https://github.com/lupantech/dual-mfa-vqa
Co-attending Regions and Detections for VQA.
https://github.com/lupantech/dual-mfa-vqa
aaai attention-mechanism caffe faster-rcnn multi-gpu multi-modal object-detection torch visual-question-answering vqa
Last synced: 5 months ago
JSON representation
Co-attending Regions and Detections for VQA.
- Host: GitHub
- URL: https://github.com/lupantech/dual-mfa-vqa
- Owner: lupantech
- Created: 2017-11-17T12:49:02.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2018-06-02T12:32:43.000Z (about 8 years ago)
- Last Synced: 2025-10-21T22:39:43.694Z (9 months ago)
- Topics: aaai, attention-mechanism, caffe, faster-rcnn, multi-gpu, multi-modal, object-detection, torch, visual-question-answering, vqa
- Language: Matlab
- Homepage:
- Size: 1.44 MB
- Stars: 40
- Watchers: 4
- Forks: 14
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
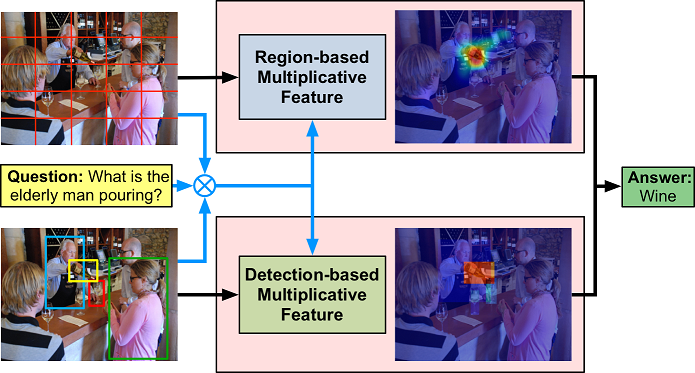
## Dual-MFA-VQA
Co-attending Regions and Detections with Multi-modal Multiplicative Embedding for VQA.
The network has two attention branches with the proposed multiplicative feature embedding scheme: one branch attends free-form image regions, another branch attends detection boxes for encoding question-related visual features.
This current code can get **66.09** on Open-Ended and 69.97 on Multiple-Choice on test-standard split for the VQA 1.0 dataset.
**Spotlights**
- **Paper on arXiv**: https://arxiv.org/abs/1711.06794
- **Bounding box-based attention** with Faster R-CNN pre-trained model
- **Co-attention** with whole image and object detection
- **Multi-modal multiplicative embedding** feature method
- **Torch implementation with multi-GPU acceleration**
### Dependencies
This main part of code is written in Lua and requires [Torch](http://torch.ch/docs/getting-started.html#). After installing torch, you can install these dependencies by running the following:
##### Installing related torch libraries
```
cd ~/torch
luarocks install loadcaffe
luarocks install hdf5
pip install h5py
luarocks install optim
luarocks install nn
luarocks install math
luarocks install image
luarocks install dp
```
##### Installing rnn dependencies
```
cd ~/torch
git clone git@github.com:Element-Research/rnn.git
cd rnn
luarocks make rocks/rnn-scm-1.rockspec
```
##### Installing Cjson
```
cd /usr/local/
sudo wget https://www.kyne.com.au/~mark/software/download/lua-cjson-2.1.0.tar.gz
sudo tar -xzvf lua-cjson-2.1.0.tar.gz
cd lua-cjson-2.1.0
sudo luarocks make
sudo rm ../lua-cjson-2.1.0.tar.gz
```
##### Installing NLTK
```
cd /usr/share/
sudo mkdir nltk_data
sudo pip install -U nltk
python -m nltk.downloader all
```
##### Installing GPU acceleration
- If have an NVIDIA GPU and want to accelerate the model with CUDA, you'll also need to install [torch/cutorch](https://github.com/torch/cutorch) and [torch/cunn](https://github.com/torch/cunn); you can install these by running:
```
luarocks install cutorch
luarocks install cunn
luarocks install cudnn
```
##### Installing cuDNN (Optional)
- If you want to use NVIDIA's cuDNN library, you'll need to register for the CUDA Developer Program (it's free) and download the library from [NVIDIA's website](https://developer.nvidia.com/cudnn). An running script **just for an example**:
```
cd ~/torch
# download the right cudnn file to cuda version
tar -xzvf cudnn-7.5-linux-x64-v5.1.tgz
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-7.5/lib64/
sudo cp cuda/include/cudnn.h /usr/local/cuda-7.5/include/
```
- You'll also need to install the [cuDNN bindings for Torch](https://github.com/soumith/cudnn.torch) by running:
```
luarocks install cudnn
```
##### Installing nccl for Multi-GPU Optimization (Optional)
- Optimized primitives for collective multi-GPU communication. Note that [NVIDIA/nccl](https://github.com/NVIDIA/nccl) is an optimization tool, and you can run the codes on multi-GPUs without nccl.
```
cd torch/
git clone https://github.com/NVIDIA/nccl.git
# build the library
cd nccl/
make CUDA_HOME=/usr/local/cuda-7.5 test
# update LIBRARY_PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/plu/torch/nccl/build/lib
source ~/.bashrc
# test demo
$ ./build/test/single/all_reduce_test
$ ./build/test/single/all_reduce_test 10000000
luarocks install nccl
```
#### Caffe and faster-rcnn
Extracting and visualizing bounding boxes are supported by [caffe](http://caffe.berkeleyvision.org/installation.html) and [py-faster-rcnn](https://github.com/rbgirshick/py-faster-rcnn). You can install Caffe and faster-rcnn following the [instructions](faster-rcnn-vqa/README.md).
Then copy the faster-rcnn for vqa files to the target folder:
```
cp ~/dual-mfa-vqa/faster-rcnn-vqa/tools/*.py ~/py-faster-rcnn/tools/
```
### VQA Dataset
#### Download mscoco images
```
mkdir -p ~/VQA/Images/mscoco
cd ~/VQA/Images/mscoco
wget http://msvocds.blob.core.windows.net/coco2014/train2014.zip
unzip train2014.zip
cd ~/VQA/Images/mscoco
wget http://msvocds.blob.core.windows.net/coco2014/val2014.zip
unzip val2014.zip
cd ~/VQA/Images/mscoco
wget http://msvocds.blob.core.windows.net/coco2015/test2015.zip
unzip test2015.zip
ln -s test2015 test-dev2015
```
#### Download VQA question and answers
```
mkdir -p ~/VQA/Annotations
cd ~/dual-mfa-vqa/data_train-val_test-dev_2k
python vqa_preprocess.py --download 1
python prepro_vqa.py
cd ~/dual-mfa-vqa/data_train_test-dev_2k
python vqa_preprocess.py
python prepro_vqa.py
cd ~/dual-mfa-vqa
th prepro/prepro_seconds.lua
```
#### Download resnet image model
```
mkdir -p ~/VQA/Images/Image_model
cd ~/VQA/Image_model
wget https://d2j0dndfm35trm.cloudfront.net/resnet-152.t7
wget https://raw.githubusercontent.com/facebook/fb.resnet.torch/master/datasets/transforms.lua
```
#### Download faster-rcnn model
```
cd ~/py-faster-rcnn/data/
mkdir faster_rcnn_models
cd faster_rcnn_models
wget https://dl.dropboxusercontent.com/s/cotx0y81zvbbhnt/coco_vgg16_faster_rcnn_final.caffemodel?dl=0
mv coco_vgg16_faster_rcnn_final.caffemodel?dl=0 coco_vgg16_faster_rcnn_final.caffemodel
```
#### Download skipthoughts models
You can download the pretrained Skipthoughts models to folder `skipthoughts_model/` for learning ([See more details](https://github.com/jnhwkim/MulLowBiVQA/tree/master/skipthoughts_model)):
- [gru.t7 (332M)](https://drive.google.com/uc?export=download&confirm=fFRb&id=0B-75nmZV6j-JZng3VEtmeDdxVXM)
- [lookup_2k.t7 (142M)](https://drive.google.com/uc?export=download&confirm=liRP&id=0B-75nmZV6j-JRmhIMnctVXpGMEU)
#### Download pretrained VQA models
This current code can get **66.01** on Open-Ended and 70.04 on Multiple-Choice on test-tev split for the VQA 1.0 dataset. Download the pre-trained model `vqa_dual-mfa_model_6601.t7` (315M) from [here](https://drive.google.com/open?id=1OdMhh6lmqWgUuZ1hBxR1ymFbtCL12ihC) into folder `dual-mfa-vqa/model/save/`.
### Extracting Image Features
#### Free-form region based features
- Image features for train dataset
```
cd prepro
th prepro_res_train.lua -batch_size 8
```
- Image features for test-dev dataset
```
th prepro_res_test.lua -batch_size 8
```
#### Detection region based features
- Image features for train dataset
```
python extract_box_feat_train.py
```
- Image features for test dataset
```
python extract_box_feat_train.py
```
- Bounding box coordinates for test dataset. You can directly download the result file `faster-rcnn_box4_19_test.h5` from [here](https://drive.google.com/open?id=1nhxbRcUyH2xoEQRajNbKLm0bxCuOzOCx).
```
python extract_box_test.py
```
### Training
Now, everything is ready, let's train the vqa network. Here are some common training ways for different needs.
- Training the network on train dataset and validating on val dataset
```
th train.lua -phase 1 -val_nqs -1 -nGPU 4
```
- Training the network on train-val dataset with multi-GPUs (4 GPUs)
```
th train.lua -phase 2 -nGPU 4 -batchsize 300
```
- Training the network loading image features into memory (much faster, 200-300G memory is needed)
```
th train.lua -phase 1 -val_nqs 10000 -nGPU 4 -memory_ms -memory_frms
```
- Training the network from the previous checkpoint
```
th train.lua -phase 2 -nGPU 4 -memory_ms -load_checkpoint_path model/save/vqa_model_dual-mfa_6601.t7 -previous_iters 350000
```
- Main options useful training are listed as follows:
- `phase`:training phase, `1`: train on Train, `2`: train on Train+Val
- `vqa_type`: vqa dataset type, `vqa` or `coco-qa`
- `memory_ms`: load image resnet feature to memory
- `memory_frms`: load image fast-rcnn feature to memory
- `val`: running validation
- `val_nqs`: number of validation questions, `-1` for all questions
- `batch_size`: batch_size for each iterations, change it to smaller value if out of the memory
- `run_id`: running model id
- `model_label`: model label name
- `save_checkpoint_every`: how often to save a model checkpoint
- `skip_save_model`: skip saving t7 model
- `cg_every`: How often do we collectgarbage in the training process, change it to smaller value if out of the memory
- `quick_check`: quick check for code
- `quickquick_check`: very quick check for code
- `nGPU`: how many GPUs to use, 1 = use 1 GPU, change it to larger value if out of the memory
### Evaluation
Evaluate the pre-trained model on VQA dataset:
```
cd ~/dual-mfa-vqa
th eval.lua -model_path model/vqa_model_dual-mfa_6601.t7 -output_model_name vqa_model_dual-mfa_6601 -batch_size 10
```
Then you can submit the result jsons and obtain the evaluation scores:
- Open-Ended for real images: [Submission](https://competitions.codalab.org/competitions/6961#participate-submit_results)
- Multiple-Choice for real images: [Submission](https://competitions.codalab.org/competitions/6971#participate-submit_results)
### COCO-QA Dataset
- Download the dataset
```
cd data_coco
python cocoqa_preprocess.py --download 1
```
- Preprocess the dataset
```
python prepro_cocoqa.py
```
- Extract the free-form image features
```
cd prepro
th prepro_res_coco.lua -batch_size 8
```
- Training the network
```
th train.lua -vqa_type coco-qa -learning_rate 4e-4 -nGPU 4 -batch_size 300 \
-model_id 1 -model_label dual-mfa
```
- Evaluation based on WUPS
``` bash
cd ~/dual-mfa-vqa/metric
python gen_wups_input.py
python calculate_wups.py gt_ans_save.txt pd_ans_save.txt 0.9
python calculate_wups.py gt_ans_save.txt pd_ans_save.txt 0.0
```
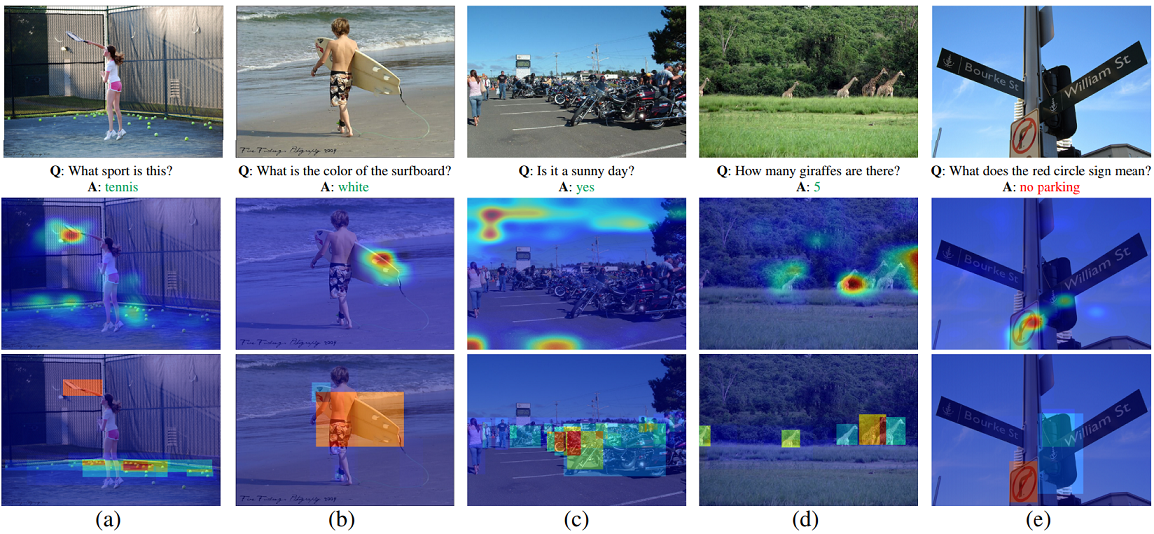
### Visualization
- Generate the attention maps. You can directly download the result file of attention map from [here](https://drive.google.com/open?id=1PvXId4VOPrvw_y98Q-iPHjlxxg8IKWdf).
```
cd ~/dual-mfa-vqa
th eval_vis_att.lua -model_path model/vqa_model_dual-mfa_6601.t7 -output_model_name vqa_model_dual-mfa_6601 -batch_size 8
```
- Preprocess the question data before visualization:
```
cd vis_att
python vis_prepro.py
```
- Run the matlab file `vis_attention_demo.m` to show the results of attention maps.
- Run the matlab file `vis_attention.m` to save the results of attention maps.
### Reference
- **Paper on arXiv**: https://arxiv.org/abs/1711.06794
- **Paper on AAAI**: https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16249/16315
If you use this code as part of any published research, please acknowledge the following paper.
```
@inproceedings{lu2018co-attending,
title={Co-attending Free-form Regions and Detections with Multi-modal Multiplicative Feature Embedding for Visual Question Answering.},
author={Lu, Pan and Li, Hongsheng and Zhang, Wei and Wang, Jianyong and Wang, Xiaogang},
booktitle={AAAI 2018},
pages={7218-7225},
year={2018}
}
```