https://github.com/justorez/pica-cli
😉 哔咔漫画下载器
https://github.com/justorez/pica-cli
bika cli downloader pica
Last synced: 6 months ago
JSON representation
😉 哔咔漫画下载器
- Host: GitHub
- URL: https://github.com/justorez/pica-cli
- Owner: justorez
- License: mit
- Created: 2024-01-28T15:16:10.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2025-10-08T08:04:18.000Z (9 months ago)
- Last Synced: 2025-10-08T10:08:39.223Z (9 months ago)
- Topics: bika, cli, downloader, pica
- Language: TypeScript
- Homepage:
- Size: 1020 KB
- Stars: 155
- Watchers: 2
- Forks: 396
- Open Issues: 1
-
Metadata Files:
- Readme: readme.md
- License: LICENSE
Awesome Lists containing this project
README
# pica-cli
[](https://www.npmjs.com/package/pica-cli)
[](https://github.com/justorez/pica-cli/actions/workflows/publish.yml)
[](http://commitizen.github.io/cz-cli/)
😉 哔咔漫画下载器

- 排行榜:下载当前排行榜的全部漫画
- 收藏夹:下载当前用户收藏夹的全部漫画
- 搜索:支持关键字和漫画ID (多个用 # 隔开)。访问哔咔电脑端网站,进入漫画详情,地址栏链接里的 `cid` 就是漫画ID
- 自动过滤已下载的章节和图片,不会重复下载
- 按章节批量压缩,配合支持 zip 的漫画阅读软件使用,比如 [Perfect Viewer](https://play.google.com/store/apps/details?id=com.rookiestudio.perfectviewer)。不限于 `pica-cli` 下载的漫画,只要符合 [cmoics/漫画标题/漫画章节/漫画图片](#) 的目录结构即可。
- 借助 github action 实现飞速下载,支持从 github artifact 和 file.io 两种方式下载完整漫画包。file.io 无需注册,无需科学上网,文件保存两周,单文件最大 2GB,注意链接只能下载**一次**,下载后文件会自动删除
- [更新日志](#更新日志)
如果用的开心,求个 star 支持一下,比心 ~ ❤️
## 用法
### 方式一:GitHub Action(推荐)
> ❗️**一次性下载大量漫画,可能会导致 Action 磁盘空间不足或者长时间运行导致任务失败,所以不要一次性下载太多**
利用 github 的免费服务器下载,最关键的是不用科学上网,网速飞快,孩子用了都说好。
```bash
# 必填,账号名
PICA_ACCOUNT
# 必填,账号密码
PICA_PASSWORD
```
Fork 一份[本仓库](https://github.com/justorez/pica-cli),将上面两个环境变量,设置为仓库密钥:
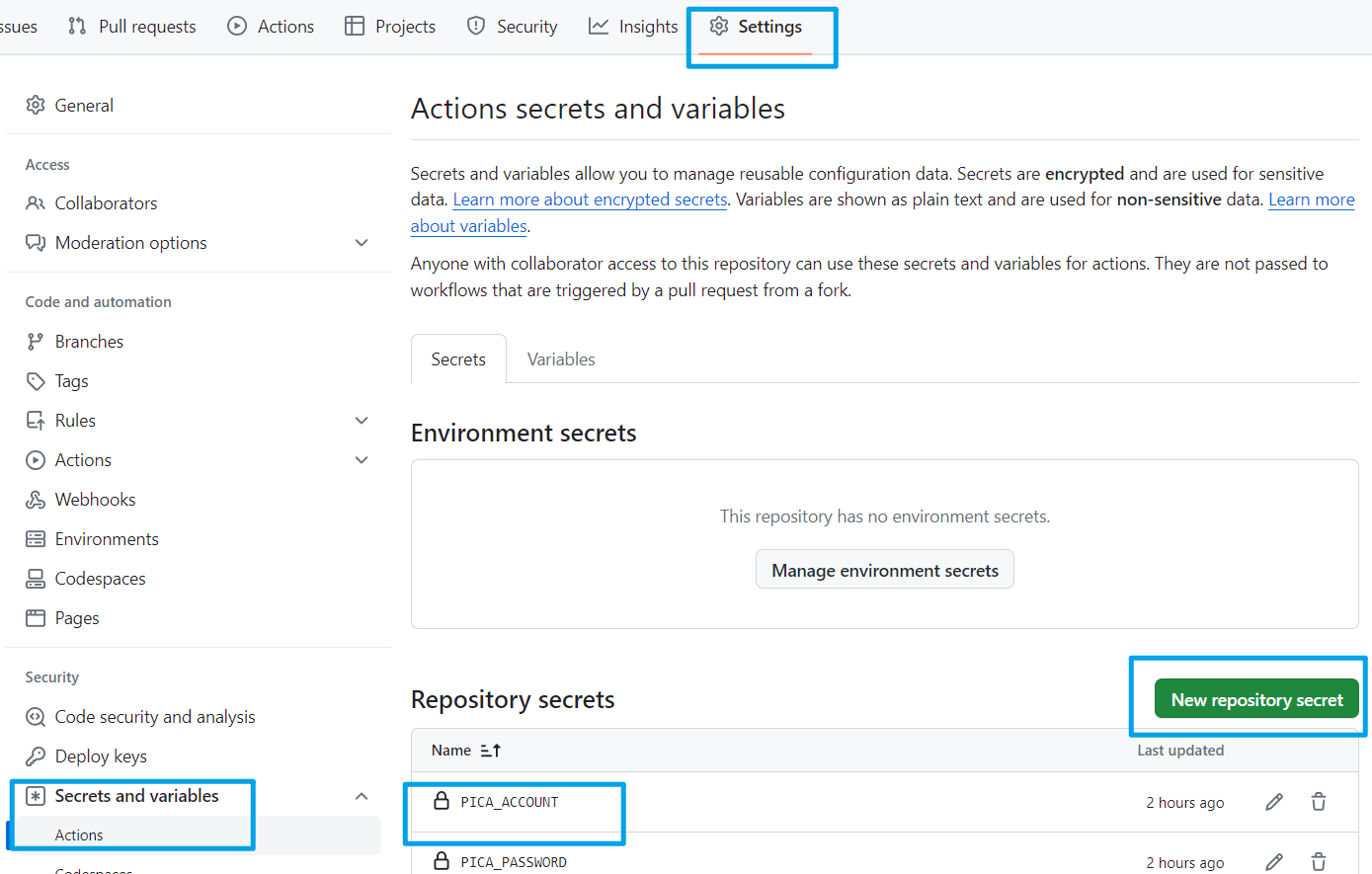
然后点击 Actions,再点击左侧的 `task` 工作流,再点击右侧的 `Run workflow`,输入相关的信息,点击运行。
针对收藏夹漫画太多的情况,已支持指定页码,每次只下载收藏夹的某一页即可。
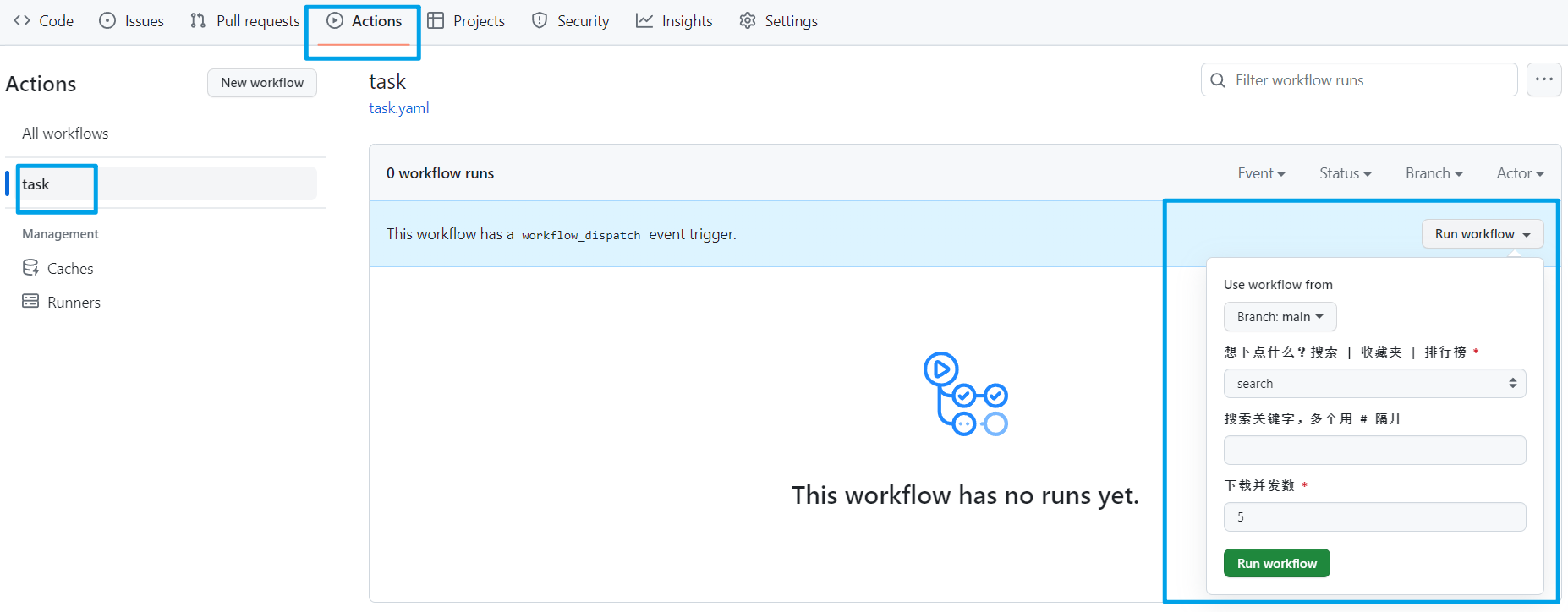
等执行完之后,进入详情,在最下方有漫画的完整压缩包,点击下载即可。
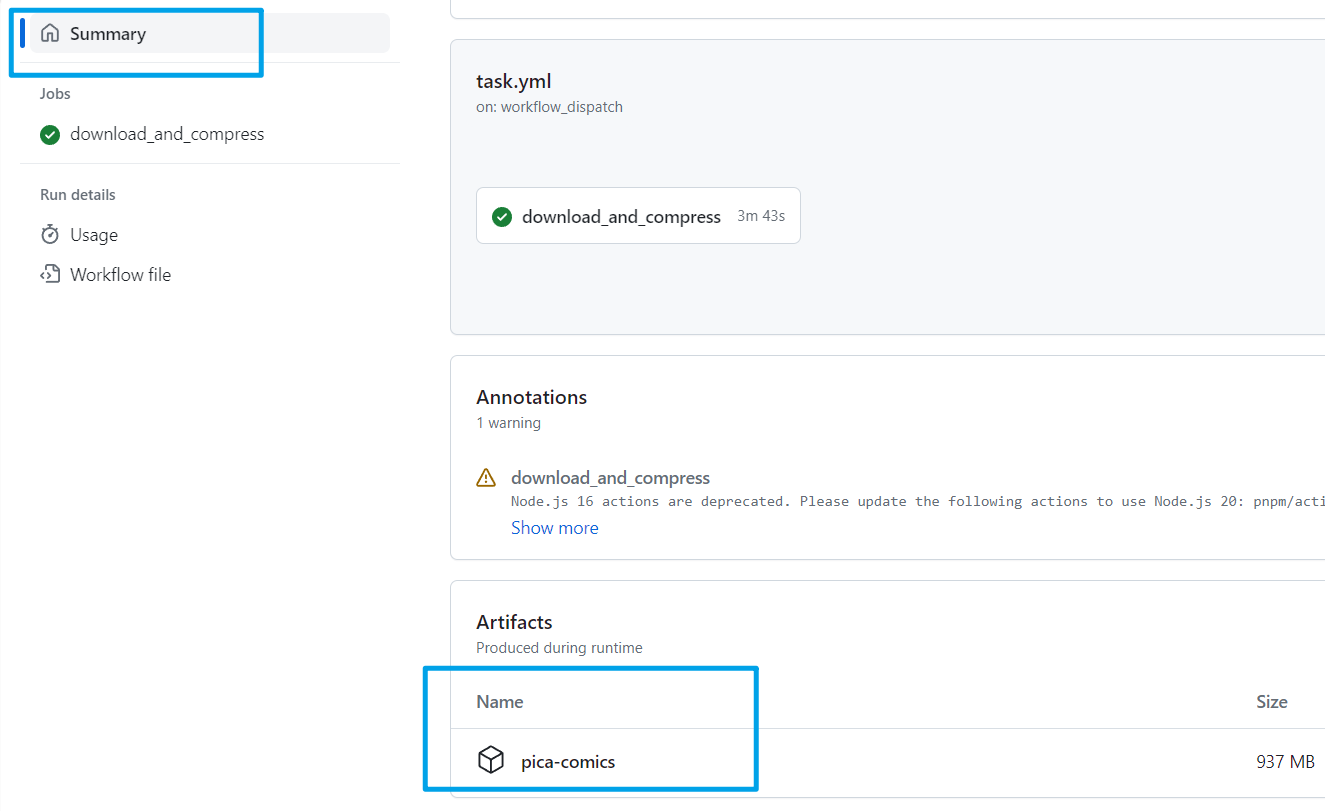
点击 job 详情查看日志,可以看到 file.io 的下载地址:
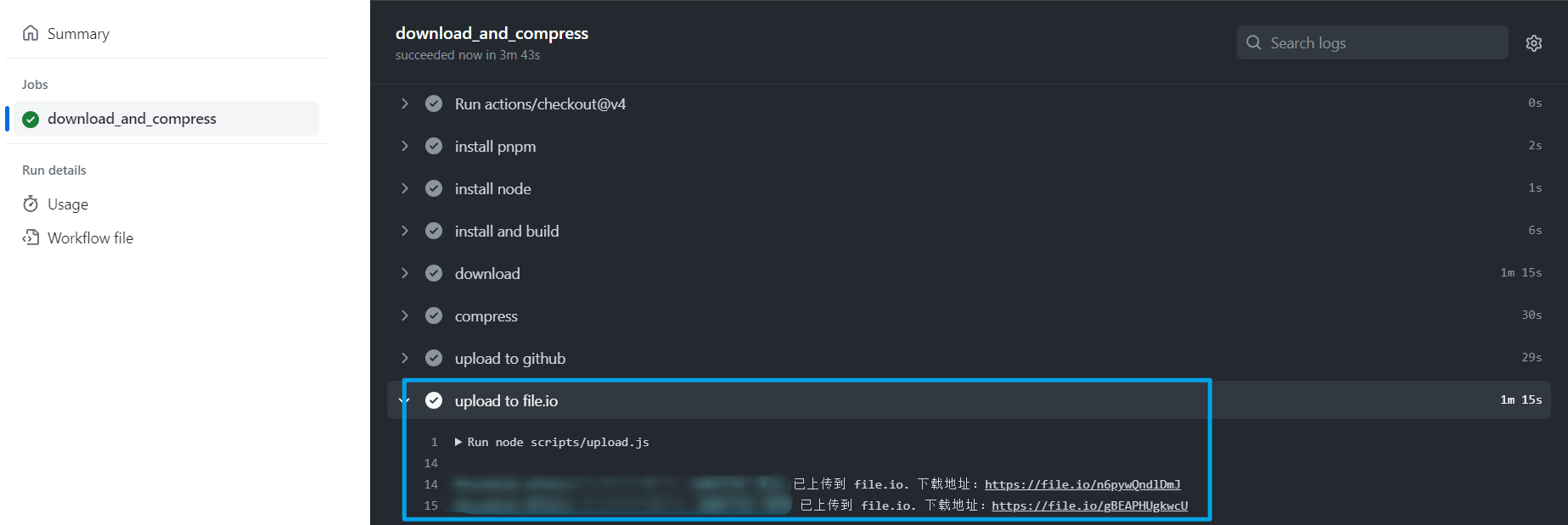
如果你想自定义过程,请自行修改 [.github/workflows/task.yml](.github/workflows/task.yml)。
### 方式二:直接安装
```bash
pnpm add pica-cli -g
```
在自己电脑上配置好环境变量,所需的环境变量如下所示:
```bash
# 账号名
# 若无配置,会提示手动输入
PICA_ACCOUNT=
# 账号密码
# 若无配置,会提示手动输入
PICA_PASSWORD=
# 代理地址,示例:http://127.0.0.1:7890
PICA_PROXY=
# 下载图片的并发数,默认 5
PICA_DL_CONCURRENCY=5
# search | favorites | leaderboard
# 下载内容,分别表示:搜索 | 收藏夹 | 排行榜
PICA_DL_CONTENT=
# 搜索关键字或漫画ID,多个用 # 隔开
# 尽量输入完整漫画名,避免返回过多结果
PICA_DL_SEARCH_KEYWORDS=
```
```bash
# 运行
pica-cli
# 漫画打压缩包
pica-zip
```
## 开发
```bash
git clone https://github.com/justorez/pica-cli.git
```
拷贝一份 [.env.template](.env.template),命名为 `.env.local`,填写好后就不用设置环境变量了,配置优先从 `.env.local` 里加载。
```bash
# 安装依赖
pnpm install
# 运行
pnpm dev
# 漫画打压缩包
pnpm dev:zip
```
[哔咔 API 文档(非官方)](https://www.apifox.cn/apidoc/shared-44da213e-98f7-4587-a75e-db998ed067ad/doc-1034189)。
## 更新日志
- 2024/06/02 支持下载收藏夹指定页
- 2024/05/27 修复收藏夹只获取了第一页
- 2024/04/27 处理响应 400 异常:被禁止访问的漫画
- 2024/02/21 支持通过命令行输入账号密码,硬编码密钥
- 2024/02/08 支持下载指定章节
- 2024/02/01 支持通过漫画ID精确下载
- 2024/01/31 github action 同时将漫画包上传到 file.io
- 2024/01/30 提供 github action 的下载方式
- 2024/01/29 下载完成后,提供命令把漫画按章节批量压缩
- 2024/01/28 完成基本功能
## 其他
代码参考了 [pica_crawler](https://github.com/lx1169732264/pica_crawler),本来是想添加新功能,奈何 Python 早就忘光了,只好重写一个。