https://github.com/kemalcanbora/foo_scientist
https://github.com/kemalcanbora/foo_scientist
big-data json pyspark python sh shell spark
Last synced: 3 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/kemalcanbora/foo_scientist
- Owner: kemalcanbora
- Created: 2019-09-10T14:52:40.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2019-09-13T14:59:58.000Z (almost 7 years ago)
- Last Synced: 2025-06-24T06:42:26.731Z (about 1 year ago)
- Topics: big-data, json, pyspark, python, sh, shell, spark
- Language: Python
- Size: 8.79 KB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Foo Scientist
Apache Spark follows a master/slave architecture with two main daemons
- Master Daemon — (Master/Driver Process)
- Worker Daemon –(Slave Process)
Cluster Manager
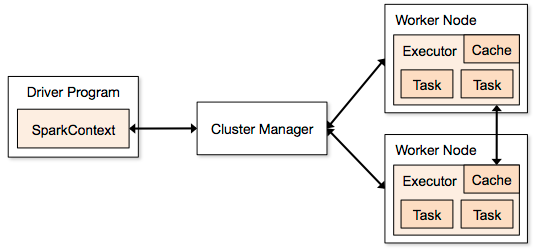
Sometimes architecture can be hard to build for this there are solutions such as cloudera etc. I wanted to do it my way.
All you have to do is edit the json file yourself it's name is **architecture.json** and run mimar.py
Note:
Don't change type in json file and if you add another slave in json file just add new number end of the name like
hadoop_slave_2, hadoop_slave_3 ..
JSON File
[{
"type":"hadoop-master",
"password":"123456",
"IP": "10.11.2.183",
"username": "root",
"name": "hadoop_master_mimar"
},
{
"type":"hadoop-slave",
"password":"123456",
"IP": "10.11.2.228",
"username": "root",
"name": "hadoop_slave_1"
}]