https://github.com/memgraph/example-streaming-app
An example repository on how to start building graph applications on streaming data. Just clone and start building 💻 💪
https://github.com/memgraph/example-streaming-app
Last synced: 11 months ago
JSON representation
An example repository on how to start building graph applications on streaming data. Just clone and start building 💻 💪
- Host: GitHub
- URL: https://github.com/memgraph/example-streaming-app
- Owner: memgraph
- License: apache-2.0
- Created: 2021-06-24T16:45:37.000Z (about 5 years ago)
- Default Branch: main
- Last Pushed: 2022-01-12T13:21:20.000Z (over 4 years ago)
- Last Synced: 2025-06-25T22:38:12.319Z (12 months ago)
- Language: Rust
- Homepage: https://memgraph.com
- Size: 188 KB
- Stars: 56
- Watchers: 6
- Forks: 7
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Example Streaming App 🚀🚀



This repository serves as a point of reference when developing a streaming application with [Memgraph](https://memgraph.com) and a message broker such as [Kafka](https://kafka.apache.org).
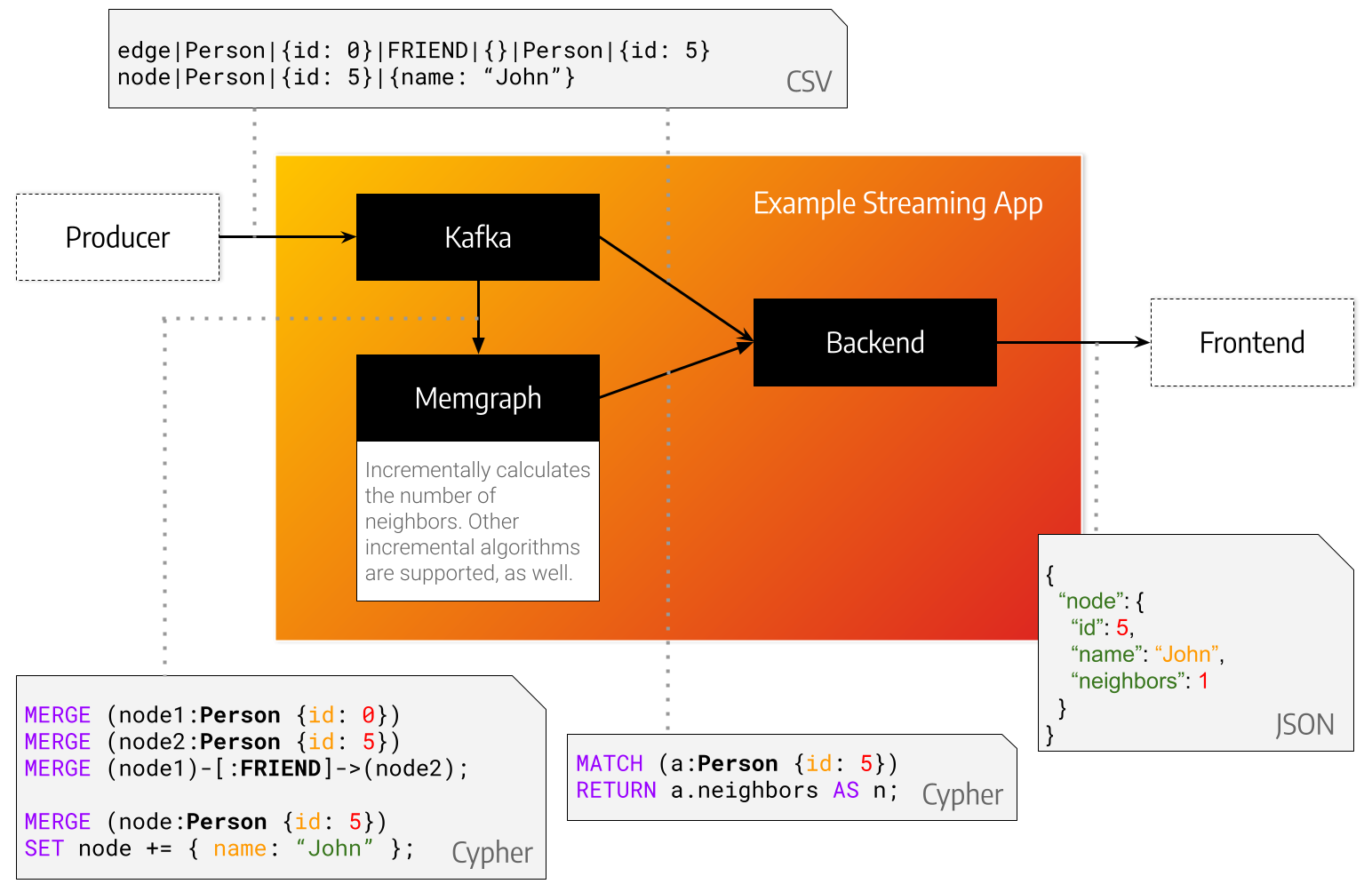
*KafkaProducer* represents the source of your data.
That can be transactions, queries, metadata or something different entirely.
In this minimal example we propose using a [special string format](./kafka) that is easy to parse.
The data is sent from the *KafkaProducer* to *Kafka* under a topic aptly named *topic*.
The *Backend* implements a *KafkaConsumer*.
It takes data from *Kafka*, consumes it, but also queries *Memgraph* for graph analysis, feature extraction or storage.
## Installation
Install [Kafka](./kafka) and [Memgraph](./memgraph) using the instructions in the homonymous directories.
Then choose a programming language from the list of supported languages and follow the instructions given there.
### List of supported programming languages
- [c#](./backend/cs)
- [go](./backend/go)
- [java](./backend/java)
- [node](./backend/node)
- [python](./backend/python)
- [rust](./backend/rust)
## How does it work *exactly*
### KafkaProducer
The *KafkaProducer* in [./kafka/producer](./kafka/producer) creates nodes with a label *Person* that are connected with edges of type *CONNECTED_WITH*.
In this repository we provide a static producer that reads entries from a file and a stream producer that produces entries every *X* seconds.
### Backend
The *backend* takes a message at a time from kafka, parses it with a csv parser as a line, converts it into a `openCypher` query and sends it to Memgraph.
After storing a node in Memgraph the backend asks Memgraph how many adjacent nodes does it have and prints it to the terminal.
### Memgraph
You can think of Memgraph as two separate components: a storage engine and an algorithm execution engine.
First we create a [trigger](./memgraph/queries/create_trigger.cypher): an algorithm that will be run every time a node is inserted.
This algorithm calculates and updates the number of neighbors of each affected node after every query is executed.