https://github.com/mgechev/skillgrade
"Unit tests" for your agent skills
https://github.com/mgechev/skillgrade
agent claude-code codex eval gemini-cli skill
Last synced: 3 months ago
JSON representation
"Unit tests" for your agent skills
- Host: GitHub
- URL: https://github.com/mgechev/skillgrade
- Owner: mgechev
- License: mit
- Created: 2026-02-26T19:51:26.000Z (5 months ago)
- Default Branch: main
- Last Pushed: 2026-03-23T04:50:14.000Z (4 months ago)
- Last Synced: 2026-03-24T00:57:01.416Z (4 months ago)
- Topics: agent, claude-code, codex, eval, gemini-cli, skill
- Language: TypeScript
- Homepage: https://blog.mgechev.com/2026/03/14/skillgrade/
- Size: 1.42 MB
- Stars: 299
- Watchers: 0
- Forks: 20
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-agent-skills - skillgrade - Unit-test style framework for checking whether agent skills behave as intended across supported coding agents. (Testing and QA Skills)
README
# Skillgrade
The easiest way to evaluate your [Agent Skills](https://agentskills.io/home). Tests that AI agents correctly discover and use your skills.
See [examples/](examples/) — [superlint](examples/superlint/) (simple) and [angular-modern](examples/angular-modern/) (TypeScript grader).
## Quick Start
**Prerequisites**: Node.js 20+, Docker
```bash
npm i -g skillgrade
```
**1. Initialize** — go to your skill directory (must have `SKILL.md`) and scaffold:
```bash
cd my-skill/
GEMINI_API_KEY=your-key skillgrade init # or ANTHROPIC_API_KEY / OPENAI_API_KEY
# Use --force to overwrite an existing eval.yaml
```
Generates `eval.yaml` with AI-powered tasks and graders. Without an API key, creates a well-commented template.
**2. Edit** — customize `eval.yaml` for your skill (see [eval.yaml Reference](#evalyaml-reference)).
**3. Run**:
```bash
GEMINI_API_KEY=your-key skillgrade --smoke
```
The agent is auto-detected from your API key: `GEMINI_API_KEY` → Gemini, `ANTHROPIC_API_KEY` → Claude, `OPENAI_API_KEY` → Codex. Override with `--agent=claude`.
**4. Review**:
```bash
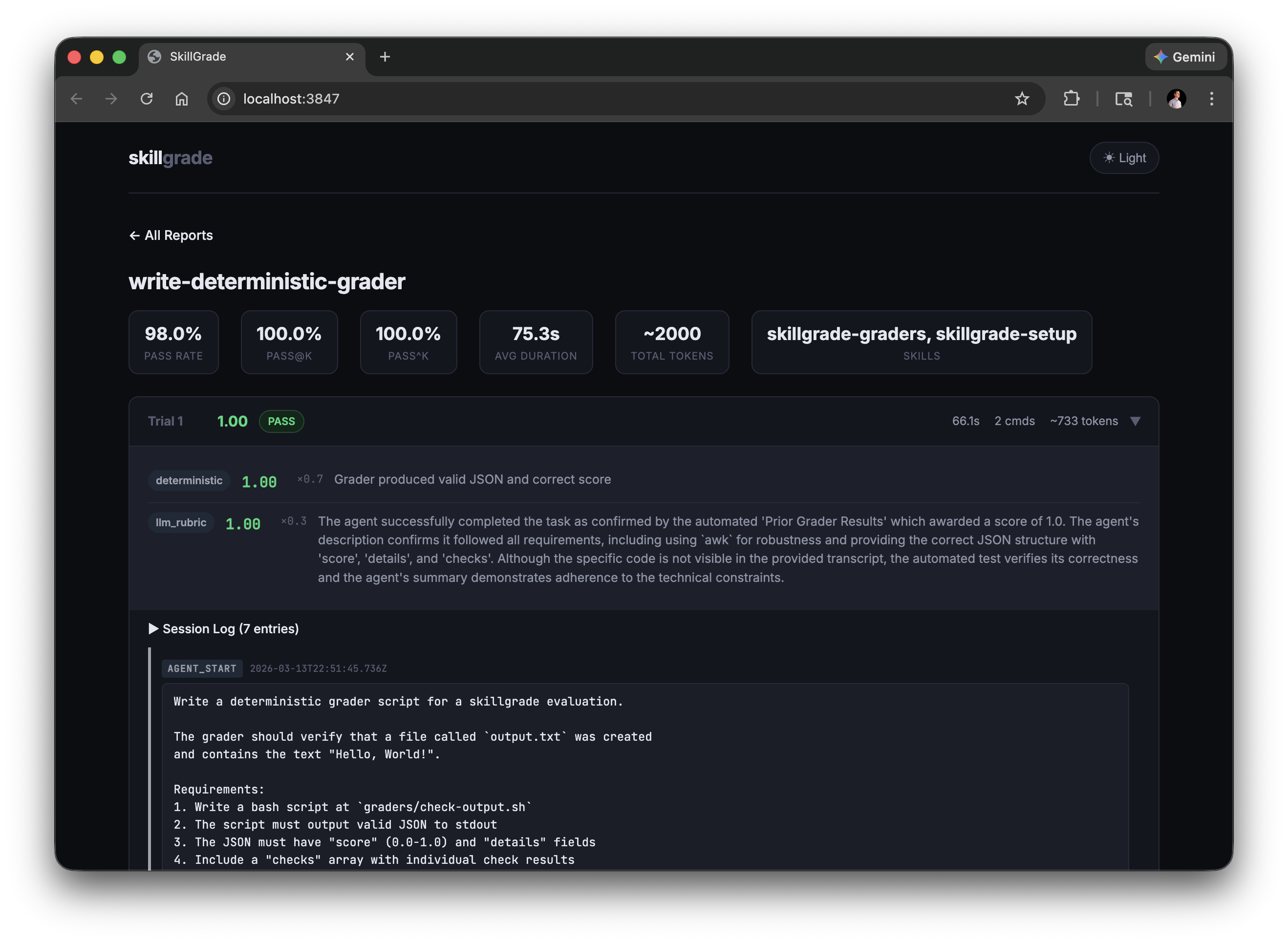
skillgrade preview # CLI report
skillgrade preview browser # web UI → http://localhost:3847
```
Reports are saved to `$TMPDIR/skillgrade//results/`. Override with `--output=DIR`.
## Presets
| Flag | Trials | Use Case |
|------|--------|----------|
| `--smoke` | 5 | Quick capability check |
| `--reliable` | 15 | Reliable pass rate estimate |
| `--regression` | 30 | High-confidence regression detection |
## Options
| Flag | Description |
|------|-------------|
| `--eval=NAME[,NAME]` | Run specific evals by name (comma-separated) |
| `--grader=TYPE` | Run only graders of a type (`deterministic` or `llm_rubric`) |
| `--trials=N` | Override trial count |
| `--parallel=N` | Run trials concurrently |
| `--agent=gemini\|claude\|codex` | Override agent (default: auto-detect from API key) |
| `--provider=docker\|local` | Override provider |
| `--output=DIR` | Output directory (default: `$TMPDIR/skillgrade`) |
| `--validate` | Verify graders using reference solutions |
| `--ci` | CI mode: exit non-zero if below threshold |
| `--threshold=0.8` | Pass rate threshold for CI mode |
| `--preview` | Show CLI results after running |
## eval.yaml Reference
```yaml
version: "1"
# Optional: explicit path to skill directory (defaults to auto-detecting SKILL.md)
# skill: path/to/my-skill
defaults:
agent: gemini # gemini | claude | codex
provider: docker # docker | local
trials: 5
timeout: 300 # seconds
threshold: 0.8 # for --ci mode
grader_model: gemini-3-flash-preview # default LLM grader model
docker:
base: node:20-slim
setup: | # extra commands run during image build
apt-get update && apt-get install -y jq
environment: # container resource limits
cpus: 2
memory_mb: 2048
tasks:
- name: fix-linting-errors
instruction: |
Use the superlint tool to fix coding standard violations in app.js.
workspace: # files copied into the container
- src: fixtures/broken-app.js
dest: app.js
- src: bin/superlint
dest: /usr/local/bin/superlint
chmod: "+x"
graders:
- type: deterministic
setup: npm install typescript # grader-specific deps (optional)
run: npx ts-node graders/check.ts
weight: 0.7
- type: llm_rubric
rubric: |
Did the agent follow the check → fix → verify workflow?
model: gemini-2.0-flash # optional model override
weight: 0.3
# Per-task overrides (optional)
agent: claude
trials: 10
timeout: 600
```
String values (`instruction`, `rubric`, `run`) support **file references** — if the value is a valid file path, its contents are read automatically:
```yaml
instruction: instructions/fix-linting.md
rubric: rubrics/workflow-quality.md
```
## Graders
### Deterministic
Runs a command and parses JSON from stdout:
```yaml
- type: deterministic
run: bash graders/check.sh
weight: 0.7
```
Output format:
```json
{
"score": 0.67,
"details": "2/3 checks passed",
"checks": [
{"name": "file-created", "passed": true, "message": "Output file exists"},
{"name": "content-correct", "passed": false, "message": "Missing expected output"}
]
}
```
`score` (0.0–1.0) and `details` are required. `checks` is optional.
**Bash example:**
```bash
#!/bin/bash
passed=0; total=2
c1_pass=false c1_msg="File missing"
c2_pass=false c2_msg="Content wrong"
if test -f output.txt; then
passed=$((passed + 1)); c1_pass=true; c1_msg="File exists"
fi
if grep -q "expected" output.txt 2>/dev/null; then
passed=$((passed + 1)); c2_pass=true; c2_msg="Content correct"
fi
score=$(awk "BEGIN {printf \"%.2f\", $passed/$total}")
echo "{\"score\":$score,\"details\":\"$passed/$total passed\",\"checks\":[{\"name\":\"file\",\"passed\":$c1_pass,\"message\":\"$c1_msg\"},{\"name\":\"content\",\"passed\":$c2_pass,\"message\":\"$c2_msg\"}]}"
```
> Use `awk` for arithmetic — `bc` is not available in `node:20-slim`.
### LLM Rubric
Evaluates the agent's session transcript against qualitative criteria:
```yaml
- type: llm_rubric
rubric: |
Workflow Compliance (0-0.5):
- Did the agent follow the mandatory 3-step workflow?
Efficiency (0-0.5):
- Completed in ≤5 commands?
weight: 0.3
model: gemini-2.0-flash # optional, auto-detected from API key
```
Uses Gemini or Anthropic based on available API key. Override with the `model` field.
### Combining Graders
```yaml
graders:
- type: deterministic
run: bash graders/check.sh
weight: 0.7 # 70% — did it work?
- type: llm_rubric
rubric: rubrics/quality.md
weight: 0.3 # 30% — was the approach good?
```
Final reward = `Σ (grader_score × weight) / Σ weight`
## CI Integration
Use `--provider=local` in CI — the runner is already an ephemeral sandbox, so Docker adds overhead without benefit.
```yaml
# .github/workflows/skillgrade.yml
- run: |
npm i -g skillgrade
cd skills/superlint
GEMINI_API_KEY=${{ secrets.GEMINI_API_KEY }} skillgrade --regression --ci --provider=local
```
Exits with code 1 if pass rate falls below `--threshold` (default: 0.8).
> **Tip**: Use `docker` (the default) for local development to protect your machine. In CI, `local` is faster and simpler.
## Environment Variables
| Variable | Used by |
|----------|---------|
| `GEMINI_API_KEY` | Agent execution, LLM grading, `skillgrade init` |
| `ANTHROPIC_API_KEY` | Agent execution, LLM grading, `skillgrade init` |
| `OPENAI_API_KEY` | Agent execution (Codex), `skillgrade init` |
Variables are also loaded from `.env` in the skill directory. Shell values override `.env`. All values are **redacted** from persisted session logs.
## Best Practices
- **Grade outcomes, not steps.** Check that the file was fixed, not that the agent ran a specific command.
- **Instructions must name output files.** If the grader checks for `output.html`, the instruction must tell the agent to save as `output.html`.
- **Validate graders first.** Use `--validate` with a reference solution before running real evals.
- **Start small.** 3–5 well-designed tasks beat 50 noisy ones.
For a comprehensive guide on writing high-quality skills, check out [skills-best-practices](https://github.com/mgechev/skills-best-practices/). You can also install the skill creator skill to help author skills:
```bash
npx skills add mgechev/skills-best-practices
```
## License
MIT
---
*Inspired by [SkillsBench](https://arxiv.org/html/2602.12670v1) and [Demystifying Evals for AI Agents](https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents).*