https://github.com/matin-ghorbani/transformers-from-scratch
Transformer from Scratch using PyTorch
https://github.com/matin-ghorbani/transformers-from-scratch
pytorch pytorch-implementation transformers
Last synced: 3 months ago
JSON representation
Transformer from Scratch using PyTorch
- Host: GitHub
- URL: https://github.com/matin-ghorbani/transformers-from-scratch
- Owner: matin-ghorbani
- License: mit
- Created: 2024-08-17T09:43:57.000Z (11 months ago)
- Default Branch: main
- Last Pushed: 2024-08-17T09:57:57.000Z (11 months ago)
- Last Synced: 2025-04-12T20:49:56.588Z (3 months ago)
- Topics: pytorch, pytorch-implementation, transformers
- Language: Python
- Homepage:
- Size: 4.88 KB
- Stars: 2
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Transformer from Scratch using PyTorch
This repository contains a complete implementation of the Transformer model from scratch using PyTorch. The Transformer architecture, introduced by Vaswani et al. in the paper "Attention is All You Need," revolutionized the field of natural language processing by enabling models to process sequences in parallel and capture long-range dependencies effectively.
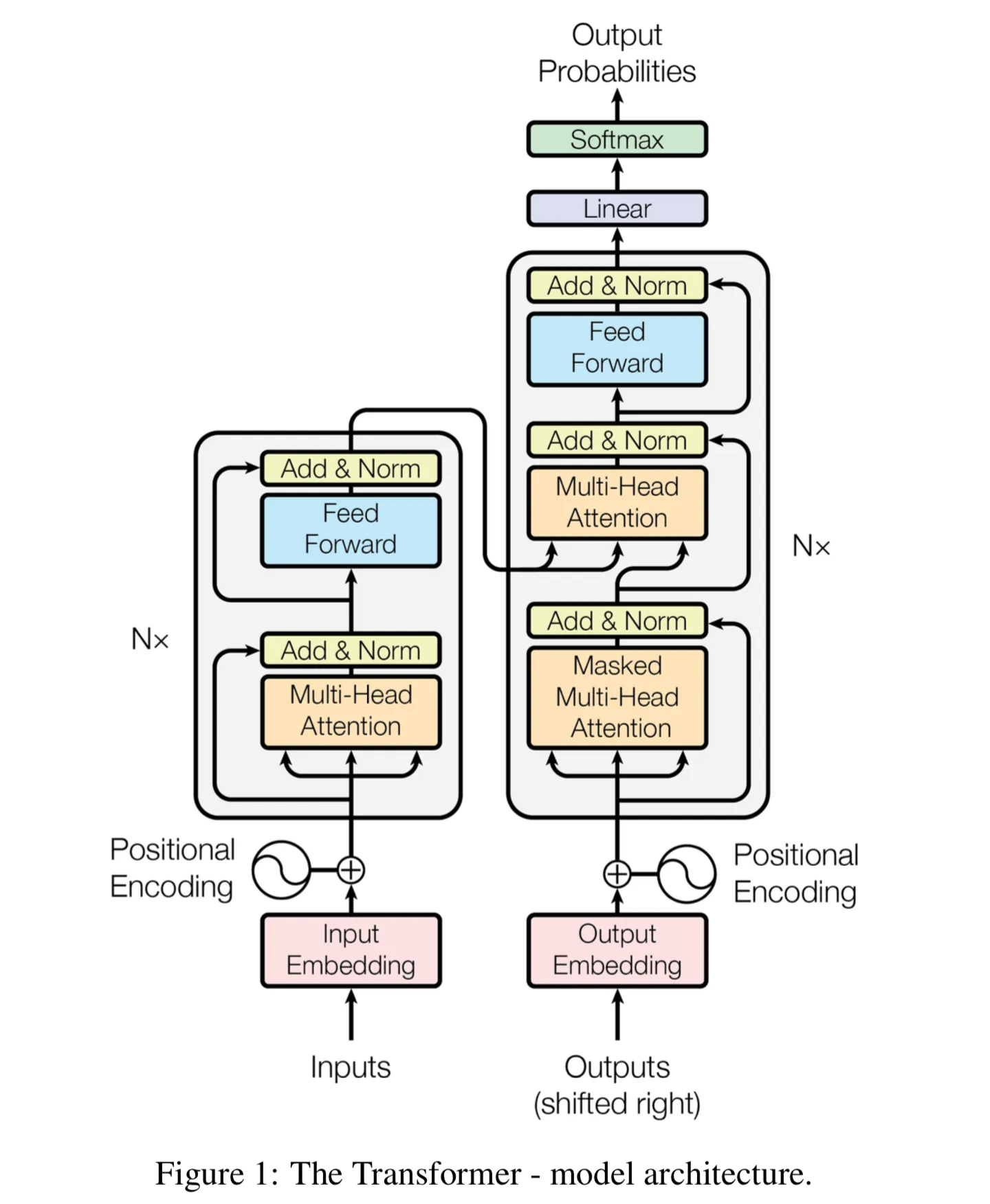
## Table of Contents
- [Introduction](#introduction)
- [Architecture Overview](#architecture-overview)
- [Self-Attention](#self-attention)
- [Transformer Block](#transformer-block)
- [Encoder](#encoder)
- [Decoder](#decoder)
- [Setup and Requirements](#setup-and-requirements)
- [Usage](#usage)
- [Acknowledgments](#acknowledgments)
- [References](#references)
## Introduction
The Transformer model has become the backbone of many state-of-the-art NLP models such as BERT, GPT, and T5. Unlike traditional RNNs and LSTMs, Transformers rely entirely on self-attention mechanisms, enabling faster computation and better parallelization.
In this implementation, we provide a basic version of the Transformer model that can be used as a building block for various NLP tasks like machine translation, text generation, and more.
## Architecture Overview
### Self-Attention
The core component of the Transformer model is the self-attention mechanism. It allows the model to focus on different parts of the input sequence when making predictions.
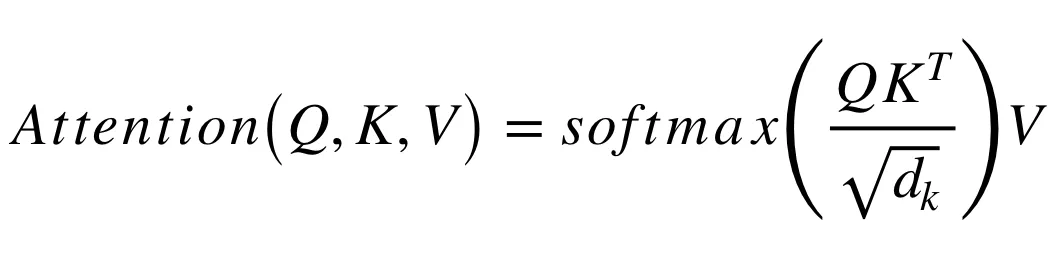
The self-attention mechanism computes a weighted sum of input features, where the weights are determined by the similarity between different positions in the input.
### Transformer Block
The Transformer block combines the self-attention mechanism with feed-forward neural networks. It also includes layer normalization and dropout for regularization.
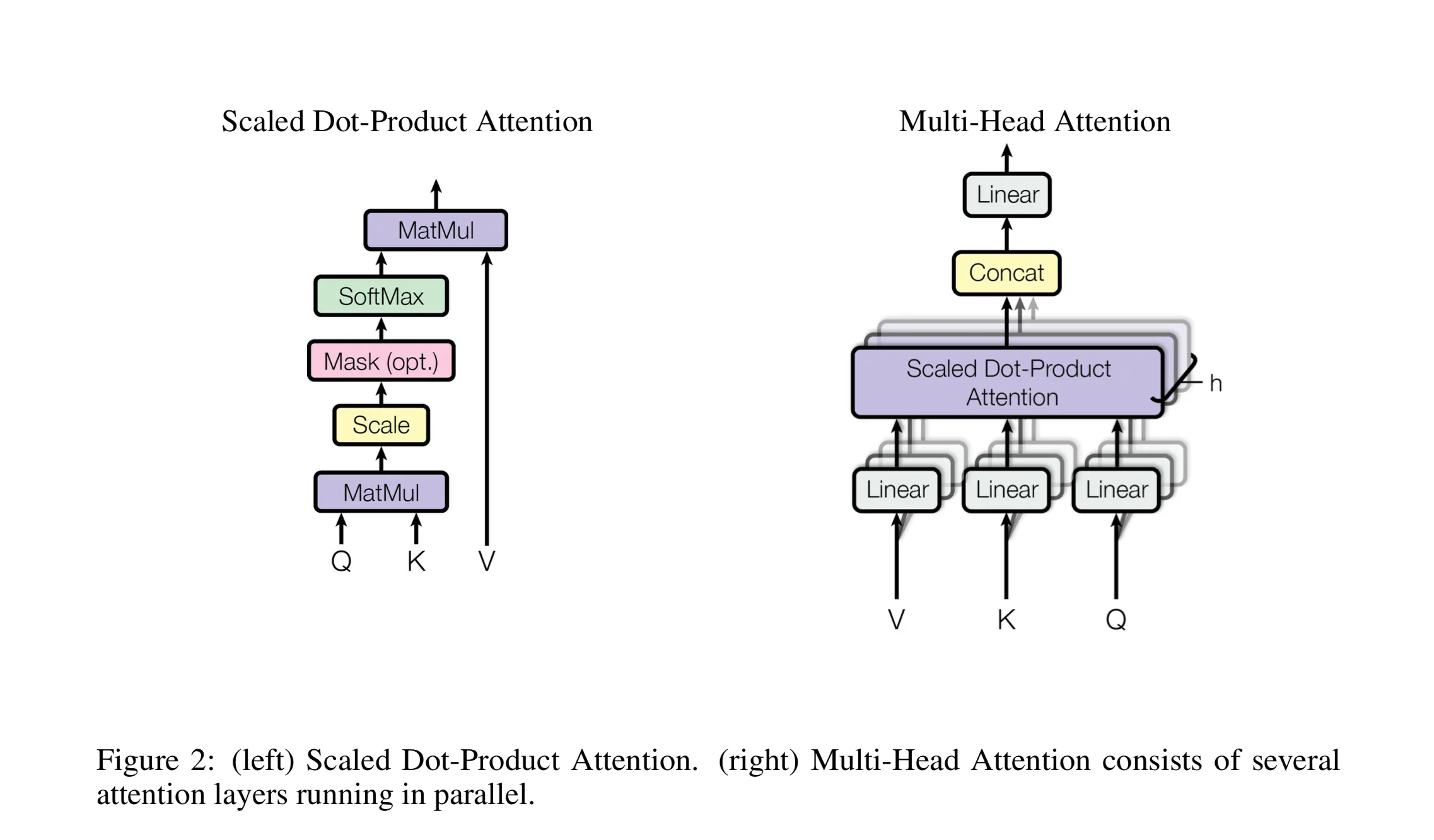
A typical Transformer block consists of multi-head self-attention followed by a feed-forward network.
### Encoder
The Encoder is composed of multiple Transformer blocks stacked together. It takes the input sequence and processes it through several layers of self-attention and feed-forward networks.
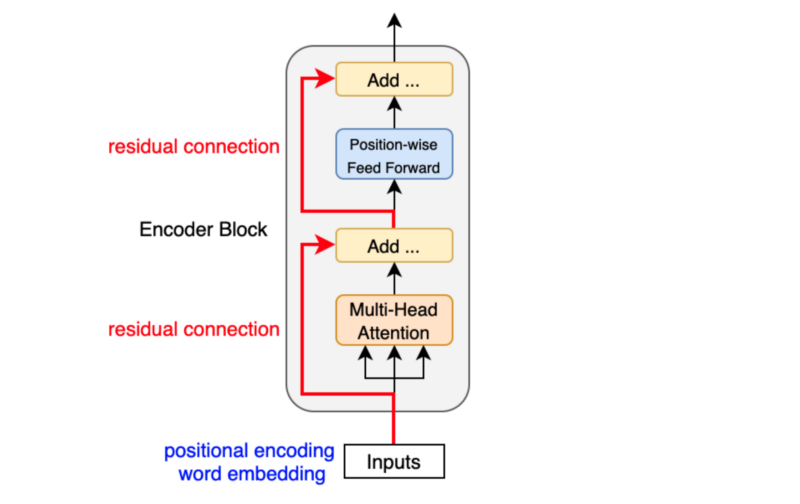
### Decoder
The Decoder is similar to the Encoder but with an additional layer of masked self-attention to prevent the model from attending to future positions in the sequence during training.
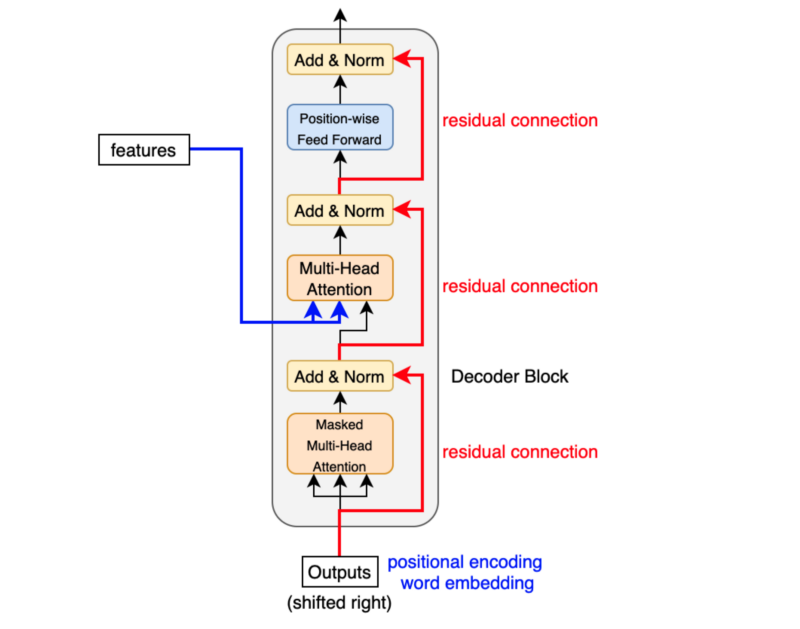
The overall Transformer architecture is made up of an Encoder and a Decoder, which work together to transform an input sequence into an output sequence.
## Setup and Requirements
Clone the repository first and navigate to the repository directory:
```bash
git clone https://github.com/matin-ghorbani/transformers-from-scratch
cd transformers-from-scratch
```
To run the code, you need to have Python and PyTorch installed. You can install the required packages using pip:
```bash
pip install torch
```
## Usage
The main.py file contains an example of how to instantiate and run the Transformer model.
Run this command:
```bash
python main.py
```
This example demonstrates how to create a simple Transformer model and pass an input sequence through it.
## Acknowledgments
This implementation is inspired by the original Transformer paper and various educational resources that break down the model's components. Special thanks to the PyTorch community for providing extensive documentation and examples.
## References
1. Vaswani, Ashish, et al. "[Attention is all you need.](https://arxiv.org/pdf/1706.03762)" Advances in neural information processing systems 30 (2017).
2. PyTorch [Documentation](https://pytorch.org/docs/)