https://github.com/langchain-ai/langchain-benchmarks
🦜💯 Flex those feathers!
https://github.com/langchain-ai/langchain-benchmarks
benchmark-framework benchmarking langchain langchain-python llm llms
Last synced: about 1 year ago
JSON representation
🦜💯 Flex those feathers!
- Host: GitHub
- URL: https://github.com/langchain-ai/langchain-benchmarks
- Owner: langchain-ai
- License: mit
- Created: 2023-08-10T21:31:11.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-10-21T20:47:16.000Z (over 1 year ago)
- Last Synced: 2025-04-07T16:16:58.935Z (about 1 year ago)
- Topics: benchmark-framework, benchmarking, langchain, langchain-python, llm, llms
- Language: Python
- Homepage: https://langchain-ai.github.io/langchain-benchmarks/
- Size: 16.2 MB
- Stars: 244
- Watchers: 8
- Forks: 51
- Open Issues: 19
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Security: security.md
Awesome Lists containing this project
- StarryDivineSky - langchain-ai/langchain-benchmarks
README
# 🦜💯 LangChain Benchmarks
[](https://github.com/langchain-ai/langchain-benchmarks/releases)
[](https://github.com/langchain-ai/langchain-benchmarks/actions/workflows/ci.yml)
[](https://opensource.org/licenses/MIT)
[](https://twitter.com/langchainai)
[](https://discord.gg/6adMQxSpJS)
[](https://github.com/langchain-ai/langchain-benchmarks/issues)
[📖 Documentation](https://langchain-ai.github.io/langchain-benchmarks/index.html)
A package to help benchmark various LLM related tasks.
The benchmarks are organized by end-to-end use cases, and
utilize [LangSmith](https://smith.langchain.com/) heavily.
We have several goals in open sourcing this:
- Showing how we collect our benchmark datasets for each task
- Showing what the benchmark datasets we use for each task is
- Showing how we evaluate each task
- Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
## Benchmarking Results
Read some of the articles about benchmarking results on our blog.
* [Agent Tool Use](https://blog.langchain.dev/benchmarking-agent-tool-use/)
* [Query Analysis in High Cardinality Situations](https://blog.langchain.dev/high-cardinality/)
* [RAG on Tables](https://blog.langchain.dev/benchmarking-rag-on-tables/)
* [Q&A over CSV data](https://blog.langchain.dev/benchmarking-question-answering-over-csv-data/)
### Tool Usage (2024-04-18)
See [tool usage docs](https://langchain-ai.github.io/langchain-benchmarks/notebooks/tool_usage/benchmark_all_tasks.html) to recreate!
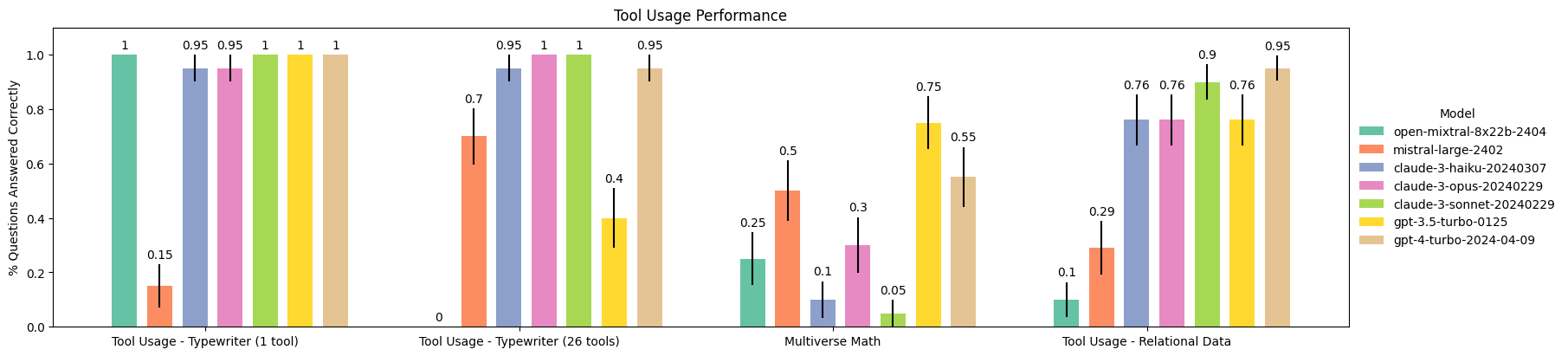
Explore Agent Traces on LangSmith:
* [Relational Data](https://smith.langchain.com/public/22721064-dcf6-4e42-be65-e7c46e6835e7/d)
* [Tool Usage (1-tool)](https://smith.langchain.com/public/ac23cb40-e392-471f-b129-a893a77b6f62/d)
* [Tool Usage (26-tools)](https://smith.langchain.com/public/366bddca-62b3-4b6e-849b-a478abab73db/d)
* [Multiverse Math](https://smith.langchain.com/public/983faff2-54b9-4875-9bf2-c16913e7d489/d)
## Installation
To install the packages, run the following command:
```bash
pip install -U langchain-benchmarks
```
All the benchmarks come with an associated benchmark dataset stored in [LangSmith](https://smith.langchain.com). To take advantage of the eval and debugging experience, [sign up](https://smith.langchain.com), and set your API key in your environment:
```bash
export LANGCHAIN_API_KEY=ls-...
```
## Repo Structure
The package is located within [langchain_benchmarks](./langchain_benchmarks/). Check out the [docs](https://langchain-ai.github.io/langchain-benchmarks/index.html) for information on how to get starte.
The other directories are legacy and may be moved in the future.
## Archived
Below are archived benchmarks that require cloning this repo to run.
- [CSV Question Answering](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/csv-qa)
- [Extraction](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/extraction)
- [Q&A over the LangChain docs](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/langchain-docs-benchmarking)
- [Meta-evaluation of 'correctness' evaluators](https://github.com/langchain-ai/langchain-benchmarks/tree/main/archived/meta-evals)
## Related
- For cookbooks on other ways to test, debug, monitor, and improve your LLM applications, check out the [LangSmith docs](https://docs.smith.langchain.com/)
- For information on building with LangChain, check out the [python documentation](https://python.langchain.com/docs/get_started/introduction) or [JS documentation](https://js.langchain.com/docs/get_started/introduction)