https://github.com/mikeroyal/apache-ignite-guide
Apache Ignite Guide
https://github.com/mikeroyal/apache-ignite-guide
data-science database hadoop hadoop-cluster ignite nosql nosql-data-storage nosql-databases stream-processing streaming
Last synced: about 1 year ago
JSON representation
Apache Ignite Guide
- Host: GitHub
- URL: https://github.com/mikeroyal/apache-ignite-guide
- Owner: mikeroyal
- Created: 2021-10-14T21:44:25.000Z (almost 5 years ago)
- Default Branch: main
- Last Pushed: 2021-10-14T22:14:08.000Z (almost 5 years ago)
- Last Synced: 2025-03-31T01:51:39.686Z (over 1 year ago)
- Topics: data-science, database, hadoop, hadoop-cluster, ignite, nosql, nosql-data-storage, nosql-databases, stream-processing, streaming
- Homepage:
- Size: 162 KB
- Stars: 11
- Watchers: 2
- Forks: 4
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README

Apache Ignite Guide
#### A guide covering Apache Ignite including the applications, libraries and tools that will make you better and more efficient with Apache Ignite development.
**Note: You can easily convert this markdown file to a PDF in [VSCode](https://code.visualstudio.com/) using this handy extension [Markdown PDF](https://marketplace.visualstudio.com/items?itemName=yzane.markdown-pdf).**


Applications Acceleration & Data Caching with Apache Ignite. Source: [Apache Ignite](https://ignite.apache.org/use-cases/in-memory-data-grid.html)
# Table of Contents
1. [Apache Ignite Learning Resources](https://github.com/mikeroyal/Apache-Ignite-Guide#Apache-Ignite-learning-resources)
2. [Apache Ignite Tools, Libraries, and Frameworks](https://github.com/mikeroyal/Apache-Ignite-Guide#Apache-Ignite-tools-libraries-and-frameworks)
3. [Kubernetes](https://github.com/mikeroyal/Apache-Ignite-Guide#kubernetes)
4. [Docker](https://github.com/mikeroyal/Apache-Ignite-Guide#docker)
5. [Machine Learning](https://github.com/mikeroyal/Apache-Ignite-Guide#machine-learning)
6. [Algorithms](https://github.com/mikeroyal/Apache-Ignite-Guide#Algorithms)
7. [Deep Learning Development](https://github.com/mikeroyal/Apache-Ignite-Guide#Deep-Learning-Development)
8. [Reinforcement Learning Development](https://github.com/mikeroyal/Apache-Ignite-Guide#Reinforcement-Learning-Development)
9. [Computer Vision Development](https://github.com/mikeroyal/Apache-Ignite-Guide#computer-vision-development)
10. [Natural Language Processing (NLP) Development](https://github.com/mikeroyal/Apache-Ignite-Guide#nlp-development)
11. [Bioinformatics](https://github.com/mikeroyal/Apache-Ignite-Guide#bioinformatics)
12. [Databases](https://github.com/mikeroyal/Apache-Ignite-Guide#databases)
13. [CUDA Development](https://github.com/mikeroyal/Apache-Ignite-Guide#cuda-development)
14. [MATLAB Development](https://github.com/mikeroyal/Apache-Ignite-Guide#matlab-development)
15. [Java Development](https://github.com/mikeroyal/Apache-Ignite-Guide#java-development)
16. [C/C++ Development](https://github.com/mikeroyal/Apache-Ignite-Guide#cc-development)
17. [C# Development](https://github.com/mikeroyal/Apache-Ignite-Guide#c-development)
18. [Python Development](https://github.com/mikeroyal/Apache-Ignite-Guide#python-development)
19. [Go Development](https://github.com/mikeroyal/Apache-Ignite-Guide#go-development)
20. [Scala Development](https://github.com/mikeroyal/Apache-Ignite-Guide#scala-development)
21. [R Development](https://github.com/mikeroyal/Apache-Ignite-Guide#r-development)
# Apache Ignite Learning Resources
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)
[Apache Ignite®](https://ignite.apache.org/) is a distributed database for high-performance computing with in-memory speed. Ignite's main goal is to provide performance and scalability by partitioning and distributing data within a cluster. The cluster provides very fast data processing.
[Getting Strated with Apache Ignite](https://ignite.apache.org/docs/latest/index)
[Ignite Community Resources](https://ignite.apache.org/community/resources.html)
[Ignite Wiki](https://cwiki.apache.org/confluence/display/IGNITE/)
[Ignite Book](https://www.shamimbhuiyan.com/ignitebook)
[Ignite Videos & Presentations](https://ignite.apache.org/screencasts.html)
[GridGain Training and Certification | GridGain Systems](https://www.gridgain.com/services/training)
[Getting Started with Apache Ignite | Pluralsight](https://www.pluralsight.com/courses/apache-ignite-getting-started)
[Apache Ignite Training Courses | NobleProg](https://www.nobleprog.com/apache-ignite-training)
[Accelerating End-to-End Data Science Workflows | Deep Learning Institute | NVIDIA](https://courses.nvidia.com/courses/course-v1:DLI+S-DS-01+V1/about)
[Introducing Apache Arrow | Cloudera](https://blog.cloudera.com/introducing-apache-arrow-a-fast-interoperable-in-memory-columnar-data-structure-standard/)
[Understanding Apache Arrow Flight | Dremio](https://www.dremio.com/understanding-apache-arrow-flight)
[Apache Arrow in PySpark | Apache Spark](http://spark.apache.org/docs/latest/api/python/user_guide/arrow_pandas.html)
[PySpark Usage Guide for Pandas with Apache Arrow | Apache Spark](https://spark.apache.org/docs/2.4.0/sql-pyspark-pandas-with-arrow.html)
[Apache Arrow Training Courses | NobleProg](https://www.nobleprog.com/apache-arrow-training)
[Apache Spark Quick Start](https://spark.apache.org/docs/latest/quick-start.html)
[What is Apache Spark? | IBM](https://www.ibm.com/cloud/learn/apache-spark)
[Introduction to Apache Spark and Analytics | AWS](https://aws.amazon.com/big-data/what-is-spark/)
[Apache Spark 3.0: For Analytics & Machine Learning | NVIDIA](https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-science/apache-spark-3/)
[.NET for Apache Spark™ | Big data analytics](https://dotnet.microsoft.com/apps/data/spark)
[Apache Spark Basics | MATLAB & Simulink](https://www.mathworks.com/help//compiler/spark/apache-spark-basics.html)
[MATLAB Hadoop and Spark | MATLAB & Simulink](https://www.mathworks.com/products/compiler/hadoop-and-spark.html)
[Top Apache Spark Courses Online | Coursera](https://www.coursera.org/courses?query=apache%20spark)
[Top Apache Spark Courses Online | Udemy](https://www.udemy.com/topic/apache-spark/)
[Apache Spark In-Depth (Spark with Scala) | Udemy](https://www.udemy.com/course/apache-spark-in-depth-spark-with-scala/)
[Learn Apache Spark with Online Courses | edX](https://www.edx.org/learn/apache-spark)
[Apache Spark Essential Training Online Class | LinkedIn Learning](https://www.linkedin.com/learning/apache-spark-essential-training)
[Cloudera Developer Training for Apache Spark™ and Hadoop | Cloudera](https://www.cloudera.com/about/training/courses/developer-training-for-spark-and-hadoop.html)
[Databricks Certified Associate Developer for Apache Spark 3.0 certification | Databricks](https://academy.databricks.com/exam/databricks-certified-associate-developer)
[Apache Spark Training Courses | NobleProg](https://www.nobleprog.com/apache-spark-training)
# Apache Ignite Tools, Libraries, and Frameworks
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)
[Zabbix](https://www.zabbix.com/integrations/ignite#tab:official1) is an open-source monitoring software tool for diverse IT components, including networks, servers, virtual machines and cloud services. Zabbix provides monitoring metrics, among others network utilization, CPU load and disk space consumption.
[Prometheus](https://prometheus.io) is an open source systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts when specified conditions are observed. Prometheus is a [Cloud Native Computing Foundation project](https://cncf.io/), though, it was originally built at [SoundCloud](https://soundcloud.com/).
[Grafana](https://grafana.com/) is an open and composable observability and data visualization platform. It visualizes metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
[Ganglia](https://developer.nvidia.com/ganglia-monitoring-system) is an open-source scalable distributed monitoring system for high-performance computing systems such as clusters and Grids. It is carefully engineered to achieve very low per-node overheads and high concurrency.
[Graphite](https://github.com/graphite-project/graphite-web) is an enterprise-ready monitoring tool that runs equally well on cheap hardware or Cloud infrastructure. Teams use Graphite to track the performance of their websites, applications, business services, and networked servers.
[Carbon](https://github.com/graphite-project/carbon) is one of the components of Graphite, and is responsible for receiving metrics over the network and writing them down to disk using a storage backend.
[Whisper](https://github.com/graphite-project/whisper) is a fixed-size database, similar in design and purpose to RRD (round-robin-database). It provides fast, reliable storage of numeric data over time. Whisper allows for higher resolution (seconds per point) of recent data to degrade into lower resolutions for long-term retention of historical data.
[AppDynamics](https://www.appdynamics.com/) is an observability and data visualization platform that provides industry-leading application performance monitoring, end user experience monitoring, hybrid cloud infrastructure monitoring, and network & security monitoring.
[Sematext](https://sematext.com) is a monitoring system for all of your development environments in real time.
[Visor Command Line tool](https://ignite.apache.org/docs/latest/tools/visor-cmd) is a tool that provides basic statistics about cluster nodes, caches, and compute tasks. It also lets you manage the size of your cluster by starting or stopping nodes.
[Control Script](https://ignite.apache.org/docs/latest/tools/control-script) is an advanced command-line utility that can change the baseline topology, activate and deactivate the cluster, perform consistency checks of your data and indexes, detect long-running or hanging transactions.
[GridGain Control Center](https://www.gridgain.com/products/software/control-center) is a management and monitoring tool for Apache Ignite that supports the following:
- Monitor the state of the cluster with customizable dashboards.
- Define custom alerts to track and react on over 200 cluster, node, and storage metrics.
- Execute and optimize SQL queries as well as monitor already running commands.
- Perform OpenCensus-based root cause analysis with visual debugging of API calls as they execute on nodes across the cluster.
- Take full, incremental, and continuous cluster backups to enable disaster recovery in the event of data loss or corruption.
[Datadog](https://www.datadoghq.com/blog/monitor-apache-ignite-with-datadog/) is a general-purpose monitoring service that integrates natively with Apache Ignite to provide the following capabilities:
- Collect and visualize metrics for your Ignite nodes through an out-of-the-box dashboard.
- Track cluster-wide memory usage, including detailed garbage collection activity.
- Use the built-in health check for Ignite to create an alert to notify you about the "node goes offline" events.
[Tableau](https://www.tableau.com) is an interactive data-visualization tool focused on business intelligence. It uses ODBC API to connect to a variety of databases and data platforms allowing to analyze data stored there. Ignite is shipped with its own implementation of the [ODBC driver](https://apacheignite.readme.io/docs/odbc-driver) which makes it possible to connect to Ignite from Tableau and analyze the data stored in a distributed Ignite cluster.
[Apache Parquet](https://parquet.apache.org/) is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
[DataFusion](https://arrow.apache.org/datafusion) is an extensible query execution framework, written in Rust, that uses [Apache Arrow](https://arrow.apache.org/) as its in-memory format. DataFusion supports both an SQL and a DataFrame API for building logical query plans as well as a query optimizer and execution engine capable of parallel execution against partitioned data sources (CSV and Parquet) using threads.
[Fletcher](https://github.com/abs-tudelft/fletcher) is a framework that helps to integrate FPGA accelerators with tools and frameworks that use Apache Arrow in their back-ends.
[Apache Flink™](https://flink.apache.org/) is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
[Apache Cassandra™](https://cassandra.apache.org/) is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Cassandra provides linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
[Apache Flume](https://flume.apache.org/) is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming event data.
[Apache Mesos](http://mesos.apache.org/) is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, Jenkins, Spark, Aurora, and other frameworks on a dynamically shared pool of nodes.
[Apache Kafka®](https://kafka.apache.org/) is a distributed data store optimized for ingesting and processing streaming data in real-time. Streaming data is data that is continuously generated by thousands of data sources, which typically send the data records in simultaneously.
[Apache Spark™](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Spark SQL](https://spark.apache.org/sql/) is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations.
[Spark Streaming](https://spark.apache.org/streaming/) is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. It can express your streaming computation the same way you would express a batch computation on static data from various sources including [Apache Kafka](https://kafka.apache.org/), [Apache Flume](https://flume.apache.org/), and [Amazon Kinesis](https://aws.amazon.com/kinesis/).
[Apache HBase™](https://hbase.apache.org/) is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data. HBase is very effective for handling large, sparse datasets. HBase serves as a direct input and output to the Apache MapReduce framework for Hadoop, and works with Apache Phoenix to enable SQL-like queries over HBase tables.
[Hadoop Distributed File System (HDFS)](https://www.ibm.com/analytics/hadoop/hdfs) is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being [MapReduce](https://www.ibm.com/analytics/hadoop/mapreduce) and [YARN](https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html).
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Apache Arrow](https://arrow.apache.org/) is a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs. Languages that have Arrow libraries (under development) include C, C++, Go, Java, JavaScript, Python, Ruby and Rust.
[Apache Beam](https://beam.apache.org/) is an open source, unified model and set of language-specific SDKs for defining and executing data processing workflows, and also data ingestion and integration flows, supporting Enterprise Integration Patterns (EIPs) and Domain Specific Languages (DSLs).
[Confluent Platform](https://docs.confluent.io/platform/current/platform.html) is a full-scale data streaming platform that enables you to easily access, store, and manage data as continuous, real-time streams. Built by the original creators of Apache Kafka®, Confluent expands the benefits of Kafka with enterprise-grade features while removing the burden of Kafka management or monitoring.
[Kafka Connec](https://docs.confluent.io/platform/current/connect/index.html) is an open source Apache Kafka framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems.
[IBM Streams](https://github.com/IBMStreams/streamsx.messaging) is a stream processing framework with Kafka source and sink to consume and produce Kafka messages.
[KaBoom](https://github.com/blackberry/KaBoom) is a high-performance HDFS data loader.
[Azkarra Streams](https://www.azkarrastreams.io/) is a lightweight java framework to make it easy to build and manage streaming microservices based on Kafka Streams.
[uReplicator](https://github.com/uber/uReplicator) is a tool that provides the ability to replicate across Kafka clusters in other data centers.
[Mirus](https://github.com/salesforce/mirus) is a tool for distributed, high-volume replication between Apache Kafka clusters based on Kafka Connect.
[Kafka Manager](https://github.com/yahoo/kafka-manager) is a tool for managing Apache Kafka.
[Kafkat](https://github.com/airbnb/kafkat) is a simplified command-line administration for Kafka brokers.
[Kafka Web Console](https://github.com/claudemamo/kafka-web-console) is a tool that displays information about your Kafka cluster including which nodes are up and what topics they host data for.
[Kafka Offset Monitor](https://quantifind.github.io/KafkaOffsetMonitor/) is a tool that displays the state of all consumers and how far behind the head of the stream they are.
[Capillary](https://github.com/keenlabs/capillary) is a tool that displays the state and deltas of Kafka-based Apache Storm topologies.
[Doctor Kafka](https://github.com/pinterest/doctorkafka) is a service for cluster auto healing and workload balancing.
[Cruise Control](https://github.com/linkedin/cruise-control) is a tool that fully automate the dynamic workload rebalance and self-healing of a Kafka cluster.
[Burrow](https://github.com/linkedin/Burrow) is a monitoring tool that provides consumer lag checking as a service without the need for specifying thresholds.
[Chaperone](https://github.com/uber/chaperone) is an audit system that monitors the completeness and latency of data stream.
[Sematext](https://sematext.com/) is an integration tool for Kafka monitoring that collects and charts 200+ Kafka metrics.
[Cloudera](https://www.cloudera.com/) is the big data software platform of choice across numerous industries, providing customers with components like Hadoop, Spark, and Hive.
[Splunk](https://www.splunk.com/en_us/software.html) is a software platform that is used for searching, monitoring, and examining machine-generated Big Data through a web interface.
[MLib](https://spark.apache.org/mllib/) is Spark’s machine learning (ML) library. Its goal is to make practical machine learning scalable and easy. It consists of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as lower-level optimization primitives and higher-level pipeline APIs.
[Graphx](https://spark.apache.org/graphx/) is the new Spark API for graphs and graph-parallel computation. At a high-level, GraphX extends the [Spark RDD](https://spark.apache.org/docs/latest/rdd-programming-guide.html) by introducing the Resilient Distributed Property Graph: a directed multigraph with properties attached to each vertex and edge.
[PySpark](https://spark.apache.org/docs/latest/api/python/index.html) is an interface for Apache Spark in Python. It not only allows you to write Spark applications using Python APIs, but also provides the PySpark shell for interactively analyzing your data in a distributed environment.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Koalas](https://github.com/databricks/koalas) is a project that makes data scientists more productive when interacting with big data, by implementing the [pandas DataFrame API](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html) on top of [Apache Spark](https://spark.apache.org/).
[MLflow](https://mlflow.org/)is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. It offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (notebooks, standalone applications or the cloud). MLflow has four main components:
- The [Tracking component](https://mlflow.org/docs/latest/tracking.html) that allows you to record machine model training sessions (called runs) and run queries using Java, Python, R, and REST APIs.
- The [Projects component](https://mlflow.org/docs/latest/projects.html) packages code that is used in data science projects to ensure it can easily be reused and experiments can be reproduced.
- The [Models component](https://mlflow.org/docs/latest/models.html) that provides a standard unit for packaging and reusing machine learning models.
- The [Model Registry](https://mlflow.org/docs/latest/model-registry.html) component that lets you centrally manage models and their lifecycle.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Dask](https://dask.org) is an open source tool that provides advanced parallelism for analytics, enabling performance at scale for the tools you love. It is developed in coordination with other community projects like NumPy, pandas, and scikit-learn.
[Dask DataFrame](https://docs.dask.org/en/latest/dataframe.html) is a large parallel DataFrame composed of many smaller Pandas DataFrames, split along the index. These Pandas DataFrames may live on disk for larger-than-memory computing on a single machine, or on many different machines in a cluster. One Dask DataFrame operation triggers many operations on the constituent Pandas DataFrames.
[Neo4j](https://neo4j.com/) is the only enterprise-strength graph database that combines native graph storage, advanced security, scalable speed-optimized architecture, and ACID compliance to ensure predictability and integrity of relationship-based queries.
[ElasticSearch](https://www.elastic.co/) is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
[Logstash](https://www.elastic.co/products/logstash) is a tool for managing events and logs. When used generically, the term encompasses a larger system of log collection, processing, storage and searching activities.
[Kibana](https://www.elastic.co/products/kibana) is an open source data visualization plugin for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster. Users can create bar, line and scatter plots, or pie charts and maps on top of large volumes of data.
[Trino](https://trino.io/) is a Distributed SQL query engine for big data. It is able to tremendously speed up [ETL processes](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl), allow them all to use standard SQL statement, and work with numerous data sources and targets all in the same system.
[Extract, transform, and load (ETL)](https://docs.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl) is a data pipeline used to collect data from various sources, transform the data according to business rules, and load it into a destination data store.
[Redis(REmote DIctionary Server)](https://redis.io/) is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. It provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.
[Apache OpenNLP](https://opennlp.apache.org/) is an open-source library for a machine learning based toolkit used in the processing of natural language text. It features an API for use cases like [Named Entity Recognition](https://en.wikipedia.org/wiki/Named-entity_recognition), [Sentence Detection](), [POS(Part-Of-Speech) tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), [Tokenization](https://en.wikipedia.org/wiki/Tokenization_(data_security)) [Feature extraction](https://en.wikipedia.org/wiki/Feature_extraction), [Chunking](https://en.wikipedia.org/wiki/Chunking_(psychology)), [Parsing](https://en.wikipedia.org/wiki/Parsing), and [Coreference resolution](https://en.wikipedia.org/wiki/Coreference).
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
# Kubernetes
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)


**Building Highly-Availability(HA) Clusters with kubeadm. Source: [Kubernetes.io](https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/)**
## Kubernetes Learning Resources
[Kubernetes (K8s)](https://kubernetes.io/) is an open-source system for automating deployment, scaling, and management of containerized applications.
[Getting Kubernetes Certifications](https://training.linuxfoundation.org/certification/catalog/?_sft_technology=kubernetes)
[Getting started with Kubernetes on AWS](https://aws.amazon.com/kubernetes/)
[Kubernetes on Microsoft Azure](https://azure.microsoft.com/en-us/topic/what-is-kubernetes/)
[Intro to Azure Kubernetes Service](https://docs.microsoft.com/en-us/azure/aks/kubernetes-dashboard)
[Azure Red Hat OpenShift ](https://azure.microsoft.com/en-us/services/openshift/)
[Getting started with Google Cloud](https://cloud.google.com/learn/what-is-kubernetes)
[Getting started with Kubernetes on Red Hat](https://www.redhat.com/en/topics/containers/what-is-kubernetes)
[Getting started with Kubernetes on IBM](https://www.ibm.com/cloud/learn/kubernetes)
[Red Hat OpenShift on IBM Cloud](https://www.ibm.com/cloud/openshift)
[Enable OpenShift Virtualization on Red Hat OpenShift](https://developers.redhat.com/blog/2020/08/28/enable-openshift-virtualization-on-red-hat-openshift/)
[YAML basics in Kubernetes](https://developer.ibm.com/technologies/containers/tutorials/yaml-basics-and-usage-in-kubernetes/)
[Elastic Cloud on Kubernetes](https://www.elastic.co/elastic-cloud-kubernetes)
[Docker and Kubernetes](https://www.docker.com/products/kubernetes)
[Running Apache Spark on Kubernetes](http://spark.apache.org/docs/latest/running-on-kubernetes.html)
[Kubernetes Across VMware vRealize Automation](https://blogs.vmware.com/management/2019/06/kubernetes-across-vmware-cloud-automation-services.html)
[VMware Tanzu Kubernetes Grid](https://tanzu.vmware.com/kubernetes-grid)
[All the Ways VMware Tanzu Works with AWS](https://tanzu.vmware.com/content/blog/all-the-ways-vmware-tanzutm-works-with-aws)
[VMware Tanzu Education](https://tanzu.vmware.com/education)
[Using Ansible in a Cloud-Native Kubernetes Environment](https://www.ansible.com/blog/how-useful-is-ansible-in-a-cloud-native-kubernetes-environment)
[Managing Kubernetes (K8s) objects with Ansible](https://docs.ansible.com/ansible/latest/collections/community/kubernetes/k8s_module.html)
[Setting up a Kubernetes cluster using Vagrant and Ansible](https://kubernetes.io/blog/2019/03/15/kubernetes-setup-using-ansible-and-vagrant/)
[Running MongoDB with Kubernetes](https://www.mongodb.com/kubernetes)
[Kubernetes Fluentd](https://docs.fluentd.org/v/0.12/articles/kubernetes-fluentd)
[Understanding the new GitLab Kubernetes Agent](https://about.gitlab.com/blog/2020/09/22/introducing-the-gitlab-kubernetes-agent/)
[Intro Local Process with Kubernetes for Visual Studio 2019](https://devblogs.microsoft.com/visualstudio/introducing-local-process-with-kubernetes-for-visual-studio%E2%80%AF2019/)
[Kubernetes Contributors](https://www.kubernetes.dev/)
[KubeAcademy from VMware](https://kube.academy/)
[Kubernetes Tutorials from Pulumi](https://www.pulumi.com/docs/tutorials/kubernetes/)
[Kubernetes Playground by Katacoda](https://www.katacoda.com/courses/kubernetes/playground)
[Scalable Microservices with Kubernetes course from Udacity ](https://www.udacity.com/course/scalable-microservices-with-kubernetes--ud615)
## Kubernetes Tools, Frameworks, and Projects
[Open Container Initiative](https://opencontainers.org/about/overview/) is an open governance structure for the express purpose of creating open industry standards around container formats and runtimes.
[Buildah](https://buildah.io/) is a command line tool to build Open Container Initiative (OCI) images. It can be used with Docker, Podman, Kubernetes.
[Podman](https://podman.io/) is a daemonless, open source, Linux native tool designed to make it easy to find, run, build, share and deploy applications using Open Containers Initiative (OCI) Containers and Container Images. Podman provides a command line interface (CLI) familiar to anyone who has used the Docker Container Engine.
[Containerd](https://containerd.io) is a daemon that manages the complete container lifecycle of its host system, from image transfer and storage to container execution and supervision to low-level storage to network attachments and beyond. It is available for Linux and Windows.
[Google Kubernetes Engine (GKE)](https://cloud.google.com/kubernetes-engine/) is a managed, production-ready environment for running containerized applications.
[Azure Kubernetes Service (AKS)](https://azure.microsoft.com/en-us/services/kubernetes-service/) is serverless Kubernetes, with a integrated continuous integration and continuous delivery (CI/CD) experience, and enterprise-grade security and governance. Unite your development and operations teams on a single platform to rapidly build, deliver, and scale applications with confidence.
[Amazon EKS](https://docs.aws.amazon.com/eks/latest/userguide/what-is-eks.html) is a tool that runs Kubernetes control plane instances across multiple Availability Zones to ensure high availability.
[AWS Controllers for Kubernetes (ACK)](https://aws.amazon.com/blogs/containers/aws-controllers-for-kubernetes-ack/) is a new tool that lets you directly manage AWS services from Kubernetes. ACK makes it simple to build scalable and highly-available Kubernetes applications that utilize AWS services.
[Container Engine for Kubernetes (OKE)](https://www.oracle.com/cloud-native/container-engine-kubernetes/) is an Oracle-managed container orchestration service that can reduce the time and cost to build modern cloud native applications. Unlike most other vendors, Oracle Cloud Infrastructure provides Container Engine for Kubernetes as a free service that runs on higher-performance, lower-cost compute.
[Anthos](https://cloud.google.com/anthos/docs/concepts/overview) is a modern application management platform that provides a consistent development and operations experience for cloud and on-premises environments.
[Red Hat Openshift](https://www.openshift.com/) is a fully managed Kubernetes platform that provides a foundation for on-premises, hybrid, and multicloud deployments.
[OKD](https://okd.io/) is a community distribution of Kubernetes optimized for continuous application development and multi-tenant deployment. OKD adds developer and operations-centric tools on top of Kubernetes to enable rapid application development, easy deployment and scaling, and long-term lifecycle maintenance for small and large teams.
[Odo](https://odo.dev/) is a fast, iterative, and straightforward CLI tool for developers who write, build, and deploy applications on Kubernetes and OpenShift.
[Kata Operator](https://github.com/openshift/kata-operator) is an operator to perform lifecycle management (install/upgrade/uninstall) of [Kata Runtime](https://katacontainers.io/) on Openshift as well as Kubernetes cluster.
[Thanos](https://thanos.io/) is a set of components that can be composed into a highly available metric system with unlimited storage capacity, which can be added seamlessly on top of existing Prometheus deployments.
[OpenShift Hive](https://github.com/openshift/hive) is an operator which runs as a service on top of Kubernetes/OpenShift. The Hive service can be used to provision and perform initial configuration of OpenShift 4 clusters.
[Rook](https://rook.io/) is a tool that turns distributed storage systems into self-managing, self-scaling, self-healing storage services. It automates the tasks of a storage administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management.
[VMware Tanzu](https://tanzu.vmware.com/tanzu) is a centralized management platform for consistently operating and securing your Kubernetes infrastructure and modern applications across multiple teams and private/public clouds.
[Kubespray](https://kubespray.io/) is a tool that combines Kubernetes and Ansible to easily install Kubernetes clusters that can be deployed on [AWS](https://github.com/kubernetes-sigs/kubespray/blob/master/docs/aws.md), GCE, [Azure](https://github.com/kubernetes-sigs/kubespray/blob/master/docs/azure.md), [OpenStack](https://github.com/kubernetes-sigs/kubespray/blob/master/docs/openstack.md), [vSphere](https://github.com/kubernetes-sigs/kubespray/blob/master/docs/vsphere.md), [Packet](https://github.com/kubernetes-sigs/kubespray/blob/master/docs/packet.md) (bare metal), Oracle Cloud Infrastructure (Experimental), or Baremetal.
[KubeInit](https://github.com/kubeinit/kubeinit) provides Ansible playbooks and roles for the deployment and configuration of multiple Kubernetes distributions.
[Rancher](https://rancher.com/) is a complete software stack for teams adopting containers. It addresses the operational and security challenges of managing multiple Kubernetes clusters, while providing DevOps teams with integrated tools for running containerized workloads.
[K3s](https://github.com/rancher/k3s) is a highly available, certified Kubernetes distribution designed for production workloads in unattended, resource-constrained, remote locations or inside IoT appliances.
[Helm](https://helm.sh/) is a Kubernetes Package Manager tool that makes it easier to install and manage Kubernetes applications.
[Knative](https://knative.dev/) is a Kubernetes-based platform to build, deploy, and manage modern serverless workloads. Knative takes care of the operational overhead details of networking, autoscaling (even to zero), and revision tracking.
[KubeFlow](https://www.kubeflow.org/) is a tool dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable.
[Etcd](https://etcd.io/) is a distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. Etcd is used as the backend for service discovery and stores cluster state and configuration for Kubernetes.
[OpenEBS](https://openebs.io/) is a Kubernetes-based tool to create stateful applications using Container Attached Storage.
[Container Storage Interface (CSI)](https://www.architecting.it/blog/container-storage-interface/) is an API that lets container orchestration platforms like Kubernetes seamlessly communicate with stored data via a plug-in.
[MicroK8s](https://microk8s.io/) is a tool that delivers the full Kubernetes experience. In a Fully containerized deployment with compressed over-the-air updates for ultra-reliable operations. It is supported on Linux, Windows, and MacOS.
[Charmed Kubernetes](https://ubuntu.com/kubernetes/features) is a well integrated, turn-key, conformant Kubernetes platform, optimized for your multi-cloud environments developed by Canonical.
[Grafana Kubernetes App](https://grafana.com/grafana/plugins/grafana-kubernetes-app) is a toll that allows you to monitor your Kubernetes cluster's performance. It includes 4 dashboards, Cluster, Node, Pod/Container and Deployment. It allows for the automatic deployment of the required Prometheus exporters and a default scrape config to use with your in cluster Prometheus deployment.
[KubeEdge](https://kubeedge.io/en/) is an open source system for extending native containerized application orchestration capabilities to hosts at Edge.It is built upon kubernetes and provides fundamental infrastructure support for network, app. deployment and metadata synchronization between cloud and edge.
[Lens](https://k8slens.dev/) is the most powerful IDE for people who need to deal with Kubernetes clusters on a daily basis. It has support for MacOS, Windows and Linux operating systems.
[kind](https://kind.sigs.k8s.io/) is a tool for running local Kubernetes clusters using Docker container “nodes”. It was primarily designed for testing Kubernetes itself, but may be used for local development or CI.
[Flux CD](https://fluxcd.io/) is a tool that automatically ensures that the state of your Kubernetes cluster matches the configuration you've supplied in Git. It uses an operator in the cluster to trigger deployments inside Kubernetes, which means that you don't need a separate continuous delivery tool.
[Platform9 Managed Kubernetes (PMK)](https://platform9.com/managed-kubernetes/) is a Kubernetes as a service that ensures fully automated Day-2 operations with 99.9% SLA on any environment, whether in data-centers, public clouds, or at the edge.
# Docker
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)


**Container Architecture. Source: [Containerd.io](https://containerd.io)**
## Docker Learning Resources
[Docker Training Program](https://www.docker.com/dockercon/training)
[Docker Certified Associate (DCA) certification](https://training.mirantis.com/dca-certification-exam/)
[Docker Documentation | Docker Documentation](https://docs.docker.com/)
[The Docker Workshop](https://courses.packtpub.com/courses/docker)
[Docker Courses on Udemy](https://www.udemy.com/topic/docker/)
[Docker Courses on Coursera](https://www.coursera.org/courses?query=docker)
[Docker Courses on edX](https://www.edx.org/learn/docker)
[Docker Courses on Linkedin Learning](https://www.linkedin.com/learning/topics/docker)
## Docker Tools
[Docker](https://www.docker.com/) is an open platform for developing, shipping, and running applications. Docker enables you to separate your applications from your infrastructure so you can deliver software quickly working in collaboration with cloud, Linux, and Windows vendors, including Microsoft.
[Docker Enterprise](https://www.mirantis.com/software/docker/docker-enterprise/) is a subscription including software, supported and certified container platform for CentOS, Red Hat Enterprise Linux (RHEL), Ubuntu, SUSE Linux Enterprise Server (SLES), Oracle Linux, and Windows Server 2016, as well as for cloud providers AWS and Azure. In [November 2019 Docker's Enterprise Platform business was acquired by Mirantis](https://www.mirantis.com/company/press-center/company-news/mirantis-acquires-docker-enterprise/).
[Docker Desktop](https://www.docker.com/products/docker-desktop) is an application for MacOS and Windows machines for the building and sharing of containerized applications and microservices. Docker Desktop delivers the speed, choice and security you need for designing and delivering containerized applications on your desktop. Docker Desktop includes Docker App, developer tools, Kubernetes and version synchronization to production Docker Engines.
[Docker Hub](https://hub.docker.com/) is the world's largest library and community for container images Browse over 100,000 container images from software vendors, open-source projects, and the community.
[Docker Compose](https://docs.docker.com/compose/) is a tool that was developed to help define and share multi-container applications. With Docker Compose, you can create a YAML file to define the services and with a single command, can spin everything up or tear it all down.
[Docker Swarm](https://docs.docker.com/engine/swarm/) is a Docker-native clustering system swarm is a simple tool which controls a cluster of Docker hosts and exposes it as a single "virtual" host.
[Dockerfile](https://docs.docker.com/engine/reference/builder/) is a text document that contains all the commands a user could call on the command line to assemble an image. Using docker build users can create an automated build that executes several command-line instructions in succession.
[Docker Containers](https://www.docker.com/resources/what-container) is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
[Docker Engine](https://www.docker.com/products/container-runtime) is a container runtime that runs on various Linux (CentOS, Debian, Fedora, Oracle Linux, RHEL, SUSE, and Ubuntu) and Windows Server operating systems. Docker creates simple tooling and a universal packaging approach that bundles up all application dependencies inside a container which is then run on Docker Engine.
[Docker Images](https://docs.docker.com/engine/reference/commandline/images/) is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings. Images have intermediate layers that increase reusability, decrease disk usage, and speed up docker build by allowing each step to be cached. These intermediate layers are not shown by default. The SIZE is the cumulative space taken up by the image and all its parent images.
[Docker Network](https://docs.docker.com/engine/reference/commandline/network/) is a that displays detailed information on one or more networks.
[Docker Daemon](https://docs.docker.com/config/daemon/) is a service started by a system utility, not manually by a user. This makes it easier to automatically start Docker when the machine reboots. The command to start Docker depends on your operating system. Currently, it only runs on Linux because it depends on a number of Linux kernel features, but there are a few ways to run Docker on MacOS and Windows as well by configuring the operating system utilities.
[Docker Storage](https://docs.docker.com/storage/storagedriver/select-storage-driver/) is a driver controls how images and containers are stored and managed on your Docker host.
[Kitematic](https://kitematic.com/) is a simple application for managing Docker containers on Mac, Linux and Windows letting you control your app containers from a graphical user interface (GUI).
[Open Container Initiative](https://opencontainers.org/about/overview/) is an open governance structure for the express purpose of creating open industry standards around container formats and runtimes.
[Buildah](https://buildah.io/) is a command line tool to build Open Container Initiative (OCI) images. It can be used with Docker, Podman, Kubernetes.
[Podman](https://podman.io/) is a daemonless, open source, Linux native tool designed to make it easy to find, run, build, share and deploy applications using Open Containers Initiative (OCI) Containers and Container Images. Podman provides a command line interface (CLI) familiar to anyone who has used the Docker Container Engine.
[Containerd](https://containerd.io) is a daemon that manages the complete container lifecycle of its host system, from image transfer and storage to container execution and supervision to low-level storage to network attachments and beyond. It is available for Linux and Windows.
# Machine Learning
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)

## Learning Resources for ML
[Machine Learning](https://www.ibm.com/cloud/learn/machine-learning) is a branch of artificial intelligence (AI) focused on building apps using algorithms that learn from data models and improve their accuracy over time without needing to be programmed.
[Machine Learning by Stanford University from Coursera](https://www.coursera.org/learn/machine-learning)
[AWS Training and Certification for Machine Learning (ML) Courses](https://aws.amazon.com/training/learning-paths/machine-learning/)
[Machine Learning Scholarship Program for Microsoft Azure from Udacity](https://www.udacity.com/scholarships/machine-learning-scholarship-microsoft-azure)
[Microsoft Certified: Azure Data Scientist Associate](https://docs.microsoft.com/en-us/learn/certifications/azure-data-scientist)
[Microsoft Certified: Azure AI Engineer Associate](https://docs.microsoft.com/en-us/learn/certifications/azure-ai-engineer)
[Azure Machine Learning training and deployment](https://docs.microsoft.com/en-us/azure/devops/pipelines/targets/azure-machine-learning)
[Learning Machine learning and artificial intelligence from Google Cloud Training](https://cloud.google.com/training/machinelearning-ai)
[Machine Learning Crash Course for Google Cloud](https://developers.google.com/machine-learning/crash-course/)
[JupyterLab](https://jupyterlab.readthedocs.io/)
[Scheduling Jupyter notebooks on Amazon SageMaker ephemeral instances](https://aws.amazon.com/blogs/machine-learning/scheduling-jupyter-notebooks-on-sagemaker-ephemeral-instances/)
[How to run Jupyter Notebooks in your Azure Machine Learning workspace](https://docs.microsoft.com/en-us/azure/machine-learning/how-to-run-jupyter-notebooks)
[Machine Learning Courses Online from Udemy](https://www.udemy.com/topic/machine-learning/)
[Machine Learning Courses Online from Coursera](https://www.coursera.org/courses?query=machine%20learning&)
[Learn Machine Learning with Online Courses and Classes from edX](https://www.edx.org/learn/machine-learning)
## ML Frameworks, Libraries, and Tools
[TensorFlow](https://www.tensorflow.org) is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
[Keras](https://keras.io) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.It was developed with a focus on enabling fast experimentation. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML.
[PyTorch](https://pytorch.org) is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. Primarily developed by Facebook's AI Research lab.
[Amazon SageMaker](https://aws.amazon.com/sagemaker/) is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[Apple CoreML](https://developer.apple.com/documentation/coreml) is a framework that helps integrate machine learning models into your app. Core ML provides a unified representation for all models. Your app uses Core ML APIs and user data to make predictions, and to train or fine-tune models, all on the user's device. A model is the result of applying a machine learning algorithm to a set of training data. You use a model to make predictions based on new input data.
[Tensorflow_macOS](https://github.com/apple/tensorflow_macos) is a Mac-optimized version of TensorFlow and TensorFlow Addons for macOS 11.0+ accelerated using Apple's ML Compute framework.
[Apache OpenNLP](https://opennlp.apache.org/) is an open-source library for a machine learning based toolkit used in the processing of natural language text. It features an API for use cases like [Named Entity Recognition](https://en.wikipedia.org/wiki/Named-entity_recognition), [Sentence Detection](), [POS(Part-Of-Speech) tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging), [Tokenization](https://en.wikipedia.org/wiki/Tokenization_(data_security)) [Feature extraction](https://en.wikipedia.org/wiki/Feature_extraction), [Chunking](https://en.wikipedia.org/wiki/Chunking_(psychology)), [Parsing](https://en.wikipedia.org/wiki/Parsing), and [Coreference resolution](https://en.wikipedia.org/wiki/Coreference).
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
[nGraph](https://github.com/NervanaSystems/ngraph) is an open source C++ library, compiler and runtime for Deep Learning. The nGraph Compiler aims to accelerate developing AI workloads using any deep learning framework and deploying to a variety of hardware targets.It provides the freedom, performance, and ease-of-use to AI developers.
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Tensorman](https://github.com/pop-os/tensorman) is a utility for easy management of Tensorflow containers by developed by [System76]( https://system76.com).Tensorman allows Tensorflow to operate in an isolated environment that is contained from the rest of the system. This virtual environment can operate independent of the base system, allowing you to use any version of Tensorflow on any version of a Linux distribution that supports the Docker runtime.
[Numba](https://github.com/numba/numba) is an open source, NumPy-aware optimizing compiler for Python sponsored by Anaconda, Inc. It uses the LLVM compiler project to generate machine code from Python syntax. Numba can compile a large subset of numerically-focused Python, including many NumPy functions. Additionally, Numba has support for automatic parallelization of loops, generation of GPU-accelerated code, and creation of ufuncs and C callbacks.
[Chainer](https://chainer.org/) is a Python-based deep learning framework aiming at flexibility. It provides automatic differentiation APIs based on the define-by-run approach (dynamic computational graphs) as well as object-oriented high-level APIs to build and train neural networks. It also supports CUDA/cuDNN using [CuPy](https://github.com/cupy/cupy) for high performance training and inference.
[XGBoost](https://xgboost.readthedocs.io/) is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. It supports distributed training on multiple machines, including AWS, GCE, Azure, and Yarn clusters. Also, it can be integrated with Flink, Spark and other cloud dataflow systems.
[cuML](https://github.com/rapidsai/cuml) is a suite of libraries that implement machine learning algorithms and mathematical primitives functions that share compatible APIs with other RAPIDS projects. cuML enables data scientists, researchers, and software engineers to run traditional tabular ML tasks on GPUs without going into the details of CUDA programming. In most cases, cuML's Python API matches the API from scikit-learn.
# Algorithms
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)
[Fuzzy logic](https://www.investopedia.com/terms/f/fuzzy-logic.asp) is a heuristic approach that allows for more advanced decision-tree processing and better integration with rules-based programming.
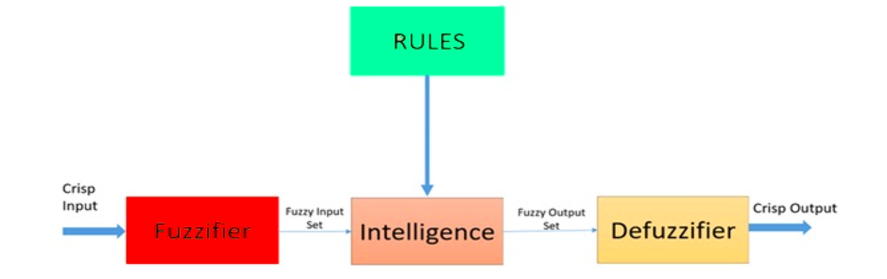
**Architecture of a Fuzzy Logic System. Source: [ResearchGate](https://www.researchgate.net/figure/Architecture-of-a-fuzzy-logic-system_fig2_309452475)**
[Support Vector Machine (SVM)](https://web.stanford.edu/~hastie/MOOC-Slides/svm.pdf) is a supervised machine learning model that uses classification algorithms for two-group classification problems.

**Support Vector Machine (SVM). Source:[OpenClipArt](https://openclipart.org/detail/182977/svm-support-vector-machines)**
[Neural networks](https://www.ibm.com/cloud/learn/neural-networks) are a subset of machine learning and are at the heart of deep learning algorithms. The name/structure is inspired by the human brain copying the process that biological neurons/nodes signal to one another.
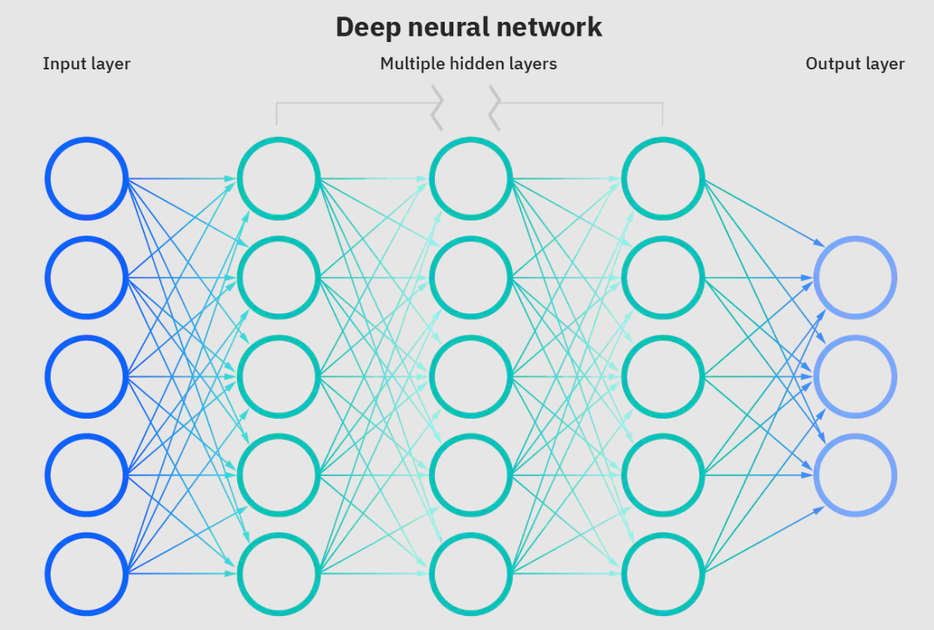
**Deep neural network. Source: [IBM](https://www.ibm.com/cloud/learn/neural-networks)**
[Convolutional Neural Networks (R-CNN)](https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks) is an object detection algorithm that first segments the image to find potential relevant bounding boxes and then run the detection algorithm to find most probable objects in those bounding boxes.
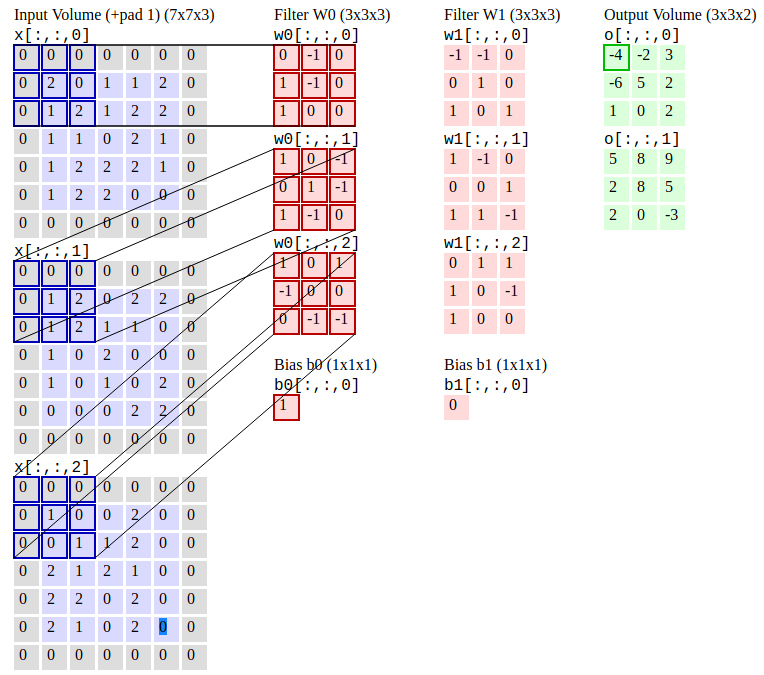
**Convolutional Neural Networks. Source:[CS231n](https://cs231n.github.io/convolutional-networks/#conv)**
[Recurrent neural networks (RNNs)](https://www.ibm.com/cloud/learn/recurrent-neural-networks) is a type of artificial neural network which uses sequential data or time series data.

**Recurrent Neural Networks. Source: [Slideteam](https://www.slideteam.net/recurrent-neural-networks-rnns-ppt-powerpoint-presentation-file-templates.html)**
[Multilayer Perceptrons (MLPs)](https://deepai.org/machine-learning-glossary-and-terms/multilayer-perceptron) is multi-layer neural networks composed of multiple layers of [perceptrons](https://en.wikipedia.org/wiki/Perceptron) with a threshold activation.

**Multilayer Perceptrons. Source: [DeepAI](https://deepai.org/machine-learning-glossary-and-terms/multilayer-perceptron)**
[Random forest](https://www.ibm.com/cloud/learn/random-forest) is a commonly-used machine learning algorithm, which combines the output of multiple decision trees to reach a single result. A decision tree in a forest cannot be pruned for sampling and therefore, prediction selection. Its ease of use and flexibility have fueled its adoption, as it handles both classification and regression problems.

**Random forest. Source: [wikimedia](https://community.tibco.com/wiki/random-forest-template-tibco-spotfirer-wiki-page)**
[Decision trees](https://www.cs.cmu.edu/~bhiksha/courses/10-601/decisiontrees/) are tree-structured models for classification and regression.

**Decision Trees. Source: [CMU](http://www.cs.cmu.edu/~bhiksha/courses/10-601/decisiontrees/)**
[Naive Bayes](https://en.wikipedia.org/wiki/Naive_Bayes_classifier) is a machine learning algorithm that is used solved calssification problems. It's based on applying [Bayes' theorem](https://www.mathsisfun.com/data/bayes-theorem.html) with strong independence assumptions between the features.

**Bayes' theorem. Source:[mathisfun](https://www.mathsisfun.com/data/bayes-theorem.html)**
# Deep Learning Development
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)

## Deep Learning Learning Resources
[Deep Learning](https://www.ibm.com/cloud/learn/deep-learning) is a subset of machine learning, which is essentially a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain,though, far from matching its ability. This allows the neural networks to "learn" from large amounts of data. The Learning can be [supervised](https://en.wikipedia.org/wiki/Supervised_learning), [semi-supervised](https://en.wikipedia.org/wiki/Semi-supervised_learning) or [unsupervised](https://en.wikipedia.org/wiki/Unsupervised_learning).
[Deep Learning Online Courses | NVIDIA](https://www.nvidia.com/en-us/training/online/)
[Top Deep Learning Courses Online | Coursera](https://www.coursera.org/courses?query=deep%20learning)
[Top Deep Learning Courses Online | Udemy](https://www.udemy.com/topic/deep-learning/)
[Learn Deep Learning with Online Courses and Lessons | edX](https://www.edx.org/learn/deep-learning)
[Deep Learning Online Course Nanodegree | Udacity](https://www.udacity.com/course/deep-learning-nanodegree--nd101)
[Machine Learning Course by Andrew Ng | Coursera](https://www.coursera.org/learn/machine-learning?)
[Machine Learning Engineering for Production (MLOps) course by Andrew Ng | Coursera](https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops)
[Data Science: Deep Learning and Neural Networks in Python | Udemy](https://www.udemy.com/course/data-science-deep-learning-in-python/)
[Understanding Machine Learning with Python | Pluralsight ](https://www.pluralsight.com/courses/python-understanding-machine-learning)
[How to Think About Machine Learning Algorithms | Pluralsight](https://www.pluralsight.com/courses/machine-learning-algorithms)
[Deep Learning Courses | Stanford Online](https://online.stanford.edu/courses/cs230-deep-learning)
[Deep Learning - UW Professional & Continuing Education](https://www.pce.uw.edu/courses/deep-learning)
[Deep Learning Online Courses | Harvard University](https://online-learning.harvard.edu/course/deep-learning-0)
[Machine Learning for Everyone Courses | DataCamp](https://www.datacamp.com/courses/introduction-to-machine-learning-with-r)
[Artificial Intelligence Expert Course: Platinum Edition | Udemy](https://www.udemy.com/course/artificial-intelligence-exposed-future-10-extreme-edition/)
[Top Artificial Intelligence Courses Online | Coursera](https://www.coursera.org/courses?query=artificial%20intelligence)
[Learn Artificial Intelligence with Online Courses and Lessons | edX](https://www.edx.org/learn/artificial-intelligence)
[Professional Certificate in Computer Science for Artificial Intelligence | edX](https://www.edx.org/professional-certificate/harvardx-computer-science-for-artifical-intelligence)
[Artificial Intelligence Nanodegree program](https://www.udacity.com/course/ai-artificial-intelligence-nanodegree--nd898)
[Artificial Intelligence (AI) Online Courses | Udacity](https://www.udacity.com/school-of-ai)
[Intro to Artificial Intelligence Course | Udacity](https://www.udacity.com/course/intro-to-artificial-intelligence--cs271)
[Edge AI for IoT Developers Course | Udacity](https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131)
[Reasoning: Goal Trees and Rule-Based Expert Systems | MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/lecture-videos/lecture-3-reasoning-goal-trees-and-rule-based-expert-systems/)
[Expert Systems and Applied Artificial Intelligence](https://www.umsl.edu/~joshik/msis480/chapt11.htm)
[Autonomous Systems - Microsoft AI](https://www.microsoft.com/en-us/ai/autonomous-systems)
[Introduction to Microsoft Project Bonsai](https://docs.microsoft.com/en-us/learn/autonomous-systems/intro-to-project-bonsai/)
[Machine teaching with the Microsoft Autonomous Systems platform](https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/autonomous-systems)
[Autonomous Maritime Systems Training | AMC Search](https://www.amcsearch.com.au/ams-training)
[Top Autonomous Cars Courses Online | Udemy](https://www.udemy.com/topic/autonomous-cars/)
[Applied Control Systems 1: autonomous cars: Math + PID + MPC | Udemy](https://www.udemy.com/course/applied-systems-control-for-engineers-modelling-pid-mpc/)
[Learn Autonomous Robotics with Online Courses and Lessons | edX](https://www.edx.org/learn/autonomous-robotics)
[Artificial Intelligence Nanodegree program](https://www.udacity.com/course/ai-artificial-intelligence-nanodegree--nd898)
[Autonomous Systems Online Courses & Programs | Udacity](https://www.udacity.com/school-of-autonomous-systems)
[Edge AI for IoT Developers Course | Udacity](https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131)
[Autonomous Systems MOOC and Free Online Courses | MOOC List](https://www.mooc-list.com/tags/autonomous-systems)
[Robotics and Autonomous Systems Graduate Program | Standford Online](https://online.stanford.edu/programs/robotics-and-autonomous-systems-graduate-program)
[Mobile Autonomous Systems Laboratory | MIT OpenCourseWare](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-186-mobile-autonomous-systems-laboratory-january-iap-2005/lecture-notes/)
## Deep Learning Tools, Libraries, and Frameworks
[NVIDIA cuDNN](https://developer.nvidia.com/cudnn) is a GPU-accelerated library of primitives for [deep neural networks](https://developer.nvidia.com/deep-learning). cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN accelerates widely used deep learning frameworks, including [Caffe2](https://caffe2.ai/), [Chainer](https://chainer.org/), [Keras](https://keras.io/), [MATLAB](https://www.mathworks.com/solutions/deep-learning.html), [MxNet](https://mxnet.incubator.apache.org/), [PyTorch](https://pytorch.org/), and [TensorFlow](https://www.tensorflow.org/).
[NVIDIA DLSS (Deep Learning Super Sampling)](https://developer.nvidia.com/dlss) is a temporal image upscaling AI rendering technology that increases graphics performance using dedicated Tensor Core AI processors on GeForce RTX™ GPUs. DLSS uses the power of a deep learning neural network to boost frame rates and generate beautiful, sharp images for your games.
[AMD FidelityFX Super Resolution (FSR)](https://www.amd.com/en/technologies/radeon-software-fidelityfx) is an open source, high-quality solution for producing high resolution frames from lower resolution inputs. It uses a collection of cutting-edge Deep Learning algorithms with a particular emphasis on creating high-quality edges, giving large performance improvements compared to rendering at native resolution directly. FSR enables “practical performance” for costly render operations, such as hardware ray tracing for the AMD RDNA™ and AMD RDNA™ 2 architectures.
[Intel Xe Super Sampling (XeSS)](https://www.youtube.com/watch?v=Y9hfpf-SqEg) is a temporal image upscaling AI rendering technology that increases graphics performance similar to NVIDIA's [DLSS (Deep Learning Super Sampling)](https://developer.nvidia.com/dlss). Intel's Arc GPU architecture (early 2022) will have GPUs that feature dedicated Xe-cores to run XeSS. The GPUs will have Xe Matrix eXtenstions matrix (XMX) engines for hardware-accelerated AI processing. XeSS will be able to run on devices without XMX, including integrated graphics, though, the performance of XeSS will be lower on non-Intel graphics cards because it will be powered by [DP4a instruction](https://www.intel.com/content/dam/www/public/us/en/documents/reference-guides/11th-gen-quick-reference-guide.pdf).
[Jupyter Notebook](https://jupyter.org/) is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Jupyter is used widely in industries that do data cleaning and transformation, numerical simulation, statistical modeling, data visualization, data science, and machine learning.
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. It also supports a rich set of higher-level tools including Spark SQL for SQL and DataFrames, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
[Apache Spark Connector for SQL Server and Azure SQL](https://github.com/microsoft/sql-spark-connector) is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
[Apache PredictionIO](https://predictionio.apache.org/) is an open source machine learning framework for developers, data scientists, and end users. It supports event collection, deployment of algorithms, evaluation, querying predictive results via REST APIs. It is based on scalable open source services like Hadoop, HBase (and other DBs), Elasticsearch, Spark and implements what is called a Lambda Architecture.
[Cluster Manager for Apache Kafka(CMAK)](https://github.com/yahoo/CMAK) is a tool for managing [Apache Kafka](https://kafka.apache.org/) clusters.
[BigDL](https://bigdl-project.github.io/) is a distributed deep learning library for Apache Spark. With BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
[Eclipse Deeplearning4J (DL4J)](https://deeplearning4j.konduit.ai/) is a set of projects intended to support all the needs of a JVM-based(Scala, Kotlin, Clojure, and Groovy) deep learning application. This means starting with the raw data, loading and preprocessing it from wherever and whatever format it is in to building and tuning a wide variety of simple and complex deep learning networks.
[Deep Learning Toolbox™](https://www.mathworks.com/products/deep-learning.html) is a tool that provides a framework for designing and implementing deep neural networks with algorithms, pretrained models, and apps. You can use convolutional neural networks (ConvNets, CNNs) and long short-term memory (LSTM) networks to perform classification and regression on image, time-series, and text data. You can build network architectures such as generative adversarial networks (GANs) and Siamese networks using automatic differentiation, custom training loops, and shared weights. With the Deep Network Designer app, you can design, analyze, and train networks graphically. It can exchange models with TensorFlow™ and PyTorch through the ONNX format and import models from TensorFlow-Keras and Caffe. The toolbox supports transfer learning with DarkNet-53, ResNet-50, NASNet, SqueezeNet and many other pretrained models.
[Reinforcement Learning Toolbox™](https://www.mathworks.com/products/reinforcement-learning.html) is a tool that provides an app, functions, and a Simulink® block for training policies using reinforcement learning algorithms, including DQN, PPO, SAC, and DDPG. You can use these policies to implement controllers and decision-making algorithms for complex applications such as resource allocation, robotics, and autonomous systems.
[Deep Learning HDL Toolbox™](https://www.mathworks.com/products/deep-learning-hdl.html) is a tool that provides functions and tools to prototype and implement deep learning networks on FPGAs and SoCs. It provides pre-built bitstreams for running a variety of deep learning networks on supported Xilinx® and Intel® FPGA and SoC devices. Profiling and estimation tools let you customize a deep learning network by exploring design, performance, and resource utilization tradeoffs.
[Parallel Computing Toolbox™](https://www.mathworks.com/products/matlab-parallel-server.html) is a tool that lets you solve computationally and data-intensive problems using multicore processors, GPUs, and computer clusters. High-level constructs such as parallel for-loops, special array types, and parallelized numerical algorithms enable you to parallelize MATLAB® applications without CUDA or MPI programming. The toolbox lets you use parallel-enabled functions in MATLAB and other toolboxes. You can use the toolbox with Simulink® to run multiple simulations of a model in parallel. Programs and models can run in both interactive and batch modes.
[XGBoost](https://xgboost.readthedocs.io/) is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. It supports distributed training on multiple machines, including AWS, GCE, Azure, and Yarn clusters. Also, it can be integrated with Flink, Spark and other cloud dataflow systems.
[LIBSVM](https://www.csie.ntu.edu.tw/~cjlin/libsvm/) is an integrated software for support vector classification, (C-SVC, nu-SVC), regression (epsilon-SVR, nu-SVR) and distribution estimation (one-class SVM). It supports multi-class classification.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a simple and efficient tool for data mining and data analysis. It is built on NumPy,SciPy, and mathplotlib.
[TensorFlow](https://www.tensorflow.org) is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
[Keras](https://keras.io) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.It was developed with a focus on enabling fast experimentation. It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML.
[PyTorch](https://pytorch.org) is a library for deep learning on irregular input data such as graphs, point clouds, and manifolds. Primarily developed by Facebook's AI Research lab.
[Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/) is a fast and collaborative Apache Spark-based big data analytics service designed for data science and data engineering. Azure Databricks, sets up your Apache Spark environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
[Microsoft Cognitive Toolkit (CNTK)](https://docs.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
[Tensorflow_macOS](https://github.com/apple/tensorflow_macos) is a Mac-optimized version of TensorFlow and TensorFlow Addons for macOS 11.0+ accelerated using Apple's ML Compute framework.
[Apache Airflow](https://airflow.apache.org) is an open-source workflow management platform created by the community to programmatically author, schedule and monitor workflows. Install. Principles. Scalable. Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
[Open Neural Network Exchange(ONNX)](https://github.com/onnx) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
[Apache MXNet](https://mxnet.apache.org/) is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scaling effectively to multiple GPUs and multiple machines. Support for Python, R, Julia, Scala, Go, Javascript and more.
[AutoGluon](https://autogluon.mxnet.io/index.html) is toolkit for Deep learning that automates machine learning tasks enabling you to easily achieve strong predictive performance in your applications. With just a few lines of code, you can train and deploy high-accuracy deep learning models on tabular, image, and text data.
[Anaconda](https://www.anaconda.com/) is a very popular Data Science platform for machine learning and deep learning that enables users to develop models, train them, and deploy them.
[PlaidML](https://github.com/plaidml/plaidml) is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
[OpenCV](https://opencv.org) is a highly optimized library with focus on real-time computer vision applications. The C++, Python, and Java interfaces support Linux, MacOS, Windows, iOS, and Android.
[Scikit-Learn](https://scikit-learn.org/stable/index.html) is a Python module for machine learning built on top of SciPy, NumPy, and matplotlib, making it easier to apply robust and simple implementations of many popular machine learning algorithms.
[Weka](https://www.cs.waikato.ac.nz/ml/weka/) is an open source machine learning software that can be accessed through a graphical user interface, standard terminal applications, or a Java API. It is widely used for teaching, research, and industrial applications, contains a plethora of built-in tools for standard machine learning tasks, and additionally gives transparent access to well-known toolboxes such as scikit-learn, R, and Deeplearning4j.
[Caffe](https://github.com/BVLC/caffe) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors.
[Theano](https://github.com/Theano/Theano) is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently including tight integration with NumPy.
[Microsoft Project Bonsai](https://azure.microsoft.com/en-us/services/project-bonsai/) is a low-code AI platform that speeds AI-powered automation development and part of the Autonomous Systems suite from Microsoft. Bonsai is used to build AI components that can provide operator guidance or make independent decisions to optimize process variables, improve production efficiency, and reduce downtime.
[Microsoft AirSim](https://microsoft.github.io/AirSim/lidar.html) is a simulator for drones, cars and more, built on Unreal Engine (with an experimental Unity release). AirSim is open-source, cross platform, and supports [software-in-the-loop simulation](https://www.mathworks.com/help///ecoder/software-in-the-loop-sil-simulation.html) with popular flight controllers such as PX4 & ArduPilot and [hardware-in-loop](https://www.ni.com/en-us/innovations/white-papers/17/what-is-hardware-in-the-loop-.html) with PX4 for physically and visually realistic simulations. It is developed as an Unreal plugin that can simply be dropped into any Unreal environment. AirSim is being developed as a platform for AI research to experiment with deep learning, computer vision and reinforcement learning algorithms for autonomous vehicles.
[CARLA](https://github.com/carla-simulator/carla) is an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely.
[ROS/ROS2 bridge for CARLA(package)](https://github.com/carla-simulator/ros-bridge) is a bridge that enables two-way communication between ROS and CARLA. The information from the CARLA server is translated to ROS topics. In the same way, the messages sent between nodes in ROS get translated to commands to be applied in CARLA.
[ROS Toolbox](https://www.mathworks.com/products/ros.html) is a tool that provides an interface connecting MATLAB® and Simulink® with the Robot Operating System (ROS and ROS 2), enabling you to create a network of ROS nodes. The toolbox includes MATLAB functions and Simulink blocks to import, analyze, and play back ROS data recorded in rosbag files. You can also connect to a live ROS network to access ROS messages.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Image Processing Toolbox™](https://www.mathworks.com/products/image.html) is a tool that provides a comprehensive set of reference-standard algorithms and workflow apps for image processing, analysis, visualization, and algorithm development. You can perform image segmentation, image enhancement, noise reduction, geometric transformations, image registration, and 3D image processing.
[Computer Vision Toolbox™](https://www.mathworks.com/products/computer-vision.html) is a tool that provides algorithms, functions, and apps for designing and testing computer vision, 3D vision, and video processing systems. You can perform object detection and tracking, as well as feature detection, extraction, and matching. You can automate calibration workflows for single, stereo, and fisheye cameras. For 3D vision, the toolbox supports visual and point cloud SLAM, stereo vision, structure from motion, and point cloud processing.
[Robotics Toolbox™](https://www.mathworks.com/products/robotics.html) is a tool that provides a toolbox that brings robotics specific functionality(designing, simulating, and testing manipulators, mobile robots, and humanoid robots) to MATLAB, exploiting the native capabilities of MATLAB (linear algebra, portability, graphics). The toolbox also supports mobile robots with functions for robot motion models (bicycle), path planning algorithms (bug, distance transform, D*, PRM), kinodynamic planning (lattice, RRT), localization (EKF, particle filter), map building (EKF) and simultaneous localization and mapping (EKF), and a Simulink model a of non-holonomic vehicle. The Toolbox also including a detailed Simulink model for a quadrotor flying robot.
[Model Predictive Control Toolbox™](https://www.mathworks.com/products/model-predictive-control.html) is a tool that provides functions, an app, and Simulink® blocks for designing and simulating controllers using linear and nonlinear model predictive control (MPC). The toolbox lets you specify plant and disturbance models, horizons, constraints, and weights. By running closed-loop simulations, you can evaluate controller performance.
[Predictive Maintenance Toolbox™](https://www.mathworks.com/products/predictive-maintenance.html) is a tool that lets you manage sensor data, design condition indicators, and estimate the remaining useful life (RUL) of a machine. The toolbox provides functions and an interactive app for exploring, extracting, and ranking features using data-based and model-based techniques, including statistical, spectral, and time-series analysis.
[Vision HDL Toolbox™](https://www.mathworks.com/products/vision-hdl.html) is a tool that provides pixel-streaming algorithms for the design and implementation of vision systems on FPGAs and ASICs. It provides a design framework that supports a diverse set of interface types, frame sizes, and frame rates. The image processing, video, and computer vision algorithms in the toolbox use an architecture appropriate for HDL implementations.
[Automated Driving Toolbox™](https://www.mathworks.com/products/automated-driving.html) is a MATLAB tool that provides algorithms and tools for designing, simulating, and testing ADAS and autonomous driving systems. You can design and test vision and lidar perception systems, as well as sensor fusion, path planning, and vehicle controllers. Visualization tools include a bird’s-eye-view plot and scope for sensor coverage, detections and tracks, and displays for video, lidar, and maps. The toolbox lets you import and work with HERE HD Live Map data and OpenDRIVE® road networks. It also provides reference application examples for common ADAS and automated driving features, including FCW, AEB, ACC, LKA, and parking valet. The toolbox supports C/C++ code generation for rapid prototyping and HIL testing, with support for sensor fusion, tracking, path planning, and vehicle controller algorithms.
[UAV Toolbox](https://www.mathworks.com/products/uav.html) is an application that provides tools and reference applications for designing, simulating, testing, and deploying unmanned aerial vehicle (UAV) and drone applications. You can design autonomous flight algorithms, UAV missions, and flight controllers. The Flight Log Analyzer app lets you interactively analyze 3D flight paths, telemetry information, and sensor readings from common flight log formats.
[Navigation Toolbox™](https://www.mathworks.com/products/navigation.html) is a tool that provides algorithms and analysis tools for motion planning, simultaneous localization and mapping (SLAM), and inertial navigation. The toolbox includes customizable search and sampling-based path planners, as well as metrics for validating and comparing paths. You can create 2D and 3D map representations, generate maps using SLAM algorithms, and interactively visualize and debug map generation with the SLAM map builder app.
[Lidar Toolbox™](https://www.mathworks.com/products/lidar.html) is a tool that provides algorithms, functions, and apps for designing, analyzing, and testing lidar processing systems. You can perform object detection and tracking, semantic segmentation, shape fitting, lidar registration, and obstacle detection. Lidar Toolbox supports lidar-camera cross calibration for workflows that combine computer vision and lidar processing.
[Mapping Toolbox™](https://www.mathworks.com/products/mapping.html) is a tool that provides algorithms and functions for transforming geographic data and creating map displays. You can visualize your data in a geographic context, build map displays from more than 60 map projections, and transform data from a variety of sources into a consistent geographic coordinate system.
# Reinforcement Learning Development
[Back to the Top](https://github.com/mikeroyal/Apache-Ignite-Guide#table-of-contents)

## Reinforcement Learning Learning Resources
[Reinforcement Learning](https://www.ibm.com/cloud/learn/deep-learning#toc-deep-learn-md_Q_Of3) is a subset of machine learning, which is a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain,though, far from matching its ability. This allows the neural networks to "learn" from a process in which a model learns to become more accurate for performing an action in an environment based on feedback in order to maximize the reward. The Learning can be [supervised](https://en.wikipedia.org/wiki/Supervised_learning), [semi-supervised](https://en.wikipedia.org/wiki/Semi-supervised_learning) or [unsupervised](https://en.wikipedia.org/wiki/Unsupervised_learning).
[Top Reinforcement Learning Courses | Coursera](https://www.coursera.org/courses?query=reinforcement%20learning)
[Top Reinforcement Learning Courses | Udemy](https://www.udemy.com/topic/reinforcement-le