https://github.com/marioleo7k/bookscraper
Bookscraper é um projeto de web scraping para extrair informações sobre livros, como títulos e preços. Os dados são visualizados interativamente com Streamlit, oferecendo uma forma dinâmica de explorar as informações.
https://github.com/marioleo7k/bookscraper
python streamlit-dashboard webscraping
Last synced: 9 months ago
JSON representation
Bookscraper é um projeto de web scraping para extrair informações sobre livros, como títulos e preços. Os dados são visualizados interativamente com Streamlit, oferecendo uma forma dinâmica de explorar as informações.
- Host: GitHub
- URL: https://github.com/marioleo7k/bookscraper
- Owner: marioleo7k
- License: mit
- Created: 2025-01-23T12:49:30.000Z (12 months ago)
- Default Branch: main
- Last Pushed: 2025-02-25T12:41:17.000Z (11 months ago)
- Last Synced: 2025-02-25T13:42:03.857Z (11 months ago)
- Topics: python, streamlit-dashboard, webscraping
- Language: Python
- Homepage: https://bookscraper-dashboard.streamlit.app/
- Size: 275 KB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# 📚 BookScraper: Extração e Visualização de Dados de Livros
Bem-vindo ao **BookScraper**, um projeto de Python que combina web scraping e visualização de dados para explorar informações de livros disponíveis no site [Books to Scrape](https://books.toscrape.com/).
Com este projeto, você poderá:
- Extrair dados como títulos e preços de livros.
- Armazenar essas informações em um arquivo CSV.
- Visualizar insights através de uma dashboard interativa criada com Streamlit.
---
## 📜 **Propósito do Projeto**
Este projeto foi desenvolvido com o objetivo de demonstrar habilidades em:
- **Web Scraping**: Coleta de informações automatizada de páginas web.
- **Análise de Dados**: Organização e processamento dos dados extraídos.
- **Visualização de Dados**: Criação de dashboards interativas e acessíveis.
Além disso, é uma oportunidade para aprender e explorar bibliotecas poderosas como:
- `BeautifulSoup`: Para scraping de dados.
- `Pandas`: Para manipulação e análise de dados.
- `Streamlit`: Para criação de dashboards.
---
## 🚀 **Como Executar o Projeto**
### 1. Clone este repositório:
```bash
git clone https://github.com/marioleo7k/bookscraper
cd bookscraper
```
### 2. Instale as dependências:
Certifique-se de que você tem o Python instalado e execute o comando:
```bash
pip install -r requirements.txt
```
### 3. Extraia os dados:
Execute o script `bookscraper.py` para realizar o web scraping e gerar o arquivo `livros.csv`:
```bash
python bookscraper.py
```
### 4. Visualize os dados:
Execute a dashboard interativa:
```bash
streamlit run bookscraper_dashboard.py
```
Acesse a URL local exibida no terminal, como `http://localhost:8501`.
---
## 🛠️ **Principais Funcionalidades**
### **1. Web Scraping:**
- O script `bookscraper.py` coleta automaticamente:
- Títulos dos livros.
- Preços em Libras Esterlinas (£).
- Gera um arquivo CSV com os dados extraídos.
### **2. Dashboard Interativa:**
- A dashboard, criada com Streamlit, inclui:
- **Distribuição de Preços:** Visualize a variação de preços em um histograma.
- **Top 10 Livros Mais Caros:** Descubra os livros mais caros.
- **Preço por Ordem de Extração:** Um gráfico de dispersão para acompanhar os preços na sequência.
---
## 🖼️ **Exemplos de Visualizações**
### Distribuição de Preços:

### Preço dos Livros por Ordem de Extração:
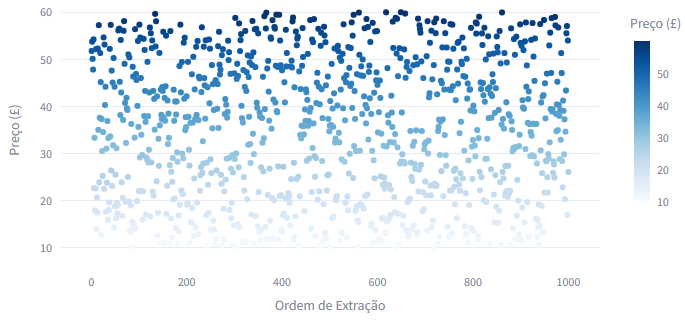
---
## 📂 **Estrutura do Repositório**
A estrutura de arquivos do repositório está organizada da seguinte forma:
```
bookscraper/
├── bookscraper.py # Script de extração de dados
├── bookscraper_dashboard.py # Script da dashboard
├── livros.csv # Dados extraídos (gerado pelo scraper)
├── requirements.txt # Dependências do projeto
├── .gitignore # Arquivos ignorados pelo Git
└── README.md # Documentação do projeto
```
---
## ⚖️ **Licença**
Este projeto está sob a licença MIT. Consulte o arquivo [LICENSE](./LICENSE) para mais detalhes.
---
## 💬 **Contato**
Para dúvidas ou feedback:
- **LinkedIn**: [Mario Leonardo da Silva](https://www.linkedin.com/in/marioleo7k/)
- **E-mail**: marioleo7k@icloud.com
---
## 🌐 **Dashboard Publicada**
Você também pode acessar a versão publicada da dashboard [aqui](https://bookscraper-dashboard.streamlit.app/).