Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/kojix2/paperclippers
https://github.com/kojix2/paperclippers
Last synced: 22 days ago
JSON representation
- Host: GitHub
- URL: https://github.com/kojix2/paperclippers
- Owner: kojix2
- License: mit
- Created: 2024-01-30T05:49:26.000Z (9 months ago)
- Default Branch: main
- Last Pushed: 2024-03-15T06:09:13.000Z (8 months ago)
- Last Synced: 2024-04-21T02:15:36.105Z (7 months ago)
- Language: Ruby
- Size: 48.8 KB
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE.txt
Awesome Lists containing this project
README
# PaperClippers - kirinuki
[](https://github.com/kojix2/PaperClippers/actions/workflows/main.yml)
ChatGPT を利用して、自動で論文を翻訳します。
## インストール
このツールは私がGitHubにアップロードしている他の多くのツールと違いkojix2の個人用ツールです。
Gem サーバーには公開しません。ソースコードからインストールしてください。
```sh
gem install specific_install
gem specific_install https://github.com/kojix2/PaperClippers
```
## 基本的な方針
1. [Zotero](https://www.zotero.org/) を使ってウェブページのスナップショットを取る
2. Ruby の [Nokogiri](https://github.com/sparklemotion/nokogiri) を使って論文を分割して保存する
3. ChatGPT の API 版で翻訳する
4. 生成されたテキストファイルの統合、マークダウン化
5. Pandocによる日本語PDF/DOCXの生成
## 利用するツール
- [Firefox](https://www.mozilla.org/firefox/) - ブラウザ
- [Zotero](https://www.zotero.org/) - 文献管理ソフト
- [Ruby](https://www.ruby-lang.org) - プログラミング言語
- [chatgpt-cli](https://github.com/kojix2/chatgpt-cli) - Crystal で作成されたコマンドラインツール
## 論文からテキストを抽出する
最初に、論文からテキストを抽出します。PDF ではなく HTML からスクレイピングします(スクレイピングには「XPath」を使います)。**しかし、論文が掲載されているウェブサイトの多くは簡単にスクレイピングさせてくれません。403 Forbidden となってしまいます。** そこで、「Zotero」を使ってスナップショットをローカルに保存し、そのローカルの HTML ファイルに対してスクレイピングを行います。
### ① 文献の保存に Zotero を使用する
文献管理ソフトである Zotero で論文を保存します。私は Firefox の拡張機能を使用しています。保存された論文を右クリックして「スナップショットを閲覧する」を選択すると、ローカルに保存された HTML ファイルをブラウザで開くことができます。
`/home/kojix2/Zotero/storage/HOGEFUGA/S1234567890123456789.html`
後でこのファイルパスを使用します。
### ② Firefox で XPath を確認する
トークン数の制限を回避するために論文を各セクションごとに分割してファイルに保存します。はじめに、各セクションが HTML 内でどのように表現されているかを確認します。
Firefox の画面で、論文本文中の「調査」をクリックします。インスペクタを開き、HTML のソースコードを確認します。例えば Cell 紙の場合は、以下のようにセクションが並んでいることがわかります。
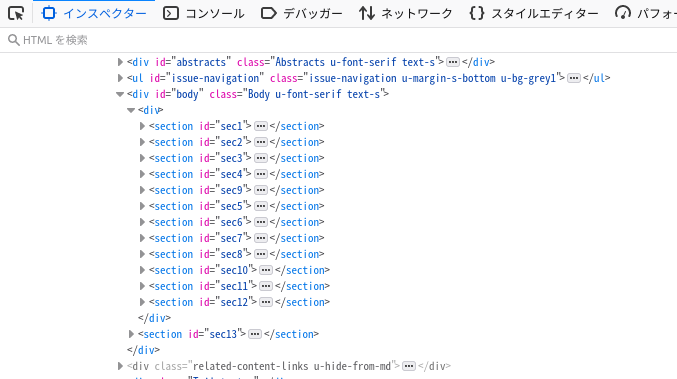
右クリックで、「コピー」>「XPath」を選択します。すると、XPath がクリップボードにコピーされます。
```
//*[@id="sec1"]
```
この XPath に対応する本文を抽出し、適切に改行を入れるような小さなコマンドラインツールを Ruby で作成しました。
### ③ ファイルの抽出
```
kirinuki [options]
Example: ruby kirinuki.rb -f 'path/to/your.html' -p '//*[@id="sec{}"]' -r '1..12'
-f, --file HTML_PATH HTML file path
-x, --xpath XPATH XPath
-r, --range RANGE Range
-o, --output OUTPUT_DIR Output directory
```
例に従って、先ほど作成したツールを実行します。「{}」の部分が、range のイテレータの各要素に置き換わります。`range` は `eval` で評価されるため、応用的な使い方も可能です。セキュリティの観点から `eval` はなるべく使わない方が良いとされていますが、今回はローカルのファイルを変換するだけなので問題ありません。
## ChatGPT を使って翻訳する
ここでは、自作の[chatgpt-cli](https://github.com/kojix2/chatgpt-cli) を使います。それなりに便利なツールですが、一般向けに作られていないので、興味がある方のみご利用ください。ここではその基本的な機能のみを使います。他の ChatGPT 向けコマンドラインツールでも同じことができるでしょう。
まずは、翻訳用のプロンプトのテンプレートを作ります。
```txt:prompt.txt
次の論文のアブストラクトを読んでください。
# ここにアブストラクトやサマリーを貼り付ける
読み終わったら、以下のセクションを翻訳してください。わかりやすく平易な文章でお願いします。翻訳された文章だけ回答してください。専門的な科学用語はカッコを用いて日本語(英語)の形で併記してください。
---
```
上記のテンプレートはさらに改良できるでしょう。例えば、専門用語を英語で併記させるなどの工夫が可能です。
これで、`cat prompt.txt idsec1.txt` とすると、プロンプト、翻訳対象の英文、がその順に出力されます。これを標準入力から `chatgpt-cli` に渡します。
```
cat prompt.txt idsec1.txt | chatgpt -M gpt-4 > idsec1_ja.txt
```
さらに、連番を使ってシェルスクリプトを作成します。
```sh
seq 1 12 | xargs -t -I{} sh -c 'cat prompt.txt idsec{}.txt | chatgpt -M gpt-4 > idsec{}_ja.txt'
```
FIXME: 連番はナチュラルソートしにくいという問題がある。命名規則を規約化する、連番のつけかたを00xのようにする、ファイルの生成時間順にするなどの工夫が必要
あとは十分に時間をかけて待つことで、翻訳されたテキストファイルが生成されます。
このプロセスはかなり時間がかかりますので、根気よく待ちましょう。
## 生成されたファイルから不要な文字を取り除く
https://github.com/kojix2/bleach
## ファイルの統合でMarkdownを作成し、Prettierで修正
ファイルの統合は単にcatコマンドを使い、自動修正はVSCodeの機能を利用する
## PDFやDOCXの作成
dockerを利用する具体的には
```
kirinuki --prompt pandoc
```
## 最後に
最短で数ヶ月、最長で 1 年後には、論文全体が ChatGPT のトークンに収まるようになると思います。そのため、ここで述べているような論文を分割してトークン数に収める方法は遅かれ早かれ必要なくなるでしょう。しかし、現時点ではトークン数に限界があるため、このような工夫が必要です。
いずれ便利なツールが開発され、ボタン一つで簡単に翻訳できるようになると良いですね。