https://github.com/leoChaoGlut/log-sys
A distributed log system which is based on spring cloud & docker
https://github.com/leoChaoGlut/log-sys
distributed-systems log microservice springcloud
Last synced: about 1 year ago
JSON representation
A distributed log system which is based on spring cloud & docker
- Host: GitHub
- URL: https://github.com/leoChaoGlut/log-sys
- Owner: leoChaoGlut
- Created: 2016-11-02T03:50:14.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2018-04-17T08:56:24.000Z (about 8 years ago)
- Last Synced: 2024-11-16T06:30:30.730Z (over 1 year ago)
- Topics: distributed-systems, log, microservice, springcloud
- Language: JavaScript
- Homepage:
- Size: 1.71 MB
- Stars: 161
- Watchers: 19
- Forks: 96
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-list-microservice - log-sys
README
# 说明
- 日志追踪模型基于论文: Dapper
- [英文原文](http://research.google.com/pubs/pub36356.html)
- [论文译文](http://bigbully.github.io/Dapper-translation/)
# 功能简介
- 多余信息过滤
- 规范日志打印格式
- 微服务应用日志采集
- 高效日志查询,问题定位
- 精确定位关键词所处上下文
- 精确定位关键词所处业务跨应用日志链
# 工程模块简介
- log-common: ☞整个工程的common包.所有需要被采集日志的应用,都需要引用这个包.(使用logback来打印日志)
- log-component: ☞功能组件
- log-component-aggregator: ☞日志内容聚合器,索引聚合.
- log-component-common: ☞功能组件的common包
- log-component-filter: ☞过滤"非目标关键词的日志内容"
- log-component-index:☞ 基础索引数据结构:[上下文索引,key value索引,keyword索引]
- log-component-scanner: ☞日志扫描器,索引扫描器.
- log-component-search-engine: ☞把关键词等信息交给搜索引擎,它能帮你找到你想要的日志
- log-front-end: ☞前端代码
- log-resource: ☞相关资源文件,如sql,shell,redis,服务配置等.
- log-service: ☞日志系统所有服务
- log-service-collector: ☞最重要的服务->采集器 每一台服务器上,只需要配置一个采集器,它可以采集这台服务器上的多个应用的日志.它还提供[实时日志,历史日志,跨应用日志,定时任务]等功能
- log-service-collector-service: ☞"采集器服务",顾名思义:为采集器而服务..它的功能:[注册采集器,让采集器获取数据]
- log-service-common: ☞日志系统服务的common包
- log-service-tracer: ☞与Spring Cloud 的 tracer类似,用于收集跨应用日志.如果应用日志量很多,可以考虑将该服务器拆为一读一写的2个实例.
- log-service-center: ☞Spring Cloud的核心组件
- log-service-center-config-center: ☞配置中心
- log-service-center-gateway: ☞统一入口网关
- log-service-center-registry: ☞注册中心
# 开发环境
- intellj idea
- jdk1.7
- maven3.3.9
- nodejs6.9.2
# 相关技术
- [Spring Cloud Camden.SR6](http://cloud.spring.io/spring-cloud-static/Camden.SR6/)
- [Spring Boot 1.4.5](http://docs.spring.io/spring-boot/docs/1.4.5.RELEASE/reference/htmlsingle/)
- [Vue](https://github.com/vuejs/vue)
- [Element UI](http://element.eleme.io/)
- [Sockjs](https://github.com/sockjs/sockjs-client)
- [Redis3.2.8](https://redis.io/)
- [Kafka](http://kafka.apache.org/)
- [MySQL5.7](https://www.mysql.com/)
# 日志规范
* Logback配置: 请使用logback作为日志打印,并将配置文件logback.xml修改如下.[STDOUT,ALL]是必须的Appender.
```xml
${log.context}
[%d{yyyy-MM-dd HH:mm:ss}][%-5level][%thread][%class.%method:%line]:%m%n
${log.path}/%d{yyyy/MM/dd/HH/mm, aux}/%d{yyyyMMddHHmm}.log
[%d{yyyy-MM-dd HH:mm:ss}][%-5level][%thread][%class.%method:%line]:%m%n
```
* 日志打印:
1.引入依赖:
```xml
cn.yunyichina.log
log-common
1.0-SNAPSHOT
```
2.使用LoggerWrapper替代Logger打印日志:
```java
LoggerWrapper wrapper = LoggerWrapper.getLogger(Target.class);
wrapper.info("hello");
wrapper.getLogger().info("world");
```
3.定义上下文:
```java
/**
* User类,有如下方法
*/
public String getUserBy(Integer userId){
//...
}
```
```java
/**
* UserAspect类,是User类的一个切面,切点'userPointCut'可切取User类的'getUserBy'方法.
*/
@Around("userPointCut()")
public Object aroundUserPointCut(ProceedingJoinPoint pjp) throws Throwable {
wrapper.contextBegin("获取用户开始");//为getUserBy方法生成一个上下文,上下文的开始就是方法被调用之前.此时会利用Mongodb的ObjectId,生成一个id,作为getUserBy这个方法调用的上下文id.
Object returnValue = pjp.proceed();//调用getUserBy()
wrapper.contextEnd("获取用户结束");//上下文的结束,就是getUserBy返回之后,或者异常捕获之后.
}
```
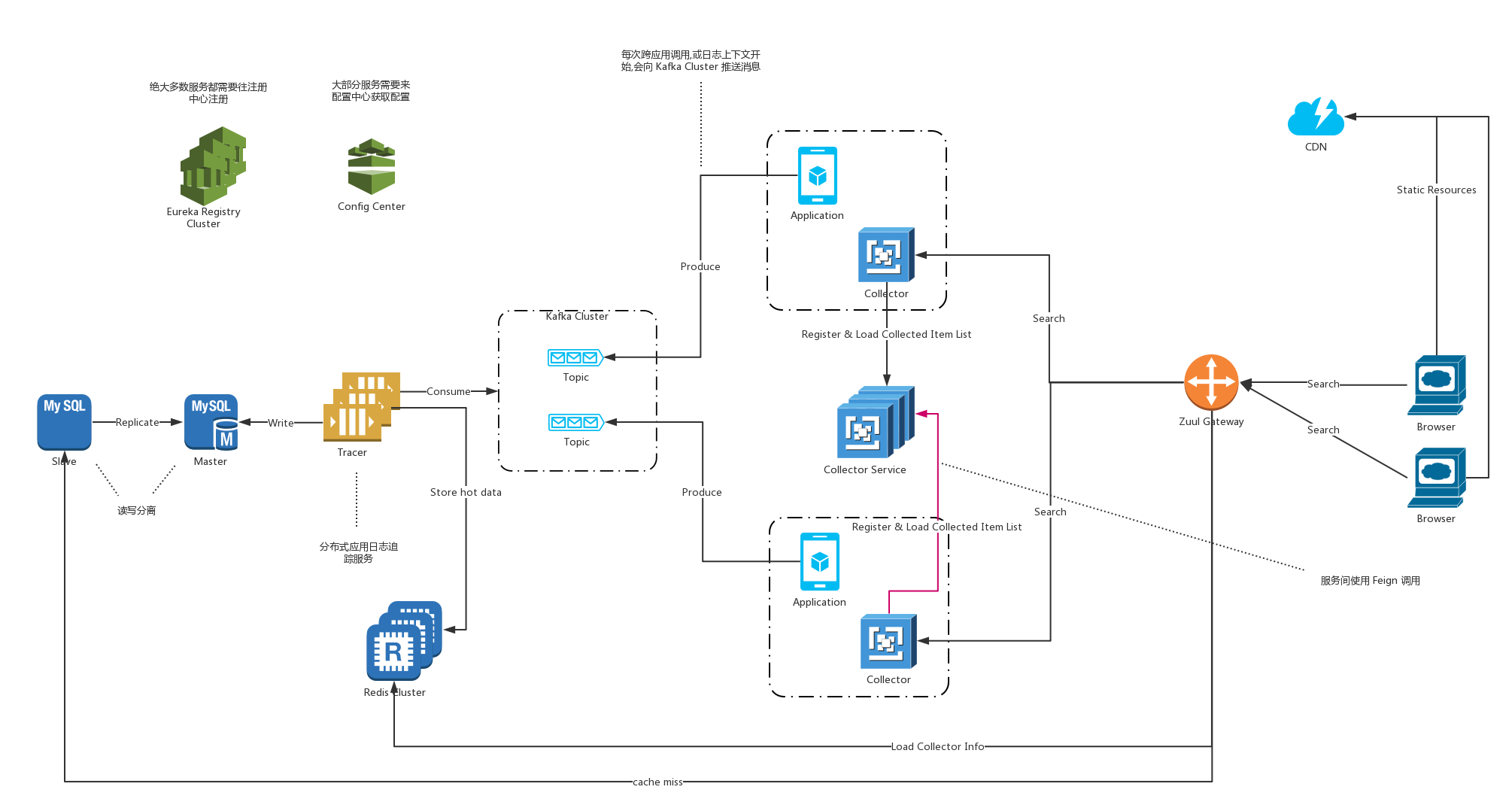
# 基础架构图
# 安装步骤
[Here](https://github.com/leoChaoGlut/log-sys/issues/6)