https://github.com/leondgarse/keras_cv_attention_models
Keras beit,caformer,CMT,CoAtNet,convnext,davit,dino,efficientdet,edgenext,efficientformer,efficientnet,eva,fasternet,fastervit,fastvit,flexivit,gcvit,ghostnet,gpvit,hornet,hiera,iformer,inceptionnext,lcnet,levit,maxvit,mobilevit,moganet,nat,nfnets,pvt,swin,tinynet,tinyvit,uniformer,volo,vanillanet,yolor,yolov7,yolov8,yolox,gpt2,llama2, alias kecam
https://github.com/leondgarse/keras_cv_attention_models
attention clip coco ddpm detection imagenet keras model recognition segment-anything stable-diffusion tensorflow tf tf2 visualizing
Last synced: over 1 year ago
JSON representation
Keras beit,caformer,CMT,CoAtNet,convnext,davit,dino,efficientdet,edgenext,efficientformer,efficientnet,eva,fasternet,fastervit,fastvit,flexivit,gcvit,ghostnet,gpvit,hornet,hiera,iformer,inceptionnext,lcnet,levit,maxvit,mobilevit,moganet,nat,nfnets,pvt,swin,tinynet,tinyvit,uniformer,volo,vanillanet,yolor,yolov7,yolov8,yolox,gpt2,llama2, alias kecam
- Host: GitHub
- URL: https://github.com/leondgarse/keras_cv_attention_models
- Owner: leondgarse
- License: mit
- Created: 2021-08-02T00:59:55.000Z (almost 5 years ago)
- Default Branch: main
- Last Pushed: 2024-07-12T05:25:23.000Z (about 2 years ago)
- Last Synced: 2024-09-07T09:35:41.211Z (almost 2 years ago)
- Topics: attention, clip, coco, ddpm, detection, imagenet, keras, model, recognition, segment-anything, stable-diffusion, tensorflow, tf, tf2, visualizing
- Language: Python
- Homepage:
- Size: 4.22 MB
- Stars: 587
- Watchers: 23
- Forks: 92
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# ___Keras_cv_attention_models___
***
- **WARNING: currently NOT compatible with `keras 3.x`, if using `tensorflow>=2.16.0`, needs to install `pip install tf-keras~=$(pip show tensorflow | awk -F ': ' '/Version/{print $2}')` manually. While importing, import this package ahead of Tensorflow, or set `export TF_USE_LEGACY_KERAS=1`.**
- **It's not recommended downloading and loading model from h5 file directly, better building model and loading weights like `import kecam; mm = kecam.models.LCNet050()`.**
- **coco_train_script.py for TF is still under testing...**
- [___>>>> Roadmap and todo list <<<<___](https://github.com/leondgarse/keras_cv_attention_models/wiki/Roadmap)
- [General Usage](#general-usage)
- [Basic](#basic)
- [T4 Inference](#t4-inference)
- [Layers](#layers)
- [Model surgery](#model-surgery)
- [ImageNet training and evaluating](#imagenet-training-and-evaluating)
- [COCO training and evaluating](#coco-training-and-evaluating)
- [CLIP training and evaluating](#clip-training-and-evaluating)
- [Text training](#text-training)
- [DDPM training](#ddpm-training)
- [Visualizing](#visualizing)
- [TFLite Conversion](#tflite-conversion)
- [Using PyTorch as backend](#using-pytorch-as-backend)
- [Using keras core as backend](#using-keras-core-as-backend)
- [Recognition Models](#recognition-models)
- [AotNet](#aotnet)
- [BEiT](#beit)
- [BEiTV2](#beitv2)
- [BotNet](#botnet)
- [CAFormer](#caformer)
- [CMT](#cmt)
- [CoaT](#coat)
- [CoAtNet](#coatnet)
- [ConvNeXt](#convnext)
- [ConvNeXtV2](#convnextv2)
- [CoTNet](#cotnet)
- [CSPNeXt](#cspnext)
- [DaViT](#davit)
- [DiNAT](#dinat)
- [DINOv2](#dinov2)
- [EdgeNeXt](#edgenext)
- [EfficientFormer](#efficientformer)
- [EfficientFormerV2](#efficientformerv2)
- [EfficientNet](#efficientnet)
- [EfficientNetEdgeTPU](#efficientnetedgetpu)
- [EfficientNetV2](#efficientnetv2)
- [EfficientViT_B](#efficientvit_b)
- [EfficientViT_M](#efficientvit_m)
- [EVA](#eva)
- [EVA02](#eva02)
- [FasterNet](#fasternet)
- [FasterViT](#fastervit)
- [FastViT](#fastvit)
- [FBNetV3](#fbnetv3)
- [FlexiViT](#flexivit)
- [GCViT](#gcvit)
- [GhostNet](#ghostnet)
- [GhostNetV2](#ghostnetv2)
- [GMLP](#gmlp)
- [GPViT](#gpvit)
- [HaloNet](#halonet)
- [Hiera](#hiera)
- [HorNet](#hornet)
- [IFormer](#iformer)
- [InceptionNeXt](#inceptionnext)
- [LCNet](#lcnet)
- [LeViT](#levit)
- [MaxViT](#maxvit)
- [MetaTransFormer](#metatransformer)
- [MLP mixer](#mlp-mixer)
- [MobileNetV3](#mobilenetv3)
- [MobileViT](#mobilevit)
- [MobileViT_V2](#mobilevit_v2)
- [MogaNet](#moganet)
- [NAT](#nat)
- [NFNets](#nfnets)
- [PVT_V2](#pvt_v2)
- [RegNetY](#regnety)
- [RegNetZ](#regnetz)
- [RepViT](#repvit)
- [ResMLP](#resmlp)
- [ResNeSt](#resnest)
- [ResNetD](#resnetd)
- [ResNetQ](#resnetq)
- [ResNeXt](#resnext)
- [SwinTransformerV2](#swintransformerv2)
- [TinyNet](#tinynet)
- [TinyViT](#tinyvit)
- [UniFormer](#uniformer)
- [VanillaNet](#vanillanet)
- [VOLO](#volo)
- [WaveMLP](#wavemlp)
- [Detection Models](#detection-models)
- [EfficientDet](#efficientdet)
- [YOLO_NAS](#yolo_nas)
- [YOLOR](#yolor)
- [YOLOV7](#yolov7)
- [YOLOV8](#yolov8)
- [YOLOX](#yolox)
- [Language Models](#language-models)
- [GPT2](#gpt2)
- [LLaMA2](#llama2)
- [Stable Diffusion](#stable-diffusion)
- [Segmentation Models](#segmentation-models)
- [YOLOV8 Segmentation](#yolov8-segmentation)
- [Segment Anything](#segment-anything)
- [Licenses](#licenses)
- [Citing](#citing)
***
# General Usage
## Basic
- **Default import** will not specific these while using them in READMEs.
```py
import os
import sys
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow import keras
```
- Install as pip package. `kecam` is a short alias name of this package. **Note**: the pip package `kecam` doesn't set any backend requirement, make sure either Tensorflow or PyTorch installed before hand. For PyTorch backend usage, refer [Keras PyTorch Backend](keras_cv_attention_models/pytorch_backend).
```sh
pip install -U kecam
# Or
pip install -U keras-cv-attention-models
# Or
pip install -U git+https://github.com/leondgarse/keras_cv_attention_models
```
Refer to each sub directory for detail usage.
- **Basic model prediction**
```py
from keras_cv_attention_models import volo
mm = volo.VOLO_d1(pretrained="imagenet")
""" Run predict """
import tensorflow as tf
from tensorflow import keras
from keras_cv_attention_models.test_images import cat
img = cat()
imm = keras.applications.imagenet_utils.preprocess_input(img, mode='torch')
pred = mm(tf.expand_dims(tf.image.resize(imm, mm.input_shape[1:3]), 0)).numpy()
pred = tf.nn.softmax(pred).numpy() # If classifier activation is not softmax
print(keras.applications.imagenet_utils.decode_predictions(pred)[0])
# [('n02124075', 'Egyptian_cat', 0.99664897),
# ('n02123045', 'tabby', 0.0007249644),
# ('n02123159', 'tiger_cat', 0.00020345),
# ('n02127052', 'lynx', 5.4973923e-05),
# ('n02123597', 'Siamese_cat', 2.675306e-05)]
```
Or just use model preset `preprocess_input` and `decode_predictions`
```py
from keras_cv_attention_models import coatnet
mm = coatnet.CoAtNet0()
from keras_cv_attention_models.test_images import cat
preds = mm(mm.preprocess_input(cat()))
print(mm.decode_predictions(preds))
# [[('n02124075', 'Egyptian_cat', 0.9999875), ('n02123045', 'tabby', 5.194884e-06), ...]]
```
The preset `preprocess_input` and `decode_predictions` also compatible with PyTorch backend.
```py
os.environ['KECAM_BACKEND'] = 'torch'
from keras_cv_attention_models import caformer
mm = caformer.CAFormerS18()
# >>>> Using PyTorch backend
# >>>> Aligned input_shape: [3, 224, 224]
# >>>> Load pretrained from: ~/.keras/models/caformer_s18_224_imagenet.h5
from keras_cv_attention_models.test_images import cat
preds = mm(mm.preprocess_input(cat()))
print(preds.shape)
# torch.Size([1, 1000])
print(mm.decode_predictions(preds))
# [[('n02124075', 'Egyptian_cat', 0.8817097), ('n02123045', 'tabby', 0.009335292), ...]]
```
- **`num_classes=0`** set for excluding model top `GlobalAveragePooling2D + Dense` layers.
```py
from keras_cv_attention_models import resnest
mm = resnest.ResNest50(num_classes=0)
print(mm.output_shape)
# (None, 7, 7, 2048)
```
- **`num_classes={custom output classes}`** others than `1000` or `0` will just skip loading the header Dense layer weights. As `model.load_weights(weight_file, by_name=True, skip_mismatch=True)` is used for loading weights.
```py
from keras_cv_attention_models import swin_transformer_v2
mm = swin_transformer_v2.SwinTransformerV2Tiny_window8(num_classes=64)
# >>>> Load pretrained from: ~/.keras/models/swin_transformer_v2_tiny_window8_256_imagenet.h5
# WARNING:tensorflow:Skipping loading weights for layer #601 (named predictions) due to mismatch in shape for weight predictions/kernel:0. Weight expects shape (768, 64). Received saved weight with shape (768, 1000)
# WARNING:tensorflow:Skipping loading weights for layer #601 (named predictions) due to mismatch in shape for weight predictions/bias:0. Weight expects shape (64,). Received saved weight with shape (1000,)
```
- **Reload own model weights by set `pretrained="xxx.h5"`**. Better than calling `model.load_weights` directly, if reloading model with different `input_shape` and with weights shape not matching.
```py
import os
from keras_cv_attention_models import coatnet
pretrained = os.path.expanduser('~/.keras/models/coatnet0_224_imagenet.h5')
mm = coatnet.CoAtNet1(input_shape=(384, 384, 3), pretrained=pretrained) # No sense, just showing usage
```
- **Alias name `kecam`** can be used instead of `keras_cv_attention_models`. It's `__init__.py` only with `from keras_cv_attention_models import *`.
```py
import kecam
mm = kecam.yolor.YOLOR_CSP()
imm = kecam.test_images.dog_cat()
preds = mm(mm.preprocess_input(imm))
bboxs, lables, confidences = mm.decode_predictions(preds)[0]
kecam.coco.show_image_with_bboxes(imm, bboxs, lables, confidences)
```
- **Calculate flops** method from [TF 2.0 Feature: Flops calculation #32809](https://github.com/tensorflow/tensorflow/issues/32809#issuecomment-849439287). For PyTorch backend, needs `thop` `pip install thop`.
```py
from keras_cv_attention_models import coatnet, resnest, model_surgery
model_surgery.get_flops(coatnet.CoAtNet0())
# >>>> FLOPs: 4,221,908,559, GFLOPs: 4.2219G
model_surgery.get_flops(resnest.ResNest50())
# >>>> FLOPs: 5,378,399,992, GFLOPs: 5.3784G
```
- **[Deprecated] `tensorflow_addons`** is not imported by default. While reloading model depending on `GroupNormalization` like `MobileViTV2` from `h5` directly, needs to import `tensorflow_addons` manually first.
```py
import tensorflow_addons as tfa
model_path = os.path.expanduser('~/.keras/models/mobilevit_v2_050_256_imagenet.h5')
mm = keras.models.load_model(model_path)
```
- **Export TF model to onnx**. Needs `tf2onnx` for TF, `pip install onnx tf2onnx onnxsim onnxruntime`. For using PyTorch backend, exporting onnx is supported by PyTorch.
```py
from keras_cv_attention_models import volo, nat, model_surgery
mm = nat.DiNAT_Small(pretrained=True)
model_surgery.export_onnx(mm, fuse_conv_bn=True, batch_size=1, simplify=True)
# Exported simplified onnx: dinat_small.onnx
# Run test
from keras_cv_attention_models.imagenet import eval_func
aa = eval_func.ONNXModelInterf(mm.name + '.onnx')
inputs = np.random.uniform(size=[1, *mm.input_shape[1:]]).astype('float32')
print(f"{np.allclose(aa(inputs), mm(inputs), atol=1e-5) = }")
# np.allclose(aa(inputs), mm(inputs), atol=1e-5) = True
```
- **Model summary** `model_summary.csv` contains gathered model info.
- `params` for model params count in `M`
- `flops` for FLOPs in `G`
- `input` for model input shape
- `acc_metrics` means `Imagenet Top1 Accuracy` for recognition models, `COCO val AP` for detection models
- `inference_qps` for `T4 inference query per second` with `batch_size=1 + trtexec`
- `extra` means if any extra training info.
```py
from keras_cv_attention_models import plot_func
plot_series = [
"efficientnetv2", 'tinynet', 'lcnet', 'mobilenetv3', 'fasternet', 'fastervit', 'ghostnet',
'inceptionnext', 'efficientvit_b', 'mobilevit', 'convnextv2', 'efficientvit_m', 'hiera',
]
plot_func.plot_model_summary(
plot_series, model_table="model_summary.csv", log_scale_x=True, allow_extras=['mae_in1k_ft1k']
)
```
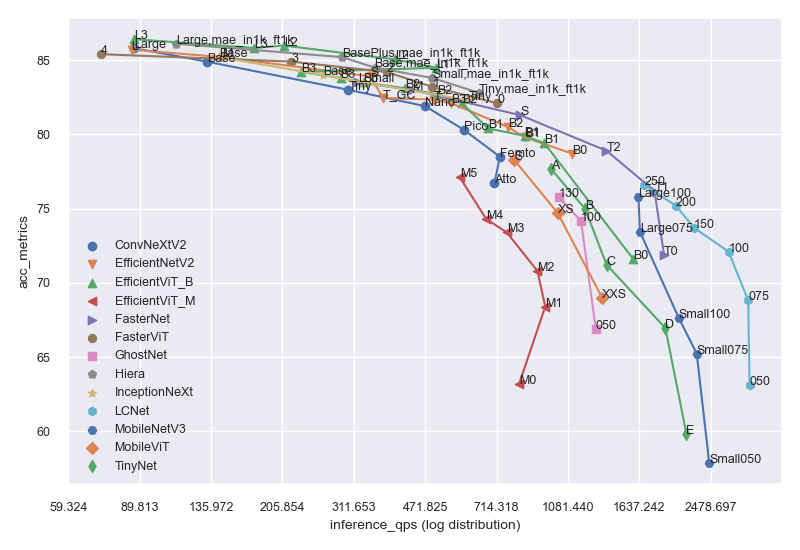
- **Code format** is using `line-length=160`:
```sh
find ./* -name "*.py" | grep -v __init__ | xargs -I {} black -l 160 {}
```
## T4 Inference
- **T4 Inference** in the model tables are tested using `trtexec` on `Tesla T4` with `CUDA=12.0.1-1, Driver=525.60.13`. All models are exported as ONNX using PyTorch backend, using `batch_szie=1` only. **Note: this data is for reference only, and vary in different batch sizes or benchmark tools or platforms or implementations**.
- All results are tested using colab [trtexec.ipynb](https://colab.research.google.com/drive/1xLwfvbZNqadkdAZu9b0UzOrETLo657oc?usp=drive_link). Thus reproducible by any others.
```py
os.environ["KECAM_BACKEND"] = "torch"
from keras_cv_attention_models import convnext, test_images, imagenet
# >>>> Using PyTorch backend
mm = convnext.ConvNeXtTiny()
mm.export_onnx(simplify=True)
# Exported onnx: convnext_tiny.onnx
# Running onnxsim.simplify...
# Exported simplified onnx: convnext_tiny.onnx
# Onnx run test
tt = imagenet.eval_func.ONNXModelInterf('convnext_tiny.onnx')
print(mm.decode_predictions(tt(mm.preprocess_input(test_images.cat()))))
# [[('n02124075', 'Egyptian_cat', 0.880507), ('n02123045', 'tabby', 0.0047998047), ...]]
""" Run trtexec benchmark """
!trtexec --onnx=convnext_tiny.onnx --fp16 --allowGPUFallback --useSpinWait --useCudaGraph
```
## Layers
- [attention_layers](keras_cv_attention_models/attention_layers) is `__init__.py` only, which imports core layers defined in model architectures. Like `RelativePositionalEmbedding` from `botnet`, `outlook_attention` from `volo`, and many other `Positional Embedding Layers` / `Attention Blocks`.
```py
from keras_cv_attention_models import attention_layers
aa = attention_layers.RelativePositionalEmbedding()
print(f"{aa(tf.ones([1, 4, 14, 16, 256])).shape = }")
# aa(tf.ones([1, 4, 14, 16, 256])).shape = TensorShape([1, 4, 14, 16, 14, 16])
```
## Model surgery
- [model_surgery](keras_cv_attention_models/model_surgery) including functions used to change model parameters after built.
```py
from keras_cv_attention_models import model_surgery
mm = keras.applications.ResNet50() # Trainable params: 25,583,592
# Replace all ReLU with PReLU. Trainable params: 25,606,312
mm = model_surgery.replace_ReLU(mm, target_activation='PReLU')
# Fuse conv and batch_norm layers. Trainable params: 25,553,192
mm = model_surgery.convert_to_fused_conv_bn_model(mm)
```
## ImageNet training and evaluating
- [ImageNet](keras_cv_attention_models/imagenet) contains more detail usage and some comparing results.
- [Init Imagenet dataset using tensorflow_datasets #9](https://github.com/leondgarse/keras_cv_attention_models/discussions/9).
- For custom dataset, `custom_dataset_script.py` can be used creating a `json` format file, which can be used as `--data_name xxx.json` for training, detail usage can be found in [Custom recognition dataset](https://github.com/leondgarse/keras_cv_attention_models/discussions/52#discussion-3971513).
- Another method creating custom dataset is using `tfds.load`, refer [Writing custom datasets](https://www.tensorflow.org/datasets/add_dataset) and [Creating private tensorflow_datasets from tfds #48](https://github.com/leondgarse/keras_cv_attention_models/discussions/48) by @Medicmind.
- Running an AWS Sagemaker estimator job using `keras_cv_attention_models` can be found in [AWS Sagemaker script example](https://github.com/leondgarse/keras_cv_attention_models/discussions/107) by @Medicmind.
- `aotnet.AotNet50` default parameters set is a typical `ResNet50` architecture with `Conv2D use_bias=False` and `padding` like `PyTorch`.
- Default parameters for `train_script.py` is like `A3` configuration from [ResNet strikes back: An improved training procedure in timm](https://arxiv.org/pdf/2110.00476.pdf) with `batch_size=256, input_shape=(160, 160)`.
```sh
# `antialias` is default enabled for resize, can be turned off be set `--disable_antialias`.
CUDA_VISIBLE_DEVICES='0' TF_XLA_FLAGS="--tf_xla_auto_jit=2" python3 train_script.py --seed 0 -s aotnet50
```
```sh
# Evaluation using input_shape (224, 224).
# `antialias` usage should be same with training.
CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m aotnet50_epoch_103_val_acc_0.7674.h5 -i 224 --central_crop 0.95
# >>>> Accuracy top1: 0.78466 top5: 0.94088
```
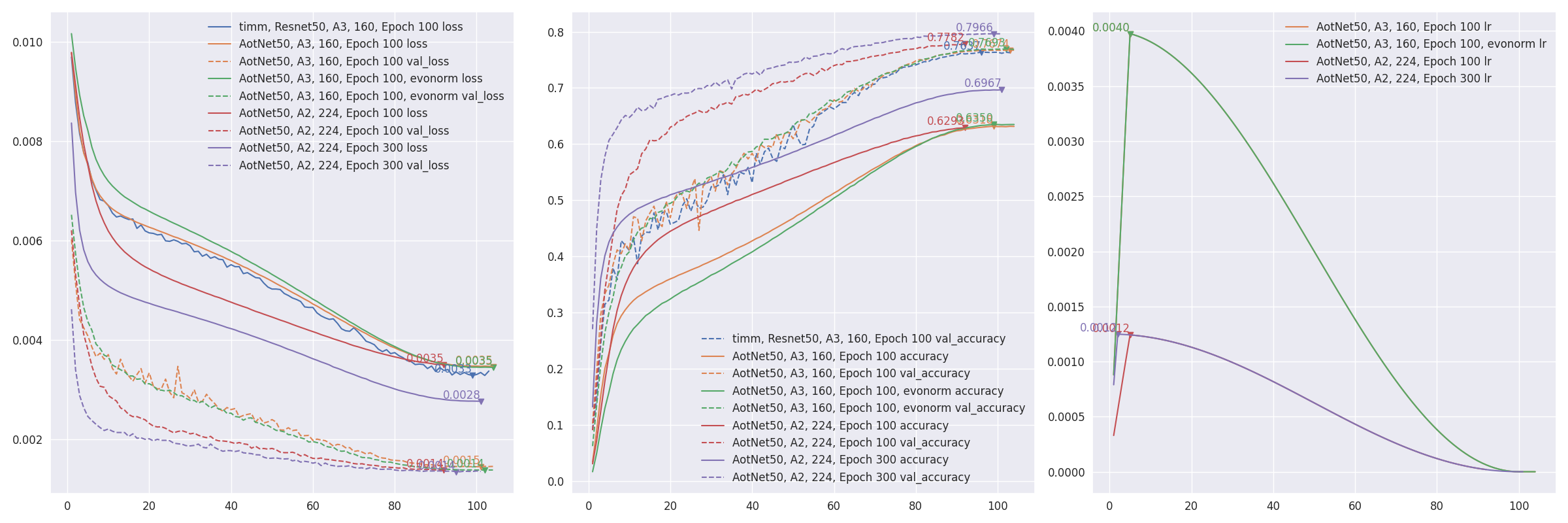
- **Restore from break point** by setting `--restore_path` and `--initial_epoch`, and keep other parameters same. `restore_path` is higher priority than `model` and `additional_model_kwargs`, also restore `optimizer` and `loss`. `initial_epoch` is mainly for learning rate scheduler. If not sure where it stopped, check `checkpoints/{save_name}_hist.json`.
```py
import json
with open("checkpoints/aotnet50_hist.json", "r") as ff:
aa = json.load(ff)
len(aa['lr'])
# 41 ==> 41 epochs are finished, initial_epoch is 41 then, restart from epoch 42
```
```sh
CUDA_VISIBLE_DEVICES='0' TF_XLA_FLAGS="--tf_xla_auto_jit=2" python3 train_script.py --seed 0 -r checkpoints/aotnet50_latest.h5 -I 41
# >>>> Restore model from: checkpoints/aotnet50_latest.h5
# Epoch 42/105
```
- **`eval_script.py`** is used for evaluating model accuracy. [EfficientNetV2 self tested imagenet accuracy #19](https://github.com/leondgarse/keras_cv_attention_models/discussions/19) just showing how different parameters affecting model accuracy.
```sh
# evaluating pretrained builtin model
CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m regnet.RegNetZD8
# evaluating pretrained timm model
CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m timm.models.resmlp_12_224 --input_shape 224
# evaluating specific h5 model
CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m checkpoints/xxx.h5
# evaluating specific tflite model
CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m xxx.tflite
```
- **Progressive training** refer to [PDF 2104.00298 EfficientNetV2: Smaller Models and Faster Training](https://arxiv.org/pdf/2104.00298.pdf). AotNet50 A3 progressive input shapes `96 128 160`:
```sh
CUDA_VISIBLE_DEVICES='1' TF_XLA_FLAGS="--tf_xla_auto_jit=2" python3 progressive_train_script.py \
--progressive_epochs 33 66 -1 \
--progressive_input_shapes 96 128 160 \
--progressive_magnitudes 2 4 6 \
-s aotnet50_progressive_3_lr_steps_100 --seed 0
```
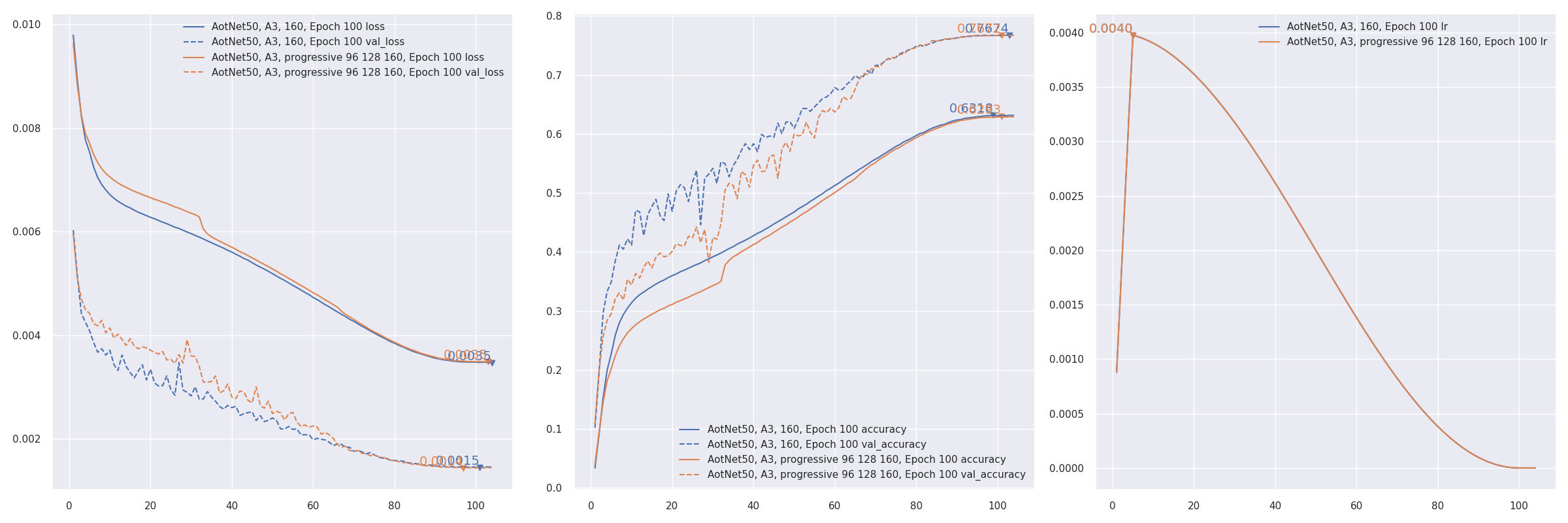
- Transfer learning with `freeze_backbone` or `freeze_norm_layers`: [EfficientNetV2B0 transfer learning on cifar10 testing freezing backbone #55](https://github.com/leondgarse/keras_cv_attention_models/discussions/55).
- [Token label train test on CIFAR10 #57](https://github.com/leondgarse/keras_cv_attention_models/discussions/57). **Currently not working as well as expected**. `Token label` is implementation of [Github zihangJiang/TokenLabeling](https://github.com/zihangJiang/TokenLabeling), paper [PDF 2104.10858 All Tokens Matter: Token Labeling for Training Better Vision Transformers](https://arxiv.org/pdf/2104.10858.pdf).
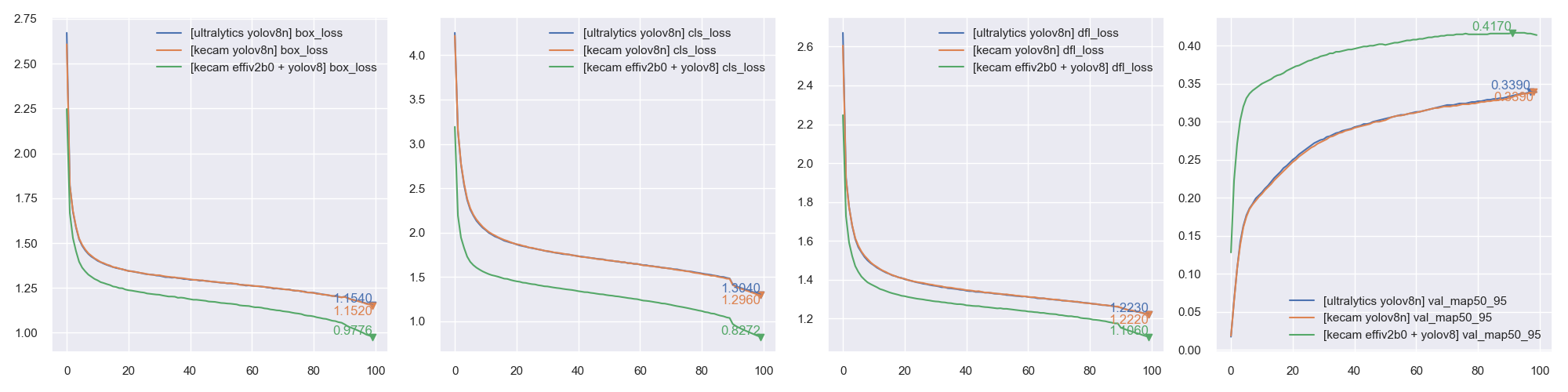
## COCO training and evaluating
- **Currently still under testing**.
- [COCO](keras_cv_attention_models/coco) contains more detail usage.
- `custom_dataset_script.py` can be used creating a `json` format file, which can be used as `--data_name xxx.json` for training, detail usage can be found in [Custom detection dataset](https://github.com/leondgarse/keras_cv_attention_models/discussions/52#discussioncomment-2460664).
- Default parameters for `coco_train_script.py` is `EfficientDetD0` with `input_shape=(256, 256, 3), batch_size=64, mosaic_mix_prob=0.5, freeze_backbone_epochs=32, total_epochs=105`. Technically, it's any `pyramid structure backbone` + `EfficientDet / YOLOX header / YOLOR header` + `anchor_free / yolor / efficientdet anchors` combination supported.
- Currently 4 types anchors supported, parameter **`anchors_mode`** controls which anchor to use, value in `["efficientdet", "anchor_free", "yolor", "yolov8"]`. Default `None` for `det_header` presets.
- **NOTE: `YOLOV8` has a default `regression_len=64` for bbox output length. Typically it's `4` for other detection models, for yolov8 it's `reg_max=16 -> regression_len = 16 * 4 == 64`.**
| anchors_mode | use_object_scores | num_anchors | anchor_scale | aspect_ratios | num_scales | grid_zero_start |
| ------------ | ----------------- | ----------- | ------------ | ------------- | ---------- | --------------- |
| efficientdet | False | 9 | 4 | [1, 2, 0.5] | 3 | False |
| anchor_free | True | 1 | 1 | [1] | 1 | True |
| yolor | True | 3 | None | presets | None | offset=0.5 |
| yolov8 | False | 1 | 1 | [1] | 1 | False |
```sh
# Default EfficientDetD0
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py
# Default EfficientDetD0 using input_shape 512, optimizer adamw, freezing backbone 16 epochs, total 50 + 5 epochs
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py -i 512 -p adamw --freeze_backbone_epochs 16 --lr_decay_steps 50
# EfficientNetV2B0 backbone + EfficientDetD0 detection header
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone efficientnet.EfficientNetV2B0 --det_header efficientdet.EfficientDetD0
# ResNest50 backbone + EfficientDetD0 header using yolox like anchor_free anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone resnest.ResNest50 --anchors_mode anchor_free
# UniformerSmall32 backbone + EfficientDetD0 header using yolor anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone uniformer.UniformerSmall32 --anchors_mode yolor
# Typical YOLOXS with anchor_free anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolox.YOLOXS --freeze_backbone_epochs 0
# YOLOXS with efficientdet anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolox.YOLOXS --anchors_mode efficientdet --freeze_backbone_epochs 0
# CoAtNet0 backbone + YOLOX header with yolor anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone coatnet.CoAtNet0 --det_header yolox.YOLOX --anchors_mode yolor
# Typical YOLOR_P6 with yolor anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolor.YOLOR_P6 --freeze_backbone_epochs 0
# YOLOR_P6 with anchor_free anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolor.YOLOR_P6 --anchors_mode anchor_free --freeze_backbone_epochs 0
# ConvNeXtTiny backbone + YOLOR header with efficientdet anchors
CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone convnext.ConvNeXtTiny --det_header yolor.YOLOR --anchors_mode yolor
```
**Note: COCO training still under testing, may change parameters and default behaviors. Take the risk if would like help developing.**
- **`coco_eval_script.py`** is used for evaluating model AP / AR on COCO validation set. It has a dependency `pip install pycocotools` which is not in package requirements. More usage can be found in [COCO Evaluation](keras_cv_attention_models/coco#evaluation).
```sh
# EfficientDetD0 using resize method bilinear w/o antialias
CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m efficientdet.EfficientDetD0 --resize_method bilinear --disable_antialias
# >>>> [COCOEvalCallback] input_shape: (512, 512), pyramid_levels: [3, 7], anchors_mode: efficientdet
# YOLOX using BGR input format
CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m yolox.YOLOXTiny --use_bgr_input --nms_method hard --nms_iou_or_sigma 0.65
# >>>> [COCOEvalCallback] input_shape: (416, 416), pyramid_levels: [3, 5], anchors_mode: anchor_free
# YOLOR / YOLOV7 using letterbox_pad and other tricks.
CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m yolor.YOLOR_CSP --nms_method hard --nms_iou_or_sigma 0.65 \
--nms_max_output_size 300 --nms_topk -1 --letterbox_pad 64 --input_shape 704
# >>>> [COCOEvalCallback] input_shape: (704, 704), pyramid_levels: [3, 5], anchors_mode: yolor
# Specify h5 model
CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m checkpoints/yoloxtiny_yolor_anchor.h5
# >>>> [COCOEvalCallback] input_shape: (416, 416), pyramid_levels: [3, 5], anchors_mode: yolor
```
- **[Experimental] Training using PyTorch backend**
```py
import os, sys, torch
os.environ["KECAM_BACKEND"] = "torch"
from keras_cv_attention_models.yolov8 import train, yolov8
from keras_cv_attention_models import efficientnet
global_device = torch.device("cuda:0") if torch.cuda.is_available() and int(os.environ.get("CUDA_VISIBLE_DEVICES", "0")) >= 0 else torch.device("cpu")
# model Trainable params: 7,023,904, GFLOPs: 8.1815G
bb = efficientnet.EfficientNetV2B0(input_shape=(3, 640, 640), num_classes=0)
model = yolov8.YOLOV8_N(backbone=bb, classifier_activation=None, pretrained=None).to(global_device) # Note: classifier_activation=None
# model = yolov8.YOLOV8_N(input_shape=(3, None, None), classifier_activation=None, pretrained=None).to(global_device)
ema = train.train(model, dataset_path="coco.json", initial_epoch=0)
```
## CLIP training and evaluating
- [CLIP](keras_cv_attention_models/clip) contains more detail usage.
- `custom_dataset_script.py` can be used creating a `tsv` / `json` format file, which can be used as `--data_name xxx.tsv` for training, detail usage can be found in [Custom caption dataset](https://github.com/leondgarse/keras_cv_attention_models/discussions/52#discussioncomment-6516154).
- **Train using `clip_train_script.py on COCO captions`** Default `--data_path` is a testing one `datasets/coco_dog_cat/captions.tsv`.
```sh
CUDA_VISIBLE_DEVICES=1 TF_XLA_FLAGS="--tf_xla_auto_jit=2" python clip_train_script.py -i 160 -b 128 \
--text_model_pretrained None --data_path coco_captions.tsv
```
**Train Using PyTorch backend by setting `KECAM_BACKEND='torch'`**
```sh
KECAM_BACKEND='torch' CUDA_VISIBLE_DEVICES=1 python clip_train_script.py -i 160 -b 128 \
--text_model_pretrained None --data_path coco_captions.tsv
```
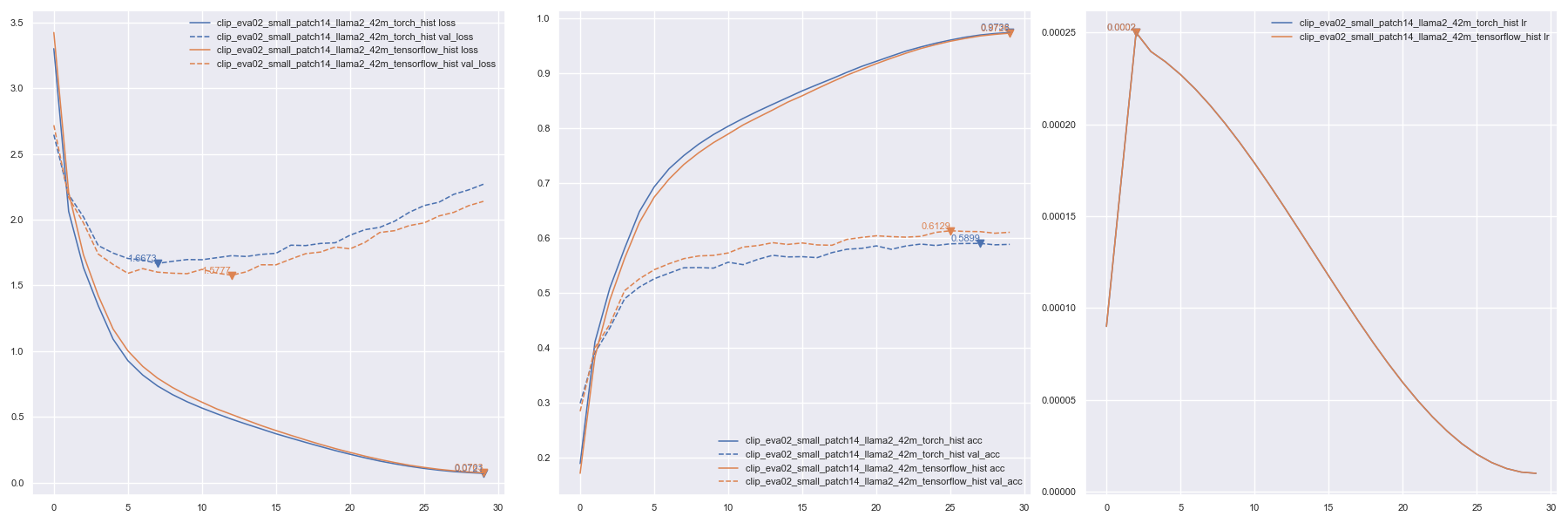
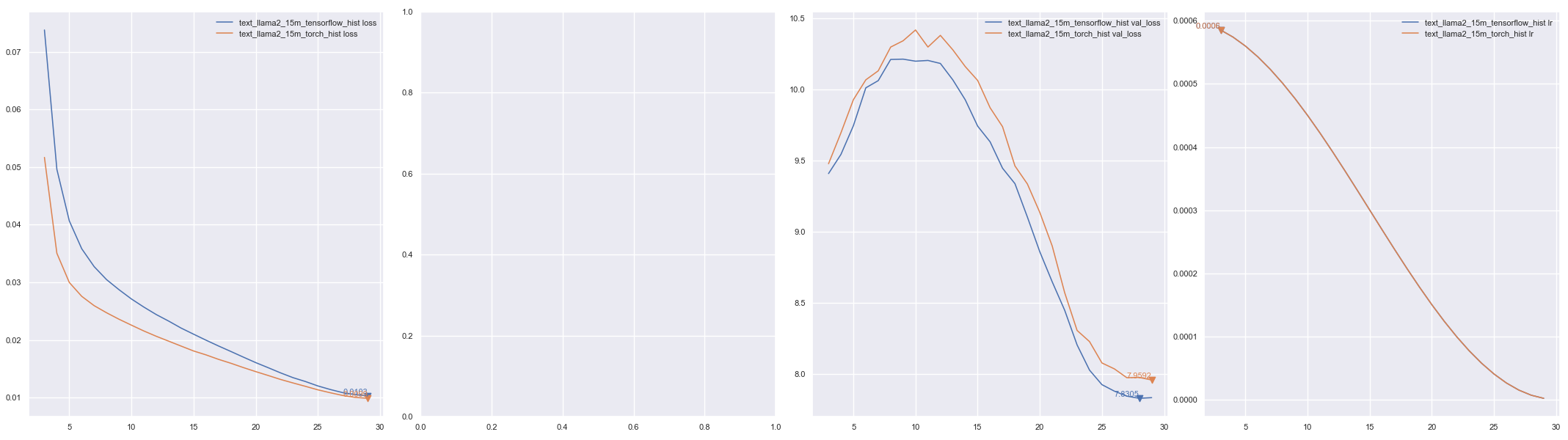
## Text training
- Currently it's only a simple one modified from [Github karpathy/nanoGPT](https://github.com/karpathy/nanoGPT).
- **Train using `text_train_script.py`** As dataset is randomly sampled, needs to specify `steps_per_epoch`
```sh
CUDA_VISIBLE_DEVICES=1 TF_XLA_FLAGS="--tf_xla_auto_jit=2" python text_train_script.py -m LLaMA2_15M \
--steps_per_epoch 8000 --batch_size 8 --tokenizer SentencePieceTokenizer
```
**Train Using PyTorch backend by setting `KECAM_BACKEND='torch'`**
```sh
KECAM_BACKEND='torch' CUDA_VISIBLE_DEVICES=1 python text_train_script.py -m LLaMA2_15M \
--steps_per_epoch 8000 --batch_size 8 --tokenizer SentencePieceTokenizer
```
**Plotting**
```py
from keras_cv_attention_models import plot_func
hists = ['checkpoints/text_llama2_15m_tensorflow_hist.json', 'checkpoints/text_llama2_15m_torch_hist.json']
plot_func.plot_hists(hists, addition_plots=['val_loss', 'lr'], skip_first=3)
```
## DDPM training
- [Stable Diffusion](keras_cv_attention_models/stable_diffusion) contains more detail usage.
- **Note: Works better with PyTorch backend, Tensorflow one seems overfitted if training logger like `--epochs 200`, and evaluation runs ~5 times slower. [???]**
- **Dataset** can be a directory containing images for basic DDPM training using images only, or a recognition json file created following [Custom recognition dataset](https://github.com/leondgarse/keras_cv_attention_models/discussions/52#discussion-3971513), which will train using labels as instruction.
```sh
python custom_dataset_script.py --train_images cifar10/train/ --test_images cifar10/test/
# >>>> total_train_samples: 50000, total_test_samples: 10000, num_classes: 10
# >>>> Saved to: cifar10.json
```
- **Train using `ddpm_train_script.py on cifar10 with labels`** Default `--data_path` is builtin `cifar10`.
```py
# Set --eval_interval 50 as TF evaluation is rather slow [???]
TF_XLA_FLAGS="--tf_xla_auto_jit=2" CUDA_VISIBLE_DEVICES=1 python ddpm_train_script.py --eval_interval 50
```
**Train Using PyTorch backend by setting `KECAM_BACKEND='torch'`**
```py
KECAM_BACKEND='torch' CUDA_VISIBLE_DEVICES=1 python ddpm_train_script.py
```

## Visualizing
- [Visualizing](keras_cv_attention_models/visualizing) is for visualizing convnet filters or attention map scores.
- **make_and_apply_gradcam_heatmap** is for Grad-CAM class activation visualization.
```py
from keras_cv_attention_models import visualizing, test_images, resnest
mm = resnest.ResNest50()
img = test_images.dog()
superimposed_img, heatmap, preds = visualizing.make_and_apply_gradcam_heatmap(mm, img, layer_name="auto")
```

- **plot_attention_score_maps** is model attention score maps visualization.
```py
from keras_cv_attention_models import visualizing, test_images, botnet
img = test_images.dog()
_ = visualizing.plot_attention_score_maps(botnet.BotNetSE33T(), img)
```

## TFLite Conversion
- Currently `TFLite` not supporting `tf.image.extract_patches` / `tf.transpose with len(perm) > 4`. Some operations could be supported in latest or `tf-nightly` version, like previously not supported `gelu` / `Conv2D with groups>1` are working now. May try if encountering issue.
- More discussion can be found [Converting a trained keras CV attention model to TFLite #17](https://github.com/leondgarse/keras_cv_attention_models/discussions/17). Some speed testing results can be found [How to speed up inference on a quantized model #44](https://github.com/leondgarse/keras_cv_attention_models/discussions/44#discussioncomment-2348910).
- Functions like `model_surgery.convert_groups_conv2d_2_split_conv2d` and `model_surgery.convert_gelu_to_approximate` are not needed using up-to-date TF version.
- Not supporting `VOLO` / `HaloNet` models converting, cause they need a longer `tf.transpose` `perm`.
- **model_surgery.convert_dense_to_conv** converts all `Dense` layer with 3D / 4D inputs to `Conv1D` / `Conv2D`, as currently TFLite xnnpack not supporting it.
```py
from keras_cv_attention_models import beit, model_surgery, efficientformer, mobilevit
mm = efficientformer.EfficientFormerL1()
mm = model_surgery.convert_dense_to_conv(mm) # Convert all Dense layers
converter = tf.lite.TFLiteConverter.from_keras_model(mm)
open(mm.name + ".tflite", "wb").write(converter.convert())
```
| Model | Dense, use_xnnpack=false | Conv, use_xnnpack=false | Conv, use_xnnpack=true |
| ----------------- | ------------------------- | ------------------------- | ------------------------- |
| MobileViT_S | Inference (avg) 215371 us | Inference (avg) 163836 us | Inference (avg) 163817 us |
| EfficientFormerL1 | Inference (avg) 126829 us | Inference (avg) 107053 us | Inference (avg) 107132 us |
- **model_surgery.convert_extract_patches_to_conv** converts `tf.image.extract_patches` to a `Conv2D` version:
```py
from keras_cv_attention_models import cotnet, model_surgery
from keras_cv_attention_models.imagenet import eval_func
mm = cotnet.CotNetSE50D()
mm = model_surgery.convert_groups_conv2d_2_split_conv2d(mm)
# mm = model_surgery.convert_gelu_to_approximate(mm) # Not required if using up-to-date TFLite
mm = model_surgery.convert_extract_patches_to_conv(mm)
converter = tf.lite.TFLiteConverter.from_keras_model(mm)
open(mm.name + ".tflite", "wb").write(converter.convert())
test_inputs = np.random.uniform(size=[1, *mm.input_shape[1:]])
print(np.allclose(mm(test_inputs), eval_func.TFLiteModelInterf(mm.name + '.tflite')(test_inputs), atol=1e-7))
# True
```
- **model_surgery.prepare_for_tflite** is just a combination of above functions:
```py
from keras_cv_attention_models import beit, model_surgery
mm = beit.BeitBasePatch16()
mm = model_surgery.prepare_for_tflite(mm)
converter = tf.lite.TFLiteConverter.from_keras_model(mm)
open(mm.name + ".tflite", "wb").write(converter.convert())
```
- **Detection models** including `efficinetdet` / `yolox` / `yolor`, model can be converted a TFLite format directly. If need [DecodePredictions](https://github.com/leondgarse/keras_cv_attention_models/blob/main/keras_cv_attention_models/coco/eval_func.py#L8) also included in TFLite model, need to set `use_static_output=True` for `DecodePredictions`, as TFLite requires a more static output shape. Model output shape will be fixed as `[batch, max_output_size, 6]`. The last dimension `6` means `[bbox_top, bbox_left, bbox_bottom, bbox_right, label_index, confidence]`, and those valid ones are where `confidence > 0`.
```py
""" Init model """
from keras_cv_attention_models import efficientdet
model = efficientdet.EfficientDetD0(pretrained="coco")
""" Create a model with DecodePredictions using `use_static_output=True` """
model.decode_predictions.use_static_output = True
# parameters like score_threshold / iou_or_sigma can be set another value if needed.
nn = model.decode_predictions(model.outputs[0], score_threshold=0.5)
bb = keras.models.Model(model.inputs[0], nn)
""" Convert TFLite """
converter = tf.lite.TFLiteConverter.from_keras_model(bb)
open(bb.name + ".tflite", "wb").write(converter.convert())
""" Inference test """
from keras_cv_attention_models.imagenet import eval_func
from keras_cv_attention_models import test_images
dd = eval_func.TFLiteModelInterf(bb.name + ".tflite")
imm = test_images.cat()
inputs = tf.expand_dims(tf.image.resize(imm, dd.input_shape[1:-1]), 0)
inputs = keras.applications.imagenet_utils.preprocess_input(inputs, mode='torch')
preds = dd(inputs)[0]
print(f"{preds.shape = }")
# preds.shape = (100, 6)
pred = preds[preds[:, -1] > 0]
bboxes, labels, confidences = pred[:, :4], pred[:, 4], pred[:, -1]
print(f"{bboxes = }, {labels = }, {confidences = }")
# bboxes = array([[0.22825494, 0.47238672, 0.816262 , 0.8700745 ]], dtype=float32),
# labels = array([16.], dtype=float32),
# confidences = array([0.8309707], dtype=float32)
""" Show result """
from keras_cv_attention_models.coco import data
data.show_image_with_bboxes(imm, bboxes, labels, confidences, num_classes=90)
```
## Using PyTorch as backend
- **Experimental** [Keras PyTorch Backend](keras_cv_attention_models/pytorch_backend).
- **Set os environment `export KECAM_BACKEND='torch'` to enable this PyTorch backend.**
- Currently supports most recognition and detection models except hornet*gf / nfnets / volo. For detection models, using `torchvision.ops.nms` while running prediction.
- **Basic model build and prediction**.
- Will load same `h5` weights as TF one if available.
- Note: `input_shape` will auto fit image data format. Given `input_shape=(224, 224, 3)` or `input_shape=(3, 224, 224)`, will both set to `(3, 224, 224)` if `channels_first`.
- Note: model is default set to `eval` mode.
```py
os.environ['KECAM_BACKEND'] = 'torch'
from keras_cv_attention_models import res_mlp
mm = res_mlp.ResMLP12()
# >>>> Load pretrained from: ~/.keras/models/resmlp12_imagenet.h5
print(f"{mm.input_shape = }")
# mm.input_shape = [None, 3, 224, 224]
import torch
print(f"{isinstance(mm, torch.nn.Module) = }")
# isinstance(mm, torch.nn.Module) = True
# Run prediction
from keras_cv_attention_models.test_images import cat
print(mm.decode_predictions(mm(mm.preprocess_input(cat())))[0])
# [('n02124075', 'Egyptian_cat', 0.9597896), ('n02123045', 'tabby', 0.012809471), ...]
```
- **Export typical PyTorch onnx / pth**.
```py
import torch
torch.onnx.export(mm, torch.randn(1, 3, *mm.input_shape[2:]), mm.name + ".onnx")
# Or by export_onnx
mm.export_onnx()
# Exported onnx: resmlp12.onnx
mm.export_pth()
# Exported pth: resmlp12.pth
```
- **Save weights as h5**. This `h5` can also be loaded in typical TF backend model. Currently it's only weights without model structure supported.
```py
mm.save_weights("foo.h5")
```
- **Training with compile and fit** Note: loss function arguments should be `y_true, y_pred`, while typical torch loss functions using `y_pred, y_true`.
```py
import torch
from keras_cv_attention_models.backend import models, layers
mm = models.Sequential([layers.Input([3, 32, 32]), layers.Conv2D(32, 3), layers.GlobalAveragePooling2D(), layers.Dense(10)])
if torch.cuda.is_available():
_ = mm.to("cuda")
xx = torch.rand([64, *mm.input_shape[1:]])
yy = torch.functional.F.one_hot(torch.randint(0, mm.output_shape[-1], size=[64]), mm.output_shape[-1]).float()
loss = lambda y_true, y_pred: (y_true - y_pred.float()).abs().mean()
# Will check kwargs for calling `self.train_compile` or `torch.nn.Module.compile`
mm.compile(optimizer="AdamW", loss=loss, metrics='acc', grad_accumulate=4)
mm.fit(xx, yy, epochs=2, batch_size=4)
```
## Using keras core as backend
- **[Experimental] Set os environment `export KECAM_BACKEND='keras_core'` to enable this `keras_core` backend. Not using `keras>3.0`, as still not compiling with TensorFlow==2.15.0**
- `keras-core` has its own backends, supporting tensorflow / torch / jax, by editting `~/.keras/keras.json` `"backend"` value.
- Currently most recognition models except `HaloNet` / `BotNet` supported, also `GPT2` / `LLaMA2` supported.
- **Basic model build and prediction**.
```py
!pip install sentencepiece # required for llama2 tokenizer
os.environ['KECAM_BACKEND'] = 'keras_core'
os.environ['KERAS_BACKEND'] = 'jax'
import kecam
print(f"{kecam.backend.backend() = }")
# kecam.backend.backend() = 'jax'
mm = kecam.llama2.LLaMA2_42M()
# >>>> Load pretrained from: ~/.keras/models/llama2_42m_tiny_stories.h5
mm.run_prediction('As evening fell, a maiden stood at the edge of a wood. In her hands,')
# >>>> Load tokenizer from file: ~/.keras/datasets/llama_tokenizer.model
#
# As evening fell, a maiden stood at the edge of a wood. In her hands, she held a beautiful diamond. Everyone was surprised to see it.
# "What is it?" one of the kids asked.
# "It's a diamond," the maiden said.
# ...
```
***
# Recognition Models
## AotNet
- [Keras AotNet](keras_cv_attention_models/aotnet) is just a `ResNet` / `ResNetV2` like framework, that set parameters like `attn_types` and `se_ratio` and others, which is used to apply different types attention layer. Works like `byoanet` / `byobnet` from `timm`.
- Default parameters set is a typical `ResNet` architecture with `Conv2D use_bias=False` and `padding` like `PyTorch`.
```py
from keras_cv_attention_models import aotnet
# Mixing se and outlook and halo and mhsa and cot_attention, 21M parameters.
# 50 is just a picked number that larger than the relative `num_block`.
attn_types = [None, "outlook", ["bot", "halo"] * 50, "cot"],
se_ratio = [0.25, 0, 0, 0],
model = aotnet.AotNet50V2(attn_types=attn_types, se_ratio=se_ratio, stem_type="deep", strides=1)
model.summary()
```
## BEiT
- [Keras BEiT](keras_cv_attention_models/beit) includes models from [PDF 2106.08254 BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/pdf/2106.08254.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| -------------------------- | ------- | ------- | ----- | -------- | ------------ |
| [BeitBasePatch16, 21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_base_patch16_224_imagenet21k-ft1k.h5) | 86.53M | 17.61G | 224 | 85.240 | 321.226 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_base_patch16_384_imagenet21k-ft1k.h5) | 86.74M | 55.70G | 384 | 86.808 | 164.705 qps |
| [BeitLargePatch16, 21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_large_patch16_224_imagenet21k-ft1k.h5) | 304.43M | 61.68G | 224 | 87.476 | 105.998 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_large_patch16_384_imagenet21k-ft1k.h5) | 305.00M | 191.65G | 384 | 88.382 | 45.7307 qps |
| - [21k_ft1k, 512](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_large_patch16_512_imagenet21k-ft1k.h5) | 305.67M | 363.46G | 512 | 88.584 | 21.3097 qps |
## BEiTV2
- [Keras BEiT](keras_cv_attention_models/beit) includes models from BeitV2 Paper [PDF 2208.06366 BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers](https://arxiv.org/pdf/2208.06366.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------------ | ------- | ------ | ----- | -------- | ------------ |
| BeitV2BasePatch16 | 86.53M | 17.61G | 224 | 85.5 | 322.52 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_v2_base_patch16_224_imagenet21k-ft1k.h5) | 86.53M | 17.61G | 224 | 86.5 | 322.52 qps |
| BeitV2LargePatch16 | 304.43M | 61.68G | 224 | 87.3 | 105.734 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/beit_v2_large_patch16_224_imagenet21k-ft1k.h5) | 304.43M | 61.68G | 224 | 88.4 | 105.734 qps |
## BotNet
- [Keras BotNet](keras_cv_attention_models/botnet) is for [PDF 2101.11605 Bottleneck Transformers for Visual Recognition](https://arxiv.org/pdf/2101.11605.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------- | ------ | ------ | ----- | -------- | ------------ |
| BotNet50 | 21M | 5.42G | 224 | | 746.454 qps |
| BotNet101 | 41M | 9.13G | 224 | | 448.102 qps |
| BotNet152 | 56M | 12.84G | 224 | | 316.671 qps |
| [BotNet26T](https://github.com/leondgarse/keras_cv_attention_models/releases/download/botnet/botnet26t_256_imagenet.h5) | 12.5M | 3.30G | 256 | 79.246 | 1188.84 qps |
| [BotNextECA26T](https://github.com/leondgarse/keras_cv_attention_models/releases/download/botnet/botnext_eca26t_256_imagenet.h5) | 10.59M | 2.45G | 256 | 79.270 | 1038.19 qps |
| [BotNetSE33T](https://github.com/leondgarse/keras_cv_attention_models/releases/download/botnet/botnet_se33t_256_imagenet.h5) | 13.7M | 3.89G | 256 | 81.2 | 610.429 qps |
## CAFormer
- [Keras CAFormer](keras_cv_attention_models/caformer) is for [PDF 2210.13452 MetaFormer Baselines for Vision](https://arxiv.org/pdf/2210.13452.pdf). `CAFormer` is using 2 transformer stacks, while `ConvFormer` is all conv blocks.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------------------- | ------ | ----- | ----- | -------- | ------------ |
| [CAFormerS18](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s18_224_imagenet.h5) | 26M | 4.1G | 224 | 83.6 | 399.127 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s18_384_imagenet.h5) | 26M | 13.4G | 384 | 85.0 | 181.993 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s18_224_imagenet21k-ft1k.h5) | 26M | 4.1G | 224 | 84.1 | 399.127 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s18_384_imagenet21k-ft1k.h5) | 26M | 13.4G | 384 | 85.4 | 181.993 qps |
| [CAFormerS36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s36_224_imagenet.h5) | 39M | 8.0G | 224 | 84.5 | 204.328 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s36_384_imagenet.h5) | 39M | 26.0G | 384 | 85.7 | 102.04 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s36_224_imagenet21k-ft1k.h5) | 39M | 8.0G | 224 | 85.8 | 204.328 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_s36_384_imagenet21k-ft1k.h5) | 39M | 26.0G | 384 | 86.9 | 102.04 qps |
| [CAFormerM36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_m36_224_imagenet.h5) | 56M | 13.2G | 224 | 85.2 | 162.257 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_m36_384_imagenet.h5) | 56M | 42.0G | 384 | 86.2 | 65.6188 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_m36_224_imagenet21k-ft1k.h5) | 56M | 13.2G | 224 | 86.6 | 162.257 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_m36_384_imagenet21k-ft1k.h5) | 56M | 42.0G | 384 | 87.5 | 65.6188 qps |
| [CAFormerB36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_b36_224_imagenet.h5) | 99M | 23.2G | 224 | 85.5 | 116.865 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_b36_384_imagenet.h5) | 99M | 72.2G | 384 | 86.4 | 50.0244 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_b36_224_imagenet21k-ft1k.h5) | 99M | 23.2G | 224 | 87.4 | 116.865 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/caformer_b36_384_imagenet21k-ft1k.h5) | 99M | 72.2G | 384 | 88.1 | 50.0244 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------------------- | ------ | ----- | ----- | -------- | ------------ |
| [ConvFormerS18](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s18_224_imagenet.h5) | 27M | 3.9G | 224 | 83.0 | 295.114 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s18_384_imagenet.h5) | 27M | 11.6G | 384 | 84.4 | 145.923 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s18_224_imagenet21k-ft1k.h5) | 27M | 3.9G | 224 | 83.7 | 295.114 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s36_384_imagenet21k-ft1k.h5) | 27M | 11.6G | 384 | 85.0 | 145.923 qps |
| [ConvFormerS36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s36_224_imagenet.h5) | 40M | 7.6G | 224 | 84.1 | 161.609 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s36_384_imagenet.h5) | 40M | 22.4G | 384 | 85.4 | 80.2101 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s36_224_imagenet21k-ft1k.h5) | 40M | 7.6G | 224 | 85.4 | 161.609 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_s36_384_imagenet21k-ft1k.h5) | 40M | 22.4G | 384 | 86.4 | 80.2101 qps |
| [ConvFormerM36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_m36_224_imagenet.h5) | 57M | 12.8G | 224 | 84.5 | 130.161 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_m36_384_imagenet.h5) | 57M | 37.7G | 384 | 85.6 | 63.9712 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_m36_224_imagenet21k-ft1k.h5) | 57M | 12.8G | 224 | 86.1 | 130.161 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_m36_384_imagenet21k-ft1k.h5) | 57M | 37.7G | 384 | 86.9 | 63.9712 qps |
| [ConvFormerB36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_b36_224_imagenet.h5) | 100M | 22.6G | 224 | 84.8 | 98.0751 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_b36_384_imagenet.h5) | 100M | 66.5G | 384 | 85.7 | 48.5897 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_b36_224_imagenet21k-ft1k.h5) | 100M | 22.6G | 224 | 87.0 | 98.0751 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/caformer/convformer_b36_384_imagenet21k-ft1k.h5) | 100M | 66.5G | 384 | 87.6 | 48.5897 qps |
## CMT
- [Keras CMT](keras_cv_attention_models/cmt) is for [PDF 2107.06263 CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/pdf/2107.06263.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ---------------------------------- | ------ | ----- | ----- | -------- | ------------ |
| CMTTiny, (Self trained 105 epochs) | 9.5M | 0.65G | 160 | 77.4 | 315.566 qps |
| - [(305 epochs)](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cmt/cmt_tiny_160_imagenet.h5) | 9.5M | 0.65G | 160 | 78.94 | 315.566 qps |
| - [224, (fine-tuned 69 epochs)](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cmt/cmt_tiny_224_imagenet.h5) | 9.5M | 1.32G | 224 | 80.73 | 254.87 qps |
| [CMTTiny_torch, (1000 epochs)](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cmt/cmt_tiny_torch_160_imagenet.h5) | 9.5M | 0.65G | 160 | 79.2 | 338.207 qps |
| [CMTXS_torch](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cmt/cmt_xs_torch_192_imagenet.h5) | 15.2M | 1.58G | 192 | 81.8 | 241.288 qps |
| [CMTSmall_torch](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cmt/cmt_small_torch_224_imagenet.h5) | 25.1M | 4.09G | 224 | 83.5 | 171.109 qps |
| [CMTBase_torch](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cmt/cmt_base_torch_256_imagenet.h5) | 45.7M | 9.42G | 256 | 84.5 | 103.34 qps |
## CoaT
- [Keras CoaT](keras_cv_attention_models/coat) is for [PDF 2104.06399 CoaT: Co-Scale Conv-Attentional Image Transformers](http://arxiv.org/abs/2104.06399).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------- | ------ | ----- | ----- | -------- | ------------ |
| [CoaTLiteTiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coat/coat_lite_tiny_imagenet.h5) | 5.7M | 1.60G | 224 | 77.5 | 450.27 qps |
| [CoaTLiteMini](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coat/coat_lite_mini_imagenet.h5) | 11M | 2.00G | 224 | 79.1 | 452.884 qps |
| [CoaTLiteSmall](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coat/coat_lite_small_imagenet.h5) | 20M | 3.97G | 224 | 81.9 | 248.846 qps |
| [CoaTTiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coat/coat_tiny_imagenet.h5) | 5.5M | 4.33G | 224 | 78.3 | 152.495 qps |
| [CoaTMini](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coat/coat_mini_imagenet.h5) | 10M | 6.78G | 224 | 81.0 | 124.845 qps |
## CoAtNet
- [Keras CoAtNet](keras_cv_attention_models/coatnet) is for [PDF 2106.04803 CoAtNet: Marrying Convolution and Attention for All Data Sizes](https://arxiv.org/pdf/2106.04803.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------------------------------- | ------ | ------ | ----- | -------- | ------------ |
| [CoAtNet0, 160, (105 epochs)](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coatnet/coatnet0_160_imagenet.h5) | 23.3M | 2.09G | 160 | 80.48 | 584.059 qps |
| [CoAtNet0, (305 epochs)](https://github.com/leondgarse/keras_cv_attention_models/releases/download/coatnet/coatnet0_224_imagenet.h5) | 23.8M | 4.22G | 224 | 82.79 | 400.333 qps |
| CoAtNet0 | 25M | 4.6G | 224 | 82.0 | 400.333 qps |
| - use_dw_strides=False | 25M | 4.2G | 224 | 81.6 | 461.197 qps |
| CoAtNet1 | 42M | 8.8G | 224 | 83.5 | 206.954 qps |
| - use_dw_strides=False | 42M | 8.4G | 224 | 83.3 | 228.938 qps |
| CoAtNet2 | 75M | 16.6G | 224 | 84.1 | 156.359 qps |
| - use_dw_strides=False | 75M | 15.7G | 224 | 84.1 | 165.846 qps |
| CoAtNet2, 21k_ft1k | 75M | 16.6G | 224 | 87.1 | 156.359 qps |
| CoAtNet3 | 168M | 34.7G | 224 | 84.5 | 95.0703 qps |
| CoAtNet3, 21k_ft1k | 168M | 34.7G | 224 | 87.6 | 95.0703 qps |
| CoAtNet3, 21k_ft1k | 168M | 203.1G | 512 | 87.9 | 95.0703 qps |
| CoAtNet4, 21k_ft1k | 275M | 360.9G | 512 | 88.1 | 74.6022 qps |
| CoAtNet4, 21k_ft1k, PT-RA-E150 | 275M | 360.9G | 512 | 88.56 | 74.6022 qps |
## ConvNeXt
- [Keras ConvNeXt](keras_cv_attention_models/convnext) is for [PDF 2201.03545 A ConvNet for the 2020s](https://arxiv.org/pdf/2201.03545.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------------------- | ------ | ------- | ----- | -------- | ------------ |
| [ConvNeXtTiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_tiny_imagenet.h5) | 28M | 4.49G | 224 | 82.1 | 361.58 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_tiny_224_imagenet21k-ft1k.h5) | 28M | 4.49G | 224 | 82.9 | 361.58 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_tiny_384_imagenet21k-ft1k.h5) | 28M | 13.19G | 384 | 84.1 | 182.134 qps |
| [ConvNeXtSmall](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_small_imagenet.h5) | 50M | 8.73G | 224 | 83.1 | 202.007 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_small_224_imagenet21k-ft1k.h5) | 50M | 8.73G | 224 | 84.6 | 202.007 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_small_384_imagenet21k-ft1k.h5) | 50M | 25.67G | 384 | 85.8 | 108.125 qps |
| [ConvNeXtBase](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_base_224_imagenet.h5) | 89M | 15.42G | 224 | 83.8 | 160.036 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_base_384_imagenet.h5) | 89M | 45.32G | 384 | 85.1 | 83.3095 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_base_224_imagenet21k-ft1k.h5) | 89M | 15.42G | 224 | 85.8 | 160.036 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_base_384_imagenet21k-ft1k.h5) | 89M | 45.32G | 384 | 86.8 | 83.3095 qps |
| [ConvNeXtLarge](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_large_224_imagenet.h5) | 198M | 34.46G | 224 | 84.3 | 102.27 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_large_384_imagenet.h5) | 198M | 101.28G | 384 | 85.5 | 47.2086 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_large_224_imagenet21k-ft1k.h5) | 198M | 34.46G | 224 | 86.6 | 102.27 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_large_384_imagenet21k-ft1k.h5) | 198M | 101.28G | 384 | 87.5 | 47.2086 qps |
| [ConvNeXtXlarge, 21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_xlarge_224_imagenet21k-ft1k.h5) | 350M | 61.06G | 224 | 87.0 | 40.5776 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_xlarge_384_imagenet21k-ft1k.h5) | 350M | 179.43G | 384 | 87.8 | 21.797 qps |
| [ConvNeXtXXLarge, clip](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_xxlarge_clip-ft1k.h5) | 846M | 198.09G | 256 | 88.6 | |
## ConvNeXtV2
- [Keras ConvNeXt](keras_cv_attention_models/convnext) includes implementation of [PDF 2301.00808 ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/pdf/2301.00808.pdf). **Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only**.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------------------- | ------ | ------ | ----- | -------- | ------------ |
| [ConvNeXtV2Atto](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_atto_imagenet.h5) | 3.7M | 0.55G | 224 | 76.7 | 705.822 qps |
| [ConvNeXtV2Femto](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_femto_imagenet.h5) | 5.2M | 0.78G | 224 | 78.5 | 728.02 qps |
| [ConvNeXtV2Pico](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_pico_imagenet.h5) | 9.1M | 1.37G | 224 | 80.3 | 591.502 qps |
| [ConvNeXtV2Nano](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_nano_imagenet.h5) | 15.6M | 2.45G | 224 | 81.9 | 471.918 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_nano_224_imagenet21k-ft1k.h5) | 15.6M | 2.45G | 224 | 82.1 | 471.918 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_nano_384_imagenet21k-ft1k.h5) | 15.6M | 7.21G | 384 | 83.4 | 213.802 qps |
| [ConvNeXtV2Tiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_tiny_imagenet.h5) | 28.6M | 4.47G | 224 | 83.0 | 301.982 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_tiny_224_imagenet21k-ft1k.h5) | 28.6M | 4.47G | 224 | 83.9 | 301.982 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_tiny_384_imagenet21k-ft1k.h5) | 28.6M | 13.1G | 384 | 85.1 | 139.578 qps |
| [ConvNeXtV2Base](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_base_imagenet.h5) | 89M | 15.4G | 224 | 84.9 | 132.575 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_base_224_imagenet21k-ft1k.h5) | 89M | 15.4G | 224 | 86.8 | 132.575 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_base_384_imagenet21k-ft1k.h5) | 89M | 45.2G | 384 | 87.7 | 66.5729 qps |
| [ConvNeXtV2Large](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_large_imagenet.h5) | 198M | 34.4G | 224 | 85.8 | 86.8846 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_large_224_imagenet21k-ft1k.h5) | 198M | 34.4G | 224 | 87.3 | 86.8846 qps |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_large_384_imagenet21k-ft1k.h5) | 198M | 101.1G | 384 | 88.2 | 24.4542 qps |
| [ConvNeXtV2Huge](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_huge_imagenet.h5) | 660M | 115G | 224 | 86.3 | |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_huge_384_imagenet21k-ft1k.h5) | 660M | 337.9G | 384 | 88.7 | |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/convnext/convnext_v2_huge_512_imagenet21k-ft1k.h5) | 660M | 600.8G | 512 | 88.9 | |
## CoTNet
- [Keras CoTNet](keras_cv_attention_models/cotnet) is for [PDF 2107.12292 Contextual Transformer Networks for Visual Recognition](https://arxiv.org/pdf/2107.12292.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------ |:------:| ------ | ----- |:--------:| ------------ |
| [CotNet50](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cotnet/cotnet50_224_imagenet.h5) | 22.2M | 3.25G | 224 | 81.3 | 324.913 qps |
| [CotNetSE50D](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cotnet/cotnet_se50d_224_imagenet.h5) | 23.1M | 4.05G | 224 | 81.6 | 513.077 qps |
| [CotNet101](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cotnet/cotnet101_224_imagenet.h5) | 38.3M | 6.07G | 224 | 82.8 | 183.824 qps |
| [CotNetSE101D](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cotnet/cotnet_se101d_224_imagenet.h5) | 40.9M | 8.44G | 224 | 83.2 | 251.487 qps |
| [CotNetSE152D](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cotnet/cotnet_se152d_224_imagenet.h5) | 55.8M | 12.22G | 224 | 84.0 | 175.469 qps |
| [CotNetSE152D](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cotnet/cotnet_se152d_320_imagenet.h5) | 55.8M | 24.92G | 320 | 84.6 | 175.469 qps |
## CSPNeXt
- [Keras CSPNeXt](keras_cv_attention_models/cspnext) is for backbone of [PDF 2212.07784 RTMDet: An Empirical Study of Designing Real-Time Object Detectors](https://arxiv.org/abs/2212.07784).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------- | ------ | ----- | ----- | -------- | -------- |
| [CSPNeXtTiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cspnext/cspnext_tiny_imagenet.h5) | 2.73M | 0.34G | 224 | 69.44 | |
| [CSPNeXtSmall](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cspnext/cspnext_small_imagenet.h5) | 4.89M | 0.66G | 224 | 74.41 | |
| [CSPNeXtMedium](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cspnext/cspnext_medium_imagenet.h5) | 13.05M | 1.92G | 224 | 79.27 | |
| [CSPNeXtLarge](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cspnext/cspnext_large_imagenet.h5) | 27.16M | 4.19G | 224 | 81.30 | |
| [CSPNeXtXLarge](https://github.com/leondgarse/keras_cv_attention_models/releases/download/cspnext/cspnext_xlarge_imagenet.h5) | 48.85M | 7.75G | 224 | 82.10 | |
## DaViT
- [Keras DaViT](keras_cv_attention_models/davit) is for [PDF 2204.03645 DaViT: Dual Attention Vision Transformers](https://arxiv.org/pdf/2204.03645.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------------ | ------ | ------ | ----- | -------- | ------------ |
| [DaViT_T](https://github.com/leondgarse/keras_cv_attention_models/releases/download/davit/davit_t_imagenet.h5) | 28.36M | 4.56G | 224 | 82.8 | 224.563 qps |
| [DaViT_S](https://github.com/leondgarse/keras_cv_attention_models/releases/download/davit/davit_s_imagenet.h5) | 49.75M | 8.83G | 224 | 84.2 | 145.838 qps |
| [DaViT_B](https://github.com/leondgarse/keras_cv_attention_models/releases/download/davit/davit_b_imagenet.h5) | 87.95M | 15.55G | 224 | 84.6 | 114.527 qps |
| DaViT_L, 21k_ft1k | 196.8M | 103.2G | 384 | 87.5 | 34.7015 qps |
| DaViT_H, 1.5B | 348.9M | 327.3G | 512 | 90.2 | 12.363 qps |
| DaViT_G, 1.5B | 1.406B | 1.022T | 512 | 90.4 | |
## DiNAT
- [Keras DiNAT](keras_cv_attention_models/nat) is for [PDF 2209.15001 Dilated Neighborhood Attention Transformer](https://arxiv.org/pdf/2209.15001.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------------------- | ------ | ------ | ----- | -------- | ------------ |
| [DiNAT_Mini](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_mini_imagenet.h5) | 20.0M | 2.73G | 224 | 81.8 | 83.9943 qps |
| [DiNAT_Tiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_tiny_imagenet.h5) | 27.9M | 4.34G | 224 | 82.7 | 61.1902 qps |
| [DiNAT_Small](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_small_imagenet.h5) | 50.7M | 7.84G | 224 | 83.8 | 41.0343 qps |
| [DiNAT_Base](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_base_imagenet.h5) | 89.8M | 13.76G | 224 | 84.4 | 30.1332 qps |
| [DiNAT_Large, 21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_large_224_imagenet21k-ft1k.h5) | 200.9M | 30.58G | 224 | 86.6 | 18.4936 qps |
| - [21k, (num_classes=21841)](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_large_imagenet21k.h5) | 200.9M | 30.58G | 224 | | |
| - [21k_ft1k, 384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_large_384_imagenet21k-ft1k.h5) | 200.9M | 89.86G | 384 | 87.4 | |
| [DiNAT_Large_K11, 21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/nat/dinat_large_k11_imagenet21k-ft1k.h5) | 201.1M | 92.57G | 384 | 87.5 | |
## DINOv2
- [Keras DINOv2](keras_cv_attention_models/beit) includes models from [PDF 2304.07193 DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/pdf/2304.07193.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------------ | ------- | ------- | ----- | -------- | ------------ |
| [DINOv2_ViT_Small14](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/dinov2_vit_small14_518_imagenet.h5) | 22.83M | 47.23G | 518 | 81.1 | 165.271 qps |
| [DINOv2_ViT_Base14](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/dinov2_vit_base14_518_imagenet.h5) | 88.12M | 152.6G | 518 | 84.5 | 54.9769 qps |
| [DINOv2_ViT_Large14](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/dinov2_vit_large14_518_imagenet.h5) | 306.4M | 509.6G | 518 | 86.3 | 17.4108 qps |
| [DINOv2_ViT_Giant14](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/dinov2_vit_giant14_518_imagenet.h5) | 1139.6M | 1790.3G | 518 | 86.5 | |
## EdgeNeXt
- [Keras EdgeNeXt](keras_cv_attention_models/edgenext) is for [PDF 2206.10589 EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications](https://arxiv.org/pdf/2206.10589.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------------- | ------ | ------ | ----- | -------- | ------------ |
| [EdgeNeXt_XX_Small](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_xx_small_256_imagenet.h5) | 1.33M | 266M | 256 | 71.23 | 902.957 qps |
| [EdgeNeXt_X_Small](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_x_small_256_imagenet.h5) | 2.34M | 547M | 256 | 74.96 | 638.346 qps |
| [EdgeNeXt_Small](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_small_256_imagenet.h5) | 5.59M | 1.27G | 256 | 79.41 | 536.762 qps |
| - [usi](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_small_256_usi.h5) | 5.59M | 1.27G | 256 | 81.07 | 536.762 qps |
| [EdgeNeXt_Base](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_base_256_imagenet.h5) | 18.5M | 3.86G | 256 | 82.47 | 383.461 qps |
| - [usi](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_base_256_usi.h5) | 18.5M | 3.86G | 256 | 83.31 | 383.461 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/edgenext/edgenext_base_256_imagenet-ft1k.h5) | 18.5M | 3.86G | 256 | 83.68 | 383.461 qps |
## EfficientFormer
- [Keras EfficientFormer](keras_cv_attention_models/efficientformer) is for [PDF 2206.01191 EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/pdf/2206.01191.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| -------------------------- | ------ | ----- | ----- | -------- | ------------ |
| [EfficientFormerL1, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/levit/efficientformer_l1_224_imagenet.h5) | 12.3M | 1.31G | 224 | 79.2 | 1214.22 qps |
| [EfficientFormerL3, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/levit/efficientformer_l3_224_imagenet.h5) | 31.4M | 3.95G | 224 | 82.4 | 596.705 qps |
| [EfficientFormerL7, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/levit/efficientformer_l7_224_imagenet.h5) | 74.4M | 9.79G | 224 | 83.3 | 298.434 qps |
## EfficientFormerV2
- [Keras EfficientFormer](keras_cv_attention_models/efficientformer) includes implementation of [PDF 2212.08059 Rethinking Vision Transformers for MobileNet Size and Speed](https://arxiv.org/pdf/2212.08059.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ---------------------------- | ------ | ------ | ----- | -------- | ------------ |
| [EfficientFormerV2S0, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientformer/efficientformer_v2_s0_224_imagenet.h5) | 3.60M | 405.2M | 224 | 76.2 | 1114.38 qps |
| [EfficientFormerV2S1, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientformer/efficientformer_v2_s1_224_imagenet.h5) | 6.19M | 665.6M | 224 | 79.7 | 841.186 qps |
| [EfficientFormerV2S2, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientformer/efficientformer_v2_s2_224_imagenet.h5) | 12.7M | 1.27G | 224 | 82.0 | 573.9 qps |
| [EfficientFormerV2L, distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientformer/efficientformer_v2_l_224_imagenet.h5) | 26.3M | 2.59G | 224 | 83.5 | 377.224 qps |
## EfficientNet
- [Keras EfficientNet](keras_cv_attention_models/efficientnet) includes implementation of [PDF 1911.04252 Self-training with Noisy Student improves ImageNet classification](https://arxiv.org/pdf/1911.04252.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------------------------ | ------ | ------- | ----- | -------- | ------------ |
| [EfficientNetV1B0](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b0-imagenet.h5) | 5.3M | 0.39G | 224 | 77.6 | 1129.93 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b0-noisy_student.h5) | 5.3M | 0.39G | 224 | 78.8 | 1129.93 qps |
| [EfficientNetV1B1](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b1-imagenet.h5) | 7.8M | 0.70G | 240 | 79.6 | 758.639 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b1-noisy_student.h5) | 7.8M | 0.70G | 240 | 81.5 | 758.639 qps |
| [EfficientNetV1B2](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b2-imagenet.h5) | 9.1M | 1.01G | 260 | 80.5 | 668.959 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b2-noisy_student.h5) | 9.1M | 1.01G | 260 | 82.4 | 668.959 qps |
| [EfficientNetV1B3](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b3-imagenet.h5) | 12.2M | 1.86G | 300 | 81.9 | 473.607 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b3-noisy_student.h5) | 12.2M | 1.86G | 300 | 84.1 | 473.607 qps |
| [EfficientNetV1B4](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b4-imagenet.h5) | 19.3M | 4.46G | 380 | 83.3 | 265.244 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b4-noisy_student.h5) | 19.3M | 4.46G | 380 | 85.3 | 265.244 qps |
| [EfficientNetV1B5](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b5-imagenet.h5) | 30.4M | 10.40G | 456 | 84.3 | 146.758 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b5-noisy_student.h5) | 30.4M | 10.40G | 456 | 86.1 | 146.758 qps |
| [EfficientNetV1B6](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b6-imagenet.h5) | 43.0M | 19.29G | 528 | 84.8 | 88.0369 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b6-noisy_student.h5) | 43.0M | 19.29G | 528 | 86.4 | 88.0369 qps |
| [EfficientNetV1B7](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b7-imagenet.h5) | 66.3M | 38.13G | 600 | 85.2 | 52.6616 qps |
| - [NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-b7-noisy_student.h5) | 66.3M | 38.13G | 600 | 86.9 | 52.6616 qps |
| [EfficientNetV1L2, NoisyStudent](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetv1-l2-noisy_student.h5) | 480.3M | 477.98G | 800 | 88.4 | |
## EfficientNetEdgeTPU
- [Keras EfficientNetEdgeTPU](keras_cv_attention_models/efficientnet) includes implementation of [PDF 1911.04252 Self-training with Noisy Student improves ImageNet classification](https://arxiv.org/pdf/1911.04252.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------------------------ | ------ | ------- | ----- | -------- | ------------ |
| [EfficientNetEdgeTPUSmall](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetedgetpu-small-imagenet.h5) | 5.49M | 1.79G | 224 | 78.07 | 1459.38 qps |
| [EfficientNetEdgeTPUMedium](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetedgetpu-medium-imagenet.h5) | 6.90M | 3.01G | 240 | 79.25 | 1028.95 qps |
| [EfficientNetEdgeTPULarge](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv1_pretrained/efficientnetedgetpu-large-imagenet.h5) | 10.59M | 7.94G | 300 | 81.32 | 527.034 qps |
## EfficientNetV2
- [Keras EfficientNet](keras_cv_attention_models/efficientnet) includes implementation of [PDF 2104.00298 EfficientNetV2: Smaller Models and Faster Training](https://arxiv.org/abs/2104.00298).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| -------------------------- | ------ | ------ | ----- | -------- | ------------ |
| [EfficientNetV2B0](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b0-imagenet.h5) | 7.1M | 0.72G | 224 | 78.7 | 1109.84 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b0-21k-ft1k.h5) | 7.1M | 0.72G | 224 | 77.55? | 1109.84 qps |
| [EfficientNetV2B1](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b1-imagenet.h5) | 8.1M | 1.21G | 240 | 79.8 | 842.372 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b1-21k-ft1k.h5) | 8.1M | 1.21G | 240 | 79.03? | 842.372 qps |
| [EfficientNetV2B2](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b2-imagenet.h5) | 10.1M | 1.71G | 260 | 80.5 | 762.865 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b2-21k-ft1k.h5) | 10.1M | 1.71G | 260 | 79.48? | 762.865 qps |
| [EfficientNetV2B3](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b3-imagenet.h5) | 14.4M | 3.03G | 300 | 82.1 | 548.501 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-b3-21k-ft1k.h5) | 14.4M | 3.03G | 300 | 82.46? | 548.501 qps |
| [EfficientNetV2T](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-t-imagenet.h5) | 13.6M | 3.18G | 288 | 82.34 | 496.483 qps |
| [EfficientNetV2T_GC](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-t-gc-imagenet.h5) | 13.7M | 3.19G | 288 | 82.46 | 368.763 qps |
| [EfficientNetV2S](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-s-imagenet.h5) | 21.5M | 8.41G | 384 | 83.9 | 344.109 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-s-21k-ft1k.h5) | 21.5M | 8.41G | 384 | 84.9 | 344.109 qps |
| [EfficientNetV2M](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-m-imagenet.h5) | 54.1M | 24.69G | 480 | 85.2 | 145.346 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-m-21k-ft1k.h5) | 54.1M | 24.69G | 480 | 86.2 | 145.346 qps |
| [EfficientNetV2L](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-l-imagenet.h5) | 119.5M | 56.27G | 480 | 85.7 | 85.6514 qps |
| - [21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-l-21k-ft1k.h5) | 119.5M | 56.27G | 480 | 86.9 | 85.6514 qps |
| [EfficientNetV2XL, 21k_ft1k](https://github.com/leondgarse/keras_efficientnet_v2/releases/download/effnetv2_pretrained/efficientnetv2-xl-21k-ft1k.h5) | 206.8M | 93.66G | 512 | 87.2 | 55.141 qps |
## EfficientViT_B
- [Keras EfficientViT_B](keras_cv_attention_models/efficientvit) is for Paper [PDF 2205.14756 EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation](https://arxiv.org/pdf/2205.14756.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| --------------- | ------ | ----- | ----- | -------- | ------------ |
| [EfficientViT_B0](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b0_224_imagenet.h5) | 3.41M | 0.12G | 224 | 71.6 ? | 1581.76 qps |
| [EfficientViT_B1](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b1_224_imagenet.h5) | 9.10M | 0.58G | 224 | 79.4 | 943.587 qps |
| - [256](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b1_256_imagenet.h5) | 9.10M | 0.78G | 256 | 79.9 | 840.844 qps |
| - [288](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b1_288_imagenet.h5) | 9.10M | 1.03G | 288 | 80.4 | 680.088 qps |
| [EfficientViT_B2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b2_224_imagenet.h5) | 24.33M | 1.68G | 224 | 82.1 | 583.295 qps |
| - [256](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b2_256_imagenet.h5) | 24.33M | 2.25G | 256 | 82.7 | 507.187 qps |
| - [288](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b2_288_imagenet.h5) | 24.33M | 2.92G | 288 | 83.1 | 419.93 qps |
| [EfficientViT_B3](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b3_224_imagenet.h5) | 48.65M | 4.14G | 224 | 83.5 | 329.764 qps |
| - [256](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b3_256_imagenet.h5) | 48.65M | 5.51G | 256 | 83.8 | 288.605 qps |
| - [288](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_b3_288_imagenet.h5) | 48.65M | 7.14G | 288 | 84.2 | 229.992 qps |
| [EfficientViT_L1](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_l1_224_imagenet.h5) | 52.65M | 5.28G | 224 | 84.48 | 503.068 qps |
| [EfficientViT_L2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_l2_224_imagenet.h5) | 63.71M | 6.98G | 224 | 85.05 | 396.255 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_l2_384_imagenet.h5) | 63.71M | 20.7G | 384 | 85.98 | 207.322 qps |
| [EfficientViT_L3](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_l3_224_imagenet.h5) | 246.0M | 27.6G | 224 | 85.814 | 174.926 qps |
| - [384](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_l3_384_imagenet.h5) | 246.0M | 81.6G | 384 | 86.408 | 86.895 qps |
## EfficientViT_M
- [Keras EfficientViT_M](keras_cv_attention_models/efficientvit) is for Paper [PDF 2305.07027 EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention](https://arxiv.org/pdf/2305.07027.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| --------------- | ------ | ----- | ----- | -------- | ------------ |
| [EfficientViT_M0](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_m0_224_imagenet.h5) | 2.35M | 79.4M | 224 | 63.2 | 814.522 qps |
| [EfficientViT_M1](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_m1_224_imagenet.h5) | 2.98M | 167M | 224 | 68.4 | 948.041 qps |
| [EfficientViT_M2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_m2_224_imagenet.h5) | 4.19M | 201M | 224 | 70.8 | 906.286 qps |
| [EfficientViT_M3](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_m3_224_imagenet.h5) | 6.90M | 263M | 224 | 73.4 | 758.086 qps |
| [EfficientViT_M4](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_m4_224_imagenet.h5) | 8.80M | 299M | 224 | 74.3 | 672.891 qps |
| [EfficientViT_M5](https://github.com/leondgarse/keras_cv_attention_models/releases/download/efficientvit/efficientvit_m5_224_imagenet.h5) | 12.47M | 522M | 224 | 77.1 | 577.254 qps |
## EVA
- [Keras EVA](keras_cv_attention_models/beit) includes models from [PDF 2211.07636 EVA: Exploring the Limits of Masked Visual Representation Learning at Scale](https://arxiv.org/pdf/2211.07636.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| --------------------- | ------- | -------- | ----- | -------- | ------------ |
| [EvaLargePatch14, 21k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva_large_patch14_196_imagenet21k-ft1k.h5) | 304.14M | 61.65G | 196 | 88.59 | 115.532 qps |
| - [21k_ft1k, 336](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva_large_patch14_336_imagenet21k-ft1k.h5) | 304.53M | 191.55G | 336 | 89.20 | 53.3467 qps |
| [EvaGiantPatch14, clip](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva_giant_patch14_224_imagenet21k-ft1k.h5) | 1012.6M | 267.40G | 224 | 89.10 | |
| - [m30m](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva_giant_patch14_336_imagenet21k-ft1k.h5) | 1013.0M | 621.45G | 336 | 89.57 | |
| - [m30m](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva_giant_patch14_560_imagenet21k-ft1k.h5) | 1014.4M | 1911.61G | 560 | 89.80 | |
## EVA02
- [Keras EVA02](keras_cv_attention_models/beit) includes models from [PDF 2303.11331 EVA: EVA-02: A Visual Representation for Neon Genesis](https://arxiv.org/pdf/2303.11331.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| -------------------------------------- | ------- | ------- | ----- | -------- | ------------ |
| [EVA02TinyPatch14, mim_in22k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva02_tiny_patch14_336_mim_in22k_ft1k.h5) | 5.76M | 4.72G | 336 | 80.658 | 320.123 qps |
| [EVA02SmallPatch14, mim_in22k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva02_small_patch14_336_mim_in22k_ft1k.h5) | 22.13M | 15.57G | 336 | 85.74 | 161.774 qps |
| [EVA02BasePatch14, mim_in22k_ft22k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva02_base_patch14_448_mim_in22k_ft22k_ft1k.h5) | 87.12M | 107.6G | 448 | 88.692 | 34.3962 qps |
| [EVA02LargePatch14, mim_m38m_ft22k_ft1k](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/eva02_large_patch14_448_mim_m38m_ft22k_ft1k.h5) | 305.08M | 363.68G | 448 | 90.054 | |
## FasterNet
- [Keras FasterNet](keras_cv_attention_models/fasternet) includes implementation of [PDF 2303.03667 Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks ](https://arxiv.org/pdf/2303.03667.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ----------- | ------ | ------ | ----- | -------- | ------------ |
| [FasterNetT0](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fasternet/fasternet_t0_imagenet.h5) | 3.9M | 0.34G | 224 | 71.9 | 1890.83 qps |
| [FasterNetT1](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fasternet/fasternet_t1_imagenet.h5) | 7.6M | 0.85G | 224 | 76.2 | 1788.16 qps |
| [FasterNetT2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fasternet/fasternet_t2_imagenet.h5) | 15.0M | 1.90G | 224 | 78.9 | 1353.12 qps |
| [FasterNetS](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fasternet/fasternet_s_imagenet.h5) | 31.1M | 4.55G | 224 | 81.3 | 818.814 qps |
| [FasterNetM](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fasternet/fasternet_m_imagenet.h5) | 53.5M | 8.72G | 224 | 83.0 | 436.383 qps |
| [FasterNetL](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fasternet/fasternet_l_imagenet.h5) | 93.4M | 15.49G | 224 | 83.5 | 319.809 qps |
## FasterViT
- [Keras FasterViT](keras_cv_attention_models/fastervit) includes implementation of [PDF 2306.06189 FasterViT: Fast Vision Transformers with Hierarchical Attention](https://arxiv.org/pdf/2306.06189.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ---------- | -------- | ------- | ----- | -------- | ------------ |
| [FasterViT0](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_0_224_imagenet.h5) | 31.40M | 3.51G | 224 | 82.1 | 716.809 qps |
| [FasterViT1](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_1_224_imagenet.h5) | 53.37M | 5.52G | 224 | 83.2 | 491.971 qps |
| [FasterViT2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_2_224_imagenet.h5) | 75.92M | 9.00G | 224 | 84.2 | 377.006 qps |
| [FasterViT3](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_3_224_imagenet.h5) | 159.55M | 18.75G | 224 | 84.9 | 216.481 qps |
| [FasterViT4](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_4_224_imagenet.h5) | 351.12M | 41.57G | 224 | 85.4 | 71.6303 qps |
| [FasterViT5](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_5_224_imagenet.h5) | 957.52M | 114.08G | 224 | 85.6 | |
| [FasterViT6](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_6_224_imagenet.1.h5), [+.2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastervit/fastervit_6_224_imagenet.2.h5) | 1360.33M | 144.13G | 224 | 85.8 | |
## FastViT
- [Keras FastViT](keras_cv_attention_models/fastvit) includes implementation of [PDF 2303.14189 FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization](https://arxiv.org/pdf/2303.14189.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------- | ------ | ----- | ----- | -------- | ------------ |
| [FastViT_T8](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_t8_imagenet.h5) | 4.03M | 0.65G | 256 | 76.2 | 1020.29 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_t8_distill.h5) | 4.03M | 0.65G | 256 | 77.2 | 1020.29 qps |
| - deploy=True | 3.99M | 0.64G | 256 | 76.2 | 1323.14 qps |
| [FastViT_T12](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_t12_imagenet.h5) | 7.55M | 1.34G | 256 | 79.3 | 734.867 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_t12_distill.h5) | 7.55M | 1.34G | 256 | 80.3 | 734.867 qps |
| - deploy=True | 7.50M | 1.33G | 256 | 79.3 | 956.332 qps |
| [FastViT_S12](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_s12_imagenet.h5) | 9.47M | 1.74G | 256 | 79.9 | 666.669 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_s12_distill.h5) | 9.47M | 1.74G | 256 | 81.1 | 666.669 qps |
| - deploy=True | 9.42M | 1.74G | 256 | 79.9 | 881.429 qps |
| [FastViT_SA12](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_sa12_imagenet.h5) | 11.58M | 1.88G | 256 | 80.9 | 656.95 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_sa12_distill.h5) | 11.58M | 1.88G | 256 | 81.9 | 656.95 qps |
| - deploy=True | 11.54M | 1.88G | 256 | 80.9 | 833.011 qps |
| [FastViT_SA24](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_sa24_imagenet.h5) | 21.55M | 3.66G | 256 | 82.7 | 371.84 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_sa24_distill.h5) | 21.55M | 3.66G | 256 | 83.4 | 371.84 qps |
| - deploy=True | 21.49M | 3.66G | 256 | 82.7 | 444.055 qps |
| [FastViT_SA36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_sa36_imagenet.h5) | 31.53M | 5.44G | 256 | 83.6 | 267.986 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_sa36_distill.h5) | 31.53M | 5.44G | 256 | 84.2 | 267.986 qps |
| - deploy=True | 31.44M | 5.43G | 256 | 83.6 | 325.967 qps |
| [FastViT_MA36](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_ma36_imagenet.h5) | 44.07M | 7.64G | 256 | 83.9 | 211.928 qps |
| - [distill](https://github.com/leondgarse/keras_cv_attention_models/releases/download/fastvit/fastvit_ma36_distill.h5) | 44.07M | 7.64G | 256 | 84.6 | 211.928 qps |
| - deploy=True | 43.96M | 7.63G | 256 | 83.9 | 274.559 qps |
## FBNetV3
- [Keras FBNetV3](keras_cv_attention_models/mobilenetv3_family#fbnetv3) includes implementation of [PDF 2006.02049 FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining](https://arxiv.org/pdf/2006.02049.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| -------- | ------ | -------- | ----- | -------- | ------------ |
| [FBNetV3B](https://github.com/leondgarse/keras_cv_attention_models/releases/download/mobilenetv3_family/fbnetv3_b_imagenet.h5) | 5.57M | 539.82M | 256 | 79.15 | 713.882 qps |
| [FBNetV3D](https://github.com/leondgarse/keras_cv_attention_models/releases/download/mobilenetv3_family/fbnetv3_d_imagenet.h5) | 10.31M | 665.02M | 256 | 79.68 | 635.963 qps |
| [FBNetV3G](https://github.com/leondgarse/keras_cv_attention_models/releases/download/mobilenetv3_family/fbnetv3_g_imagenet.h5) | 16.62M | 1379.30M | 256 | 82.05 | 478.835 qps |
## FlexiViT
- [Keras FlexiViT](keras_cv_attention_models/beit) includes models from [PDF 2212.08013 FlexiViT: One Model for All Patch Sizes](https://arxiv.org/pdf/2212.08013.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
| ------------- | ------- | ------ | ----- | -------- | ------------ |
| [FlexiViTSmall](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/flexivit_small_240_imagenet.h5) | 22.06M | 5.36G | 240 | 82.53 | 744.578 qps |
| [FlexiViTBase](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/flexivit_base_240_imagenet.h5) | 86.59M | 20.33G | 240 | 84.66 | 301.948 qps |
| [FlexiViTLarge](https://github.com/leondgarse/keras_cv_attention_models/releases/download/beit/flexivit_large_240_imagenet.h5) | 304.47M | 71.09G | 240 | 85.64 | 105.187 qps |
## GCViT
- [Keras GCViT](keras_cv_attention_models/gcvit) includes implementation of [PDF 2206.09959 Global Context Vision Transformers](https://arxiv.org/pdf/2206.09959.pdf).
| Model | Params | FLOPs | Input | Top1 Acc | Download |
| --------------- | ------ | ------ | ----- | -------- | -------- |
| [GCViT_XXTiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/gcvit/gcvit_xx_tiny_224_imagenet.h5) | 12.0M | 2.15G | 224 | 79.9 | 337.7 qps |
| [GCViT_XTiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/gcvit/gcvit_x_tiny_224_imagenet.h5) | 20.0M | 2.96G | 224 | 82.0 | 255.625 qps |
| [GCViT_Tiny](https://github.com/leondgarse/keras_cv_attention_models/releases/download/gcvit/gcvit_tiny_224_imagenet.h5) | 28.2M | 4.83G | 224 | 83.5 | 174.553 qps |
| [GCViT_Tiny2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/gcvit/gcvit_tiny2_224_imagenet.h5) | 34.5M | 6.28G | 224 | 83.7 | |
| [GCViT_Small](https://github.com/leondgarse/keras_cv_attention_models/releases/download/gcvit/gcvit_small_224_imagenet.h5) | 51.1M | 8.63G | 224 | 84.3 | 131.577 qps |
| [GCViT_Small2](https://github.com/leondgarse/keras_cv_attention_models/releases/download/gcvit/gcvit_small2_224_imagenet.h5) | 68.6M | 11.7G | 224 | 84.8 | |
| [GCViT_Base](https://github.com/leondgarse/keras_cv_attention_models/releases/do