https://github.com/linjieli222/HERO
Research code for EMNLP 2020 paper "HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training"
https://github.com/linjieli222/HERO
pretraining pytorch transformers tvr vision-and-language
Last synced: 12 months ago
JSON representation
Research code for EMNLP 2020 paper "HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training"
- Host: GitHub
- URL: https://github.com/linjieli222/HERO
- Owner: linjieli222
- License: mit
- Created: 2020-09-29T19:44:03.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2021-09-16T20:50:12.000Z (almost 5 years ago)
- Last Synced: 2024-08-09T13:19:07.789Z (almost 2 years ago)
- Topics: pretraining, pytorch, transformers, tvr, vision-and-language
- Language: Python
- Homepage: https://arxiv.org/abs/2005.00200
- Size: 248 KB
- Stars: 227
- Watchers: 7
- Forks: 34
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - linjieli222/HERO - VTT Retrieval](http://ms-multimedia-challenge.com/2017/challenge)上微调 HERO 。发布了最好的预训练检查点(在[HowTo100M](https://www.di.ens.fr/willow/research/howto100m/)和[TV](http://tvqa.cs.unc.edu/)数据集上)。还提供了在 TV 数据集上进行 HERO 预训练的代码。 (其他_机器视觉 / 网络服务_其他)
README
# HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
This is the official repository of [HERO](https://arxiv.org/abs/2005.00200) (EMNLP 2020).
This repository currently supports finetuning HERO on
[TVR](https://tvr.cs.unc.edu/), [TVQA](http://tvqa.cs.unc.edu/), [TVC](https://tvr.cs.unc.edu/tvc.html),
[VIOLIN](https://github.com/jimmy646/violin),
[DiDeMo](https://github.com/LisaAnne/TemporalLanguageRelease), and
[MSR-VTT Retrieval](http://ms-multimedia-challenge.com/2017/challenge).
The best pre-trained checkpoint (on both [HowTo100M](https://www.di.ens.fr/willow/research/howto100m/) and [TV](http://tvqa.cs.unc.edu/) Dataset) are released. Code for HERO pre-training on TV Dataset is also available.
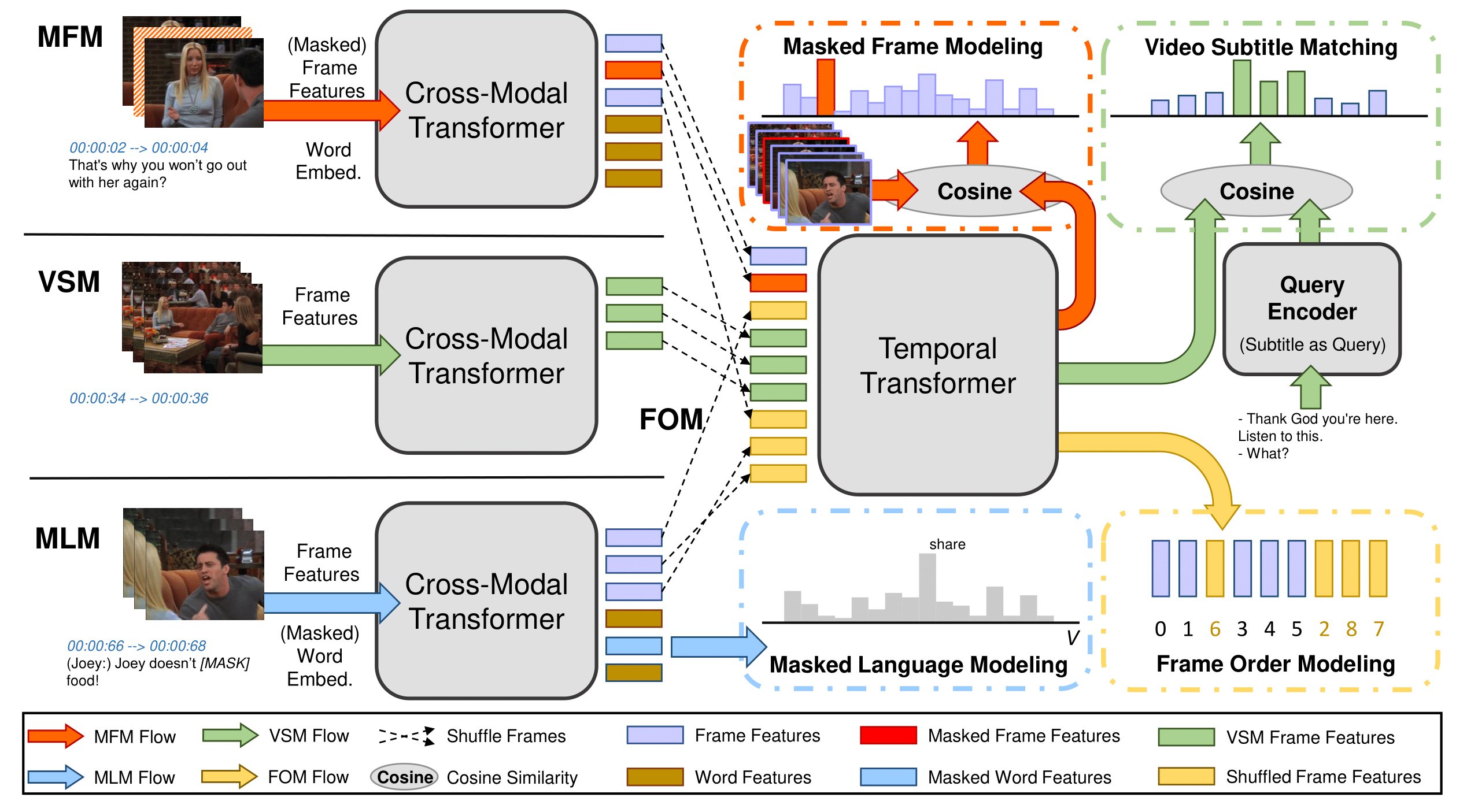
Some code in this repo are copied/modified from opensource implementations made available by
[PyTorch](https://github.com/pytorch/pytorch),
[HuggingFace](https://github.com/huggingface/transformers),
[OpenNMT](https://github.com/OpenNMT/OpenNMT-py),
[Nvidia](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch),
[TVRetrieval](https://github.com/jayleicn/TVRetrieval),
[TVCaption](https://github.com/jayleicn/TVCaption),
and [UNITER](https://github.com/ChenRocks/UNITER).
The visual frame features are extracted using [SlowFast](https://github.com/facebookresearch/SlowFast) and ResNet-152. Feature extraction code is available at [HERO_Video_Feature_Extractor](https://github.com/linjieli222/HERO_Video_Feature_Extractor)
## Requirements
We provide Docker image for easier reproduction. Please install the following:
- [nvidia driver](https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#package-manager-installation) (418+),
- [Docker](https://docs.docker.com/install/linux/docker-ce/ubuntu/) (19.03+),
- [nvidia-container-toolkit](https://github.com/NVIDIA/nvidia-docker#quickstart).
Our scripts require the user to have the [docker group membership](https://docs.docker.com/install/linux/linux-postinstall/)
so that docker commands can be run without sudo.
We only support Linux with NVIDIA GPUs. We test on Ubuntu 18.04 and V100 cards.
We use mixed-precision training hence GPUs with Tensor Cores are recommended.
## Quick Start
*NOTE*: Please run `bash scripts/download_pretrained.sh $PATH_TO_STORAGE` to get our latest pretrained
checkpoints.
We use TVR as an end-to-end example for using this code base.
1. Download processed data and pretrained models with the following command.
```bash
bash scripts/download_tvr.sh $PATH_TO_STORAGE
```
After downloading you should see the following folder structure:
```
├── finetune
│ ├── tvr_default
├── video_db
│ ├── tv
├── pretrained
│ └── hero-tv-ht100.pt
└── txt_db
├── tv_subtitles.db
├── tvr_train.db
├── tvr_val.db
└── tvr_test_public.db
```
2. Launch the Docker container for running the experiments.
```bash
# docker image should be automatically pulled
source launch_container.sh $PATH_TO_STORAGE/txt_db $PATH_TO_STORAGE/video_db \
$PATH_TO_STORAGE/finetune $PATH_TO_STORAGE/pretrained
```
The launch script respects $CUDA_VISIBLE_DEVICES environment variable.
Note that the source code is mounted into the container under `/src` instead
of built into the image so that user modification will be reflected without
re-building the image. (Data folders are mounted into the container separately
for flexibility on folder structures.)
3. Run finetuning for the TVR task.
```bash
# inside the container
horovodrun -np 8 python train_vcmr.py --config config/train-tvr-8gpu.json
# for single gpu
python train_vcmr.py --config $YOUR_CONFIG_JSON
```
4. Run inference for the TVR task.
```bash
# inference, inside the container
horovodrun -np 8 python eval_vcmr.py --query_txt_db /txt/tvr_val.db/ --split val \
--vfeat_db /video/tv/ --sub_txt_db /txt/tv_subtitles.db/ \
--output_dir /storage/tvr_default/ --checkpoint 4800 --fp16 --pin_mem
```
The result file will be written at `/storage/tvr_default/results_val/results_4800_all.json`.
Change to ``--query_txt_db /txt/tvr_test_public.db/ --split test_public`` for inference on test_public split.
Please format the result file as requested by the evaluation server for submission, our code does not include formatting.
The above command runs inference on the model we trained.
Feel free to replace `--output_dir` and `--checkpoint` with your own model trained in step 3.
Single GPU inference is also supported.
5. Misc.
In case you would like to reproduce the whole preprocessing pipeline.
* Text annotation and subtitle preprocessing
```bash
# outside of the container
bash scripts/create_txtdb.sh $PATH_TO_STORAGE/txt_db $PATH_TO_STORAGE/ann
```
* Video feature extraction
We provide feature extraction code at [HERO_Video_Feature_Extractor](https://github.com/linjieli222/HERO_Video_Feature_Extractor).
Please follow the link for instructions to extract both 2D ResNet features and 3D SlowFast features.
These features are saved as separate .npz files per video.
* Video feature preprocessing and saved to lmdb
```bash
# inside of the container
# Gather slowfast/resnet feature paths
python scripts/collect_video_feature_paths.py --feature_dir $PATH_TO_STORAGE/feature_output_dir\
--output $PATH_TO_STORAGE/video_db --dataset $DATASET_NAME
# Convert to lmdb
python scripts/convert_videodb.py --vfeat_info_file $PATH_TO_STORAGE/video_db/$DATASET_NAME/video_feat_info.pkl \
--output $PATH_TO_STORAGE/video_db --dataset $DATASET_NAME --frame_length 1.5
```
- `--frame_length`: 1 feature per "frame_length" seconds, we use 1.5/2 in our implementation. set it to be consistent with the one used in feature extraction.
- `--compress`: enable compression of lmdb
## Downstream Tasks Finetuning
### TVQA
NOTE: train and inference should be ran inside the docker container
1. download data
```bash
# outside of the container
bash scripts/download_tvqa.sh $PATH_TO_STORAGE
```
2. train
```bash
# inside the container
horovodrun -np 8 python train_videoQA.py --config config/train-tvqa-8gpu.json \
--output_dir $TVQA_EXP
```
3. inference
```bash
# inside the container
horovodrun -np 8 python eval_videoQA.py --query_txt_db /txt/tvqa_test_public.db/ --split test_public \
--vfeat_db /video/tv/ --sub_txt_db /txt/tv_subtitles.db/ \
--output_dir $TVQA_EXP --checkpoint $ckpt --pin_mem --fp16
```
The result file will be written at `$TVQA_EXP/results_test_public/results_$ckpt_all.json`, which can be submitted to the evaluation server. Please format the result file as requested by the evaluation server for submission, our code does not include formatting.
### TVC
1. download data
```bash
# outside of the container
bash scripts/download_tvc.sh $PATH_TO_STORAGE
```
2. train
```bash
# inside the container
horovodrun -np 8 python train_tvc.py --config config/train-tvc-8gpu.json \
--output_dir $TVC_EXP
```
3. inference
```bash
# inside the container
python inf_tvc.py --model_dir $TVC_EXP --ckpt_step 7000 \
--target_clip /txt/tvc_val_release.jsonl --output tvc_val_output.jsonl
```
- `tvc_val_output.jsonl` will be in the official TVC submission format.
- change to `--target_clip /txt/tvc_test_public_release.jsonl` for test results.
NOTE: see `scripts/prepro_tvc.sh` for LMDB preprocessing.
### VIOLIN
1. download data
```bash
# outside of the container
bash scripts/download_violin.sh $PATH_TO_STORAGE
```
2. train
```bash
# inside the container
horovodrun -np 8 python train_violin.py --config config/train-violin-8gpu.json \
--output_dir $VIOLIN_EXP
```
### DiDeMo
1. download data
```bash
# outside of the container
bash scripts/download_didemo.sh $PATH_TO_STORAGE
```
2. train
```bash
# inside the container
horovodrun -np 4 python train_vcmr.py --config config/train-didemo_video_only-4gpu.json \
--output_dir $DIDEMO_EXP
```
Switch to `config/train-didemo_video_sub-8gpu.json` for ASR augmented DiDeMo results. You can also download the original ASR [here](https://convaisharables.blob.core.windows.net/hero/asr/didemo_asr.jsonl).
### MSR-VTT Retrieval
1. download data
```bash
# outside of the container
bash scripts/download_msrvtt.sh $PATH_TO_STORAGE
```
2. train
```bash
# inside the container
horovodrun -np 4 python train_vr.py --config config/train-msrvtt_video_only-4gpu.json \
--output_dir $MSRVTT_EXP
```
Switch to `config/train-msrvtt_video_sub-4gpu.json` for ASR augmented MSR-VTT results. You can also download the original ASR [here](https://convaisharables.blob.core.windows.net/hero/asr/msrvtt_asr.jsonl).
### How2R and How2QA
For raw annotation, please refer to [How2R and How2QA](https://github.com/ych133/How2R-and-How2QA).
Features and code will be available soon ....
## Pre-training
1. download data
```bash
# outside of the container
bash scripts/download_tv_pretrain.sh $PATH_TO_STORAGE
```
2. pre-train
```bash
# inside of the container
horovodrun -np 16 python pretrain.py --config config/pretrain-tv-16gpu.json \
--output_dir $PRETRAIN_EXP
```
Unfortunately, we cannot host HowTo100M features due to its large size. Users can either process them on their own or send your inquiry to my email address (which you can find on our paper).
## Citation
If you find this code useful for your research, please consider citing:
```bibtex
@inproceedings{li2020hero,
title={HERO: Hierarchical Encoder for Video+ Language Omni-representation Pre-training},
author={Li, Linjie and Chen, Yen-Chun and Cheng, Yu and Gan, Zhe and Yu, Licheng and Liu, Jingjing},
booktitle={EMNLP},
year={2020}
}
```
## License
MIT