Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/karpathy/covid-sanity
Aspires to help the influx of bioRxiv / medRxiv papers on COVID-19
https://github.com/karpathy/covid-sanity
Last synced: 6 days ago
JSON representation
Aspires to help the influx of bioRxiv / medRxiv papers on COVID-19
- Host: GitHub
- URL: https://github.com/karpathy/covid-sanity
- Owner: karpathy
- License: mit
- Created: 2020-03-30T01:20:10.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2020-05-03T17:51:52.000Z (almost 5 years ago)
- Last Synced: 2025-02-06T09:07:47.128Z (14 days ago)
- Language: Python
- Homepage: http://biomed-sanity.com/
- Size: 299 KB
- Stars: 361
- Watchers: 16
- Forks: 48
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
# covid-sanity
This project organizes COVID-19 SARS-CoV-2 preprints from medRxiv and bioRxiv. The raw data comes from the [bioRxiv](https://connect.biorxiv.org/relate/content/181) page, but this project makes the data searchable, sortable, etc. The "most similar" search uses an exemplar SVM trained on tfidf feature vectors from the abstracts of these papers. The project is running live on [biomed-sanity.com](http://biomed-sanity.com/). (I could not register covid-sanity.com because the term is "protected")
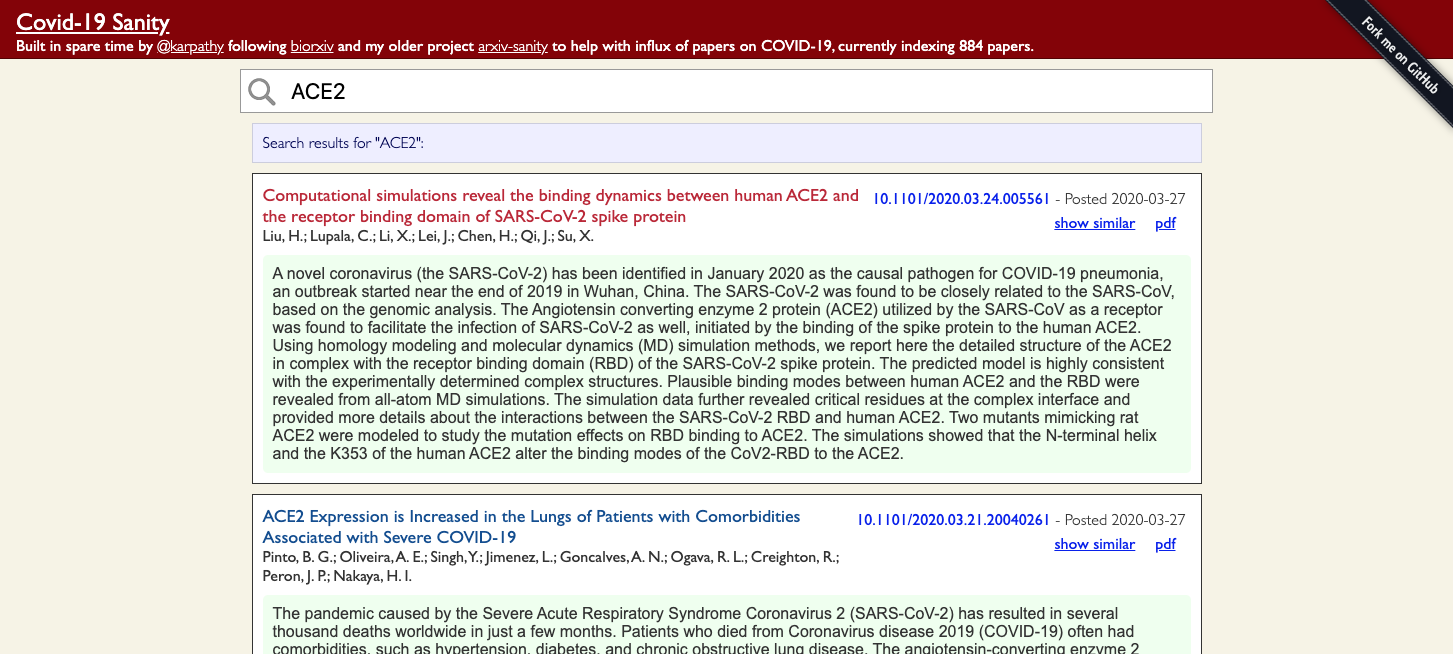
Since I can't assess the quality of the similarity search I welcome any opinions on some of the hyperparameters. For instance, the parameter `C` in the SVM training and the size of the feature vector `max_features` (currently set at 2,000) dramatically impact the results.
This project follows a previous one of mine in spirit, [arxiv-sanity](https://github.com/karpathy/arxiv-sanity-preserver).
## dev
As this is a flask app running it locallyon your own computer is relatively straight forward. First compute the database with `run.py` and then serve:
```bash
$ pip install -r requirements.txt
$ python run.py
$ export FLASK_APP=serve.py
$ flask run
```
## prod
To deploy in production I recommend NGINX and Gunicorn. [Linode](https://www.linode.com/) is one easy/cheap way to host the application on the internet and they have [detailed tutorials](https://www.linode.com/docs/development/python/flask-and-gunicorn-on-ubuntu/) one can follow to set this up.
I run the server in a screen session and have a very simple script `pull.sh` that updates the database:
```bash
#!/bin/bash
# print time
now=$(TZ=":US/Pacific" date)
echo "Time: $now"
# active directory
cd /root/covid-sanity
# pull the latest papers
python run.py
# restart the gracefully
ps aux |grep gunicorn |grep app | awk '{ print $2 }' |xargs kill -HUP
```
And in my `crontab -l` I make sure this runs every 1 hour, for example:
```bash
# m h dom mon dow command
3 * * * * /root/covid-sanity/pull.sh > /root/cron.log 2>&1
```
## seeing tweets
Seeing the tweets for each paper is purely optional. To achieve this you need to follow the instructions on setting up [python-twitter API](https://python-twitter.readthedocs.io/en/latest/) and then write your secrets into a file `twitter.txt`, which get loaded in `twitter_daemon.py`. I run this daemon process in a screen session where it pulls tweets for every paper in circles and saves the results.
## License
MIT