https://github.com/lukashedegaard/continual-inference
A Python library for Continual Inference Networks in PyTorch
https://github.com/lukashedegaard/continual-inference
cnn continual-inference convolutional-neural-networks deep-learning deep-neural-networks efficiency machine-learning neural-networks pytorch recurrent-neural-network
Last synced: about 1 year ago
JSON representation
A Python library for Continual Inference Networks in PyTorch
- Host: GitHub
- URL: https://github.com/lukashedegaard/continual-inference
- Owner: LukasHedegaard
- Created: 2021-08-09T10:30:15.000Z (almost 5 years ago)
- Default Branch: main
- Last Pushed: 2025-03-15T11:39:15.000Z (over 1 year ago)
- Last Synced: 2025-03-29T23:08:22.666Z (about 1 year ago)
- Topics: cnn, continual-inference, convolutional-neural-networks, deep-learning, deep-neural-networks, efficiency, machine-learning, neural-networks, pytorch, recurrent-neural-network
- Language: Python
- Homepage:
- Size: 1.96 MB
- Stars: 49
- Watchers: 3
- Forks: 11
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
README

__A Python library for Continual Inference Networks in PyTorch__
[Quick-start](https://continual-inference.readthedocs.io/en/latest/generated/README.html#quick-start) •
[Docs](https://continual-inference.readthedocs.io/en/latest/generated/README.html) •
[Principles](https://continual-inference.readthedocs.io/en/latest/generated/README.html#library-principles) •
[Paper](https://arxiv.org/abs/2204.03418) •
[Examples](https://continual-inference.readthedocs.io/en/latest/generated/README.html#composition-examples) •
[Modules](https://continual-inference.readthedocs.io/en/latest/common/modules.html) •
[Model Zoo](https://continual-inference.readthedocs.io/en/latest/generated/README.html#model-zoo-and-benchmarks) •
[Contribute](https://continual-inference.readthedocs.io/en/latest/generated/CONTRIBUTING.html) •
[License](https://github.com/LukasHedegaard/continual-inference/blob/main/LICENSE)








## Continual Inference Networks ensure efficient stream processing
Many of our favorite Deep Neural Network architectures (e.g., [CNNs](https://arxiv.org/abs/2106.00050) and [Transformers](https://arxiv.org/abs/2201.06268)) were built with offline-processing for offline processing. Rather than processing inputs one sequence element at a time, they require the whole (spatio-)temporal sequence to be passed as a single input.
Yet, **many important real-life applications need online predictions on a continual input stream**.
While CNNs and Transformers can be applied by re-assembling and passing sequences within a sliding window, this is _inefficient_ due to the redundant intermediary computations from overlapping clips.
**Continual Inference Networks** (CINs) are built to ensure efficient stream processing by employing an alternative computational ordering, which allows sequential computations without the use of sliding window processing.
In general, CINs requires approx. _L_ × fewer FLOPs per prediction compared to sliding window-based inference with non-CINs, where _L_ is the corresponding sequence length of a non-CIN network. For more details, check out the videos below describing Continual 3D CNNs [[1](https://arxiv.org/abs/2106.00050)] and Transformers [[2](https://arxiv.org/abs/2201.06268)].
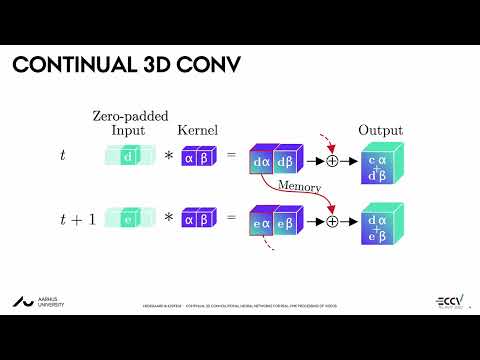

## News
- 2022-12-02: ONNX compatibility for all modules is available from v1.0.0. See [test_onnx.py](tests/continual/test_onnx.py) for examples.
## Quick-start
### Install
```bash
pip install continual-inference
```
### Example
`co` modules are weight-compatible drop-in replacement for `torch.nn`, enhanced with the capability of efficient _continual inference_:
```python3
import torch
import continual as co
# B, C, T, H, W
example = torch.randn((1, 1, 5, 3, 3))
conv = co.Conv3d(in_channels=1, out_channels=1, kernel_size=(3, 3, 3))
# Same exact computation as torch.nn.Conv3d ✅
output = conv(example)
# But can also perform online inference efficiently 🚀
firsts = conv.forward_steps(example[:, :, :4])
last = conv.forward_step(example[:, :, 4])
assert torch.allclose(output[:, :, : conv.delay], firsts)
assert torch.allclose(output[:, :, conv.delay], last)
# Temporal properties
assert conv.receptive_field == 3
assert conv.delay == 2
```
See the [network composition](#composition) and [model zoo](#model-zoo-and-benchmarks) sections for additional examples.
## Library principles
### Forward modes
The library components feature three distinct forward modes, which are handy for different situations, namely `forward`, `forward_step`, and `forward_steps`:
#### `forward(input)`
Performs a forward computation over multiple time-steps. This function is identical to the corresponding module in _torch.nn_, ensuring cross-compatibility. Moreover, it's handy for efficient training on clip-based data.
```
O (O: output)
↑
N (N: network module)
↑
----------------- (-: aggregation)
P I I I P (I: input frame, P: padding)
```
#### `forward_step(input, update_state=True)`
Performs a forward computation for a single frame and (optionally) updates internal states accordingly. This function performs efficient continual inference.
```
O+S O+S O+S O+S (O: output, S: updated internal state)
↑ ↑ ↑ ↑
N N N N (N: network module)
↑ ↑ ↑ ↑
I I I I (I: input frame)
```
#### `forward_steps(input, pad_end=False, update_state=True)`
Performs a forward computation across multiple time-steps while updating internal states for continual inference (if update_state=True).
Start-padding is always accounted for, but end-padding is omitted per default in expectance of the next input step. It can be added by specifying pad_end=True. If so, the output-input mapping the exact same as that of forward.
```
O (O: output)
↑
----------------- (-: aggregation)
O O+S O+S O+S O (O: output, S: updated internal state)
↑ ↑ ↑ ↑ ↑
N N N N N (N: network module)
↑ ↑ ↑ ↑ ↑
P I I I P (I: input frame, P: padding)
```
#### `__call__`
Per default, the `__call__` function operates identically to _torch.nn_ and executes forward. We supply two options for changing this behavior, namely the _call_mode_ property and the _call_mode_ context manager. An example of their use follows:
```python
timeseries = torch.randn(batch, channel, time)
timestep = timeseries[:, :, 0]
net(timeseries) # Invokes net.forward(timeseries)
# Assign permanent call_mode property
net.call_mode = "forward_step"
net(timestep) # Invokes net.forward_step(timestep)
# Assign temporary call_mode with context manager
with co.call_mode("forward_steps"):
net(timeseries) # Invokes net.forward_steps(timeseries)
net(timestep) # Invokes net.forward_step(timestep) again
```
### Composition
Continual Inference Networks require strict handling of internal data delays to guarantee correspondence between [forward modes](#forward-modes). While it is possible to compose neural networks by defining _forward_, _forward_step_, and _forward_steps_ manually, correct handling of delays is cumbersome and time-consuming. Instead, we provide a rich interface of container modules, which handles delays automatically. On top of `co.Sequential` (which is a drop-in replacement of _torch.nn.Sequential_), we provide modules for handling parallel and conditional dataflow.
- [`co.Sequential`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Sequential.html): Invoke modules sequentially, passing the output of one module onto the next.
- [`co.Broadcast`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Broadcast.html): Broadcast one stream to multiple.
- [`co.Parallel`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Parallel.html): Invoke modules in parallel given each their input.
- [`co.ParallelDispatch`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.ParallelDispatch.html): Dispatch multiple input streams to multiple output streams flexibly.
- [`co.Reduce`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Reduce.html): Reduce multiple input streams to one.
- [`co.BroadcastReduce`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.BroadcastReduce.html): Shorthand for Sequential(Broadcast, Parallel, Reduce).
- [`co.Residual`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Residual.html): Residual connection.
- [`co.Conditional`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Conditional.html): Conditionally checks whether to invoke a module (or another) at runtime.
#### Composition examples:
Residual module
Short-hand:
```python3
residual = co.Residual(co.Conv3d(32, 32, kernel_size=3, padding=1))
```
Explicit:
```python3
residual = co.Sequential(
co.Broadcast(2),
co.Parallel(
co.Conv3d(32, 32, kernel_size=3, padding=1),
co.Delay(2),
),
co.Reduce("sum"),
)
```
3D MobileNetV2 Inverted residual block
Continual 3D version of the [MobileNetV2 Inverted residual block](https://arxiv.org/pdf/1801.04381.pdf).
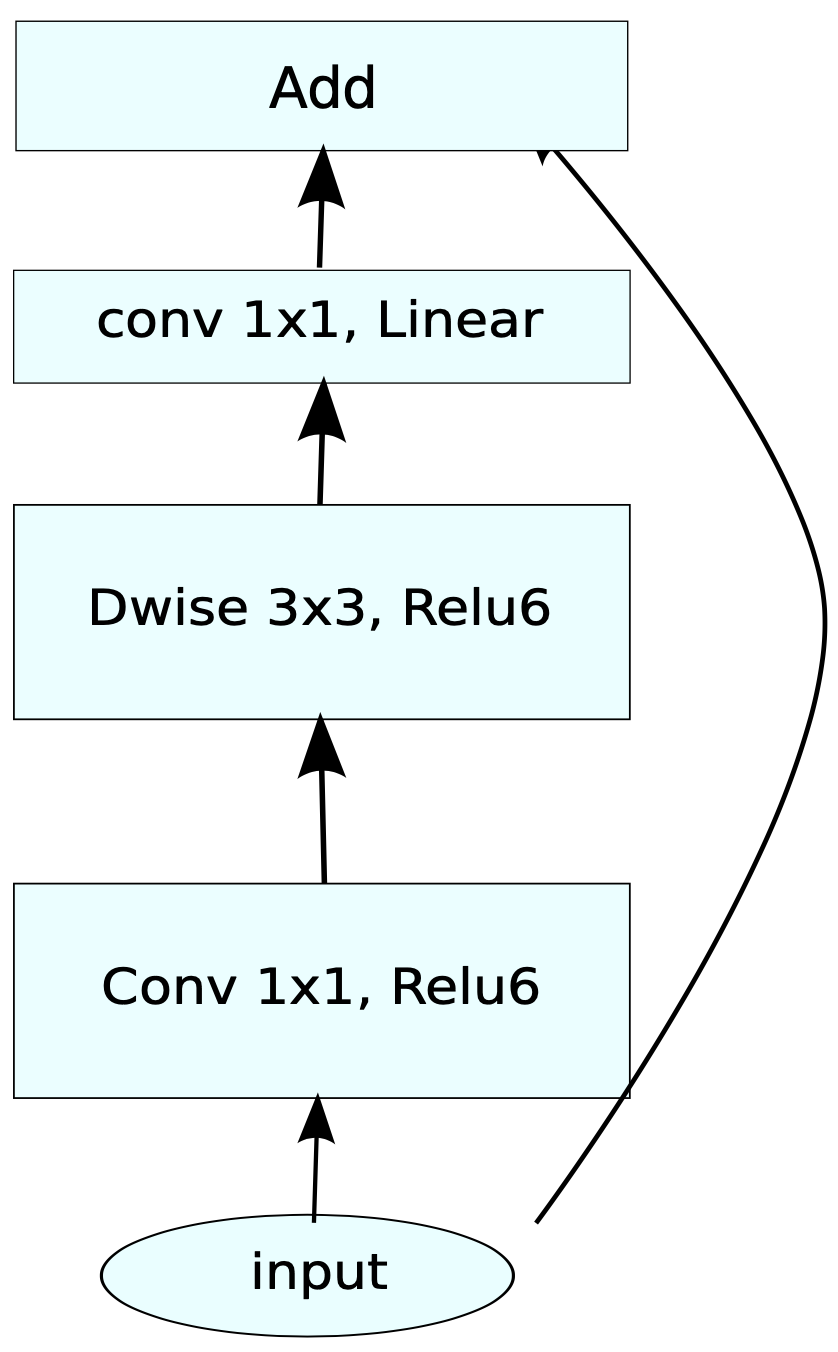
MobileNetV2 Inverted residual block. Source: https://arxiv.org/pdf/1801.04381.pdf
```python3
mb_conv = co.Residual(
co.Sequential(
co.Conv3d(32, 64, kernel_size=(1, 1, 1)),
nn.BatchNorm3d(64),
nn.ReLU6(),
co.Conv3d(64, 64, kernel_size=(3, 3, 3), padding=(1, 1, 1), groups=64),
nn.ReLU6(),
co.Conv3d(64, 32, kernel_size=(1, 1, 1)),
nn.BatchNorm3d(32),
)
)
```
3D Squeeze-and-Excitation module
Continual 3D version of the [Squeeze-and-Excitation module](https://arxiv.org/pdf/1709.01507.pdf)
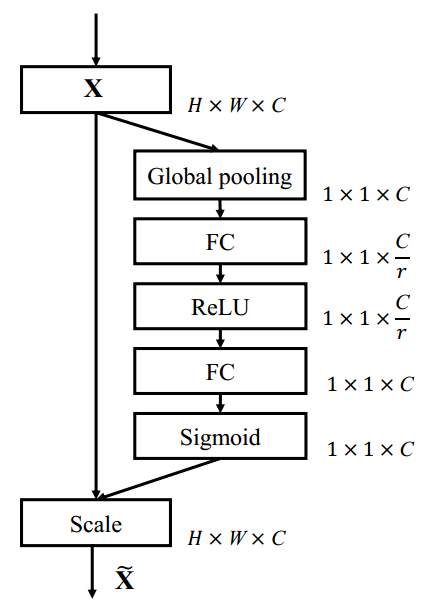
Squeeze-and-Excitation block.
Scale refers to a broadcasted element-wise multiplication.
Adapted from: https://arxiv.org/pdf/1709.01507.pdf
```python3
se = co.Residual(
co.Sequential(
OrderedDict([
("pool", co.AdaptiveAvgPool3d((1, 1, 1), kernel_size=7)),
("down", co.Conv3d(256, 16, kernel_size=1)),
("act1", nn.ReLU()),
("up", co.Conv3d(16, 256, kernel_size=1)),
("act2", nn.Sigmoid()),
])
),
reduce="mul",
)
```
3D Inception module
Continual 3D version of the [Inception module](https://arxiv.org/pdf/1409.4842v1.pdf):
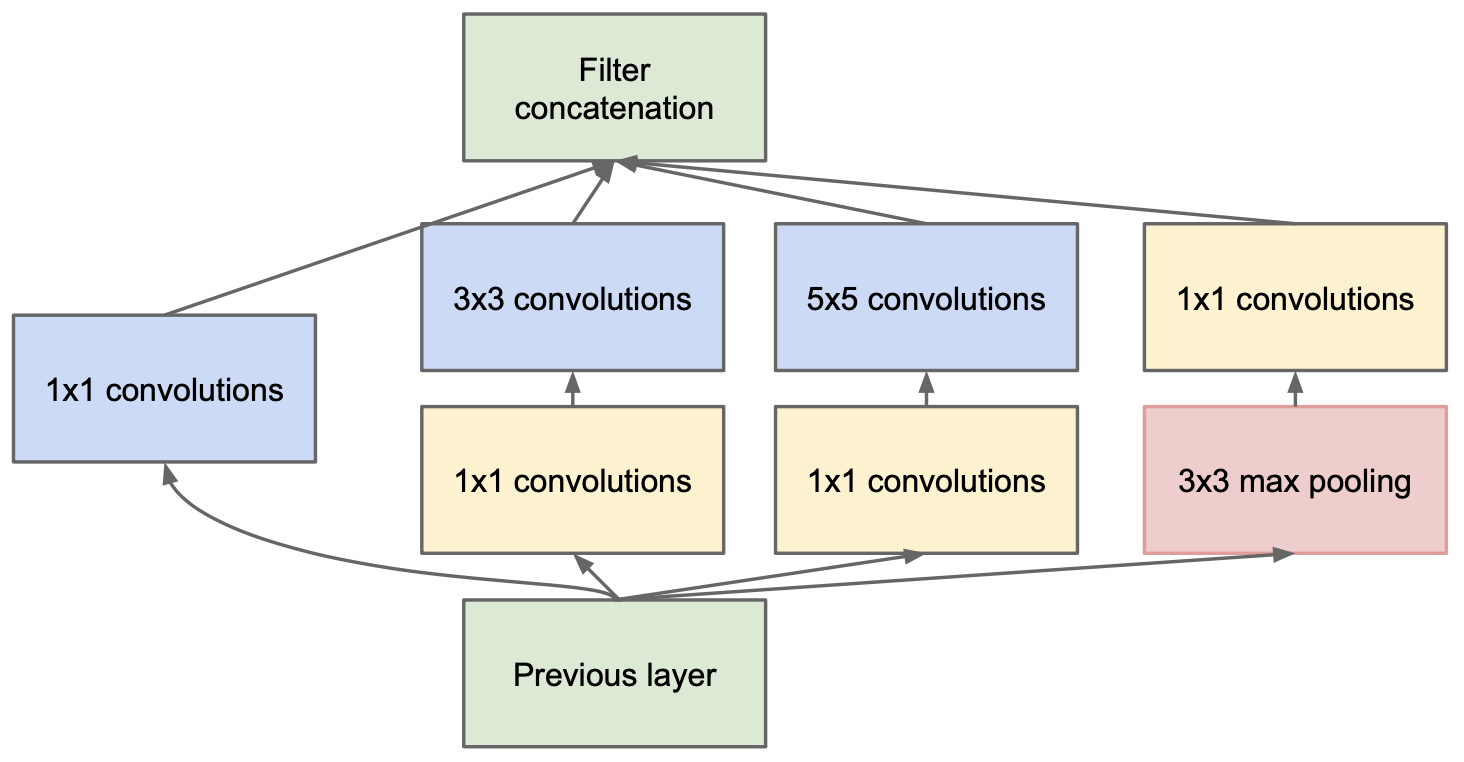
Inception module. Source: https://arxiv.org/pdf/1409.4842v1.pdf
```python3
def norm_relu(module, channels):
return co.Sequential(
module,
nn.BatchNorm3d(channels),
nn.ReLU(),
)
inception_module = co.BroadcastReduce(
co.Conv3d(192, 64, kernel_size=1),
co.Sequential(
norm_relu(co.Conv3d(192, 96, kernel_size=1), 96),
norm_relu(co.Conv3d(96, 128, kernel_size=3, padding=1), 128),
),
co.Sequential(
norm_relu(co.Conv3d(192, 16, kernel_size=1), 16),
norm_relu(co.Conv3d(16, 32, kernel_size=5, padding=2), 32),
),
co.Sequential(
co.MaxPool3d(kernel_size=(1, 3, 3), padding=(0, 1, 1), stride=1),
norm_relu(co.Conv3d(192, 32, kernel_size=1), 32),
),
reduce="concat",
)
```
### Input shapes
We enforce a unified ordering of input dimensions for all library modules, namely:
(batch, channel, time, optional_dim2, optional_dim3)
### Outputs
The outputs produces by `forward_step` and `forward_steps` are identical to those of `forward`, provided the same data was input beforehand and state update was enabled. We know that input and output shapes aren't necessarily the same when using `forward` in the PyTorch library, and generally depends on padding, stride and receptive field of a module.
For the `forward_step` function, this comes to show by some `None`-valued outputs. Specifically, modules with a _delay_ (i.e. with receptive fields larger than the padding + 1) will produce `None` until the input count exceeds the delay. Moreover, _stride_ > 1 will produce `Tensor` outputs every _stride_ steps and `None` the remaining steps. A visual example is shown below:
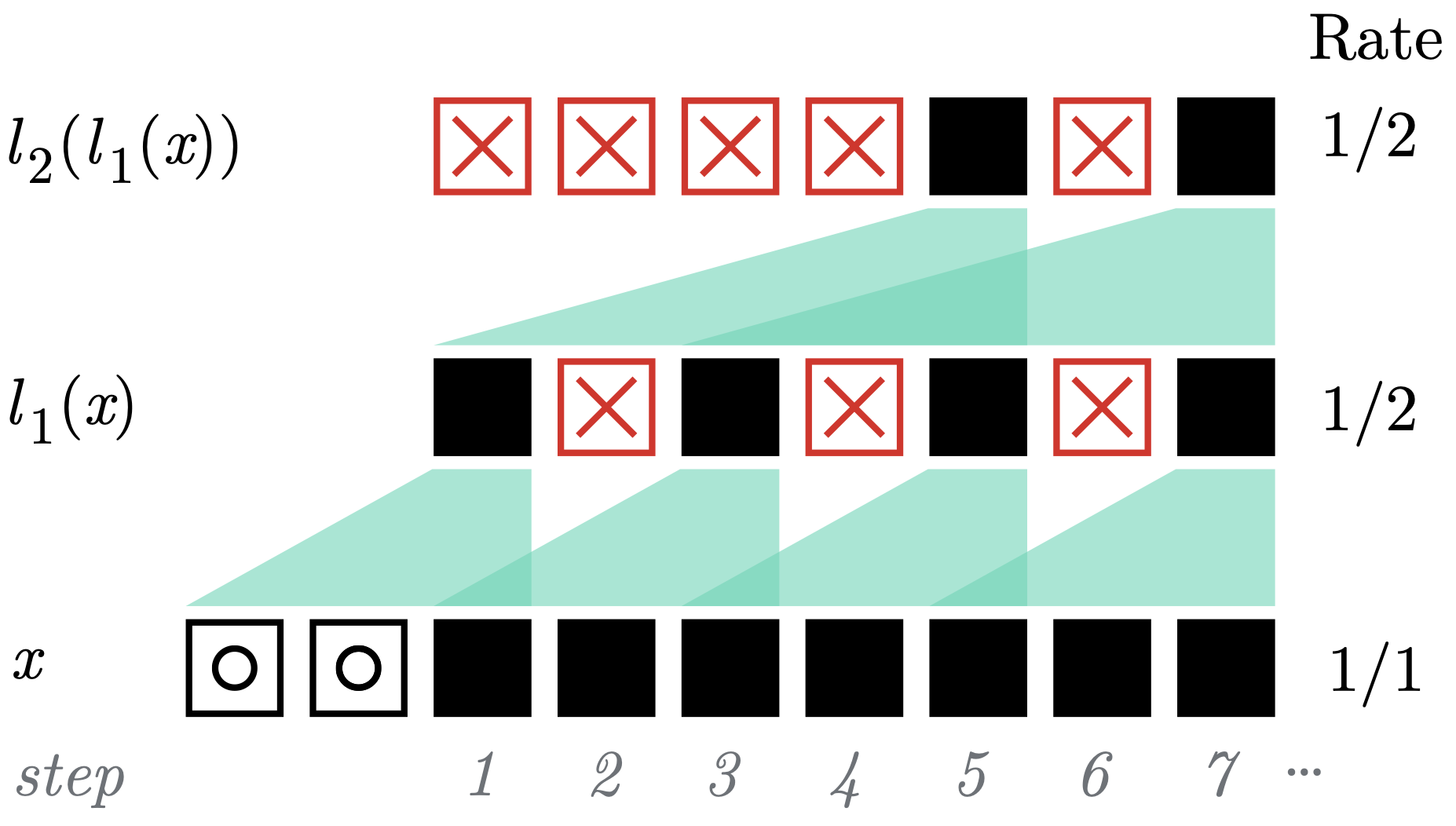
A mixed example of delay and outputs under padding and stride. Here, we illustrate the step-wise operation of two co module layers, l1 with with receptive_field = 3, padding = 2, and stride = 2 and l2 with receptive_field = 3, no padding and stride = 1. ⧇ denotes a padded zero, ■ is a non-zero step-feature, and ☒ is an empty output.
For more information, please see the [library paper](https://arxiv.org/abs/2204.03418).
### Handling state
During stream processing, network modules which operate over multiple time-steps, e.g., a convolution with `kernel_size > 1` in the temporal dimension, will aggregate and cache state internally. Each module has its own local state, which can be inspected using `module.get_state()`. During `forward_step` and `forward_steps`, the state is updated unless the forward_step(s) is invoked with an `update_state = False` argument.
A __state cleanup__ can be accomplished via `module.clean_state()`.
## Module library
_Continual Inference_ features a rich collection of modules for defining Continual Inference Networks. Specific care was taken to create CIN versions of the PyTorch modules found in [_torch.nn_](https://pytorch.org/docs/stable/nn.html):
Convolutions
- [`co.Conv1d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Conv1d.html)
- [`co.Conv2d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Conv2d.html)
- [`co.Conv3d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Conv3d.html)
Pooling
- [`co.AvgPool1d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AvgPool1d.html)
- [`co.AvgPool2d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AvgPool2d.html)
- [`co.AvgPool3d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AvgPool3d.html)
- [`co.MaxPool1d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.MaxPool1d.html)
- [`co.MaxPool2d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.MaxPool2d.html)
- [`co.MaxPool3d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.MaxPool3d.html)
- [`co.AdaptiveAvgPool2d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AdaptiveAvgPool2d.html)
- [`co.AdaptiveAvgPool3d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AdaptiveAvgPool3d.html)
- [`co.AdaptiveMaxPool2d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AdaptiveMaxPool2d.html)
- [`co.AdaptiveMaxPool3d`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.AdaptiveMaxPool3d.html)
Linear
- [`co.Linear`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Linear.html)
- [`co.Identity`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Identity.html): Maps input to output without modification.
- [`co.Add`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Add.html): Adds a constant value.
- [`co.Multiply`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Multiply.html): Multiplies with a constant factor.
Recurrent
- [`co.RNN`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.RNN.html)
- [`co.LSTM`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.LSTM.html)
- [`co.GRU`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.GRU.html)
Transformers
- [`co.TransformerEncoder`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.TransformerEncoder.html)
- [`co.TransformerEncoderLayerFactory`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.TransformerEncoderLayerFactory.html): Factory function corresponding to `nn.TransformerEncoderLayer`.
- [`co.SingleOutputTransformerEncoderLayer`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.SingleOutputTransformerEncoderLayer.html): SingleOutputMHA version of `nn.TransformerEncoderLayer`.
- [`co.RetroactiveTransformerEncoderLayer`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.RetroactiveTransformerEncoderLayer.html): RetroactiveMHA version of `nn.TransformerEncoderLayer`.
- [`co.RetroactiveMultiheadAttention`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.retroactive_mha.html.RetroactiveMultiheadAttention): Retroactive version of `nn.MultiheadAttention`.
- [`co.SingleOutputMultiheadAttention`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.single_output_mha.html.SingleOutputMultiheadAttention): Single-output version of `nn.MultiheadAttention`.
- [`co.RecyclingPositionalEncoding`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.RecyclingPositionalEncoding.html): Positional Encoding used for Continual Transformers.
Modules for composing and converting networks. Both _composition_ and _utility_ modules can be used for regular definition of PyTorch modules as well.
Composition modules
- [`co.Sequential`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Sequential.html): Invoke modules sequentially, passing the output of one module onto the next.
- [`co.Broadcast`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Broadcast.html): Broadcast one stream to multiple.
- [`co.Parallel`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Parallel.html): Invoke modules in parallel given each their input.
- [`co.ParallelDispatch`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.ParallelDispatch.html): Dispatch multiple input streams to multiple output streams flexibly.
- [`co.Reduce`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Reduce.html): Reduce multiple input streams to one.
- [`co.BroadcastReduce`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.BroadcastReduce.html): Shorthand for Sequential(Broadcast, Parallel, Reduce).
- [`co.Residual`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Residual.html): Residual connection.
- [`co.Conditional`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Conditional.html): Conditionally checks whether to invoke a module (or another) at runtime.
Utility modules
- [`co.Delay`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Delay.html): Pure delay module (e.g. needed in residuals).
- [`co.Skip`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Skip.html): Skip a predefined number of input steps.
- [`co.Reshape`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Reshape.html): Reshape non-temporal dimensions.
- [`co.Lambda`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Lambda.html): Lambda module which wraps any function.
- [`co.Constant`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Constant.html): Maps input to and output with constant value.
- [`co.Zero`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.Zero.html): Maps input to output of zeros.
- [`co.One`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.One.html): Maps input to output of ones.
Converters
- [`co.continual`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.continual.html): conversion function from `torch.nn` modules to `co` modules.
- [`co.forward_stepping`](https://continual-inference.readthedocs.io/en/latest/common/generated/continual.forward_stepping.html): functional wrapper, which enhances temporally local `torch.nn` modules with the forward_stepping functions.
We support drop-in interoperability with with the following _torch.nn_ modules:
Activation
- `nn.Threshold`
- `nn.ReLU`
- `nn.RReLU`
- `nn.Hardtanh`
- `nn.ReLU6`
- `nn.Sigmoid`
- `nn.Hardsigmoid`
- `nn.Tanh`
- `nn.SiLU`
- `nn.Hardswish`
- `nn.ELU`
- `nn.CELU`
- `nn.SELU`
- `nn.GLU`
- `nn.GELU`
- `nn.Hardshrink`
- `nn.LeakyReLU`
- `nn.LogSigmoid`
- `nn.Softplus`
- `nn.Softshrink`
- `nn.PReLU`
- `nn.Softsign`
- `nn.Tanhshrink`
- `nn.Softmin`
- `nn.Softmax`
- `nn.Softmax2d`
- `nn.LogSoftmax`
Normalization
- `nn.BatchNorm1d`
- `nn.BatchNorm2d`
- `nn.BatchNorm3d`
- `nn.GroupNorm`,
- `nn.InstanceNorm1d` (affine=True, track_running_stats=True required)
- `nn.InstanceNorm2d` (affine=True, track_running_stats=True required)
- `nn.InstanceNorm3d` (affine=True, track_running_stats=True required)
- `nn.LayerNorm` (only non-temporal dimensions must be specified)
Dropout
- `nn.Dropout`
- `nn.Dropout1d`
- `nn.Dropout2d`
- `nn.Dropout3d`
- `nn.AlphaDropout`
- `nn.FeatureAlphaDropout`
## Model Zoo and Benchmarks
### Continual 3D CNNs
Benchmark results for 1-view testing on __Kinetics400__. For reference, _X3D-L_ scores 69.3% top-1 acc with 19.2 GFLOPs per prediction.
Arch | Avg. pool size | Top 1 (%) | FLOPs (G) per step | FLOPs reduction | Params (M) | Code | Weights
-------- | -------------- | --------- | ------------------ | --------------- | ---------- | ---------------------------------------------------------------------- | ----
CoX3D-L | 64 | 71.6 | 1.25 | 15.3x | 6.2 | [link](https://github.com/LukasHedegaard/co3d/tree/main/models/cox3d) | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_L.pyth)
CoX3D-M | 64 | 71.0 | 0.33 | 15.1x | 3.8 | [link](https://github.com/LukasHedegaard/co3d/tree/main/models/cox3d) | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_M.pyth)
CoX3D-S | 64 | 64.7 | 0.17 | 12.1x | 3.8 | [link](https://github.com/LukasHedegaard/co3d/tree/main/models/cox3d) | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_S.pyth)
CoSlow | 64 | 73.1 | 6.90 | 8.0x | 32.5 | [link](https://github.com/LukasHedegaard/co3d/tree/main/models/coslow) | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOW\_8x8\_R50.pyth)
CoI3D | 64 | 64.0 | 5.68 | 5.0x | 28.0 | [link](https://github.com/LukasHedegaard/co3d/tree/main/models/coi3d) | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/I3D\_8x8\_R50.pyth)
FLOPs reduction is noted relative to non-continual inference.
Note that [on-hardware inference](https://arxiv.org/abs/2106.00050) doesn't reach the same speedups as "FLOPs reductions" might suggest due to overhead of state reads and writes. This overhead is less important for large batch sizes. This applies to all models in the model zoo.
### Continual ST-GCNs
Benchmark results for on __NTU RGB+D 60__ for the joint modality. For reference, _ST-GCN_ achieves 86% X-Sub and 93.4 X-View accuracy with 16.73 GFLOPs per prediction.
Arch | Receptive field | X-Sub Acc (%) | X-View Acc (%) | FLOPs (G) per step | FLOPs reduction | Params (M) | Code
-------- | --------------- | ------------- | -------------- | ------------------ | --------------- | ---------- | -----
CoST-GCN | 300 | 86.3 | 93.8 | 0.16 | 107.7x | 3.1 | [link](https://github.com/LukasHedegaard/continual-skeletons/blob/main/models/cost_gcn_mod/cost_gcn_mod.py)
CoA-GCN | 300 | 84.1 | 92.6 | 0.17 | 108.7x | 3.5 | [link](https://github.com/LukasHedegaard/continual-skeletons/blob/main/models/coa_gcn_mod/coa_gcn_mod.py)
CoST-GCN | 300 | 86.3 | 92.4 | 0.15 | 107.6x | 3.1 | [link](https://github.com/LukasHedegaard/continual-skeletons/blob/main/models/cos_tr_mod/cos_tr_mod.py)
[Here](https://drive.google.com/drive/u/4/folders/1m6aV5Zv8tAytvxF6qY4m9nyqlkKv0y72), you can download pre-trained,model weights for the above architectures on NTU RGB+D 60, NTU RGB+D 120, and Kinetics-400 on joint and bone modalities.
### Continual Transformers
Benchmark results for on __THUMOS14__ on top of features extracted using a TSN-ResNet50 backbone pre-trained on Kinetics400. For reference, _OadTR_ achieves 64.4 % mAP with 2.5 GFLOPs per prediction.
Arch | Receptive field | mAP (%) | FLOPs (G) per step | Params (M) | Code
---------- | --------------- | ------- | ------------------ | ---------- | -----
CoOadTR-b1 | 64 | 64.2 | 0.41 | 15.9 | [link](https://github.com/LukasHedegaard/CoOadTR)
CoOadTR-b2 | 64 | 64.4 | 0.01 | 9.6 | [link](https://github.com/LukasHedegaard/CoOadTR)
The library features complete implementations of the [one](https://github.com/LukasHedegaard/continual-inference/blob/9895344f50a93ebb5cf5c4f26ecfdf27b6a3fe75/tests/continual/test_transformer.py#L8)- and [two](https://github.com/LukasHedegaard/continual-inference/blob/9895344f50a93ebb5cf5c4f26ecfdf27b6a3fe75/tests/continual/test_transformer.py#L59)-block continual transformer encoders as well.
## Compatibility
The library modules are built to integrate seamlessly with other PyTorch projects.
Specifically, extra care was taken to ensure out-of-the-box compatibility with:
- [pytorch-lightning](https://github.com/PyTorchLightning/pytorch-lightning)
- [ptflops](https://github.com/sovrasov/flops-counter.pytorch)
- [ride](https://github.com/LukasHedegaard/ride)
- [onnx](https://github.com/onnx/onnx)
## Citation

```bibtex
@inproceedings{hedegaard2022colib,
title={Continual Inference: A Library for Efficient Online Inference with Deep Neural Networks in PyTorch},
author={Lukas Hedegaard and Alexandros Iosifidis},
booktitle={European Conference on Computer Vision Workshops (ECCVW)},
year={2022}
}
```
## Acknowledgement
This work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 871449 (OpenDR).