https://github.com/mauriciovazquezm/k_means_parallelized
Implementation of the K-means clustering model in C++. This model parallelized with the Open MP library
https://github.com/mauriciovazquezm/k_means_parallelized
cplusplus kmeans-clustering openmp-parallelization parallel-computing
Last synced: 23 days ago
JSON representation
Implementation of the K-means clustering model in C++. This model parallelized with the Open MP library
- Host: GitHub
- URL: https://github.com/mauriciovazquezm/k_means_parallelized
- Owner: MauricioVazquezM
- License: gpl-3.0
- Created: 2024-03-09T22:41:14.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-03-18T20:24:22.000Z (over 2 years ago)
- Last Synced: 2025-11-29T23:43:10.567Z (7 months ago)
- Topics: cplusplus, kmeans-clustering, openmp-parallelization, parallel-computing
- Language: C++
- Homepage:
- Size: 14.9 MB
- Stars: 2
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# K_Means_Parallelized
## Team
- [Mariana Luna Rocha](https://github.com/MarianaMoons), Data Science Bachelor student at ITAM.
- [Mauricio Vázquez Moran](https://github.com/MauricioVazquezM), Data Science and Actuarial Science Double Bachelor Program student at ITAM.
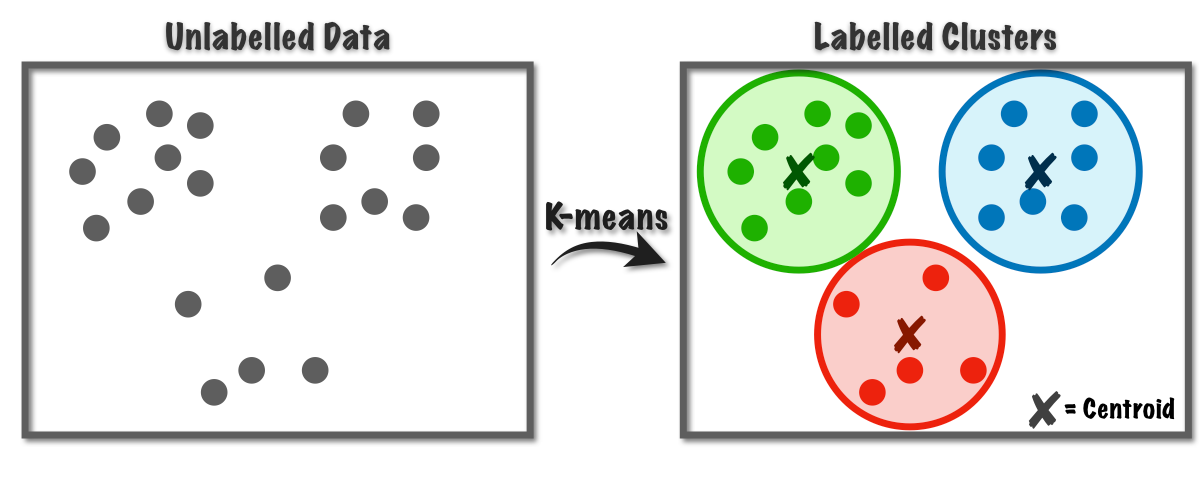
## Definition
K-means is a popular clustering algorithm used in data science and machine learning to partition a set of data points into K distinct, non-overlapping clusters.
## Algorithm Overview
1. Initialization: Choose K initial centroids randomly from the data points.
2. Assignment Step: Assign each data point to the nearest centroid, creating K clusters.
3. Update Step: Update the centroids of the clusters to the mean of all points assigned to that cluster.
4. Repeat: Repeat steps 2 and 3 until the centroids no longer change significantly, indicating convergence.
## Key Features
- Unsupervised Learning: K-means is an unsupervised learning algorithm, meaning it doesn't require labeled data.
- Efficiency: Generally fast and efficient for a moderate number of dimensions and data points.
- Applicability: Suitable for a wide range of clustering tasks where the underlying structure of the data is spherical.
- Limitations:
- The number of clusters, K, must be specified in advance.
- Sensitive to the initial choice of centroids.
- Assumes clusters are spherical and equally sized, which may not always be the case in real-world data.
- Can converge to local minima, leading to potentially suboptimal solutions.
## Applications
K-means is widely used in various fields for exploratory data analysis, pattern recognition, image compression, and more. It helps in identifying underlying patterns or groups in the data based on the similarity of data points.
## Variants and Improvements
Several variants and improvements of K-means have been developed to address its limitations, such as K-means++, which offers a smarter initialization of centroids to improve the chances of finding a better solution, and methods to automatically determine the optimal number of clusters.