https://github.com/kleinyuan/image2text
A deep learning project to tell a story with an image or a video.
https://github.com/kleinyuan/image2text
artificial-intelligence cnn convolutional-neural-networks deep-learning iapr image-understanding lasagne machine-learning multimodal-layers natural-language-processing neural-network real-time storyteller tensorflow theano word2vec word2vec-model
Last synced: about 1 year ago
JSON representation
A deep learning project to tell a story with an image or a video.
- Host: GitHub
- URL: https://github.com/kleinyuan/image2text
- Owner: KleinYuan
- Created: 2017-06-25T18:25:43.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2017-08-09T05:50:40.000Z (almost 9 years ago)
- Last Synced: 2025-04-12T10:44:52.318Z (over 1 year ago)
- Topics: artificial-intelligence, cnn, convolutional-neural-networks, deep-learning, iapr, image-understanding, lasagne, machine-learning, multimodal-layers, natural-language-processing, neural-network, real-time, storyteller, tensorflow, theano, word2vec, word2vec-model
- Language: Python
- Homepage:
- Size: 37.1 KB
- Stars: 42
- Watchers: 3
- Forks: 10
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Intro
This repo is to implement a multi-modal natural language model with tensorflow.
|**Dependencies** | **DataSets**|
| --- | --- |
|[python 2.7](https://www.python.org/download/releases/2.7/)
[tensorflow](https://www.tensorflow.org)
[lasagne](https://https://github.com/Lasagne/Lasagne)
[Theano](https://github.com/Theano/Theano) |[IAPR TC-12](http://www.imageclef.org/photodata)|
# Project Overview
1. Firstly, a word embedding with word2vec net is trained against iaprtc12 datasets.
2. Secondly, the filtered (meaning, if the description is too long, we only keep the first sentence) word vectors for each description of image are used as target output of a CNN network
# Setup
For various systems, you need to use different tools to install tensorflow, lasagne, theano, nolearn, ... dependencies, first.
Then, simply run below scripts to download the datasets
Run:
```bash setup.sh```
or:
```make setup```
# Network Design
**Word2Vec** | **StoryNet**
:-------------------------:|:-------------------------:
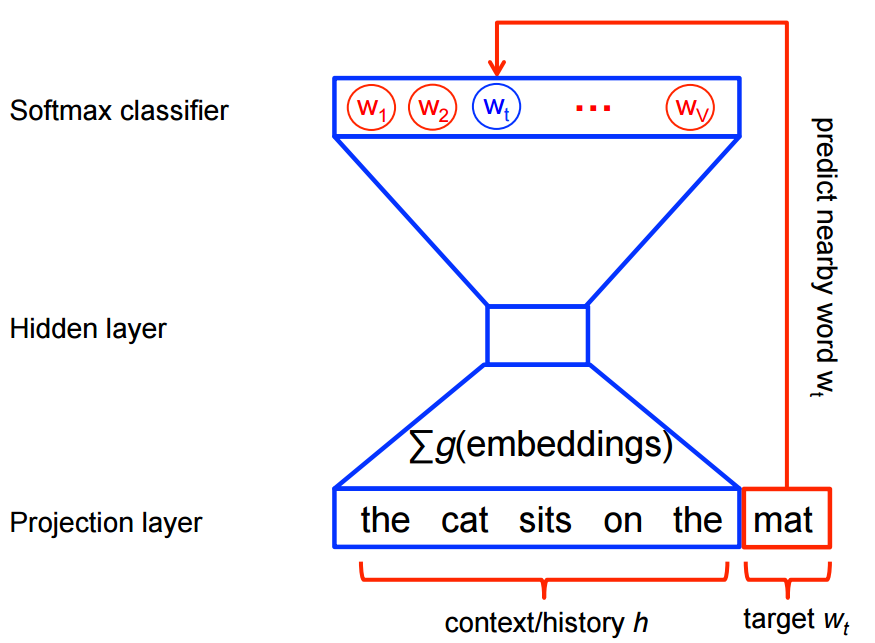|
# Training
Run:
```python train.py```
or:
```make train```
**Optimizer** | **Loss**
:-------------------------:|:-------------------------:
MomentumOptimizer | MSE Loss

# Pre-trained Model
Download [here](https://www.dropbox.com/s/hxt8xwpy4wz429k/storyNet.pb?dl=0)
# Testing and Results
Run:
```
make demo
```
# Train on your own
1. Run setup bash script to download datasets
2. Run train.py or with makefile
3. Freeze tensorflow model with the command provided in makefile
4. Run app.py or with makefile
# Data Sets
The image collection of the IAPR TC-12 Benchmark consists of 20,000 still natural images taken from locations around the world and comprising an assorted cross-section of still natural images. This includes pictures of different sports and actions, photographs of people, animals, cities, landscapes and many other aspects of contemporary life.
Each image is associated with a text caption in up to three different languages (English, German and Spanish) . These annotations are stored in a database which is managed by a benchmark administration system that allows the specification of parameters according to which different subsets of the image collection can be generated.
The IAPR TC-12 Benchmark is now available free of charge and without copyright restrictions.
More [details](http://www.imageclef.org/photodata).
Sample annotations:
```
annotations/01/1000.eng
Godchild Cristian Patricio Umaginga Tuaquiza
a dark-skinned boy wearing a knitted woolly hat and a light and dark grey striped jumper with a grey zip, leaning on a grey wall;
Quilotoa, Ecuador
April 2002
images/01/1000.jpg
thumbnails/01/1000.jpg
```
# References:
1. [Dong, Jianfeng, Xirong Li, and Cees GM Snoek. "Word2VisualVec: Image and video to sentence matching by visual feature prediction." CoRR, abs/1604.06838 (2016).](https://arxiv.org/pdf/1604.06838.pdf)
2. [Karpathy, Andrej, and Li Fei-Fei. "Deep visual-semantic alignments for generating image descriptions." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.](https://cs.stanford.edu/people/karpathy/cvpr2015.pdf)
3. [Kiros, Ryan, Ruslan Salakhutdinov, and Rich Zemel. "Multimodal neural language models." Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014.](http://proceedings.mlr.press/v32/kiros14.pdf)
4. [word2vec tutorial](http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/)