https://github.com/madsondeluna/mvp_pucrio_data_analysis
MVP de análise de dados com boas práticas, usando o dataset de câncer de mama. A análise segue o Módulo 1 da especialização em Data Science da PUC-Rio, com foco em inspeção, limpeza, visualização e extração de insights iniciais para projetos futuros.
https://github.com/madsondeluna/mvp_pucrio_data_analysis
data-exploration data-science data-visualization knn-classification puc-rio python
Last synced: 2 months ago
JSON representation
MVP de análise de dados com boas práticas, usando o dataset de câncer de mama. A análise segue o Módulo 1 da especialização em Data Science da PUC-Rio, com foco em inspeção, limpeza, visualização e extração de insights iniciais para projetos futuros.
- Host: GitHub
- URL: https://github.com/madsondeluna/mvp_pucrio_data_analysis
- Owner: madsondeluna
- License: mit
- Created: 2025-07-04T19:54:31.000Z (12 months ago)
- Default Branch: main
- Last Pushed: 2025-07-21T17:41:20.000Z (12 months ago)
- Last Synced: 2026-05-03T10:47:25.436Z (2 months ago)
- Topics: data-exploration, data-science, data-visualization, knn-classification, puc-rio, python
- Language: Jupyter Notebook
- Homepage: https://colab.research.google.com/drive/1--VBTH2w0f66WHhe33Wdgm40o6nHTX__?usp=sharing
- Size: 40.8 MB
- Stars: 1
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# MVP I (Análise de Dados e Boas Práticas)
**Pontifícia Universidade Católica do Rio de Janeiro - PUC-Rio**
**Especialização em Ciência de Dados & Analytics**
**Autor:** Madson Aragão
**Sementre**: 25/1
---
     
---
#### 🟡 [Acesse o notebook no Google Colab](https://colab.research.google.com/drive/1--VBTH2w0f66WHhe33Wdgm40o6nHTX__?usp=sharing)
#### ⚪️ [Acesse o notebook no GitHub](https://github.com/madsondeluna/mvp_pucrio_data_analysis/blob/main/mvp_pucrio_data_analysis_final.ipynb)
---
## I. Introdução
### Objetivo Geral
Validar a viabilidade de classificar dados extraídos a partir de células mamárias em processos de alteração celular (benignas vs. malignas) usando técnicas clássicas de análises de dados baseadas em Python, além de iniciar o preparo do dataset para treinamento e testes de modelos de Aprendizado de Máquina. O projeto também visa explorar a relevância biológica das variáveis envolvidas e avaliar o potencial diagnóstico do modelo.
### Detalhamento da Problemática
A figura abaixo ilustra, em três níveis de ampliação (4×, 10× e 20×), o contraste entre **amostras benignas** e **amostras malignas** de tumores de mama:
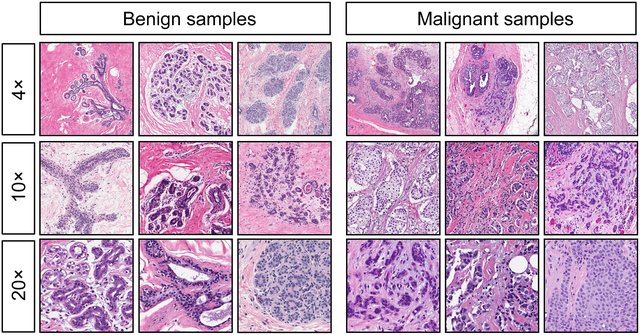
A figura acima apresenta um **comparativo de amostras histopatológicas** de tumores de mama, divididas em duas colunas principais:
1. **Coluna “Benign samples” - (Amostras benignas)**
2. **Coluna “Malignant samples” - (Amostras malignas)**
Cada coluna é organizada em três linhas, que correspondem a diferentes **níveis de ampliação** do microscópio:
| Linha | Ampliação | O que significa |
|-------|-----------|----------------------------------------------------|
| 1 | 4× | Visão geral da arquitetura |
| 2 | 10× | Organização tecidual |
| 3 | 20× | Detalhes nucleares e citoplasmáticos |
### Funcionalidades
- **Seleção e Carregamento dos Dados**
- Importação do arquivo CSV contendo métricas morfológicas extraídas de imagens clínicas.
- Verificação da integridade do dataset (dimensões, tipos de variáveis, rótulos disponíveis).
- Remoção de colunas irrelevantes ou redundantes (ex.: IDs, campos vazios).
- Classificação do tipo de variável (numérica contínua, categórica ou binária) para orientar futuras transformações.
- Identificação prévia de colinearidade, valores extremos e valores faltantes.
- Registro da proporção entre amostras benignas e malignas para verificar eventual desbalanceamento.
- **Visualização Exploratória dos Dados**
- Análise gráfica da distribuição das variáveis por meio de histogramas, boxplots e pairplots.
- Detecção visual de outliers e padrões por classe (benigno vs. maligno).
- Representação gráfica de correlações via heatmap para identificar redundância entre variáveis.
- Visualização/exibição (imagem ou texto) da distribuição das classes na base original e após divisão em treino/teste.
- **Pré-processamento dos Dados**
- Tratamento de valores ausentes e remoção de duplicatas.
- Padronização das variáveis contínuas utilizando z-score (StandardScaler).
- Separação dos dados em conjuntos de treino e teste com proporção 75/25, utilizando `train_test_split` com `random_state=10` para reprodutibilidade.
- Verificação da distribuição de classes entre treino e teste para garantir equilíbrio.
- Armazenamento das estatísticas de normalização aplicadas na base de treino para uso posterior.
- **Transformação e Mineração de Dados**
- Análise de correlações entre variáveis para identificar multicolinearidade.
- Aplicação de PCA (Análise de Componentes Principais) para reduzir dimensionalidade e observar agrupamentos de classes.
- Comparação entre variáveis para avaliar valor das informações.
- Avaliação qualitativa da separação entre classes no espaço transformado.
- **Modelo Inicial de Classificação (Extra-MVP)**
- Treinamento e avaliação de um classificador K-NN (k-Nearest Neighbors) com variação de k para análise de desempenho.
- Cálculo de métricas: acurácia, precisão, recall e F1-score com base no conjunto de teste.
- Avaliação visual do desempenho via curvas de decisão, matriz de confusão e curva AUC-ROC.
- Avaliação do Matthews Correlation Coefficient (MCC), métrica robusta para avaliação de modelos de classificação binária, especialmente eficaz em cenários com classes desbalanceadas.
- **Relatório de Resultados (Extra-MVP)**
- Tabela sumarizando as principais métricas por valor de k.
- Exibição da curva ROC com cálculo da AUC.
- Discussão dos erros (falsos positivos e negativos) e suas implicações clínicas.
- Indicação de configurações de k que maximizam a performance sem sobreajuste.
### Checklist
- (OK) Pipeline executando sem erros do início ao fim, com resultados reprodutíveis.
- (OK) Código documentado e validado em ambiente Jupyter.
- (OK) Notebook estruturado com seções claras: título, objetivos, hipóteses, análise, conclusões.
- (OK) MVP devidamente depositado, formatado e compartilhado via GitHub.
---
## II. Contexto da Base de Dados
Nesta análise, utilizamos o **Breast Cancer Wisconsin (Diagnostic) Dataset**, um dos datasets mais consagrados em aprendizado de máquina biomédico, disponível no UCI ML Repository e outras fontes públicas.
- **Tumores benignos:** 357 amostras — células com arquitetura preservada, sem capacidade de metástase.
- **Tumores malignos:** 212 amostras — células agressivas, com invasão de tecidos e potencial metastático.
Os dados foram coletados por punção aspirativa com agulha fina (FNA) de lesões mamárias, modelando características morfológicas dos núcleos celulares via análise de imagens digitalizadas.
### Referências importantes
- Clínica Einstein – Câncer de Mama Benigno e Maligno
https://www.einstein.br/noticias/noticia/cancer-benigno-maligno
- Breast Cancer: Pathogenesis and Treatments
https://www.nature.com/articles/s41392-024-02108-4
- The Size Differences of Breast Cancer and Benign Tumors Measured by Two-Dimensional Ultrasound and Contrast-Enhanced Ultrasound
https://onlinelibrary.wiley.com/doi/10.1002/jum.16449
- Distinguishing Between Benign and Malignant Breast Lesions using Diffusion Weighted Imaging and Intravoxel Incoherent Motion: A Systematic Review and Meta-Analysis
https://www.sciencedirect.com/science/article/abs/pii/S0720048X21002904
---
## III. Descrição Detalhada da Base de Dados
O Wisconsin Breast Cancer Dataset contém **569 amostras**, cada uma com **30 variáveis morfológicas** discretizadas em três escalas:
| Sufixo | Significado | Exemplos |
|-----------|----------------------|--------------------------|
| _mean | Média do atributo | radius_mean, texture_mean |
| _se | Erro-padrão da média | radius_se, area_se |
| _worst | Valor extremo | perimeter_worst, concavity_worst |
### Variáveis capturadas
- **Tamanho:** raio, perímetro, área
- **Textura:** desvio-padrão dos tons de cinza
- **Irregularidade de contorno:** smoothness, compactness, concavity, concave points
- **Simetria e complexidade fractal do contorno**
### Motivações para uso desta base
- Alta relevância clínica para diagnóstico precoce e triagem.
- Qualidade e consistência amplamente validadas.
- Desafio binário com leve desbalanceamento, ideal para métricas robustas.
- Facilita comparação com trabalhos acadêmicos prévios.
---
## IV. Exploração e Preparação dos Dados
- Checagem inicial: dimensões, tipos, valores faltantes e duplicados.
- Balanceamento: proporção 357 benignos : 212 malignos, com amostragem estratificada.
- Análise de correlação: heatmap para identificar pares com correlação alta (|r| > 0.9), por exemplo, `radius_mean`, `perimeter_mean`, `area_mean`.
- Seleção de atributos: priorização das variáveis com sufixo `_mean`, descartando `_se` e `_worst` para reduzir multicolinearidade.
- Padronização: aplicação do `StandardScaler()` do sklearn.
- Divisão treino/teste: 75% treino · 25% teste, com `random_state=10` e estratificação.
---
## V. Hipóteses e Justificativa Biológica
| Hipótese | Descrição |
|----------|------------------------------------------------------------------------------------------------|
| H1 | Pleomorfismo nuclear — tumores malignos exibem maior variação no `radius_mean` e `area_mean`. |
| H2 | Irregularidade de contorno — aumento do `perimeter_mean` refletindo formas invaginadas. |
| H3 | Agrupamento em PCA — separação clara entre benigno e maligno. |
| H4 | Performance do K-NN — distância separa amostras benignas e malignas eficientemente. |
---
## VI. Variáveis Principais
| Variável | Descrição Técnica | Relevância Clínica/Biológica |
|--------------------|-------------------------------|-------------------------------------------------------|
| `radius_mean` | Média do raio do núcleo | Núcleos malignos tendem a ser maiores |
| `texture_mean` | Desvio-padrão dos tons de cinza | Cromatina heterogênea em tumores malignos |
| `perimeter_mean` | Média do perímetro do contorno | Reflete tamanho e irregularidade nuclear |
| `area_mean` | Média da área do núcleo | Área aumentada indica maior atividade tumoral |
| `smoothness_mean` | Variação local do raio | Bordas irregulares típicas de células agressivas |
| `concavity_mean` | Profundidade média das concavidades | Concavidades refletem invaginações nucleares |
| `concave points_mean` | Número médio de pontos côncavos | Marcas de contornos recortados em malignidades |
| `symmetry_mean` | Assimetria média | Assimetria nuclear correlaciona-se ao grau de diferenciação |
| `fractal_dimension_mean` | Complexidade fractal do contorno | Alto valor indica desorganização estrutural extrema |
*(Demais variáveis com sufixos `_se` e `_worst` estão no dataset completo.)*
---
## OBS: Que restrições ou condições foram impostas para selecionar os dados?
Embora tenha utilizado o dataset completo, foram definidas condições para a seleção de features que alimentaram meu modelo final. A principal condição foi a redução de multicollinearidade. Com base nas análises dos mapas de calor, logo foi dedicido por remover um conjunto de características (`droplist_final`) que eram altamente correlacionadas, com o objetivo de evitar redundância, simplificar o modelo e torná-lo mais estável.
---
## VII. Modelagem com K-NN
| Etapa | Detalhe |
|----------------|-------------------------------------------------|
| Divisão de dados | 75% treino · 25% teste, estratificado |
| Padronização | `StandardScaler()` — z-score |
| Seleção de k | Teste de k = 1 a 14; k = 7 é o mais indicado |
| Modelo final | `KNeighborsClassifier(n_neighbors=7)` (distância Euclidiana) |
---
## VIII. Resultados
### Matriz de Confusão (k = 7)
| | Predito: Benigno | Predito: Maligno |
|-----------------|------------------|------------------|
| **Real: Benigno** | 89 (VN) | 2 (FP) |
| **Real: Maligno** | 4 (FN) | 48 (VP) |
### Métricas Principais
| Métrica | Valor |
|------------------------|--------|
| Acurácia | 0.9580 |
| Matthews Correlation (MCC) | 0.9090 |
| AUC-ROC | 0.9968 |
| Precisão (Benigno/Maligno) | 0.96 / 0.96 |
| Recall (Benigno/Maligno) | 0.98 / 0.92 |
| F1-Score (Benigno/Maligno) | 0.97 / 0.94 |
---
## IX. Interpretação dos Resultados
- Alta sensibilidade (92%) para tumores malignos reduz falsos-negativos.
- Especificidade elevada (98%) minimiza falsos-positivos.
- MCC elevado demonstra predições confiáveis em conjunto desbalanceado, sugerindo a exclusão de overfitting.
- AUC próxima a 1 reflete poder discriminativo excepcional.
- Pipeline de pré-processamento (seleção de variáveis e normalização) foi decisivo para estabilidade e performance.
---
## X. Próximos Passos
- Ajuste de limiar via `predict_proba` para minimizar falsos-negativos.
- Testar algoritmos com penalização assimétrica (SVM, Random Forest, XGBoost).
- Avaliar importância de features por permutação (SHAP/LIME).
- Validar em dados externos e cross-validation estratificada.
- Explorar redes neurais (CNN) e XAI para classificação direta em imagens.
---
## XI. Conclusão
A aplicação criteriosa do K-NN, com foco em seleção de atributos relevantes e pré-processamento rigoroso, atingiu acurácia de 95,8%, AUC de 0.9968 e MCC de 0.9090. O modelo mostrou-se robusto e promissor como ferramenta de triagem diagnóstica não invasiva de câncer de mama.
---
## Licença
Este projeto faz parte das atividades acadêmicas da disciplina de Análise de Dados e Boas Práticas como parte da Especialização em Data Science & Analytics da PUC-Rio, com fins educacionais e científicos.