https://github.com/kayvansol/sparkonkubernetes
Spark On Kubernetes via helm chart
https://github.com/kayvansol/sparkonkubernetes
apache apache-spark bitnami docker-compose helm-charts java kubernetes pyspark python scala spark
Last synced: 5 months ago
JSON representation
Spark On Kubernetes via helm chart
- Host: GitHub
- URL: https://github.com/kayvansol/sparkonkubernetes
- Owner: kayvansol
- Created: 2024-03-24T18:21:51.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-04-10T12:33:09.000Z (about 2 years ago)
- Last Synced: 2025-09-06T22:40:54.610Z (10 months ago)
- Topics: apache, apache-spark, bitnami, docker-compose, helm-charts, java, kubernetes, pyspark, python, scala, spark
- Language: Python
- Homepage: https://medium.com/@kayvan.sol2/spark-on-kubernetes-d566158186c6
- Size: 1.57 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Spark On Kubernetes

Spark On Kubernetes via **helm chart**
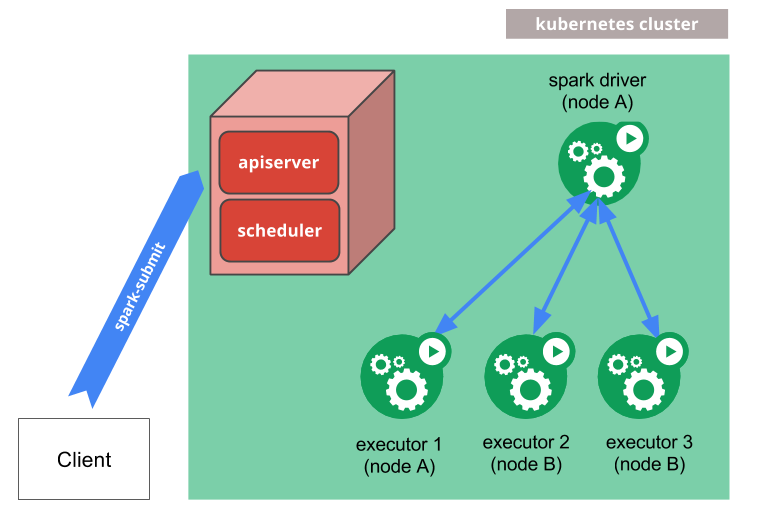
The control-plane & worker nodes addresses are :
```
192.168.56.115
192.168.56.116
192.168.56.117
```
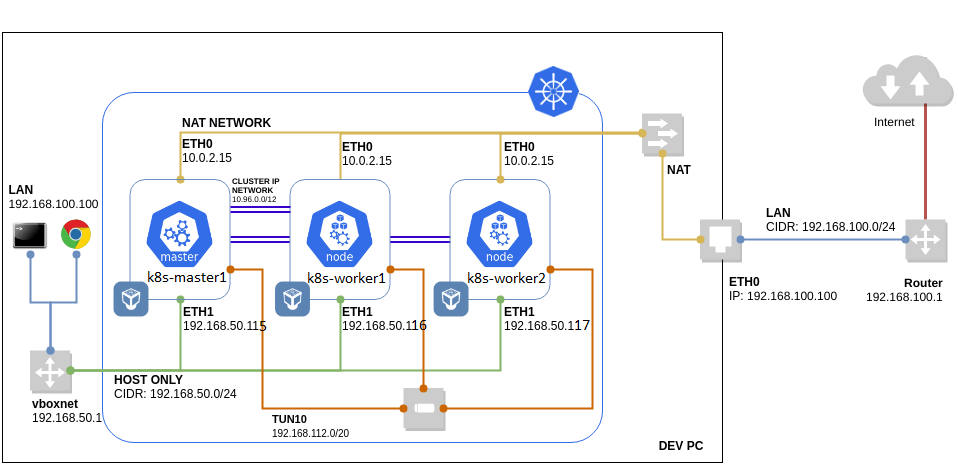
Kubernetes cluster **nodes** :

you can install helm via the link [helm](https://helm.sh/docs/intro/install) :
***
The Steps :
1) Install spark via helm chart **(bitnami)** :

```
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm search repo bitnami
$ helm install kayvan-release oci://registry-1.docker.io/bitnamicharts/spark
$ helm upgrade kayvan-release bitnami/spark --set worker.replicaCount=5
```
the installed **6 pods** :
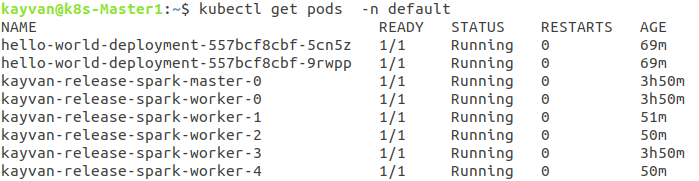
and **Services** (headless for statefull) :

and the **spark master ui** is :
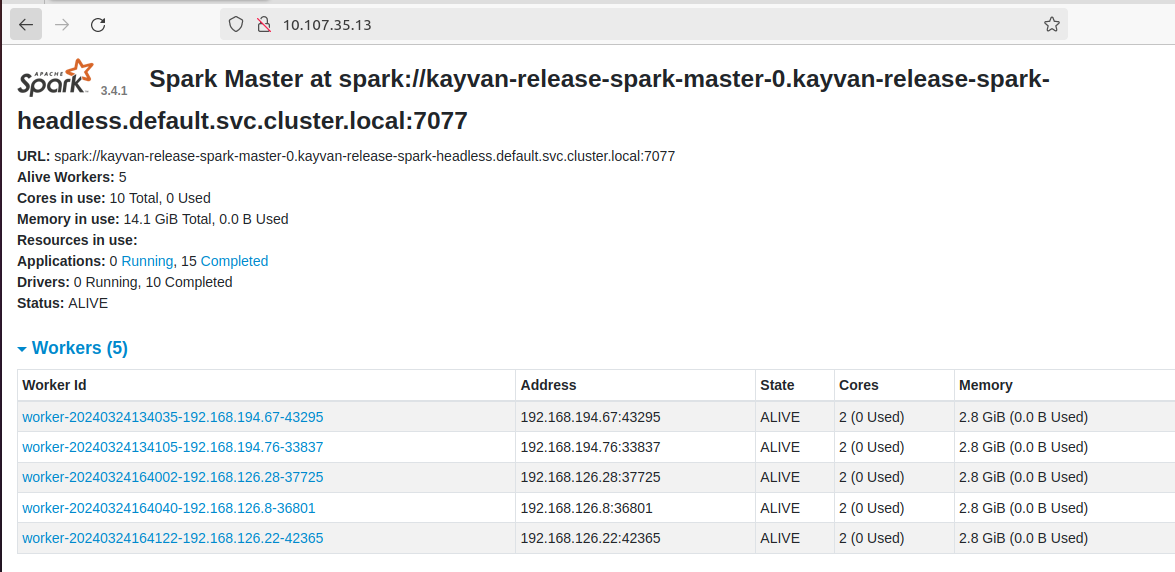
***
2) type the below commands on kubernetes kube-apiserver :
```
kubectl exec -it kayvan-release-spark-master-0 -- ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077 \
./examples/jars/spark-examples_2.12-3.4.1.jar 1000
```
or
```
kubectl exec -it kayvan-release-spark-master-0 -- /bin/bash
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077 \
./examples/jars/spark-examples_2.12-3.4.1.jar 1000
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077 \
./examples/src/main/python/pi.py 1000
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077 \
./examples/src/main/python/wordcount.py //filepath
```

the exact **scala & python** code of spark-examples_2.12-3.4.1.jar , pi.py & wordcount.py :
[examples/src/main/scala/org/apache/spark/examples/SparkPi.scala](https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/SparkPi.scala)
[examples/src/main/python/pi.py](https://github.com/apache/spark/blob/master/examples/src/main/python/pi.py)
[examples/src/main/python/wordcount.py](https://github.com/apache/spark/blob/master/examples/src/main/python/wordcount.py)
***
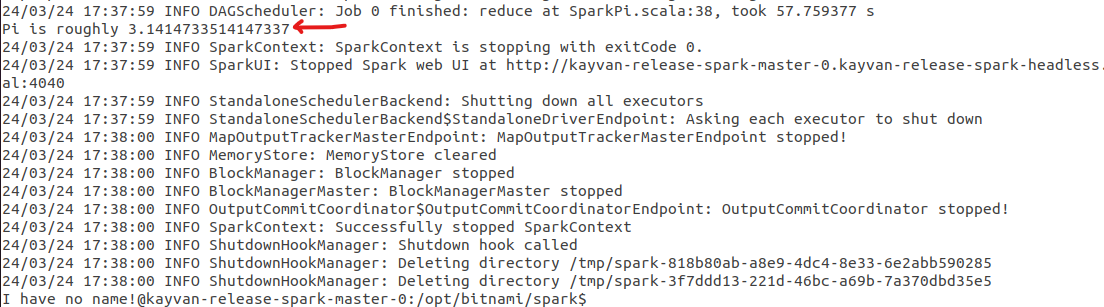
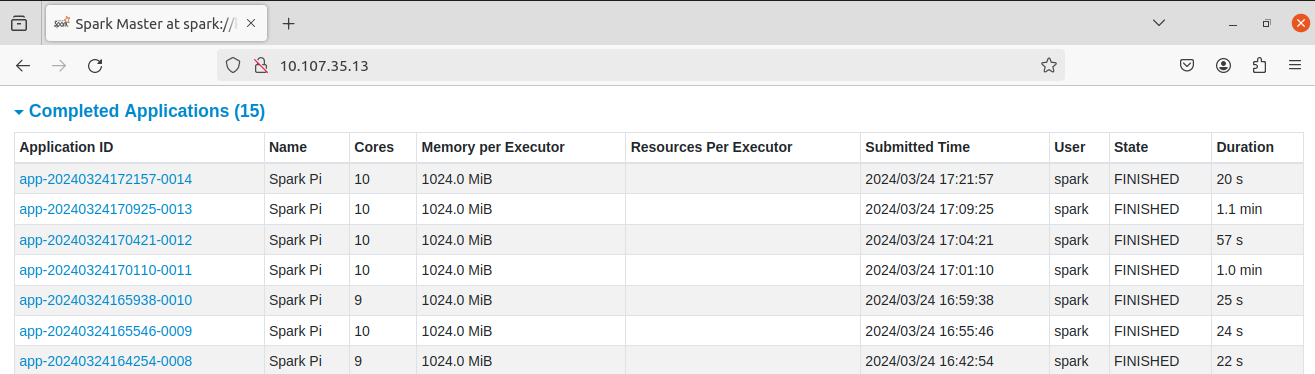
3) The final **result** is 🍹 :
for **scala** :
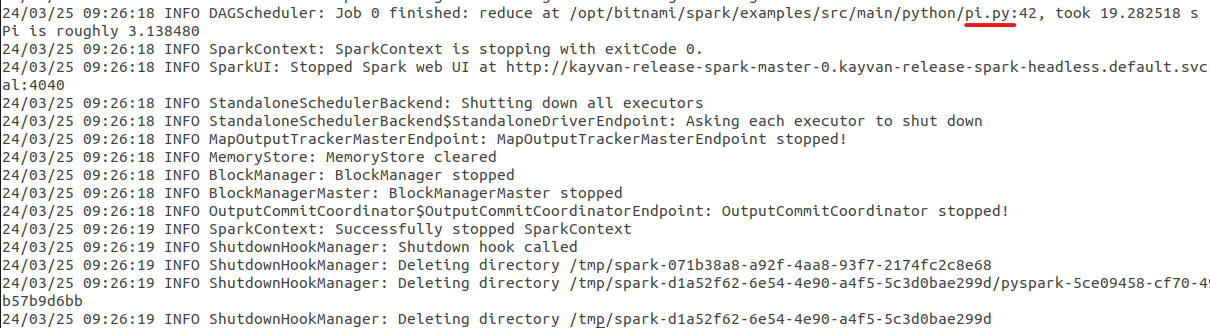
for **python** :
***
The other **python**  Programm :
Programm :
1) Copy **People.csv** (large file) inside spark worker pods :

```
kubectl cp people.csv kayvan-release-spark-worker-{x}:/opt/bitnami/spark
```
Notes:
- you can download the file from [link](https://www.datablist.com/learn/csv/download-sample-csv-files)
- you can also use a **nfs share folder** for read large csv file from it instead of copying it inside pods.
2) Write some python codes inside **readcsv.py** please :
```python
from pyspark.sql import SparkSession
#from pyspark.sql.functions import sum
from pyspark.context import SparkContext
spark = SparkSession\
.builder\
.appName("Mahla")\
.getOrCreate()
sc = spark.sparkContext
path = "people.csv"
df = spark.read.options(delimiter=",", header=True).csv(path)
df.show()
#df.groupBy("Job Title").sum().show()
df.createOrReplaceTempView("Peopletable")
df2 = spark.sql("select Sex, count(1) countsex, sum(Index) sex_sum " \
"from peopletable group by Sex")
df2.show()
#df.select(sum(df.Index)).show()
```
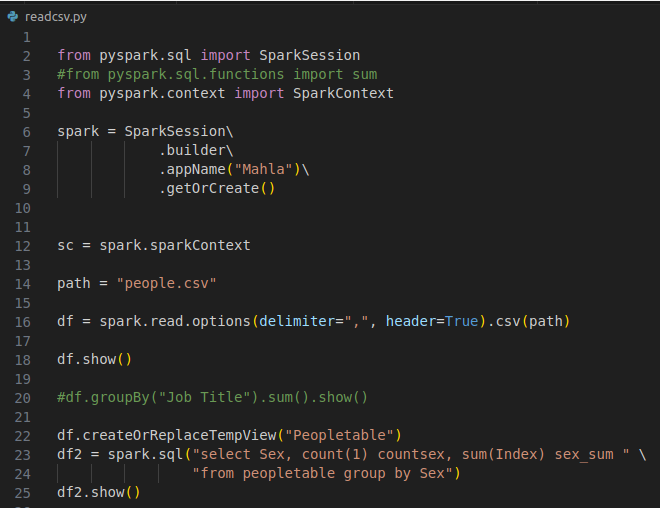
3) copy readcsv.py file inside spark **master** pod :
```
kubectl cp readcsv.py kayvan-release-spark-master-0:/opt/bitnami/spark
```
4) run the code :
```
kubectl exec -it kayvan-release-spark-master-0 -- ./bin/spark-submit --class org.apache.spark.examples.SparkPi
--master spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077
readcsv.py
```
5) showing some data :
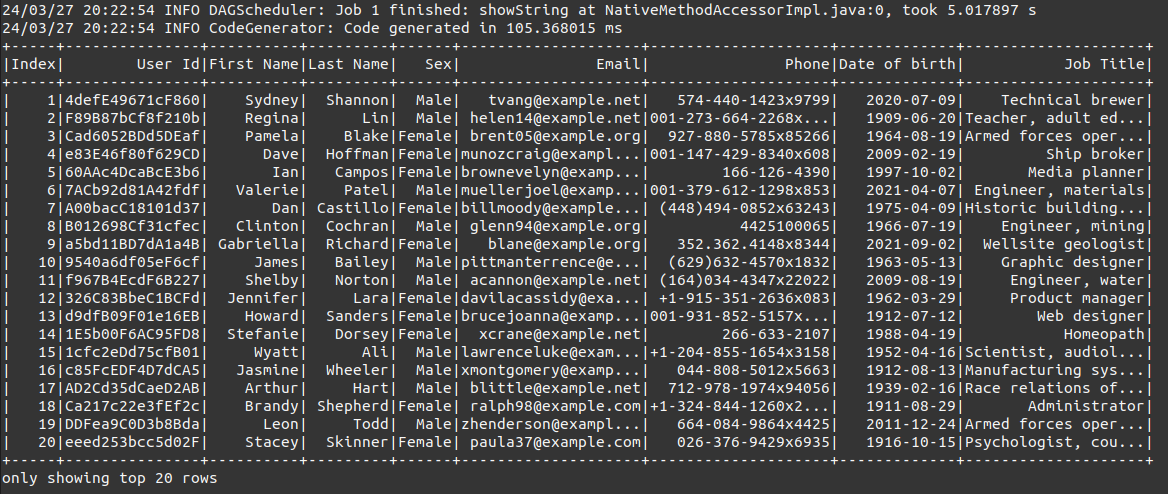
6) the next result data:
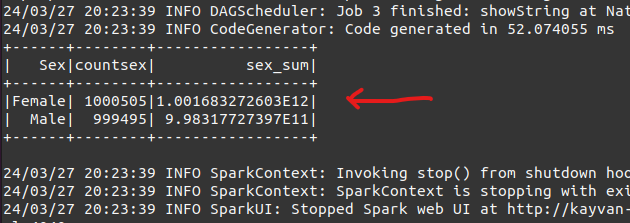
7) the time consuming for processing :
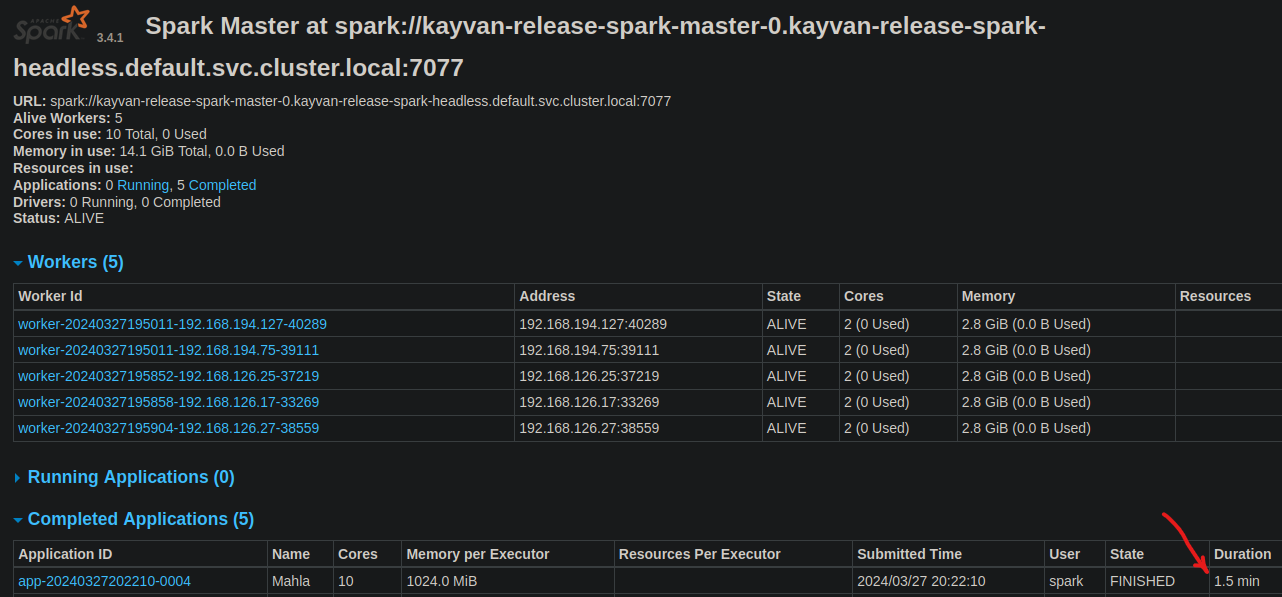
***
The other **python** Programm on **Docker Desktop** :
docker-compose.yml :
```yaml
version: '3.6'
services:
spark:
container_name: spark
image: bitnami/spark:latest
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_USER=root
- PYSPARK_PYTHON=/opt/bitnami/python/bin/python3
ports:
- 127.0.0.1:8081:8080
spark-worker:
image: bitnami/spark:latest
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=2
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_USER=root
- PYSPARK_PYTHON=/opt/bitnami/python/bin/python3
```
```
docker-compose up --scale spark-worker=2
```
copy required files to containers :
for e.g.
```bash
docker cp file.csv spark-worker-1:/opt/bitnami/spark
```
python code on master :
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Writingjson").getOrCreate()
df = spark.read.option("header", True).csv("csv/file.csv").coalesce(2)
df.show()
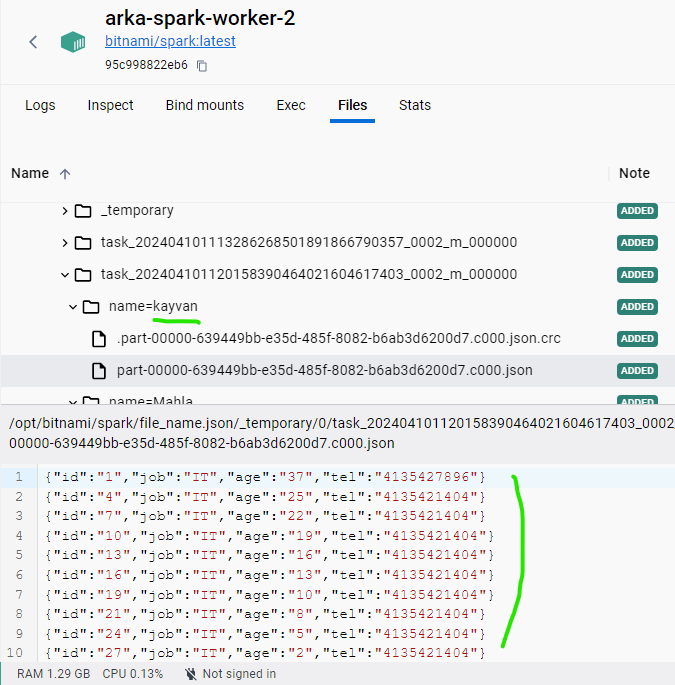
df.write.partitionBy('name').mode('overwrite').format('json').save('file_name.json')
```
run the code on spark master docker container :
```bash
./bin/spark-submit --master spark://4f28330ce077:7077 csv/ctp.py
```
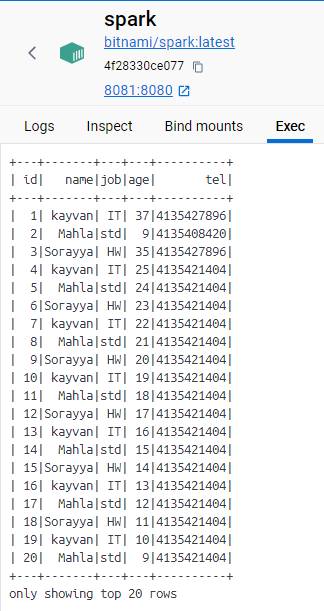
showing some data :
and the seperated json files based on name partitioning :
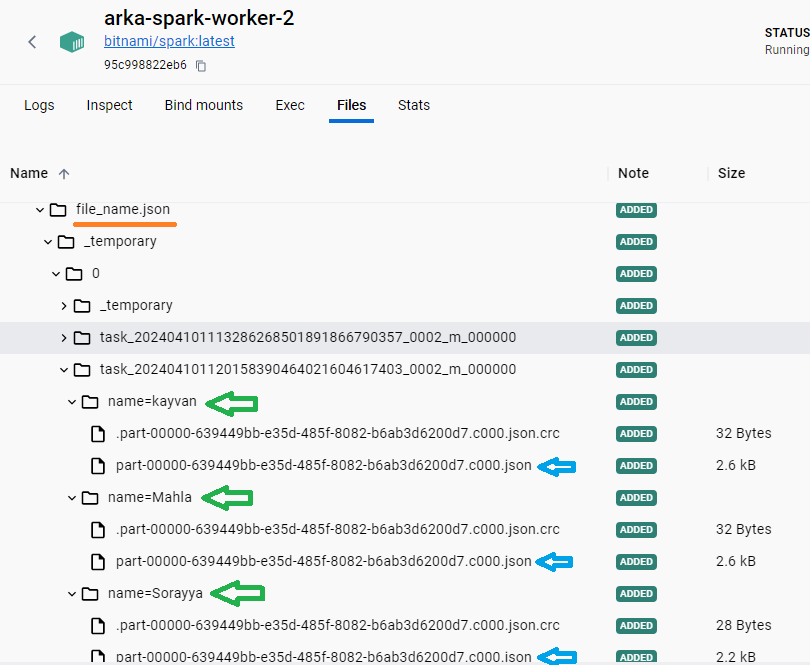
data for name=kayvan :