Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/jyolo/wLogger
wLogger 是一款集合 日志采集,日志解析持久化存储,web流量实时监控 。三位一体的web服务流量监控应用。 三大功能模块均可独立部署启用互不干扰。目前已内置 nginx 和 apache 的日志解析存储器,简单配置一下,开箱即用。
https://github.com/jyolo/wLogger
Last synced: 5 days ago
JSON representation
wLogger 是一款集合 日志采集,日志解析持久化存储,web流量实时监控 。三位一体的web服务流量监控应用。 三大功能模块均可独立部署启用互不干扰。目前已内置 nginx 和 apache 的日志解析存储器,简单配置一下,开箱即用。
- Host: GitHub
- URL: https://github.com/jyolo/wLogger
- Owner: jyolo
- License: apache-2.0
- Created: 2020-12-09T09:39:53.000Z (almost 4 years ago)
- Default Branch: master
- Last Pushed: 2021-10-26T02:57:08.000Z (about 3 years ago)
- Last Synced: 2024-08-01T22:47:49.002Z (3 months ago)
- Language: JavaScript
- Homepage:
- Size: 5.29 MB
- Stars: 506
- Watchers: 15
- Forks: 103
- Open Issues: 3
-
Metadata Files:
- Readme: README.MD
- License: LICENSE
Awesome Lists containing this project
README
# 介绍
> wLogger 介绍
* 介绍
wLogger 是一款集合 日志采集,日志解析持久化存储,web流量实时监控 。三位一体的web服务流量监控应用。
三大功能模块均可独立部署启用互不干扰。目前已内置 nginx 和 apache 的日志解析存储器,简单配置一下,开箱即用。
虽然市面上已经很多类似的开源日志采集监控服务比如goaccess,用了一圈之后始终没有一款用的特别舒心。
* 它可以在日志采集的时候可以按照日志文件的大小,或者在指定时间内自动对日志进行切割日志,存储到指定的目录 (已测2W并发切割日志不丢数据)
* 它可以不用像goaccess那样必须配置指定格式才能解析到数据,只用指定当前使用的 nginx/apache 日志格式名称 即可解析数据
* 它可以指定不同的项目走不同的队列服务,分别解析存储到不同的数据库,完全可以自己按需灵活配置
* 它天然支持分布式,日志采集服务队列已内置redis LIST结构,可自行拓展kafka ,mq等其它队列服务
* 它支持自定义持久化存储引擎,日志解析持久化存储服务已内置 mongodb 和 mysql ,可自行拓展其它数据库
* 简单配置,开箱即用,无入侵,高拓展,灵活配置,按需应用
* 运行环境:python3+ linux平台
如果该项目有帮助到您,请不要吝啬随手给个star
您也可以从数据库中取数据自己定义流量监控的UI界面和数据展现方式;
大屏实时监控效果图 本人显示器太小,截图略显拥挤;
QQ交流群 : 862251895
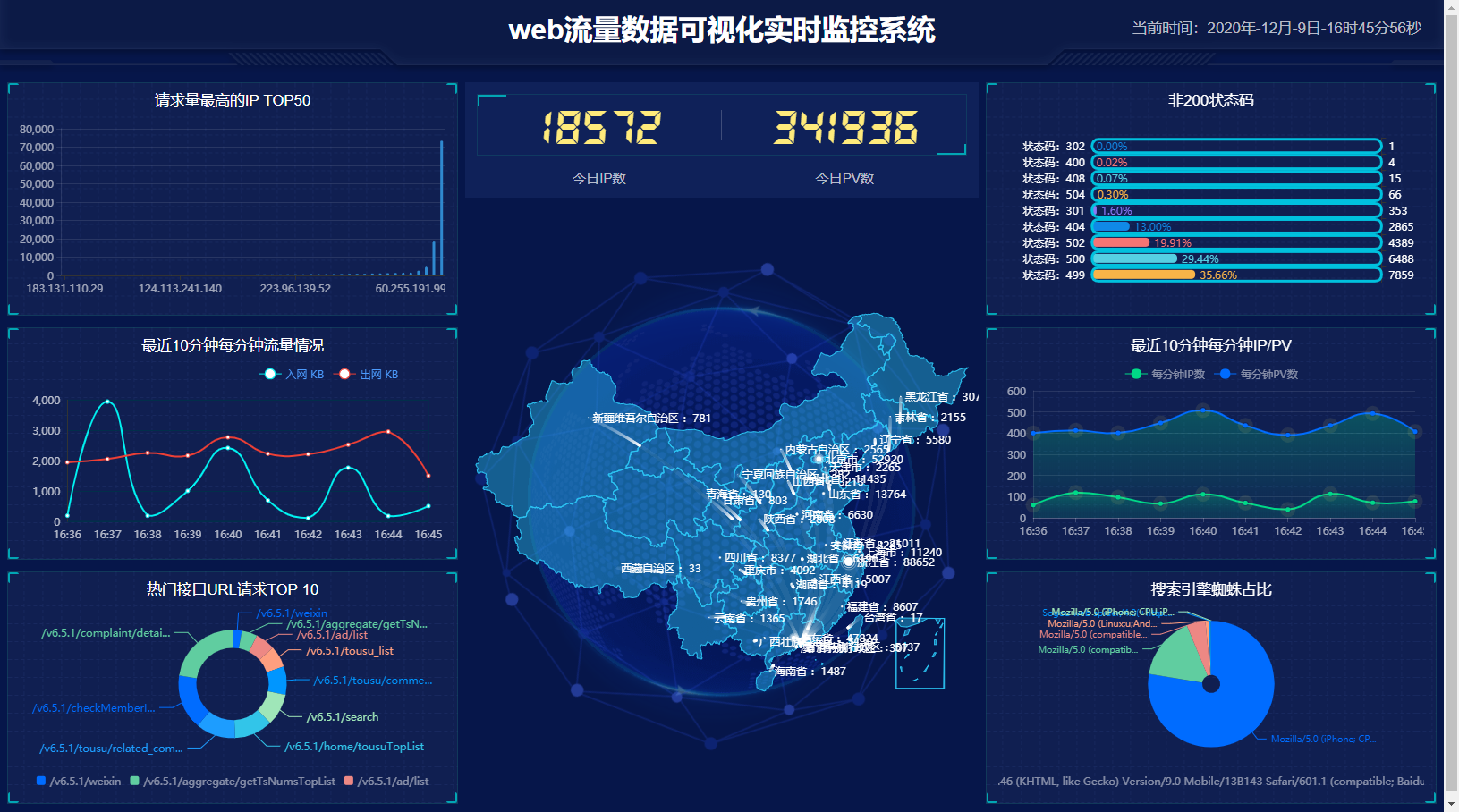
> 功能说明
采集器 inputer
* 实时日志采集,同时支持多个web日志同时采集
* 可指定按照日志文件大小或指定时间,自动切割文件到指定目录, (日志切割不丢数据.)
* 可自定义队列服务软件,接受采集的日志信息. 已内置redis 如需kafka 等其它mq队列可自行拓展
* 极低的cpu内存占用 ,低配小主机也能愉快的玩耍
解析存储器 outputer
* 实时解析日志并存储到指定的数据库, 已内置 mysql 和 mongodb 如需使用elastic全家桶或其它存储引擎 可自行拓展
* 采集器,解析器,web服务均可 独立分布到不同的服务器节点上运行
* 目前已内置 nginx,apache 解析器, 可随意指定日志格式, 只需在配置文件里面指定格式名称即可正确解析并存储
* 支持按日期天,周,月,年. 自动分表或集合存储日志
* 支持指定工作进程来快速消费队列数据,大流量也能实时解析并存储日志, 虚拟机中ab 实测2W并发延迟小于1秒
* 注: 当海量流量来的时候发现解析存储延迟过高的情况,可将解析器部署到集群中其它多个节点同时消费队列数据,提升解析存储效率
web服务 web
* 已内置大屏监控web面板,流量情况一目了然
* 同时支持 mysql 或者 mongodb 作为 数据源
# 快速开始
> 安装拓展
sudo pip3 install -r requirements.txt
> 启动 采集器
sudo python3 main.py -r inputer -c config.ini
> 启动 解析存储器
sudo python3 main.py -r outputer -c config.ini
> 启动 web服务
sudo python3 main.py -r web -c config.ini
> 查看命令行帮助
python3 main.py --help
* 以上三个应用均可单独部署和启用
-r --run ; start ['inputer', 'outputer','web']
-s --stop ; stop ['inputer', 'outputer']
-c --config ; bind config.ini file
> docker 支持
docker pull jyolo/wlogger:v1.3 或者 docker build -t yourTagName .
example:
# 启动 web 服务
docker run jyolo/wlogger:v1.3 -r web -c config.ini # 需要把配置文件复制或者挂载进 容器中/wLogger 目录内
# 启动 解析存储器 服务
docker run jyolo/wlogger:v1.3 -r outputer -c config.ini # 需要把配置文件复制或者挂载进 容器中/wLogger 目录内
* 由于采集器 inputer 中切割日志操作,需要操作容器外部 nginx/apache 相关服务器,因此无法在docker中隔离环境下运行 .
* 如果容器中有部署nginx 或者 apache 则可以
# 配置详解
> 公共配置
# 当 inputer 和 outputer 中指定了 server_type = nginx 才需此配置
[nginx]
pid_path = /www/server/nginx/logs/nginx.pid # 指定 nginx.pid 的绝对路径
server_conf = /www/server/nginx/conf/nginx.conf # 指定 nginx 配置文件的绝对路径
# 当 inputer 和 outputer 中指定了 server_type = apache 才需此配置
[apache]
apachectl_bin = /www/server/apache/bin/apachectl # 指定 apachectl 命令的绝对路径
server_conf = /www/server/apache/conf/httpd.conf # 指定 apache 配置文件的绝对路径
# 当 inputer 和 outputer 中指定了 queue = redis 才需此配置
[redis]
host = 127.0.0.1
port = 6379
password = xxxxxxxx
db = 1
# 当 outputer 中 save_engine = mysql 或 web 中 data_engine = mysql 才需此配置
[mysql]
host = 127.0.0.1
port = 3306
username = nginx_logger
password = xxxxxxxx
db = nginx_logger
table = logger
split_save = day # 当有该配置项则代表开启自动分表 目前支持按 天,周,月,年 ;参数:[day, week, month ,year] ,进行存储
# 当 outputer 中save_engine = mongodb 或 web 中 data_engine = mongodb 需此配置
[mongodb]
host = 127.0.0.1
port = 27017
username = logger_watcher
password = xxxxxxxx
db = nginx_logger
collection = logger
split_save = day # 当有该配置项则代表开启自动分集合 目前支持按 天,周,月,年 ;参数:[day, week, month ,year] ,进行存储
> 日志采集端 配置
[inputer]
log_debug = True # 开启日志debug模式 会在项目中生成日志文件。 类似 : inputer_config.ini.log 名称的日志文件
node_id = server_80 # 当前节点ID 唯一
queue = redis # 队列配置 目前内置了 [redis , mongodb]
queue_name = queue_logger # 队列 key 的名称
max_batch_push_queue_size = 5000 # 每次最多批量插入队列多少条数据
max_retry_open_file_time = 10 # 当文件读取失败之后重新打开日志文件,最多重试多少次
max_retry_reconnect_time = 20 # 连接队列失败的时候,最多重试多少次
[inputer.log_file.web1] # inputer.log_file.web1 中的 web1 代表应用名称 唯一 app_name
server_type = nginx # 服务器应用 [nginx ,apache]
file_path = /wwwlogs/ww.aaa.com.log # 日志绝对路径
log_format_name = online # 配置文件中 日志名称 example : "access_log /www/wwwlogs/xxx.log online;" 中的 `online` 则代表启用的日志配置名称
read_type = tail # 读取文件方式 支持 tail 从末尾最后一行开始 ; head 从头第一行开始 * 当文件较大的时候 建议使用 tail
cut_file_type = filesize # 切割文件方式 支持 filesize 文件大小单位M ;time 指定当天时间 24:00
cut_file_point = 200 # 切割文件条件节点 当 filesize 时 200 代表200M 切一次 ; 当 time 时 24:00 代表今天该时间 切一次
cut_file_save_dir = /wwwlogs/cut_file/ # 日志切割后存储绝对路径
[inputer.log_file.web2] # 支持同时采集多个应用日志 追加配置即可
..........................
> 日志解析存储端
[outputer]
log_debug = True # 开启日志debug模式 会在项目中生成日志文件。 类似 : outpuer_config.ini.log 名称的日志文件
save_engine = mongodb # 解析后的日志存储引擎目前支持 [mysql,mongodb]
queue = redis # 队列引擎 此处需要和 inputer 采集端保持一致
queue_name = queue_logger # 队列中 key 或 collection 集合的名称 此处需要和 inputer 采集端保持一致
server_type = nginx # 服务器的类型
worker_process_num = 1 # 指定工作进程数量 根据自己网站流量情况而定,一般4个worker即可
max_batch_insert_db_size = 1 # 最多每次批量写入存储引擎的数量,根据自己应用情况而定,一般5000即可
max_retry_reconnect_time = 200 # 连接存储引擎失败后,最多重试连接次数
> 大屏监控端
[web]
env = development # 运行环境 development | production
debug = True # 是否开启 debug
secret_key = xxxx # flask session key
host = 127.0.0.1 # 指定ip
port = 5000 # 指定端口
server_name = 127.0.0.1:5000 # 绑定域名和端口 (不推荐 ,如果是要nginx反代进行访问的话 请不要配置此项.)
data_engine = mysql # 指定读取日志存储数据库引擎 目前内置了 [ mysql , mongodb ]