataset, ranging from 81.139 to 86.690 in validation AP scores (possibly even better results can be achieved with longer training times).
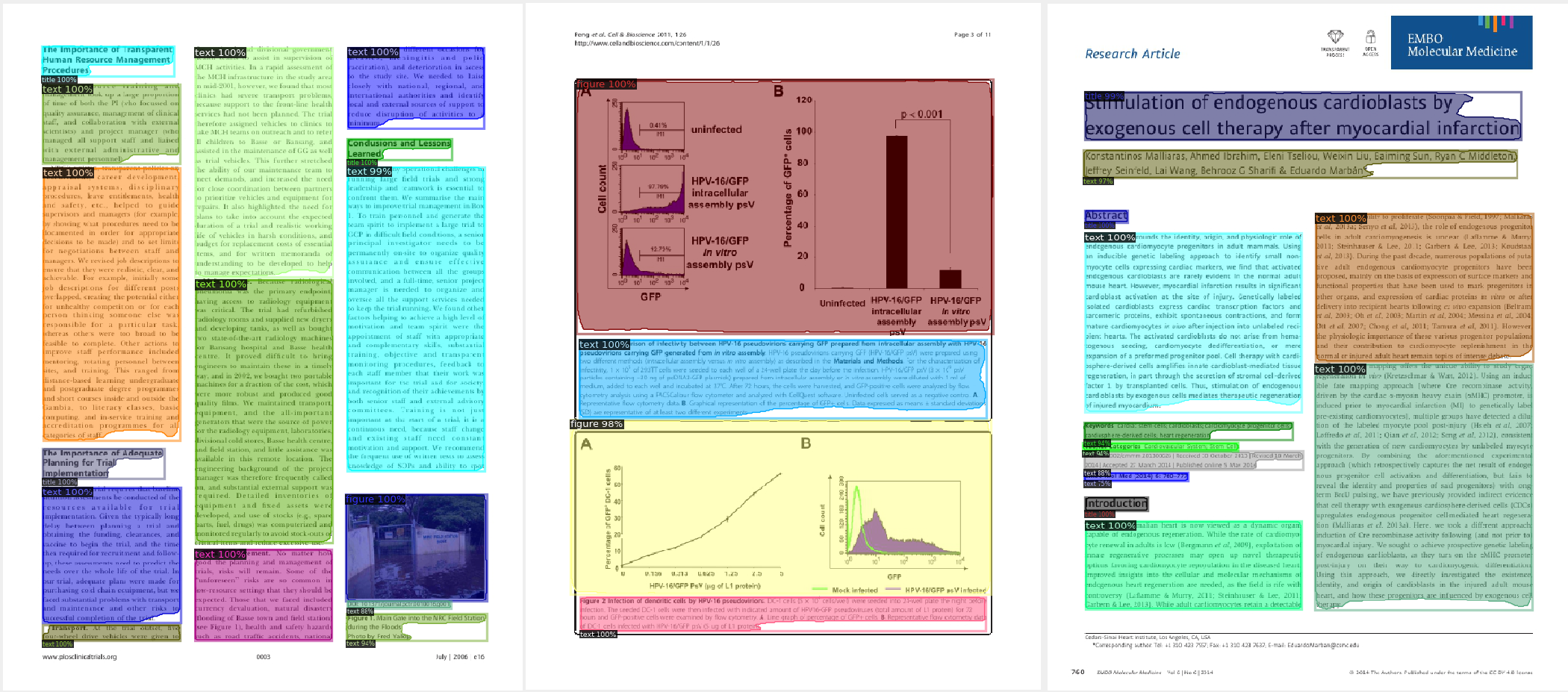
# Dataset overview
PubLayNet is a very large (over 300k images & over 90 GB in weight) dataset for document layout analysis. It contains images of research papers and articles and annotations for various elements in a page such as “text”, “list”, “figure” etc in these research paper images. The dataset was obtained by automatically matching the XML representations and the content of over 1 million PDF articles that are publicly available on PubMed Central. Originally provided by IBM [here](https://developer.ibm.com/exchanges/data/all/publaynet).
| Data Description | Zipped File Name | Purpose |
| ------------- | ------------- | ------------- |
| Train 0 Dataset, 13 GB | [train-0.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-0.tar.gz) | Training |
| Train 1 Dataset, 13 GB | [train-1.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-1.tar.gz) | Training |
| Train 2 Dataset, 13 GB | [train-2.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-2.tar.gz) | Training |
| Train 3 Dataset, 13 GB | [train-3.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-3.tar.gz) | Training |
| Train 4 Dataset, 13 GB | [train-4.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-4.tar.gz) | Training |
| Train 5 Dataset, 13 GB | [train-5.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-5.tar.gz) | Training |
| Train 6 Dataset, 13 GB | [train-6.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/train-6.tar.gz) | Training |
| Evaluation Dataset, 3 GB | [val.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/val.tar.gz) | Evaluation |
| Labels Dataset, 314 MB | [labels.tar.gz](https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/labels.tar.gz) | |
# Models overview
Models were trained on `train` part of the dataset, consisting of 335 703 images, and evaluated on `val` part of the dataset with 11 245 images. All the AP scores were obtained on the `val` dataset. Inference times were taken from official Detectron model zoo descriptions.
To provide you with some options, and to experiment with different models I have trained 4 versions for this dataset. 2 of them are from basic object detection, and 2 contain segmentation masks. You can choose which better suits your task by comparing accuracy scores and inference times of these models.
### Models from [COCO Object Detection](https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md#coco-object-detection-baselines):
| Name | Inference time (s/im) | Box AP | Folder name | Model zoo config | Trained model |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| R50-FPN | 0.038 | 81.139 | faster_rcnn_R_50_FPN_3x | [Click me!](https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml) | [Click me!](https://keybase.pub/jpleorx/detectron2-publaynet/faster_rcnn_R_50_FPN_3x) |
| R101-FPN | 0.051 | 84.295 | faster_rcnn_R_101_FPN_3x | [Click me!](https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml) | [Click me!](https://keybase.pub/jpleorx/detectron2-publaynet/faster_rcnn_R_101_FPN_3x) |
### Models from [COCO Instance Segmentation with Mask R-CNN](https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md#coco-instance-segmentation-baselines-with-mask-r-cnn):
| Name | Inference time (s/im) | Box AP | Mask AP | Folder name | Model zoo config | Trained model |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| R50-FPN | 0.043 | 83.666 | 82.268 | mask_rcnn_R_50_FPN_3x |[Click me!](https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml) | [Click me!](https://keybase.pub/jpleorx/detectron2-publaynet/mask_rcnn_R_50_FPN_3x) |
| R101-FPN | 0.056 | 86.690 | 82.105 | mask_rcnn_R_101_FPN_3x | [Click me!](https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x.yaml) | [Click me!](https://keybase.pub/jpleorx/detectron2-publaynet/mask_rcnn_R_101_FPN_3x) |
### Model folder
Each model's directory in git will contain these files:
| File name | Description |
| ------------- | ------------- |
| download.txt | A text file that contains a link from where you can download the trained model |
| train.py | Training script, that trains the model found in `training_output` sub-folder for a given number of epochs |
| test.py | Testing script, that runs the model found in `training_output` in inference mode for 6 randomly preselected images (3 from training, 3 from evaluation datasets) and displays all predictions on each image in a pop-up window |
| eval.py | Testing script, that runs the model found in `training_output` in inference mode for all images found in dataset's `val` folder and `val.json`. Evaluation is performed through Detectron's `COCOEvaluator` |
| evaluation.txt | As `eval.py` takes some time to execute (from 10 to 20 minutes) I've recorded last output of evaluation in this separate text file |
Generally all trained models `.pth` files should be available through [here](https://keybase.pub/jpleorx/detectron2-publaynet/) or [here](https://drive.google.com/drive/folders/11BeTAb8BlS9DiEb_ndoAh1fKyq16i6FC?usp=sharing), but if not - refer to individual `download.txt` links
# Using the models
In `usage_example` module I've provided a sample script `example.py` that builds Detectron objects (config and predictor) for my trained model and runs inference on it, with a sample interpretation of Detectron's outputs. Please note that `test.py` and `eval.py` in model folders use common functions shared between models in this project. While `example.py` provides a completely clean setup, assuming you only want to download the models and use them for inference directly. It requires only Pillow, OpenCV, numpy and Detectron2 to run.
# Hardware used
Believe it or not but training of these models was performed on a regular consumer-grade personal gaming PC with one NVIDIA 2070 SUPER (8GB) GPU, Intel Core i5-10600K CPU and 32 GB RAM.
# Links
In case you’d like to check my other work or contact me:
* [Personal website](https://tekleo.net/)
* [GitHub](https://github.com/jpleorx)
* [PyPI](https://pypi.org/user/JPLeoRX/)
* [DockerHub](https://hub.docker.com/u/jpleorx)
* [Articles on Medium](https://medium.com/@leo.ertuna)
* [LinkedIn (feel free to connect)](https://www.linkedin.com/in/leo-ertuna-14b539187/)