https://github.com/legel/words2map
online natural language processing with word vectors
https://github.com/legel/words2map
Last synced: 3 months ago
JSON representation
online natural language processing with word vectors
- Host: GitHub
- URL: https://github.com/legel/words2map
- Owner: legel
- License: mit
- Created: 2016-06-13T17:40:13.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2024-06-25T15:41:57.000Z (about 1 year ago)
- Last Synced: 2024-11-04T08:36:37.209Z (8 months ago)
- Language: Python
- Homepage: http://web.archive.org/web/20160806040004if_/http://blog.yhat.com/posts/words2map.html
- Size: 147 MB
- Stars: 310
- Watchers: 21
- Forks: 37
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
- awesome-starred - legel/words2map - online natural language processing with word vectors (others)
README

> *How words2map derives out-of-vocabulary ([OOV](https://medium.com/@shabeelkandi/handling-out-of-vocabulary-words-in-natural-language-processing-based-on-context-4bbba16214d5)) vectors by searching online:*
> *(1) Connect NLP vector database with a web search engine API like Google / Bing*
> *(2) Do a web search on unknown words (just like a human would)*
> *(3) Parse N-grams (e.g. N = 5) for all text from top M websites (e.g. M = 50)*
> *(4) Filter known N-grams from pre-trained corpus (e.g. word2vec, with 3 million N-grams)*
> *(5) Rank N-grams: inverse global frequency x local frequency on M websites (i.e. [TF-IDF](https://en.wikipedia.org/wiki/Tf%E2%80%93idf))*
> *(6) Derive a new vector: sum vectors for top O known N-grams (e.g. O = 25), i.e.*
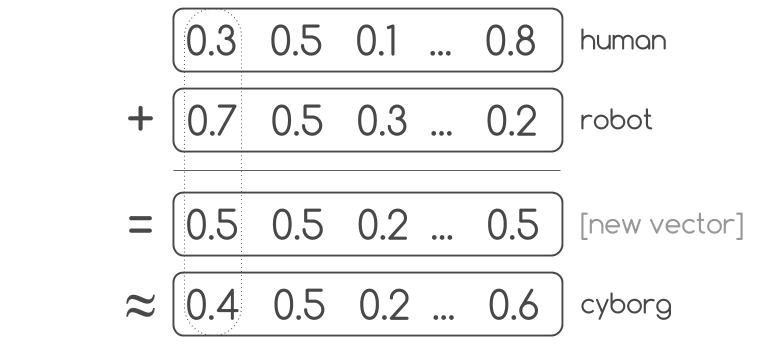
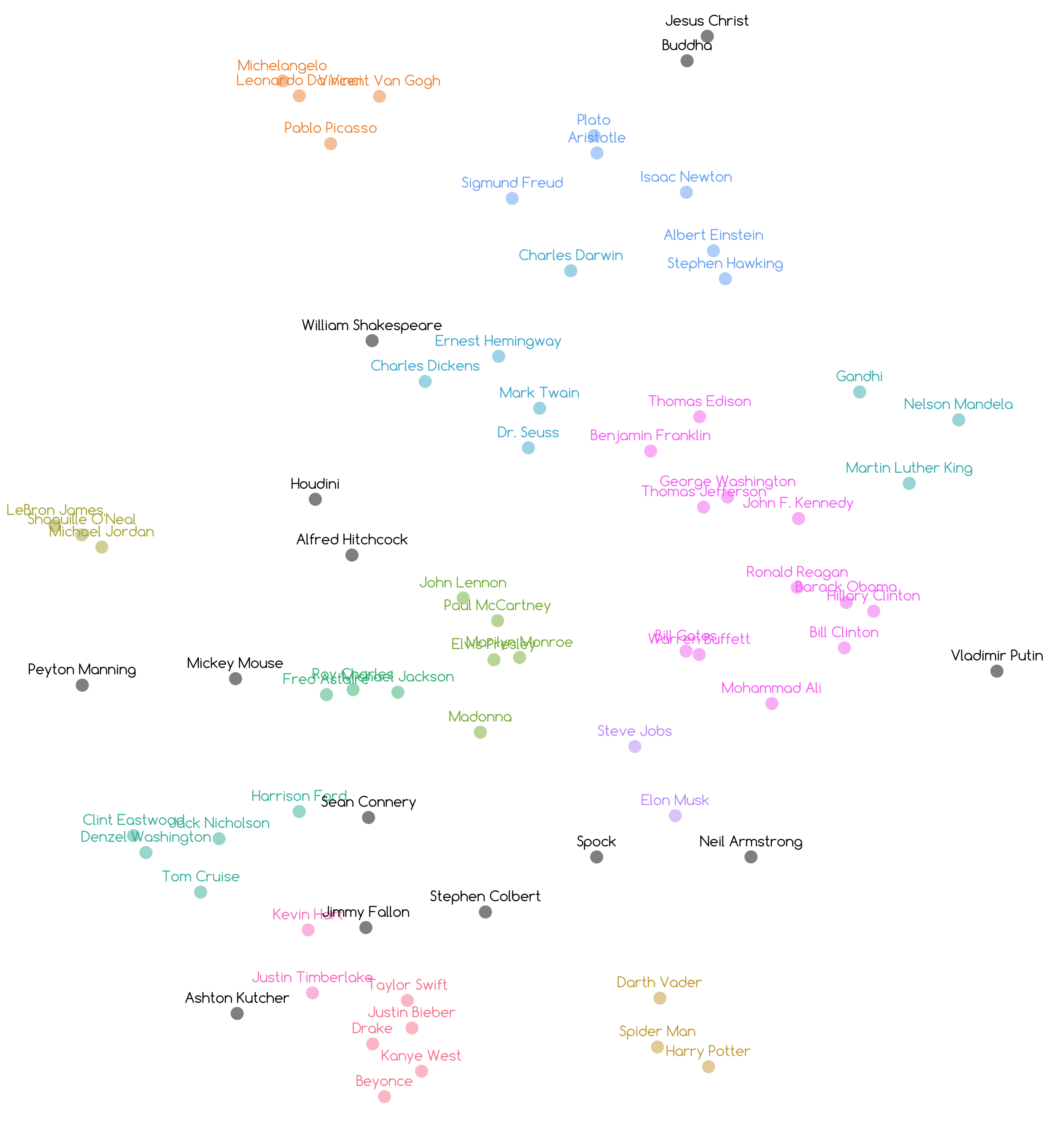
> *(7) Visualize by reducing dimensions to 2D/3D (e.g [t-SNE](https://lvdmaaten.github.io/tsne/) works, but [UMAP](https://github.com/lmcinnes/umap) recommended)*
> *(8) Finally, show clusters with [HDBSCAN](https://github.com/scikit-learn-contrib/hdbscan), color-coded in a perceptually uniform space*
> *These OOV vectors were derived in about 15 seconds as explained above:*

> *See this [archived blog post](http://web.archive.org/web/20160806040004if_/http://blog.yhat.com/posts/words2map.html) for more details on the words2map algorithm.*
### Derive new vectors for words by searching online
```python
from words2map import *
model = load_model()
words = load_words("passions.csv")
vectors = [derive_vector(word, model) for word in words]
save_derived_vectors(words, vectors, "passions.txt")
```
### Analyze derived word vectors
```python
from words2map import *
from pprint import pprint
model = load_derived_vectors("passions.txt")
pprint(k_nearest_neighbors(model=model, k=10, word="Data_Scientists"))
```
### Visualize clusters of vectors
```python
from words2map import *
model = load_derived_vectors("passions.txt")
words = [word for word in model.vocab]
vectors = [model[word] for word in words]
vectors_in_2D = reduce_dimensionality(vectors)
generate_clusters(words, vectors_in_2D)
```
### Install
```shell
# known broken dependencies: automatic conda installation, python 2 -> 3, gensim
# feel free to debug and make a pull request if desired
git clone https://github.com/overlap-ai/words2map.git
cd words2map
./install.sh
```