Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/lovelessless99/Just-In-Time-Compiler
https://github.com/lovelessless99/Just-In-Time-Compiler
Last synced: 3 days ago
JSON representation
- Host: GitHub
- URL: https://github.com/lovelessless99/Just-In-Time-Compiler
- Owner: lovelessless99
- Created: 2021-05-04T11:36:49.000Z (over 3 years ago)
- Default Branch: master
- Last Pushed: 2022-05-11T14:27:44.000Z (over 2 years ago)
- Last Synced: 2024-08-02T07:01:57.667Z (3 months ago)
- Language: C
- Size: 302 KB
- Stars: 17
- Watchers: 4
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Just In Time Compiler
## 想看本 JIT compiler 專案美美的教學請到 [網頁好讀版](https://lovelessless99.github.io/coding-hub/)😀
在本篇文章,先對本專案的進行一個簡介,介紹每一個 Part 的目的,並且介紹編譯器跟及時編譯器的目前技術發展,最後以 javascript 為例解釋及時編譯技術。
# 一、專案說明
大家有沒有看過電影小姐好白,真的是我超愛的喜劇😆,百看不膩,在戲裡面,兩個黑人警探假扮兩個千金大小姐,布蘭妮威爾森跟蒂芬妮威爾森,裡面有個橋段
|布蘭妮威爾森|蒂芬妮威爾森|
|---|---|
|||
就用這個 BF 拉開本專案的序幕,BF 有三種意思
* Bitch Fit 女生抓狂
* Boyfriend 男朋友
* Brainfuck 程式語言,本專案的主角
回到正題,事實上,Brainfuck 語言短小精幹,是個圖靈完全的程式語言,然而可讀性極差,真的是會讓人 Bitch Fit,然而語法操作的簡單很適合拿來被我們拿來當作編譯器、及時編譯器的來源語言。經過本專案一步步的實作,由 JIT compiler 的牽線,讓 Brainfuck 語言從令人 Bitch Fit 變成我們的 Boyfriend,迫不及待了嗎 ? 接下來就是本專案的主題簡介。
|Part|主題|說明|
|----|----|----|
|1| Simple JIT| 利用 Dynasm 幫助建立簡單的 JIT |
|2| BF compiler| 建立簡單的 Brainfuck compiler 和 interpreter |
|3| BF compiler interpreter comparison| 比較 Brainfuck compiler interpreter 和 編譯器最佳化比較 |
|4| BF optimization| 直譯器最佳化、實作及時編譯器 |
|5| Cross comparison| 將所有的程式做一次性的結果探討 |
# 二、Why Compiler ?
1. 為什麼需要編譯器 ? 為了更快、更有效率的使用硬體,如 CPU、GPU等,也希望程式碼可以跑在不同硬體平台上
2. 哪裡有編譯器的影子 ? 到處都是。如 Google V8, Pypy, Flacc, Java, .NET, Android ART, OpenGL ([where to find compiler](http://slide.logan.tw/compiler-intro/#/4/2))
3. LLVM 編譯器框架,因為統一了 IR 以及對 IR 的優化,再也不用因為執行平台的不同要花大量時間重新設計,可以幫助我們快速建立一個 Compiler,現在很多編譯器都使用 LLVM 開發,LLVM 也有豐富的編譯輸出 (ARM, x86, Alpha, PowerPC),LLVM的出現,讓不同的前端后端使用統一的LLVM IR ,如果需要支持新的程式語言或者新的設備平台,只需要開發對應的前端和後端即可。同時基於LLVM IR我們可以很快的開發自己的程式語言。
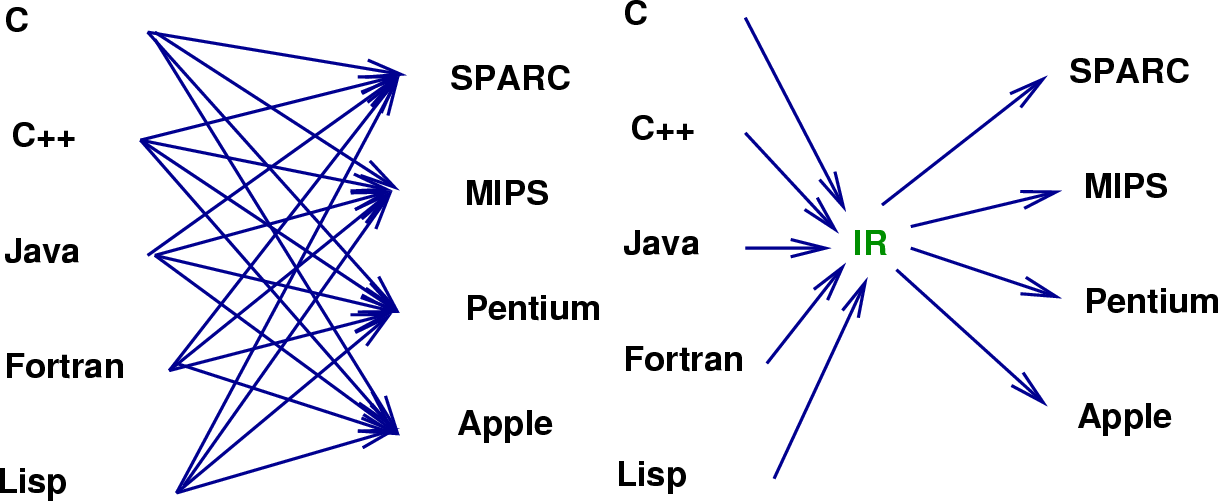
也因此,**LLVM統一的IR是它成功的關鍵之一,也充分說明了一個優秀IR的重要性**。IR可以說是一種膠水語言,注重邏輯而去掉了平台相關的各種特性,這樣為了支持一種新語言或新硬體都會非常方便

4. 根據[此篇文章](https://zhuanlan.zhihu.com/p/65452090)提到有限的精力跟無限的算力,深度學習編譯技術才會越來越重要,人會特定去最佳化某些算子(卷積),而不一定適用網路的每一層。但深度學習編譯器可以幫助我們進行針對網路的每一層進行最佳化,通過(接近無限)的算力去適配每一個應用場景看到的網絡,這是深度學習編譯器比人工路線強的地方。**編譯器可以達到更多的自動化**,以下節錄至該文章
>當比較TVM和傳統方法的時候的時候,我們往往會發現:在標準的benchmark(如imagenet resnet)上,編譯帶來的提升可能只在10%到20%,但是一旦模型相對不標準化(如最近的OctConv,Deformable,甚至是同樣的resnet不同的輸入尺寸),編譯技術可以帶來的提升會非常巨大。原因也非常簡單,有限的精力使得參與優化的人往往關注有限的公開標準benchmark,但是我們的部署目標往往並非這些benchmark,自動化可以無差別地對我們關心的場景進行特殊優化。接近無限的算力和有限的精力的差別正是為什麼編譯技術一定會越來越重要的原因。
另外,一個較新的技術 - TVM,引入 `graph compiler`,將深度學習的模型轉成 graph IR,對 IR 進行最佳化後,可以跑在如手機這種硬體資源較低的移動式裝置(當然會捨棄精度減少計算量,在精度和效率之間進行取捨)。和傳統編譯器不同的是,這類編譯器不光要解決跨平台,還有解決對神經網絡本身的最佳化問題,這樣原先一層的IR就顯得遠遠不夠,原因在於如果設計一個方便硬件最佳化的低階的語言,你幾乎很難從中推理一些神經網路中高階的概念進行最佳化
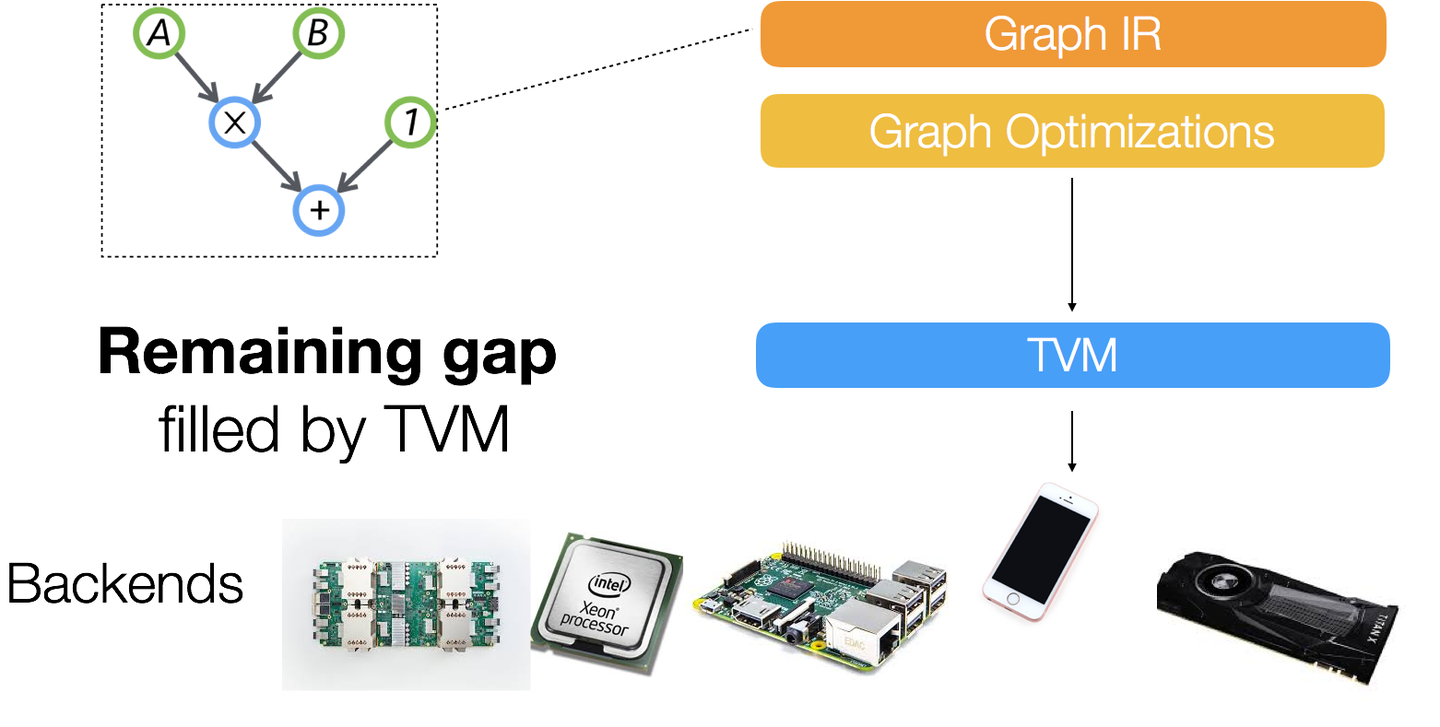
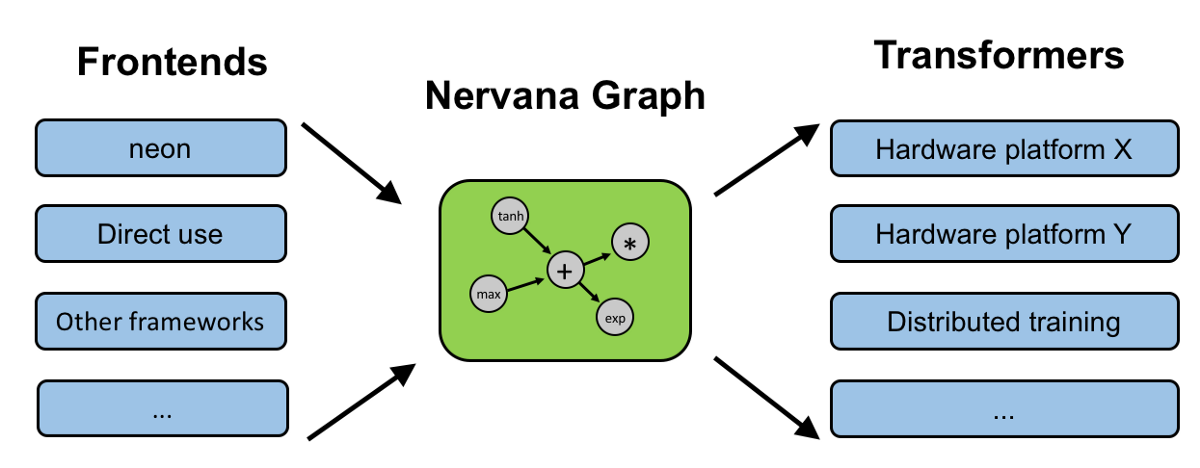
另外TVM的對手,XLA(加速線性代數)是針對線性代數的特定領域編譯器,可優化TensorFlow計算。結果是在服務器和移動平台上提高了速度,記憶體使用率和可移植性。
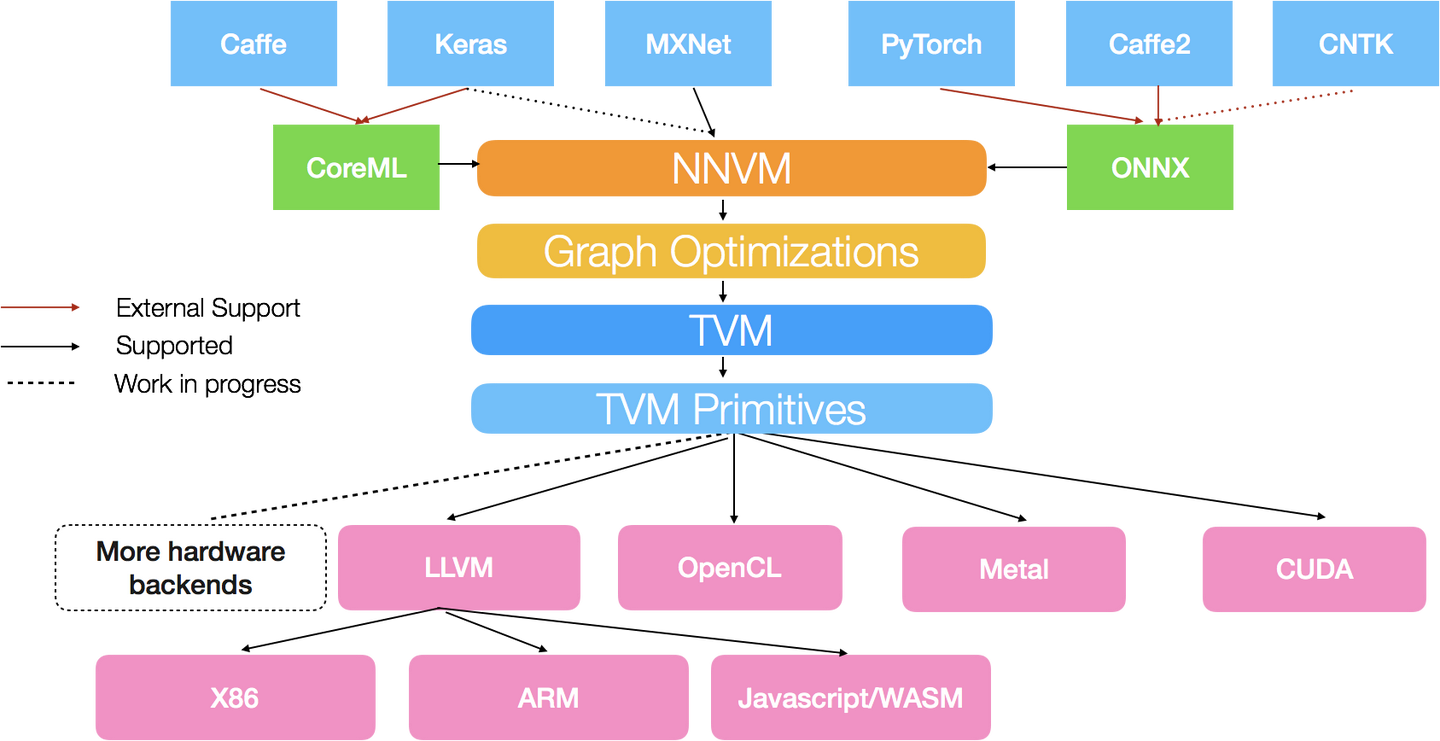
總結來說,因為根據摩爾定律,硬體晶片效能約每隔兩年便會增加一倍,但是近來計算能力的需求爆炸性的增加,例如深度學習,以及計算機架構的多樣性,摩爾定律逐漸跟不上計算能力的需求,所以我們需要編譯器,針對有限資源的硬體及架構產出最佳化、效率最高的程式碼
# 三、Compiler Language vs Interpreter Language
> [參考連結](https://github.com/yaofly2012/note/issues/193)
跟據翻譯的方式,分為編譯器和直譯器,以下為兩者比較
| | 編譯器 | 直譯器 |
|-----|--------| --------|
|執行| 要先編譯再執行| 不用事先編譯 |
|啟動| 慢 (要等編譯) | 快(不用事先編譯) |
|執行效率| 快,編譯時還可以事先優化 | 慢 |
| 重編譯 | 不用 | 每次啟動都要重編譯 |
| 跨平台 | 差,換平台需要重編譯 | 好 |
| 示意圖| | |
另外像 JVM,在 編譯 和 直譯 之間做一個取捨
1. 先編譯成中間文件 ( Bytecode)
2. 再直譯執行,並搭配 JIT compiler 的 runtime 優化
# 四、Just-in-time Compiler : 以 Javascript 為例
JIT Compiler 引入,使我們可以達到動態編譯的技術,以下以 Javascript 為例,這裡參考
[A crash course in just-in-time (JIT) compilers](https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/)


先參照下列表格
| |Baseline compiler|Optimizing compiler|
|-----|---------------|--------------------|
| 編譯,優化單位 | 程式碼行(stub) | 函數 |
| 編譯花費時間 | 短 | 長 |
| 程式碼是否最佳化 | 否 | 是 |

如上圖,JIT 會有一個監視者(monitor/profiler),會監控程式碼執行的次數以及型別的使用

如上圖當程式碼開始"暖"起來,Baseline compiler 就會開始做事,根據[此篇問答](https://stackoverflow.com/questions/59638327/what-is-a-baseline-compiler)
>baseline compiler is to generate bytecode or machine code as fast as possible. This output code (machine code or intermediate code) however is not very optimized for a processor, hence it's very inefficient and slow in runtime.
baseline compiler 盡快幫我們產生 bytecode 或是 machine code,baseline compiler 會把**函數的每一行編譯成一個 stub**,換言之,是以函數的每一行為編譯單位,這些 stub 會被行號以及`變數型別`索引。如果監控者看到同樣的程式碼再出現一遍而且型別相同,就會把剛剛編譯過的程式碼直接丟回去執行,不用重編譯。可以加速執行時間。然而,baseline compiler 可能會做一點點最佳化處理,但是又不想耽誤執行時間太久,因此這些 code 並不是真正最佳化的code。頂多算是稍微好的code,但是執行效率仍然不夠好。
然而,如果這段程式碼真的很"燙(hot)",甚至占了大多數執行時間,那就非常有必要花費額外時間去做最佳化處理。

如上圖,上圖左邊是 baseline compiler 編譯好的程式碼(那些像白紙的東西),不過如果這段程式碼真的很"燙(hot)",monitor 會把這段程式碼送去 Optimizing compiler,產生出更高效能的程式碼。但是編譯時需要符合某個假設,那就是物件一致性。舉個例子,因為 javascript 是動態語言,可以在一個陣列裡面裝不同型別的物件,可能前 99 個物件都是房子,最後一個物件卻是怪物☢,所以 compiled code 在跑之前需要確定好假設是正確的,如果是對的,就跑這個 code,如果突然變怪物,那就會把這段最佳化的程式碼給丟掉💔,然後去跑 baseline compiled 版本,這個丟掉optimize 返回baseline過程稱為 **解最佳化或反優化(deoptimization)**
雖然 Optimizing compiler 可以產生出更高效能的程式碼,但是可能會造成不可預期的效能問題,假設有個陣列有100個物件,這裡用虛擬碼宣告
```
[ 房子 * 9 + 怪物 * 1 ] * 10
```
當執行到第九次房子,監控者認為很熱時,送去最佳化編譯,但下一個遇到不符合假設的怪物物件,馬上又丟掉這段最佳化程式碼。這樣反覆最佳化 - 解最佳化,會嚴重影響到效能,那還不如乾脆執行 baseline compile 的程式碼就好,因此大部分的瀏覽器都會限制這段反覆次數,假設來回最佳化超過10次,就乾脆不最佳化💔
[A crash course in just-in-time (JIT) compilers](https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/)舉一個例子,Type specialization 看看簡單的程式碼背後的原理卻一大堆哲學,由於javascript 是動態弱型別語言,所以在執行時間時需要多做更多工作
```javascript
function arraySum(arr) {
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}
```
`+=` 看起來一個動作就好,感覺蠻簡單的,但是因為是動態型別,實際上背後偷偷執行更多東西,像是因為javascript是弱型別語言,javascript 允許字串和整數相加,例如
``` javascript
var a = 123 + '456'
// a is '123456'
```
`sum += arr[i]`,可能前 99 個都是整數,但是最後一個就是字串,導致剛剛最佳化程式碼不能用要捨棄,因為從整數的相加變成字串的相加,兩者的運算有本質上的不同。所以 JIT 會看這段 stub 是 monomorphic(不變的) 或是 polymorphic(變動的) (型別是否都相同)。如下圖


假設沒有 Optimizing compiler,當這段code 要執行時,JIT 就要不斷檢查這些型別問題,在一個迴圈下,必須要不斷重複檢查審視這些問題,但其實可以加速執行,就出現
Optimizing compiler,compiler 只需要把整段函數編譯,每次執行時都先檢查`arr[i]`的型別即可,**根本不用每一行都檢查型別**,如下圖

而火狐瀏覽器有做最佳化的處理,例如JIT再進入迴圈前會預先判斷是否整個陣列是整數型,減輕判斷時的負擔。
# 參考連結
1. [Deep Learning的IR之爭](https://zhuanlan.zhihu.com/p/29254171)
2. [JS 及時編譯器 Just-In-Time (JIT) compilers](https://github.com/yaofly2012/note/issues/193)
3. [What Can Compilers Do for Us?](https://www.slideshare.net/jserv/what-can-compilers-do-for-us/16-LLVM)
4. [為什麼這麼多人喜歡寫編譯器?](https://www.zhihu.com/question/39304476)
5. [虛擬機器設計與實作](https://hackmd.io/@sysprog/SkBsZoReb?type=view)
6. [深度學習編譯技術的現狀和未來](https://zhuanlan.zhihu.com/p/65452090)
7. [深度學習編譯器學習筆記和實踐體會 (好專欄!) ](https://www.zhihu.com/column/c_1169609848697663488)
8. [Jserv 演講- 窮得只剩下 compiler](https://www.slideshare.net/jserv/what-can-compilers-do-for-us)
9. [A crash course in just-in-time (JIT) compilers](https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/)
10. [What is a baseline compiler?](https://stackoverflow.com/questions/59638327/what-is-a-baseline-compiler)