https://github.com/kiranbaby14/talkmateai
🎭 Real-time voice-controlled 3D avatar with multimodal AI - speak naturally and watch your AI companion respond with perfect lip-sync
https://github.com/kiranbaby14/talkmateai
fastapi flash-attention-2 huggingface kokoro-tts multimodal-ai nextjs smolvlm vlm websocket whisper-ai
Last synced: 4 months ago
JSON representation
🎭 Real-time voice-controlled 3D avatar with multimodal AI - speak naturally and watch your AI companion respond with perfect lip-sync
- Host: GitHub
- URL: https://github.com/kiranbaby14/talkmateai
- Owner: kiranbaby14
- License: mit
- Created: 2025-06-29T19:02:57.000Z (4 months ago)
- Default Branch: master
- Last Pushed: 2025-06-29T20:28:36.000Z (4 months ago)
- Last Synced: 2025-06-29T21:28:55.245Z (4 months ago)
- Topics: fastapi, flash-attention-2, huggingface, kokoro-tts, multimodal-ai, nextjs, smolvlm, vlm, websocket, whisper-ai
- Language: TypeScript
- Homepage:
- Size: 3.41 MB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# 🎭 TalkMateAI
**Real-time Voice-Controlled 3D Avatar with Multimodal AI**
> Your 3D AI companion that never stops listening, never stops caring.
> Transform conversations into immersive experiences with AI-powered 3D avatars that see, hear, and respond naturally.
[](https://python.org)
[](https://fastapi.tiangolo.com)
[](https://nextjs.org)
[](https://developer.nvidia.com/cuda-toolkit)
[](LICENSE)
## 🎥 Demo Video
[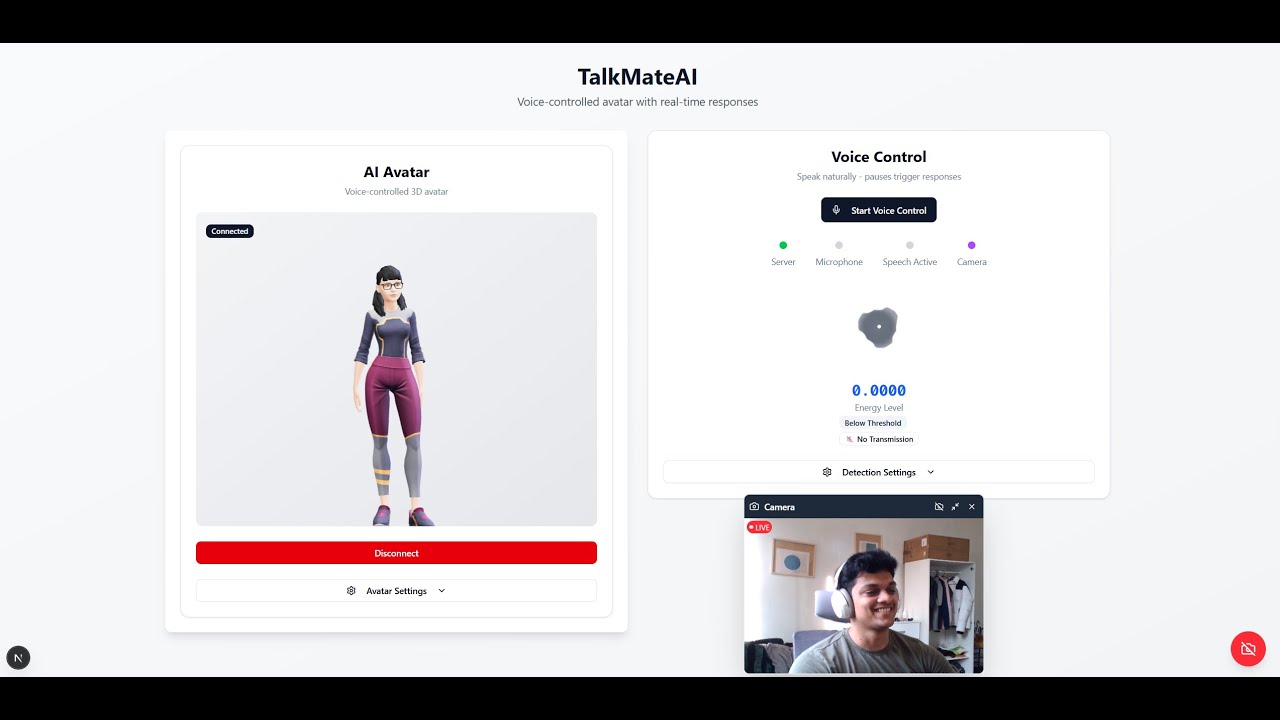](https://www.youtube.com/watch?v=dE_8TXmp2Sk)
## ✨ Features
### 🎯 **Core Capabilities**
- **🎤 Real-time Voice Activity Detection** - Advanced VAD with configurable sensitivity
- **🗣️ Speech-to-Text** - Powered by OpenAI Whisper (tiny model) for instant transcription
- **👁️ Vision Understanding** - SmolVLM2-256M-Video-Instruct for multimodal comprehension
- **🔊 Natural Text-to-Speech** - Kokoro TTS with native word-level timing
- **🎭 3D Avatar Animation** - Lip-sync and emotion-driven animations using [TalkingHead](https://github.com/met4citizen/TalkingHead)
### 🚀 **Advanced Features**
- **📹 Camera Integration** - Real-time image capture with voice commands
- **⚡ Streaming Responses** - Chunked audio generation for minimal latency
- **🎬 Native Timing Sync** - Perfect lip-sync using Kokoro's native timing data
- **🎨 Draggable Camera View** - Floating, resizable camera interface
- **📊 Real-time Analytics** - Voice energy visualization and transmission tracking
- **🔄 WebSocket Communication** - Low-latency bidirectional data flow
## 🏗️ Architecture
## 🛠️ Technology Stack
### Backend (Python)
- **🧠 AI Models from HuggingFace🤗:**
- `openai/whisper-tiny` - Speech recognition
- `HuggingFaceTB/SmolVLM2-256M-Video-Instruct` - Vision-language understanding
- `Kokoro TTS` - High-quality voice synthesis
- **⚡ Framework:** FastAPI with WebSocket support
- **🔧 Processing:** PyTorch, Transformers, Flash Attention 2
- **🎵 Audio:** SoundFile, NumPy for real-time processing
### Frontend (TypeScript/React)
- **🖼️ Framework:** Next.js 15 with TypeScript
- **🎨 UI:** Tailwind CSS + shadcn/ui components
- **🎭 3D Rendering:** [TalkingHead](https://github.com/met4citizen/TalkingHead) library
- **🎙️ Audio:** Web Audio API with AudioWorklet
- **📡 Communication:** Native WebSocket with React Context
## 📋 Requirements
### System Tested on
- **OS:** Windows 11 (Linux/macOS support coming soon, will create a docker image)
- **GPU:** NVIDIA RTX 3070 (8GB VRAM)
## 🚀 Quick Start
### 1. Prerequisites
- Node.js 20+
- PNPM
- Python 3.10
- UV (Python package manager)
### 2. **Setup monorepo dependencies from root**
```bash
# will setup both frontend and backend but require the prerequisites
pnpm run monorepo-setup
```
### 4. Run the Application
**Start Development Servers**
```bash
# Run both frontend and backend from root
pnpm dev
# Or run individually
pnpm dev:client # Frontend (http://localhost:3000)
pnpm dev:server # Backend (http://localhost:8000)
```
### 5. Initial Setup
1. **Allow microphone access** when prompted
2. **Enable camera** for multimodal interactions
3. **Click "Connect"** to establish WebSocket connection
4. **Start Voice Control** and begin speaking!
## 🎮 Usage Guide
### Camera Controls
- **Drag** to move camera window
- **Resize** with maximize/minimize buttons
- **Toggle on/off** as needed
### Voice Settings
- **Energy Threshold:** Adjust sensitivity to background noise
- **Pause Duration:** How long to wait before processing speech
- **Min/Max Speech:** Control segment length limits
## 🙏 Acknowledgments
- **TalkingHead** ([met4citizen](https://github.com/met4citizen/TalkingHead)) for 3D avatar rendering and lip-sync
- **yeyu2** ([Multimodal-local-phi4](https://github.com/yeyu2/Youtube_demos/tree/main/Multimodal-local-phi4)) for multimodal implementation inspiration
---
**⭐ Star this repo if you find it useful! ⭐**
Made with ❤️ by the Kiranbaby14