https://github.com/kvcache-ai/ktransformers
A Flexible Framework for Experiencing Heterogeneous LLM Inference/Fine-tune Optimizations
https://github.com/kvcache-ai/ktransformers
Last synced: 3 months ago
JSON representation
A Flexible Framework for Experiencing Heterogeneous LLM Inference/Fine-tune Optimizations
- Host: GitHub
- URL: https://github.com/kvcache-ai/ktransformers
- Owner: kvcache-ai
- License: apache-2.0
- Created: 2024-07-26T07:18:28.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2026-03-02T10:08:24.000Z (5 months ago)
- Last Synced: 2026-03-02T11:26:10.851Z (5 months ago)
- Language: Python
- Homepage: https://kvcache-ai.github.io/ktransformers/
- Size: 59.3 MB
- Stars: 16,648
- Watchers: 112
- Forks: 1,221
- Open Issues: 412
-
Metadata Files:
- Readme: README.md
- Contributing: .github/CONTRIBUTING.md
- License: LICENSE
- Code of conduct: .github/CODE_OF_CONDUCT.md
- Security: .github/SECURITY.md
- Maintainers: MAINTAINERS.md
Awesome Lists containing this project
- awesome-llm-and-aigc - KTransformers - ai/ktransformers?style=social"/> : A Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations. [kvcache-ai.github.io/ktransformers/](https://kvcache-ai.github.io/ktransformers/) (Summary)
- awesome-cuda-and-hpc - KTransformers - ai/ktransformers?style=social"/> : A Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations. [kvcache-ai.github.io/ktransformers/](https://kvcache-ai.github.io/ktransformers/) (Frameworks)
- awesome-llm-services - KTransformers
- awesome-opensource-ai - KTransformers - Flexible framework for heterogeneous CPU-GPU LLM inference and fine-tuning. Enables running large MoE models by offloading experts to CPU with BF16/FP8 precision support.  (3. Inference Engines & Serving)
- awesome-production-machine-learning - KTransformers - ai/ktransformers.svg?style=social) - KTransformers is a flexible framework for experiencing cutting-edge LLM inference optimizations. (Deployment and Serving)
- StarryDivineSky - kvcache-ai/ktransformers - Value Cache)的优化,允许用户轻松尝试和比较不同的优化策略,提升LLM推理效率。该项目提供了一个模块化的架构,方便集成新的优化方法。KTransformers支持多种LLM架构,并提供了详细的性能评估工具。其核心思想是高效管理和利用KV缓存,减少计算冗余,加速推理过程。通过该框架,开发者可以深入了解KV缓存优化对LLM推理性能的影响,并快速部署最佳实践。项目目标是成为LLM推理优化研究和应用的强大平台。 (A01_文本生成_文本对话 / 大语言对话模型及数据)
- awesome-LLM-resources - ktransformers - edge LLM Inference Optimizations. (推理 Inference)
- awesome-cpu-first-ai - KTransformers - CPU-GPU heterogeneous LLM inference framework designed for large MoE models; Intel AMX/AVX-512/AVX2-optimized CPU kernels for INT4/INT8 quantized inference with NUMA-aware expert scheduling and SGLang integration. Apache 2.0. *(Also listed under Mixture-of-Experts on CPU.)* (Runtimes and Inference Engines)
- awesome - kvcache-ai/ktransformers - A Flexible Framework for Experiencing Heterogeneous LLM Inference/Fine-tune Optimizations (Python)
- awesome - kvcache-ai/ktransformers - A Flexible Framework for Experiencing Heterogeneous LLM Inference/Fine-tune Optimizations (Python)
README

A Flexible Framework for Experiencing Cutting-edge LLM Inference/Fine-tune Optimizations
🎯 Overview | 🚀 Inference | 🎓 SFT | 🔥 Citation | 🚀 Roadmap(2026Q2)
## 🎯 Overview
KTransformers is a research project focused on efficient inference and fine-tuning of large language models through CPU-GPU heterogeneous computing. The project now exposes two user-facing capabilities from the kt-kernel source tree: [Inference](./kt-kernel/README.md) and [SFT](./doc/en/SFT/KTransformers-Fine-Tuning_Quick-Start.md).
## 🔥 Updates
* **May 6, 2026**: KTransformers at [GOSIM Paris 2026](https://paris2026.gosim.org/zh/schedule/) — "Agentic AI on Edge" track. We'll present KT's inference performance on consumer hardware.
* **May 02, 2026**: DeepSeek-V4-Flash Support! ([Tutorial](./doc/en/DeepSeek-V4-Flash.md))
* **Apr 30, 2026**: KTransformers v0.6.1 refreshes kt-kernel inference and SFT docs with separate [Inference](./kt-kernel/README.md) and [SFT Quick Start](./doc/en/SFT/KTransformers-Fine-Tuning_Quick-Start.md) entry points.
* **Mar 26, 2026**: Support AVX2-only CPU backend for KT-Kernel inference. ([Tutorial](./doc/en/kt-kernel/AVX2-Tutorial.md))
* **Feb 13, 2026**: MiniMax-M2.5 Day0 Support! ([Tutorial](./doc/en/MiniMax-M2.5.md))
* **Feb 12, 2026**: GLM-5 Day0 Support! ([Tutorial](./doc/en/kt-kernel/GLM-5-Tutorial.md))
* **Jan 27, 2026**: Kimi-K2.5 Day0 Support! ([Tutorial](./doc/en/Kimi-K2.5.md)) ([SFT Tutorial](./doc/en/SFT_Installation_Guide_KimiK2.5.md))
* **Jan 22, 2026**: Support [CPU-GPU Expert Scheduling](./doc/en/kt-kernel/experts-sched-Tutorial.md), [Native BF16 and FP8 per channel Precision](./doc/en/kt-kernel/Native-Precision-Tutorial.md) and [AutoDL unified fine-tuning and inference](./doc/zh/【云端低价训推】%20KTransformers%2BAutoDL%2BLlamaFactory:随用随租的低成本超大模型「微调%2B推理」一体化流程.pdf)
* **Dec 24, 2025**: Support Native MiniMax-M2.1 inference. ([Tutorial](./doc/en/kt-kernel/MiniMax-M2.1-Tutorial.md))
* **Dec 22, 2025**: Support RL-DPO fine-tuning with LLaMA-Factory. ([Tutorial](./doc/en/SFT/DPO_tutorial.md))
* **Dec 5, 2025**: Support Native Kimi-K2-Thinking inference ([Tutorial](./doc/en/kt-kernel/Kimi-K2-Thinking-Native.md))
* **Nov 6, 2025**: Support Kimi-K2-Thinking inference ([Tutorial](./doc/en/Kimi-K2-Thinking.md)) and fine-tune ([Tutorial](./doc/en/SFT_Installation_Guide_KimiK2.md))
* **Nov 4, 2025**: KTransformers Fine-Tuning × LLaMA-Factory Integration. ([Tutorial](./doc/en/SFT/KTransformers-Fine-Tuning_User-Guide.md))
* **Oct 27, 2025**: Support Ascend NPU. ([Tutorial](./doc/zh/DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md))
* **Oct 10, 2025**: Integrating into SGLang. ([Roadmap](https://github.com/sgl-project/sglang/issues/11425), [Blog](https://lmsys.org/blog/2025-10-22-KTransformers/))
* **Sept 11, 2025**: Support Qwen3-Next. ([Tutorial](./doc/en/Qwen3-Next.md))
* **Sept 05, 2025**: Support Kimi-K2-0905. ([Tutorial](./doc/en/Kimi-K2.md))
* **July 26, 2025**: Support SmallThinker and GLM4-MoE. ([Tutorial](./doc/en/SmallThinker_and_Glm4moe.md))
* **July 11, 2025**: Support Kimi-K2. ([Tutorial](./doc/en/Kimi-K2.md))
* **June 30, 2025**: Support 3-layer (GPU-CPU-Disk) [prefix cache](./doc/en/prefix_cache.md) reuse.
* **May 14, 2025**: Support Intel Arc GPU ([Tutorial](./doc/en/xpu.md)).
* **Apr 29, 2025**: Support AMX-Int8、 AMX-BF16 and Qwen3MoE ([Tutorial](./doc/en/AMX.md))
* **Apr 9, 2025**: Experimental support for LLaMA 4 models ([Tutorial](./doc/en/llama4.md)).
* **Apr 2, 2025**: Support Multi-concurrency. ([Tutorial](./doc/en/balance-serve.md)).
* **Mar 15, 2025**: Support ROCm on AMD GPU ([Tutorial](./doc/en/ROCm.md)).
* **Mar 5, 2025**: Support unsloth 1.58/2.51 bits weights and [IQ1_S/FP8 hybrid](./doc/en/fp8_kernel.md) weights. Support 139K [Longer Context](./doc/en/DeepseekR1_V3_tutorial.md#v022--v023-longer-context--fp8-kernel) for DeepSeek-V3 and R1 in 24GB VRAM.
* **Feb 25, 2025**: Support [FP8 GPU kernel](./doc/en/fp8_kernel.md) for DeepSeek-V3 and R1; [Longer Context](./doc/en/DeepseekR1_V3_tutorial.md#v022-longer-context).
* **Feb 15, 2025**: Longer Context (from 4K to 8K for 24GB VRAM) & Slightly Faster Speed (+15%, up to 16 Tokens/s), update [docs](./doc/en/DeepseekR1_V3_tutorial.md) and [online books](https://kvcache-ai.github.io/ktransformers/).
* **Feb 10, 2025**: Support Deepseek-R1 and V3 on single (24GB VRAM)/multi gpu and 382G DRAM, up to 3~28x speedup. For detailed show case and reproduction tutorial, see [here](./doc/en/DeepseekR1_V3_tutorial.md).
* **Aug 28, 2024**: Decrease DeepseekV2's required VRAM from 21G to 11G.
* **Aug 15, 2024**: Update detailed [tutorial](doc/en/injection_tutorial.md) for injection and multi-GPU.
* **Aug 14, 2024**: Support llamfile as linear backend.
* **Aug 12, 2024**: Support multiple GPU; Support new model: mixtral 8\*7B and 8\*22B; Support q2k, q3k, q5k dequant on gpu.
* **Aug 9, 2024**: Support windows native.
---
## 📦 Capabilities
### 🚀 [Inference](./kt-kernel/README.md) - High-Performance kt-kernel Serving
CPU-optimized kernel operations for heterogeneous LLM inference.

**Key Features:**
- **AMX/AVX Acceleration**: Intel AMX and AVX512/AVX2 optimized kernels for INT4/INT8 quantized inference
- **MoE Optimization**: Efficient Mixture-of-Experts inference with NUMA-aware memory management
- **Quantization Support**: CPU-side INT4/INT8 quantized weights, GPU-side GPTQ support
- **Easy Integration**: Clean Python API for SGLang and other frameworks
**Quick Start:**
```bash
cd kt-kernel
pip install .
```
**Use Cases:**
- CPU-GPU hybrid inference for large MoE models
- Integration with SGLang for production serving
- Heterogeneous expert placement (hot experts on GPU, cold experts on CPU)
**Performance Examples:**
| Model | Hardware Configuration | Total Throughput | Output Throughput |
|-------|------------------------|------------------|-------------------|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s (8-way concurrency) |
👉 **[Full Documentation →](./kt-kernel/README.md)**
---
### 🎓 [SFT](./doc/en/SFT/KTransformers-Fine-Tuning_Quick-Start.md) - Fine-Tuning with LLaMA-Factory
KTransformers × LLaMA-Factory integration for ultra-large MoE model fine-tuning.
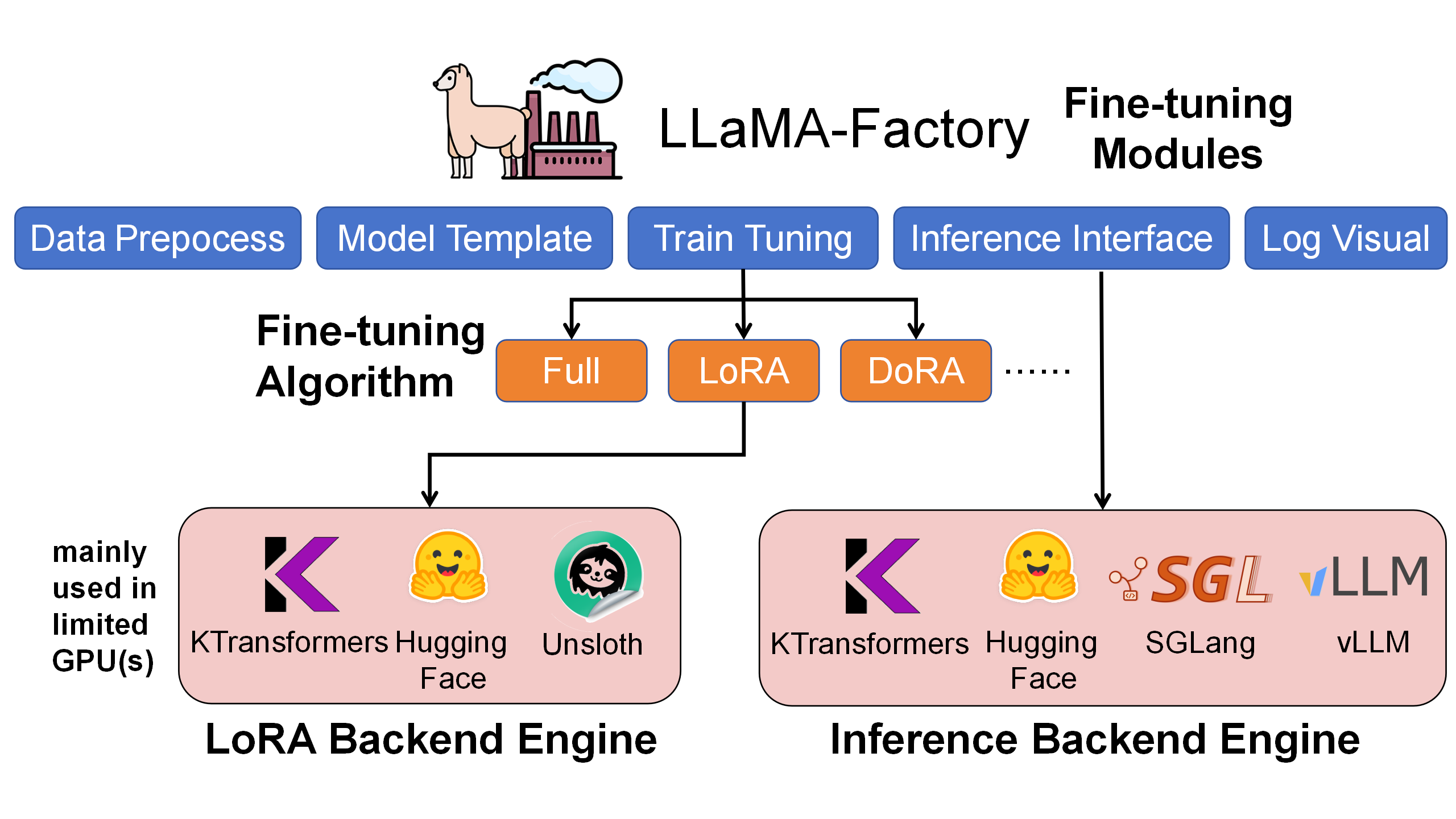
**Key Features:**
- **Multi-Backend Support**: CPU/GPU hybrid fine-tuning with INT8/INT4 quantization
- **Ultra-Large MoE Support**: Fine-tune models like DeepSeek-V3/R1 on limited GPU memory
- **Faster than ZeRO-Offload**: 6-12x training speedup in benchmarked MoE SFT workloads
- **Lower CPU Memory**: About half the CPU memory of the previous KT SFT path in the benchmarked setup
- **LLaMA-Factory Integration**: Seamless integration with popular fine-tuning framework
| Model | GPU Memory | Training Speed | Hardware |
|-------|------------|----------------|----------|
| DeepSeek-V3 | ~80GB total | 3.7 it/s | 4x RTX 4090 |
| DeepSeek-R1 | ~80GB total | 3.7 it/s | 4x RTX 4090 |
| Qwen3-30B-A3B | ~24GB total | 8+ it/s | 1x RTX 4090 |
**Quick Start:**
```bash
cd /path/to/LLaMA-Factory
pip install -e .
pip install -r requirements/ktransformers.txt
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch \
--config_file examples/ktransformers/accelerate/fsdp2_kt_int8.yaml \
src/train.py \
examples/ktransformers/train_lora/qwen3_5moe_lora_sft_kt.yaml
```
👉 **[Quick Start →](./doc/en/SFT/KTransformers-Fine-Tuning_Quick-Start.md)**
👉 **[Full Documentation →](./doc/en/SFT/KTransformers-Fine-Tuning_User-Guide.md)**
---
## 🔥 Citation
If you use KTransformers in your research, please cite our paper:
```bibtex
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
```
## 👥 Contributors & Team
Developed and maintained by:
- [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University
- [Approaching.AI](http://approaching.ai/)
- [9#AISoft](https://github.com/aisoft9)
- Community contributors
We welcome contributions! Please feel free to submit issues and pull requests.
## 💬 Community & Support
- **GitHub Issues**: [Report bugs or request features](https://github.com/kvcache-ai/ktransformers/issues)
- **WeChat Group**: See [archive/WeChatGroup.png](./archive/WeChatGroup.png)
## 📦 KT original Code
The original integrated KTransformers framework has been archived to the [`archive/`](./archive/) directory for reference. The project now organizes the two capabilities above from the kt-kernel source tree for clearer documentation and maintenance.
For the original documentation with full quick-start guides and examples, see:
- [archive/README.md](./archive/README.md) (English)
- [archive/README_ZH.md](./archive/README_ZH.md) (中文)