https://github.com/lijinma/wechat_spider
使用“代理”的方式来抓取微信公众账号文章,可以抓取阅读数、点赞数,基于 anyproxy。
https://github.com/lijinma/wechat_spider
anyproxy wechat wechat-spider
Last synced: about 1 year ago
JSON representation
使用“代理”的方式来抓取微信公众账号文章,可以抓取阅读数、点赞数,基于 anyproxy。
- Host: GitHub
- URL: https://github.com/lijinma/wechat_spider
- Owner: lijinma
- Created: 2017-04-04T06:49:24.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2020-09-04T02:44:14.000Z (almost 6 years ago)
- Last Synced: 2025-04-04T01:09:08.272Z (about 1 year ago)
- Topics: anyproxy, wechat, wechat-spider
- Language: JavaScript
- Homepage:
- Size: 43 KB
- Stars: 949
- Watchers: 55
- Forks: 226
- Open Issues: 27
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
wechat_spider
=====
[](http://badge.fury.io/js/wechat_spider)
[](https://david-dm.org/lijinma/wechat_spider)
## 【提醒】此抓取工具因为微信 api 修改无法跑通,请参考代码思路。
创造不息,交付不止

这个项目是使用打理的方式抓取微信公众账号文章,首先你需要了解一下现在抓取微信公众账号的两种主流方法,请参考我的文章:
[如何优雅的抓取微信公众号历史文章](https://mp.weixin.qq.com/s?__biz=MjM5NDA0Mjc0MQ==&mid=2651552202&idx=1&sn=832cd8e9c4f5babcd20e6a52ee03611e&chksm=bd721fd08a0596c6005f9c77f1c7b1f06fef2cceebd67dde0f33c822f8053d7c521a753c0101&scene=0&key=31688975937a18944006a2d2a5b0c346a7e091a3f473e69af65ebce0e0722a9bdac3cc4281c2eb40f110c3b87a727d8f42b8265a7c1cb20744f74eadf0178023744783aab775c2d47ac7a30b16c65548&ascene=0&uin=OTM1MDQxMDQw)
所以现在一般有两种做法,一种通过搜狗微信,一种通过代理的方式抓取,这个项目就是使用代理的方式抓取。
我本来是写了更复杂的工具,使用 Node.js 的 anyproxy 加上 php 的 Laravel 框架,完成这些功能,但是某天洗澡的时候终于想通了,我其实把一个工具复杂化了,这个工具本来是很简单的,我给一位媒体朋友指导了一下,他也很快就用起来了。
## 输出
输出有两个东西,一个是 wechat.sqlite,一个是 wechat.csv,wechat.csv 需要通过命令 `wechat_spider csv` 来生成。
如下是我的公众账号对应的数据:
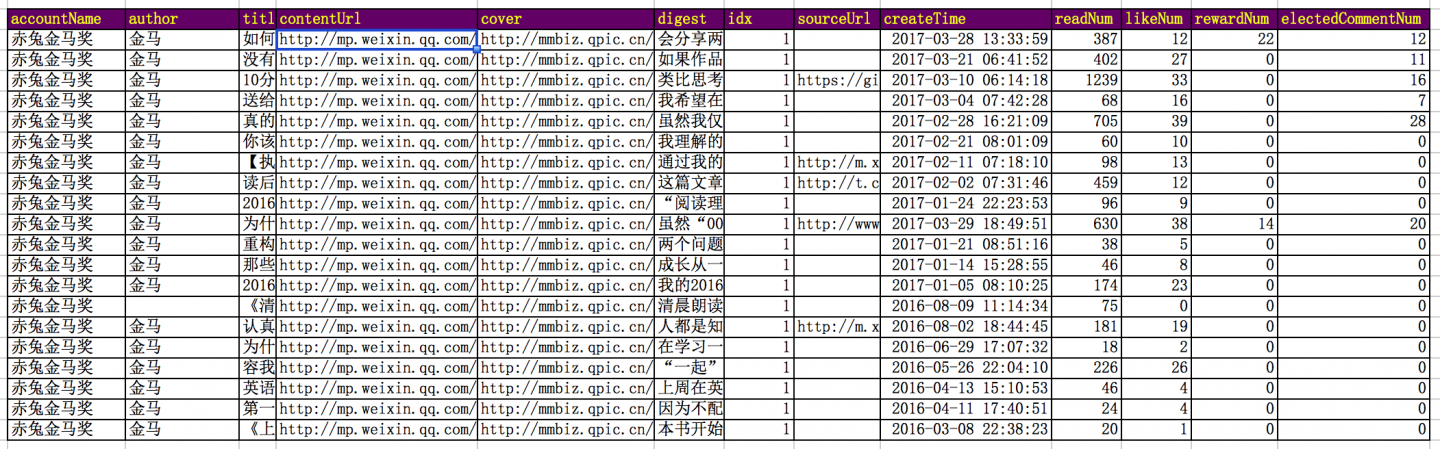
表格头解释:
```
accountName: 公众号名称
author: 作者
title: 文章标题
contentUrl: 文章链接
cover: 文章封面图
digest: 文章摘要
idx: 如果是1,代表的是当天第一篇文章,如果是2,代表当天第二篇文章,以此类推。
sourceUrl: 阅读原文对应的链接
createTime: 文章创建时间
readNum: 阅读数
likeNum: 点赞数
rewardNum: 赞赏数
electedCommentNum: 被选择显示的回复数
```
## 安装
### 安装 Node.js
通过网站 https://nodejs.org/zh-cn/ 下载最新版本。
### 安装 Python 2.x 等编译环境依赖
因为里面依赖 sqlite,通过 [node-gyp](https://github.com/nodejs/node-gyp) 编译的过程中需要 python 2.x (3.x 不行) 以及 VCBuild.exe ,所以 Windows 的同学一定要安装一下,否则会出错。
Windows 用户通过在具有管理员权限的 PowerShell 下输入 `npm install --global --production windows-build-tools` 下载安装编译环境依赖。
### 测试 Node 和 Python 安装正确
Mac 在终端下,Windows 在 cmd 下:
```bash
$ npm -v
4.3.0
$ python
Python 2.7.6 (default, Nov 18 2013, 15:12:51)
[GCC 4.2.1 Compatible Apple LLVM 5.0 (clang-500.2.79)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
```
如果输出以上类似的信息,证明工具已经安装好了。
### 安装 wechat_spider
```bash
$ npm install wechat_spider -g
```
### 测试 wechat_spider 安装正确
```bash
$ wechat_spider --help
Usage: wechat_spider [options]
Options:
-h, --help output usage information
-V, --version output the version number
```
如果输出以上类似信息,证明 wechat_spider 已经安装成功
## 使用
使用分四步,开启代理,手机设置代理,查看公众账号历史记录,接下来就开始自动抓取了,最后生成 csv。
### 首次打开需要安装证书
第一步:Mac 在终端下,Windows 在 cmd 下打开工具:
$ wechat_spider
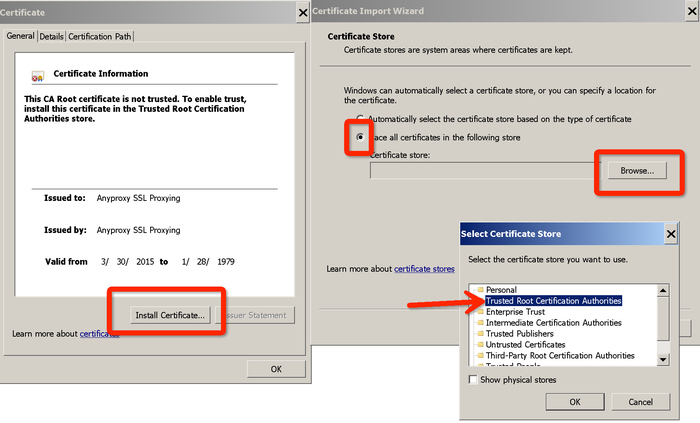
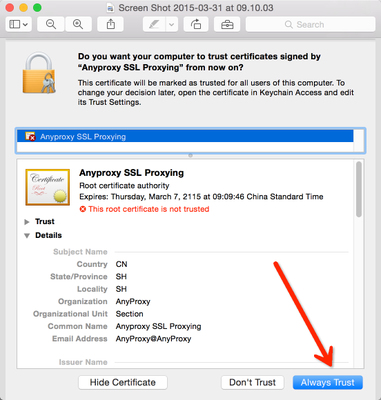
首次需要信任证书。
默认会打开证书的文件夹,如果没有打开,浏览器打开 http://localhost:8002/fetchCrtFile ,也能获取rootCA.crt文件,获取到根证书后,双击,根据操作系统提示,信任rootCA:
* Windows
* 
* Mac
* 
第二步:使用手机代理:
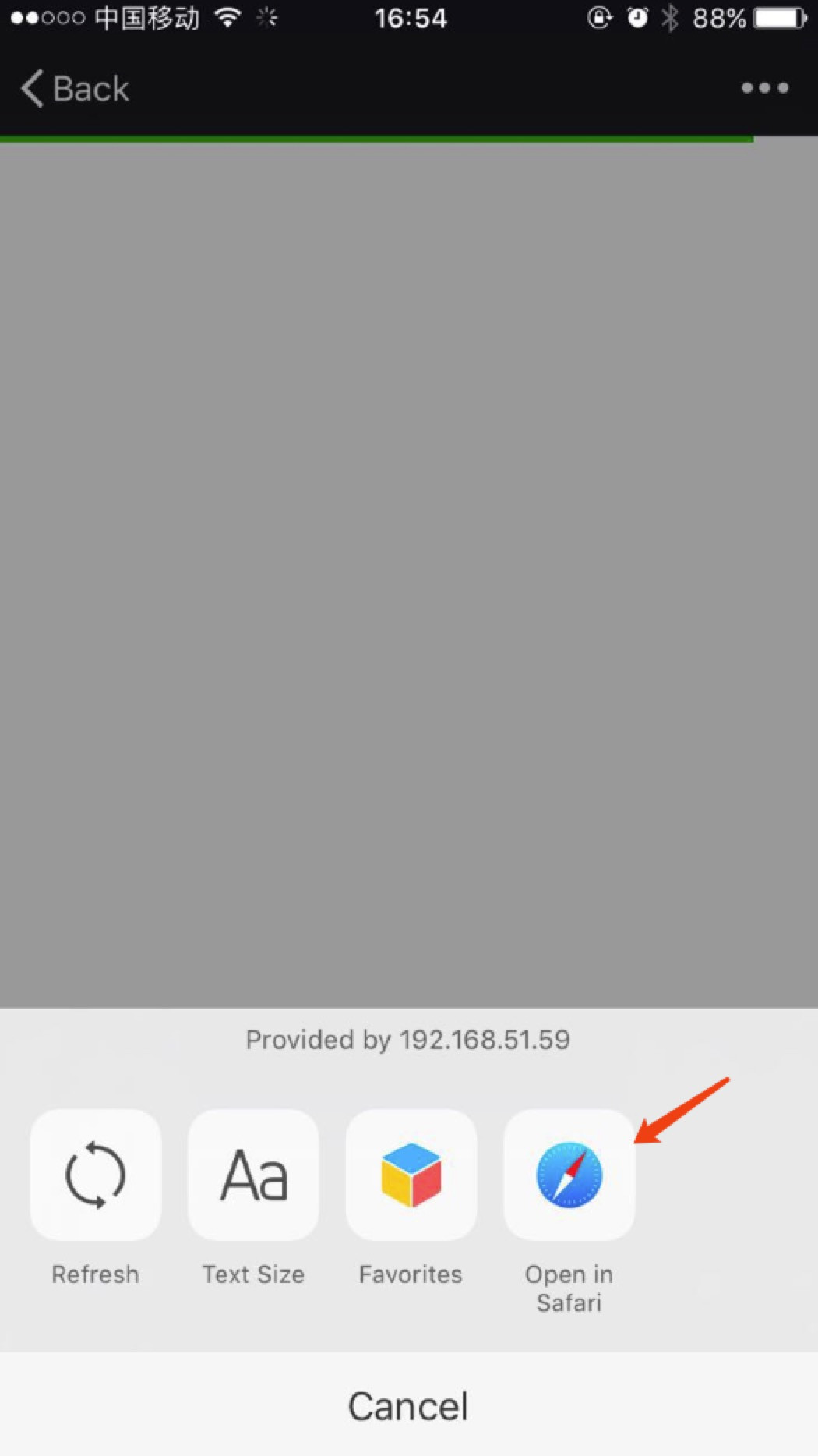
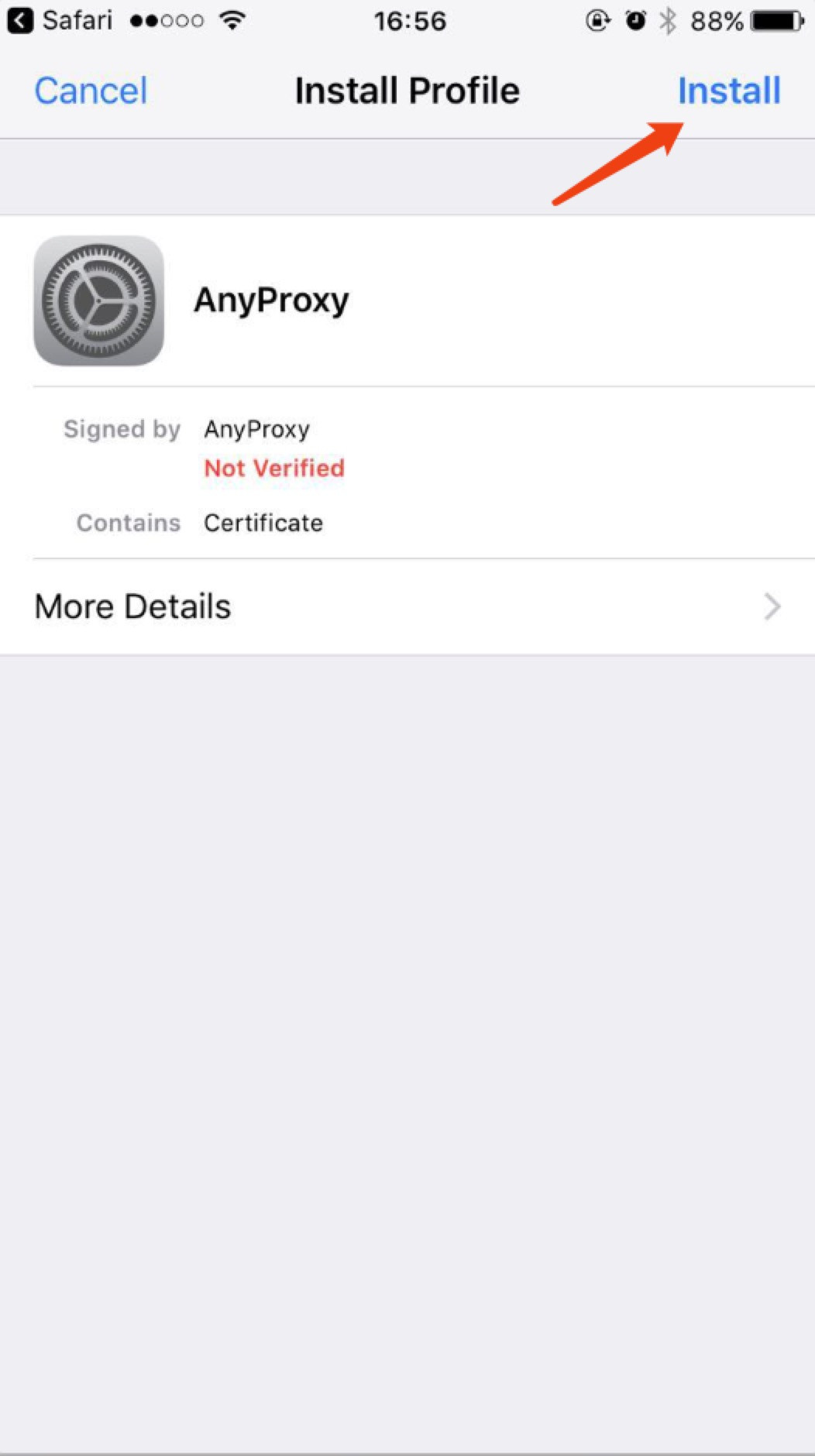
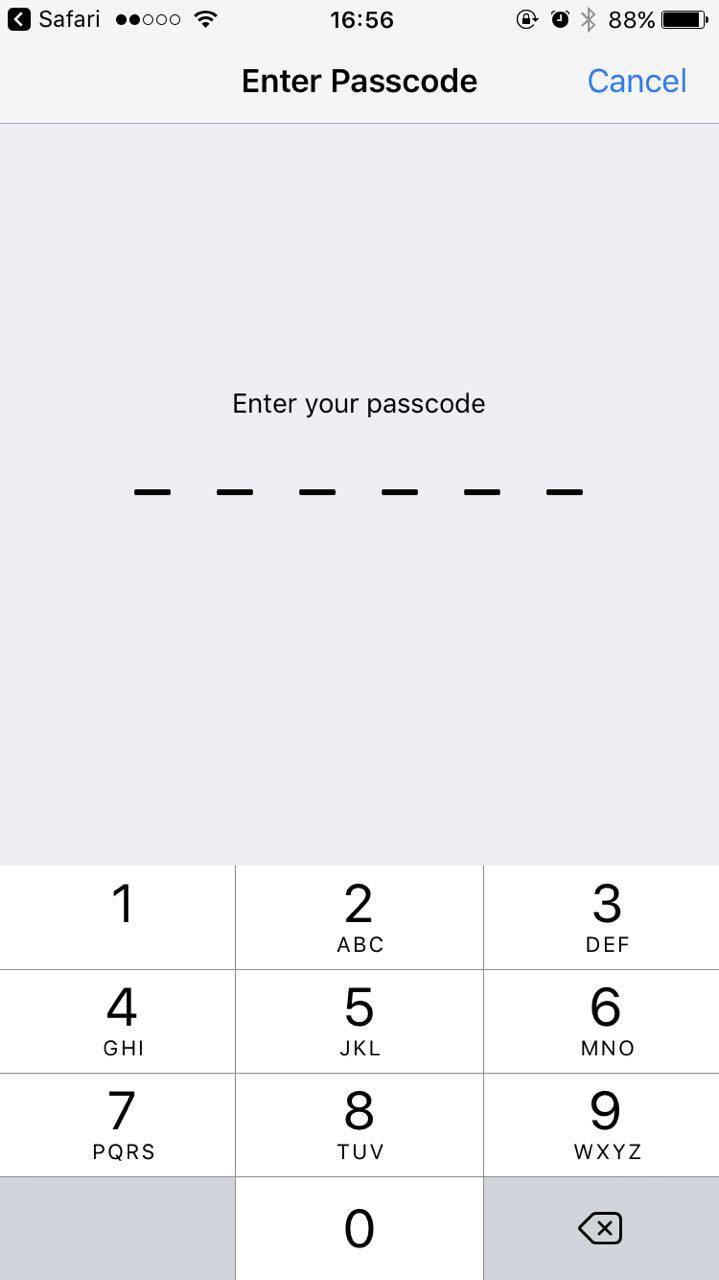
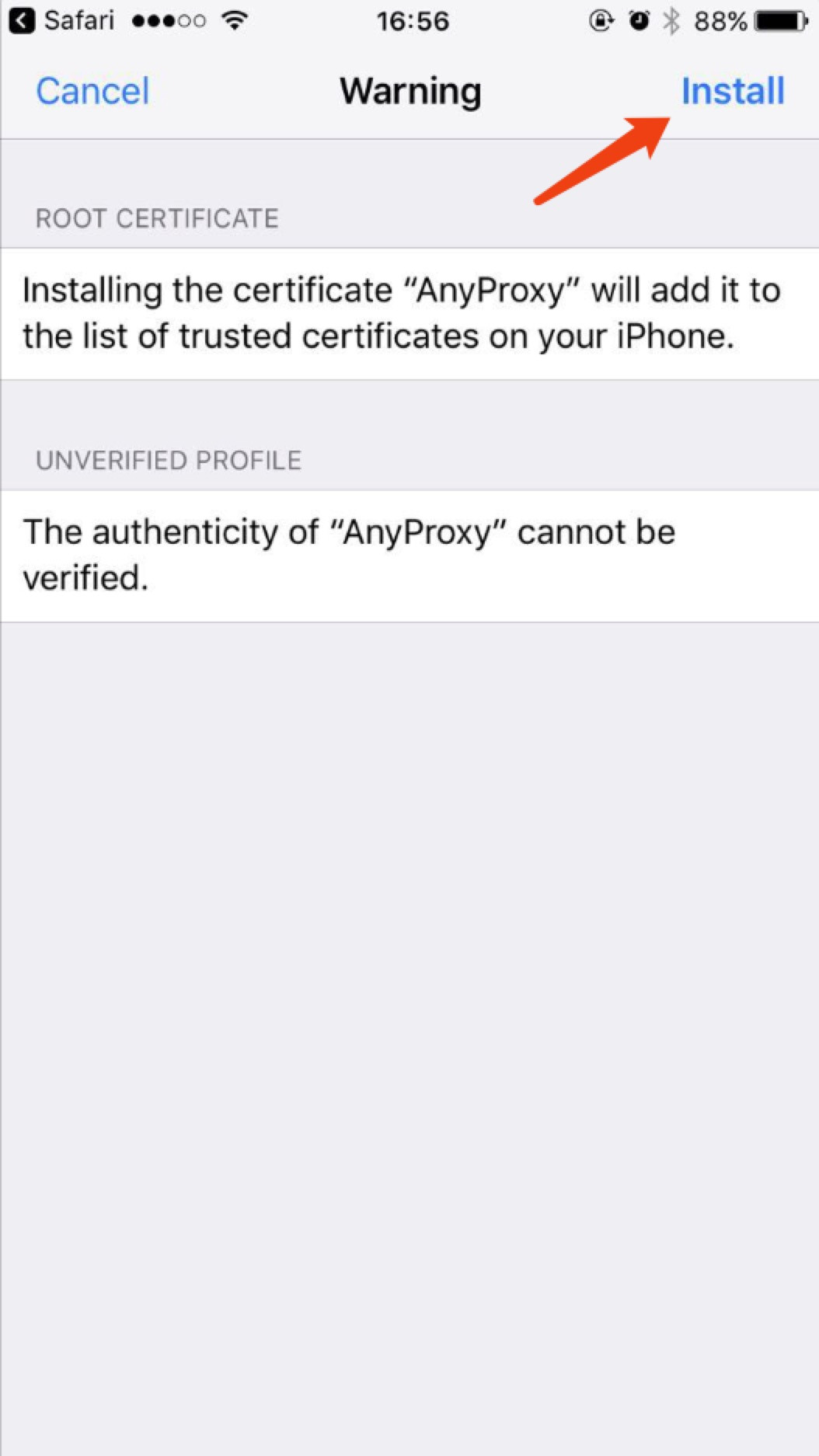
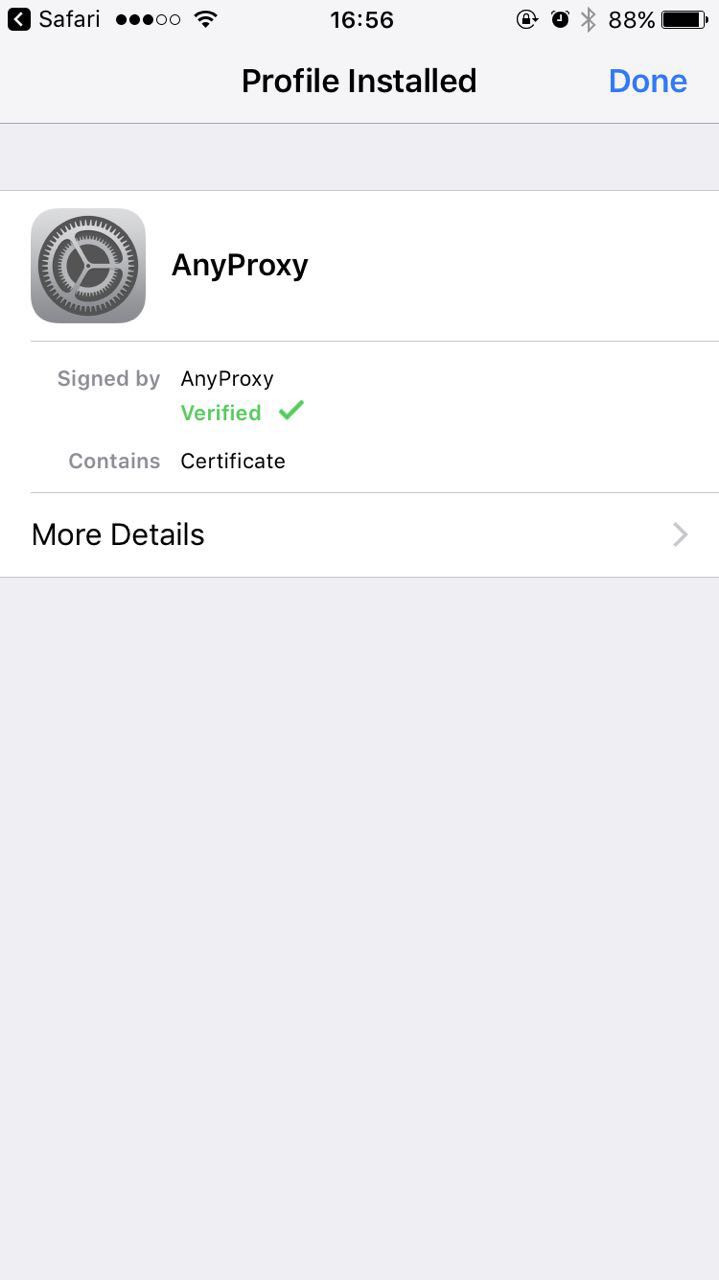
* 首次手机需要安装证书,浏览器打开:http://localhost:8002/qr_root ,使用微信扫描二维码,[重要] 用浏览器打开:
* 
* 
* 
* 
* 
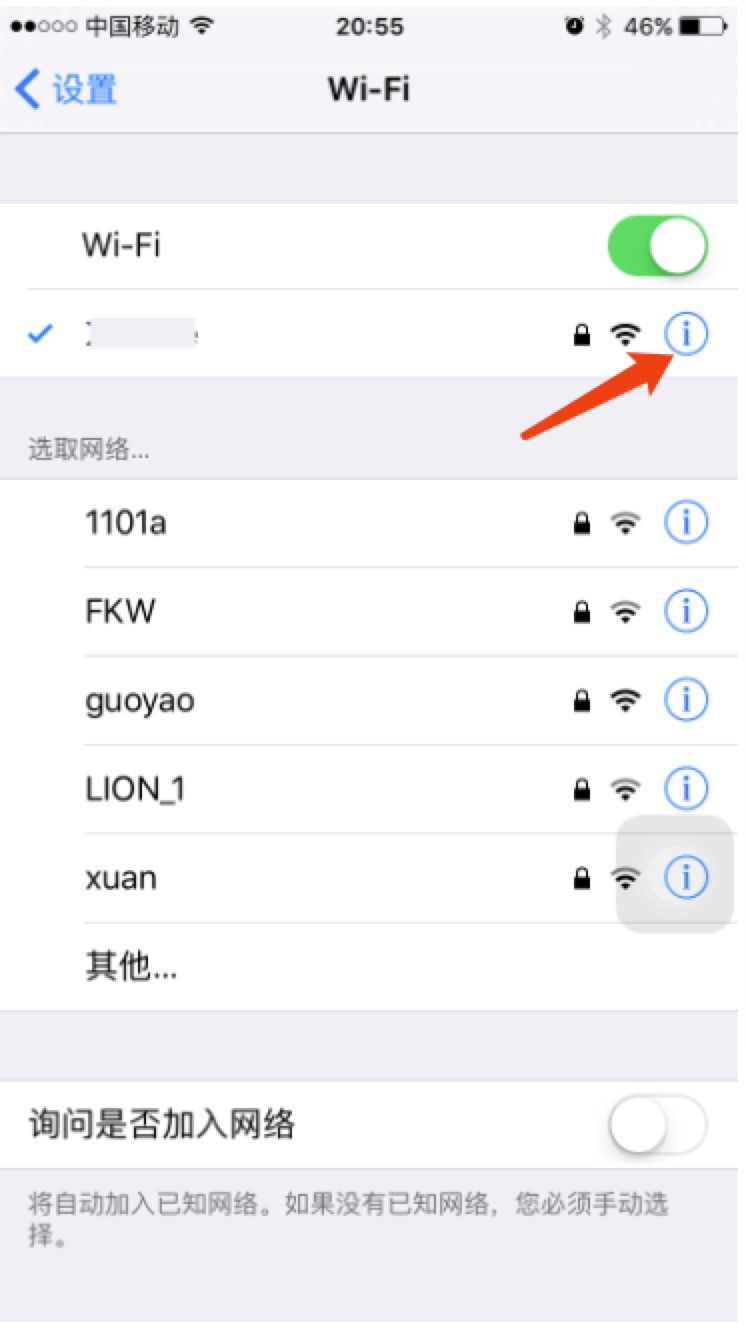
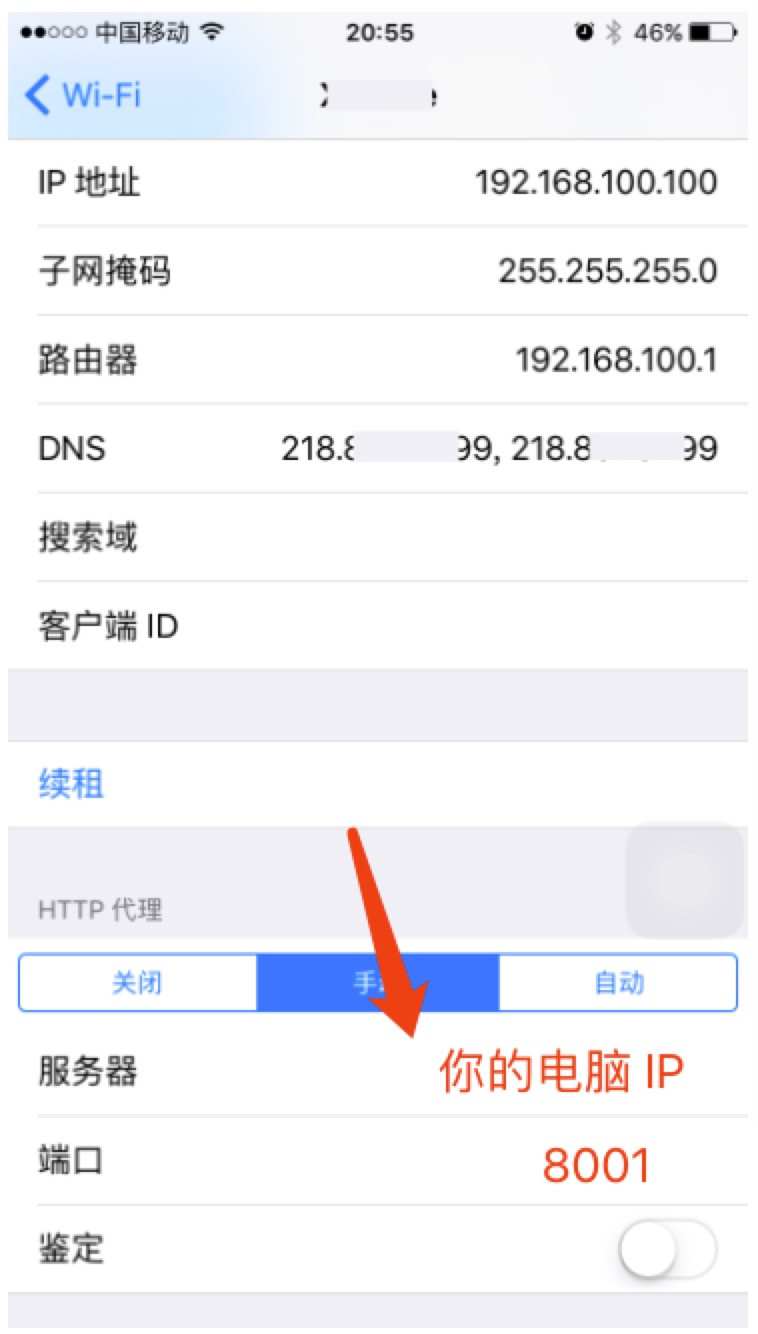
* 然后获取到你电脑的 IP 地址,假设是 192.168.1.5
* 设置手机代理为电脑:
* 
* 
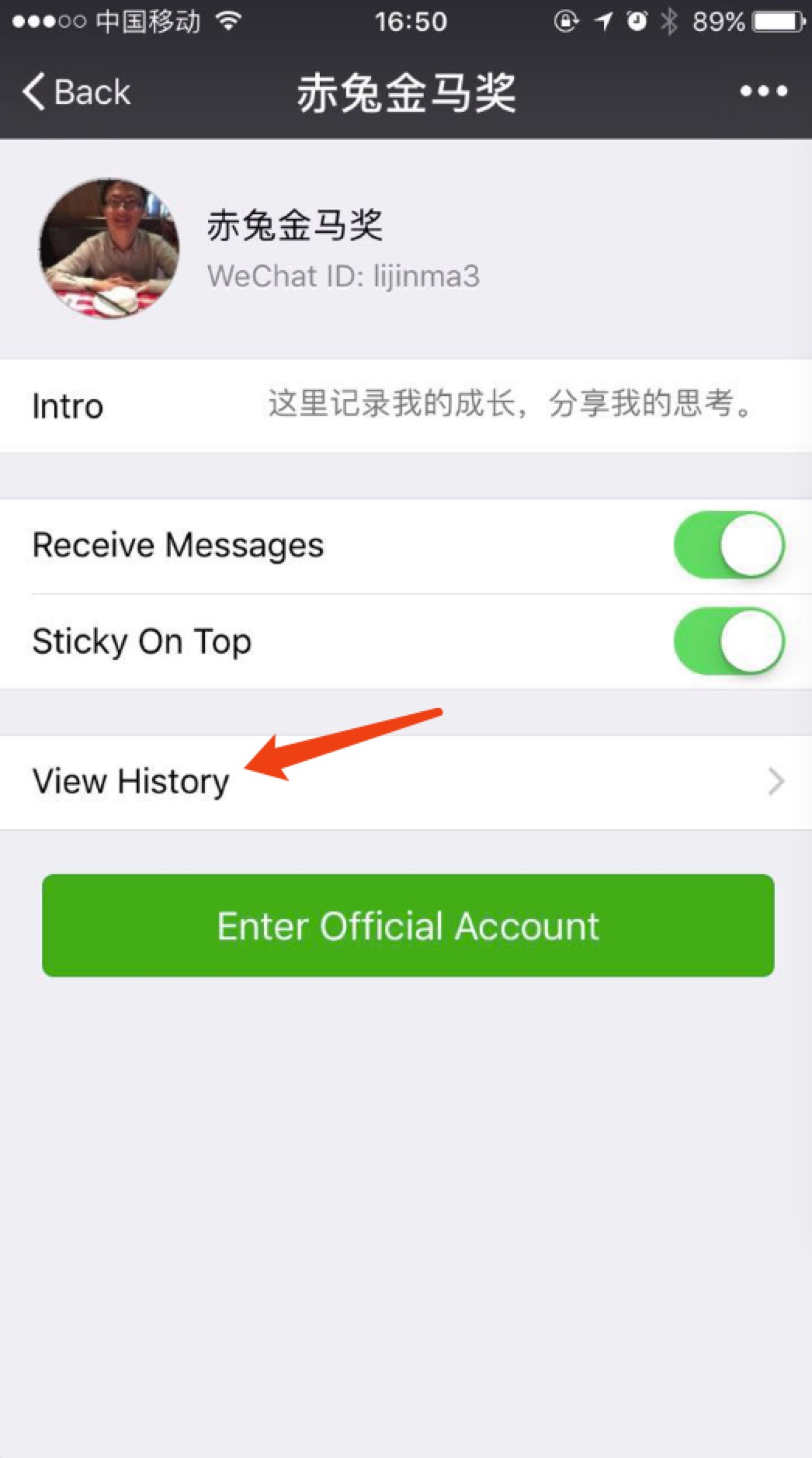
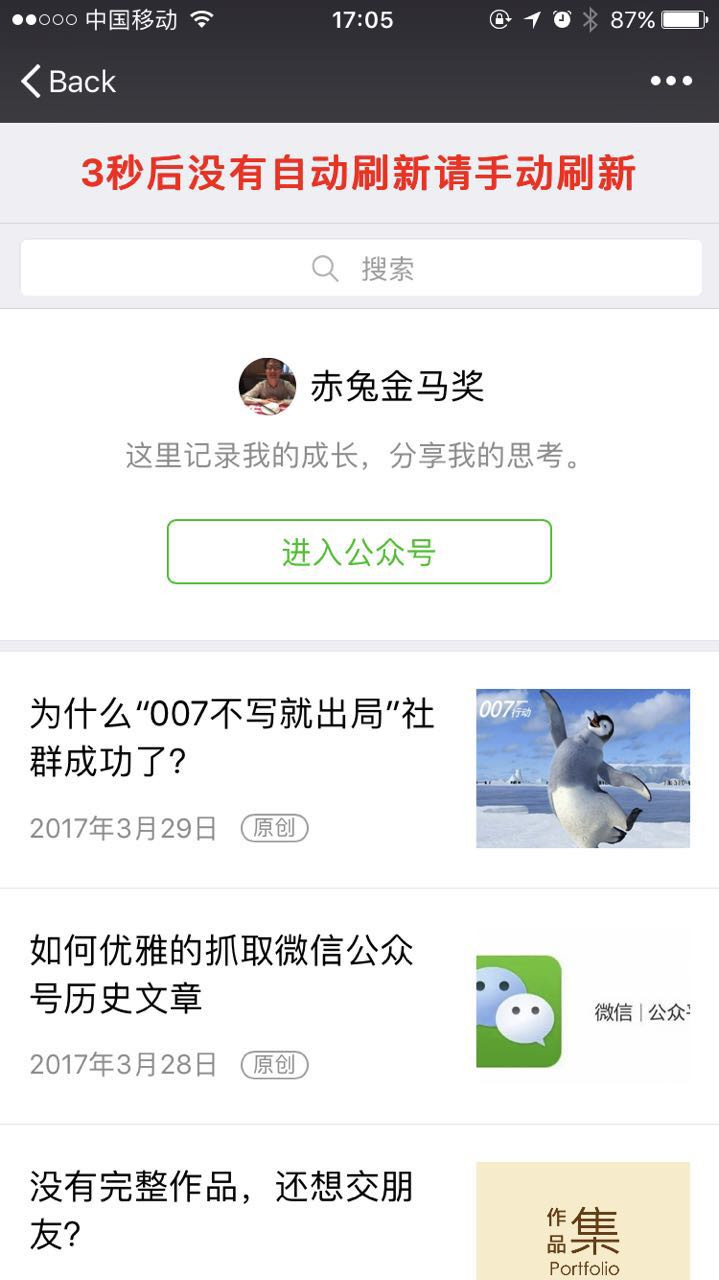
第三步:选择一个微信公众号,点击查看历史记录
* 
* 
第四步:等待出现页面“一个公众号采集完成”,就可以生成 csv 了
```bash
$ wechat_spider csv
```
## 打赏
我是金马,一个想搞点事情的程序员。如果这个小工具对你有帮助,你可以请我喝杯咖啡,谢谢 :)

## LICENSE
MIT.