https://github.com/louisbrulenaudet/ragoon
High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing ⚡
https://github.com/louisbrulenaudet/ragoon
ai embeddings embeddings-similarity faiss generative-ai groq groqapi llama llama-index llm nlp rag retrieval-augmented-generation vector-database vector-search vectorization
Last synced: 3 months ago
JSON representation
High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing ⚡
- Host: GitHub
- URL: https://github.com/louisbrulenaudet/ragoon
- Owner: louisbrulenaudet
- License: apache-2.0
- Created: 2024-05-19T17:57:20.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2024-09-01T10:30:23.000Z (almost 2 years ago)
- Last Synced: 2024-10-30T01:51:45.226Z (over 1 year ago)
- Topics: ai, embeddings, embeddings-similarity, faiss, generative-ai, groq, groqapi, llama, llama-index, llm, nlp, rag, retrieval-augmented-generation, vector-database, vector-search, vectorization
- Language: Jupyter Notebook
- Homepage: https://ragoon.readthedocs.io
- Size: 18.9 MB
- Stars: 59
- Watchers: 5
- Forks: 6
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Citation: CITATION.cff
Awesome Lists containing this project
README

# RAGoon : High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing ⚡
[](https://badge.fury.io/py/tensorflow) [](https://opensource.org/licenses/Apache-2.0) 
RAGoon is a set of NLP utilities for multi-model embedding production, high-dimensional vector visualization, and aims to improve language model performance by providing contextually relevant information through search-based querying, web scraping and data augmentation techniques.
## Quick install
The reference page for RAGoon is available on the official page of PyPI: [RAGoon](https://pypi.org/project/ragoon/).
```python
pip install ragoon
```
## Usage
This section provides an overview of different code blocks that can be executed with RAGoon to enhance your NLP and language model projects.
### Embeddings production
This class handles loading a dataset from Hugging Face, processing it to add embeddings using specified models, and provides methods to save and upload the processed dataset.
```python
from ragoon import EmbeddingsDataLoader
from datasets import load_dataset
# Initialize the dataset loader with multiple models
loader = EmbeddingsDataLoader(
token="hf_token",
dataset=load_dataset("louisbrulenaudet/dac6-instruct", split="train"), # If dataset is already loaded.
# dataset_name="louisbrulenaudet/dac6-instruct", # If you want to load the dataset from the class.
model_configs=[
{"model": "bert-base-uncased", "query_prefix": "Query:"},
{"model": "distilbert-base-uncased", "query_prefix": "Query:"}
# Add more model configurations as needed
]
)
# Uncomment this line if passing dataset_name instead of dataset.
# loader.load_dataset()
# Process the splits with all models loaded
loader.process(
column="output",
preload_models=True
)
# To access the processed dataset
processed_dataset = loader.get_dataset()
print(processed_dataset[0])
```
You can also embed a single text using multiple models:
```python
from ragoon import EmbeddingsDataLoader
# Initialize the dataset loader with multiple models
loader = EmbeddingsDataLoader(
token="hf_token",
model_configs=[
{"model": "bert-base-uncased"},
{"model": "distilbert-base-uncased"}
]
)
# Load models
loader.load_models()
# Embed a single text with all loaded models
text = "This is a single text for embedding."
embedding_result = loader.batch_encode(text)
# Output the embeddings
print(embedding_result)
```
### Similarity search and index creation
The `SimilaritySearch` class is instantiated with specific parameters to configure the embedding model and search infrastructure. The chosen model, `louisbrulenaudet/tsdae-lemone-mbert-base`, is likely a multilingual BERT model fine-tuned with TSDAE (Transfomer-based Denoising Auto-Encoder) on a custom dataset. This model choice suggests a focus on multilingual capabilities and improved semantic representations.
The `cuda` device specification leverages GPU acceleration, crucial for efficient processing of large datasets. The embedding dimension of `768` is typical for BERT-based models, representing a balance between expressiveness and computational efficiency. The `ip` (inner product) metric is selected for similarity comparisons, which is computationally faster than cosine similarity when vectors are normalized. The `i8` dtype indicates 8-bit integer quantization, a technique that significantly reduces memory usage and speeds up similarity search at the cost of a small accuracy rade-off.
```python
import polars as pl
from ragoon import (
dataset_loader,
SimilaritySearch,
EmbeddingsVisualizer
)
dataset = dataset_loader(
name="louisbrulenaudet/dac6-instruct",
streaming=False,
split="train"
)
dataset.save_to_disk("dataset.hf")
instance = SimilaritySearch(
model_name="louisbrulenaudet/tsdae-lemone-mbert-base",
device="cuda",
ndim=768,
metric="ip",
dtype="i8"
)
embeddings = instance.encode(corpus=dataset["output"])
ubinary_embeddings = instance.quantize_embeddings(
embeddings=embeddings,
quantization_type="ubinary"
)
int8_embeddings = instance.quantize_embeddings(
embeddings=embeddings,
quantization_type="int8"
)
instance.create_usearch_index(
int8_embeddings=int8_embeddings,
index_path="./usearch_int8.index",
save=True
)
instance.create_faiss_index(
ubinary_embeddings=ubinary_embeddings,
index_path="./faiss_ubinary.index",
save=True
)
top_k_scores, top_k_indices = instance.search(
query="Définir le rôle d'un intermédiaire concepteur conformément à l'article 1649 AE du Code général des Impôts.",
top_k=10,
rescore_multiplier=4
)
try:
dataframe = pl.from_arrow(dataset.data.table).with_row_index()
except:
dataframe = pl.from_arrow(dataset.data.table).with_row_count(
name="index"
)
scores_df = pl.DataFrame(
{
"index": top_k_indices,
"score": top_k_scores
}
).with_columns(
pl.col("index").cast(pl.UInt32)
)
search_results = dataframe.filter(
pl.col("index").is_in(top_k_indices)
).join(
scores_df,
how="inner",
on="index"
)
print("search_results")
```
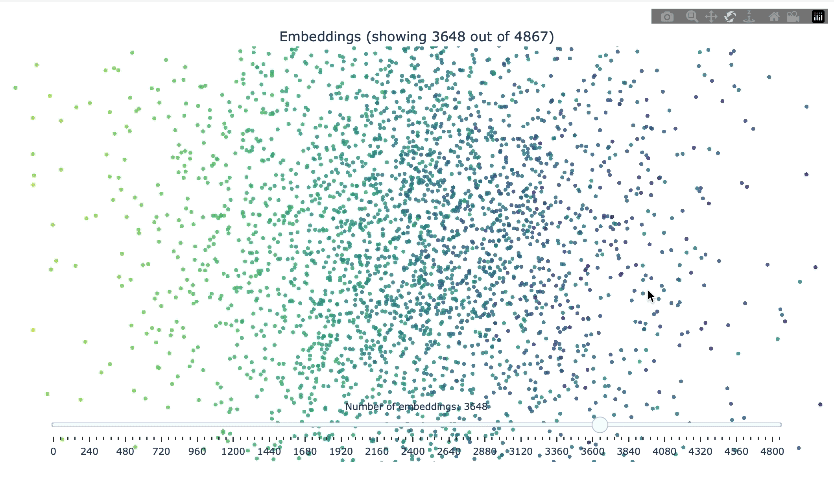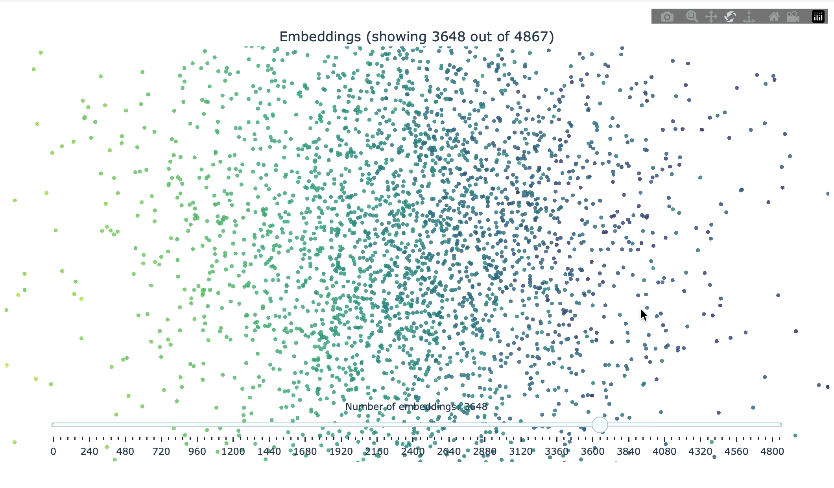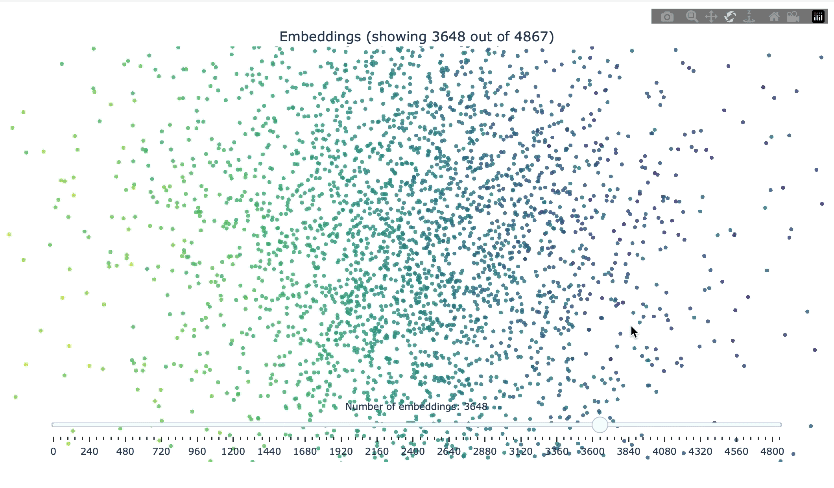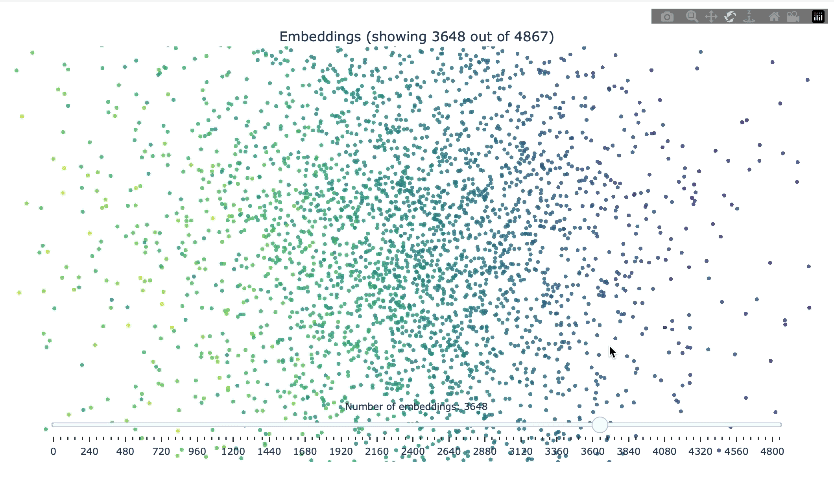
### Embeddings visualization
This class provides functionality to load embeddings from a FAISS index, reduce their dimensionality using PCA and/or t-SNE, and visualize them in an interactive 3D plot.
```python
from ragoon import EmbeddingsVisualizer
visualizer = EmbeddingsVisualizer(
index_path="path/to/index",
dataset_path="path/to/dataset"
)
visualizer.visualize(
method="pca",
save_html=True,
html_file_name="embedding_visualization.html"
)
```
### Dynamic web search
RAGoon is a Python library that aims to improve the performance of language models by providing contextually relevant information through retrieval-based querying, web scraping, and data augmentation techniques. It integrates various APIs, enabling users to retrieve information from the web, enrich it with domain-specific knowledge, and feed it to language models for more informed responses.
RAGoon's core functionality revolves around the concept of few-shot learning, where language models are provided with a small set of high-quality examples to enhance their understanding and generate more accurate outputs. By curating and retrieving relevant data from the web, RAGoon equips language models with the necessary context and knowledge to tackle complex queries and generate insightful responses.
```python
from groq import Groq
# from openai import OpenAI
from ragoon import WebRAG
# Initialize RAGoon instance
ragoon = WebRAG(
google_api_key="your_google_api_key",
google_cx="your_google_cx",
completion_client=Groq(api_key="your_groq_api_key")
)
# Search and get results
query = "I want to do a left join in Python Polars"
results = ragoon.search(
query=query,
completion_model="Llama3-70b-8192",
max_tokens=512,
temperature=1,
)
# Print results
print(results)
```
## Badge
Building something cool with RAGoon? Consider adding a badge to your project card.
```markdown
[ ](https://github.com/louisbrulenaudet/ragoon)
](https://github.com/louisbrulenaudet/ragoon)
```
[](https://github.com/louisbrulenaudet/ragoon)
## Citing this project
If you use this code in your research, please use the following BibTeX entry.
```BibTeX
@misc{louisbrulenaudet2024,
author = {Louis Brulé Naudet},
title = {RAGoon : High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing},
howpublished = {\url{https://github.com/louisbrulenaudet/ragoon}},
year = {2024}
}
```
## Feedback
If you have any feedback, please reach out at [louisbrulenaudet@icloud.com](mailto:louisbrulenaudet@icloud.com).