https://github.com/mangoggul/YOLO-MultiModal
https://github.com/mangoggul/YOLO-MultiModal
Last synced: 10 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/mangoggul/YOLO-MultiModal
- Owner: mangoggul
- Created: 2024-07-24T12:07:42.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-08-19T08:00:07.000Z (over 1 year ago)
- Last Synced: 2024-08-19T09:27:27.312Z (over 1 year ago)
- Language: Python
- Size: 43.5 MB
- Stars: 0
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-yolo-object-detection - mangoggul/YOLO-MultiModal - MultiModal?style=social"/> : Multi-Modal-YOLO detection. (Object Detection Applications)
README
# Multi-Modal-YOLO detection

## This code modifications were made with him : [mcw1217](https://github.com/mcw1217)
## Flow
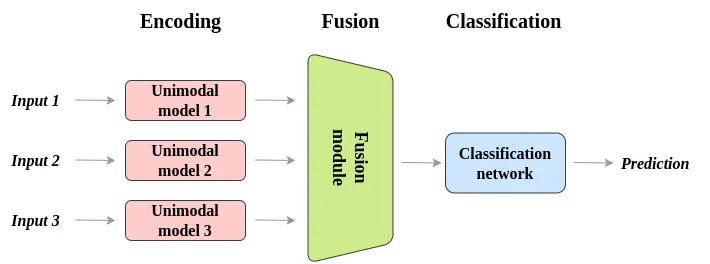
Get Depth, RGB, Thermal image to input.

(ultralytics/cfg/models/v8/yolov8.yaml)
Triple_Conv : get Depth, RGB, Thermal Image
Conv_Main : Concatenate three input images.
The remaining layers have the same structure as the standard YOLO.
## Early Fusion
In this approach, two different types of data are combined into a single dataset before training the model. Various data transformations are performed to merge the two datasets. The data can be concatenated either as raw data or after preprocessing.
## Late Fusion
In this approach, two different types of data are trained separately using different models. The results from these models are then fused together. This method works similarly to boosting in ensemble models.
## Joint (Intermediate) Fusion
This method offers flexibility to merge modalities at a desired depth of the model. It involves progressing with a single modality and then fusing it with another modality just before the final layer of model training. This process is also known as end-to-end learning.
## Primary Code (concatenate)
```
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv1 = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.conv2 = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.conv3 = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
# Combine the outputs and reduce channel dimension to 32
self.combine_conv = nn.Conv2d(c2*3, c2, 1, 1, 0, bias=False) # 1x1 conv to reduce channels from 96 to 32
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, inputs):
"""Apply convolution, batch normalization and activation to input tensor."""
x1, x2, x3 = inputs
# Process each input tensor independently
out1 = self.conv1(x1)
out2 = self.conv2(x2)
out3 = self.conv3(x3)
# Concatenation along the channel dimension
combined = torch.cat((out1, out2, out3), dim=1)
# Apply a 1x1 convolution to reduce the channel dimension to 32
reduced = self.combine_conv(combined)
# Apply batch normalization and activation
bn_combined = self.bn(reduced)
output = self.act(bn_combined)
return output
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv1(x))
```
## How to Use
### 1. git clone this file
```
git clone https://github.com/mangoggul/YOLO-MultiModal.git
```
### 2. You need to download Dataset / Dataset is organized as follows
#### Dataset Tree
```bash
dataset_name
├─test
│ ├─D (Depth)
│ ├─labels (yolo annotation = txt file)
│ ├─RGB
│ └─Thermo
├─train
│ ├─D (Depth)
│ ├─labels (yolo annotation = txt file)
│ ├─RGB
│ └─Thermo
└─val
├─D (Depth)
├─labels (yolo annotation = txt file)
├─RGB
└─Thermo
```
So For example
```
new_data
├─test
│ ├─D
│ ├─labels
│ ├─RGB
│ └─Thermo
├─train
│ ├─D
│ ├─labels
│ ├─RGB
│ └─Thermo
└─val
├─D
├─labels
├─RGB
└─Thermo
```
> It doesn't matter whether the images are in JPG or PNG format.
### 3. Start Training
type this python command
if you want multi modal training
```
python yolo_single_train.py
```
> It is Multi-Modal Detection , just file name is "single_train"
### 4. Inference
if you want inference
```
python inference.py
```

Furthermore, metrics
