Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/kabachuha/nanogpkant
Testing KAN-based text generation GPT models
https://github.com/kabachuha/nanogpkant
gpt kan kanformers kolmogorov-arnold-networks kolmogorov-arnold-representation llm text-generation transformers
Last synced: 17 days ago
JSON representation
Testing KAN-based text generation GPT models
- Host: GitHub
- URL: https://github.com/kabachuha/nanogpkant
- Owner: kabachuha
- License: mit
- Created: 2024-05-06T19:21:56.000Z (7 months ago)
- Default Branch: main
- Last Pushed: 2024-05-06T19:46:17.000Z (7 months ago)
- Last Synced: 2024-10-11T12:56:04.877Z (about 1 month ago)
- Topics: gpt, kan, kanformers, kolmogorov-arnold-networks, kolmogorov-arnold-representation, llm, text-generation, transformers
- Language: Jupyter Notebook
- Homepage:
- Size: 583 KB
- Stars: 14
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# nanoGPKANT = nano + Generative + Pretrained + Kolmogorov-Arnold-Network + Transformer
-- which is an ironic reference to Emmanuel Kant because he wrote "Critique of Pure Reason".
Structurally, a playground hybrid of `nanoGPT` and `kanformers` for easier exploration of KAN-based LLMs and maybe later scaling laws.
We train a simple downsided 2 decoder kan-transformer and see how it works. (spoiler: not THAT good yet)
## Early results and observations:
Training instructions — see https://github.com/karpathy/nanoGPT/tree/master?tab=readme-ov-file#quick-start.
### Training on shakespeare dataset:
Configs used:
1. train_shakespeare_char_micro_kan
```
n_layer = 2
n_head = 6
n_embd = 192
dropout = 0.2
```
2. train_shakespeare_char_micro (vanilla model)
```
n_layer = 2
n_head = 6
n_embd = 192
dropout = 0.2
```
3. train_shakespeare_char_micro_boosted_parameters (vanilla model)
This run is needed to balance out KAN's parameter increase because of splines.
*Perfectly balanced. As all GPTs should be.*
```
n_layer = 16
n_head = 6
n_embd = 192
dropout = 0.2
```
**GPKANT's process**
Number of parameters: 8.86M
Peak training VRAM consumption = `15.385 GB`
KAN's training is REALLY slow, it took 38 mins on a 4090.
**GPT process**
Number of parameters: 0.90M
Peak training VRAM consumption = `1.893 GB`, just one minute.
**Balanced GPT process**
Number of parameters: 7.10M
Peak training VRAM consumption = `5.791 GB`, 8 minutes.
### Now let's see what nonsence our GPTKANT model has generated
Let's see if our embryoGPKANT generated nonsence:
```
Clown:
So, whom and is not the disposition of a virtuous
call'd
here's the put of her back that aner with my faces
are his mother, and fortune of my head
and ever weeds his traitor, and by the death
news in the spel lind of his husband with a crown.
MENENIUS:
Mark, nor open is death:
I will make all already him evil so, and doubt, and
she earth-of my heart
he kindness forf sorrow the most win malice;
and fear of my omitrage, being by his wards.
MENENIUS:
But he must are no more stoops and may
---------------
Menenius, and such of contract me
That he severence by well throat them from her themselves.
O, my lord, peace! and so, madam, so not peace
Or his pardon's love, if it state of course
That may in the world Richard: there I should not go,
Which in him mother the babels against uncle
Of the voices, and, thou welcome this hearts
Of substite in his proper honour attempet thee:
Still be done thee summer in the other;
And so the silence of like a cursed;
For thou mayst do it, would have not one.
```
WHOAH! Oh, my! It's alive! It's alive! At least it works.
The rest of the texts (included the above), is put into the folder 'generated_texts'. They are readable as well, so it's not a too unique capability.
---
But is GPKANT really better? 🤔
## WANDB Validation loss comparison:
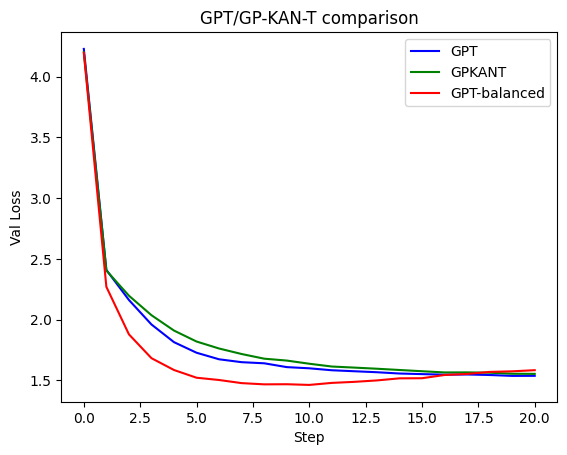
Well, the KAN's progress is not looking very great here compared to the same-level GPTs.
## WANDB stats:
https://wandb.ai/kabachuha/shakespeare-char
## Pretrained checkpoints:
Because it's a Generative PrEtRaInEd (KAN) Transformer, we need to opensource the checkpoints.
Here you can download them from my Google Drive. If there is demand, I can put them on HuggingFace.
https://drive.google.com/drive/folders/14FlTVmZjZxR57my9lv7VIUvxQPIZxaf0?usp=sharing
## Reused code:
Big thanks to these amazing guys!
nanoGPT https://github.com/karpathy/nanoGPT by Andrej Karpathy
kansformers https://github.com/akaashdash/kansformers by Akaash Dash
Also to the KAN paper authors: https://github.com/KindXiaoming/pykan
The respective licenses situate in the file THIRD_PARTY_LICENSES. (The code from this repo and from the aforementioned ones is MIT-licensed and you can use it basically everywhere.)
And, of course, I want to say additional thanks to the original concept makers — Andrey Kolmogorov and Vladimir Arnold.
## Future work:
-> The first one: **extract spline plots and formulae from the KAN layers.**
-> Measure perplexity.
-> Train on larger datasets.
-> ...
Feel free to give your ideas and suggestions. Let's see if we can improve KAN-based transformers.
---
Will KAN's accelerate our destruction as species? Only time will tell.