https://github.com/mit-han-lab/anycost-gan
[CVPR 2021] Anycost GANs for Interactive Image Synthesis and Editing
https://github.com/mit-han-lab/anycost-gan
computer-graphics computer-vision deep-learning gan gans generative-adversarial-network image-editing image-generation image-manipulation pytorch stylegan2
Last synced: about 1 year ago
JSON representation
[CVPR 2021] Anycost GANs for Interactive Image Synthesis and Editing
- Host: GitHub
- URL: https://github.com/mit-han-lab/anycost-gan
- Owner: mit-han-lab
- License: mit
- Created: 2021-03-04T05:39:06.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2023-10-03T15:20:42.000Z (almost 3 years ago)
- Last Synced: 2023-11-07T21:36:44.758Z (over 2 years ago)
- Topics: computer-graphics, computer-vision, deep-learning, gan, gans, generative-adversarial-network, image-editing, image-generation, image-manipulation, pytorch, stylegan2
- Language: Python
- Homepage: https://hanlab.mit.edu/projects/anycost-gan/
- Size: 16.7 MB
- Stars: 760
- Watchers: 24
- Forks: 97
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Anycost GAN
### [video](https://youtu.be/_yEziPl9AkM) | [paper](https://arxiv.org/abs/2103.03243) | [website](https://hanlab18.mit.edu/projects/anycost-gan/) [](https://colab.research.google.com/github/mit-han-lab/anycost-gan/blob/master/notebooks/intro_colab.ipynb)
[Anycost GANs for Interactive Image Synthesis and Editing](https://arxiv.org/abs/2103.03243)
[Ji Lin](http://linji.me/), [Richard Zhang](https://richzhang.github.io/), Frieder Ganz, [Song Han](https://songhan.mit.edu/), [Jun-Yan Zhu](https://www.cs.cmu.edu/~junyanz/)
MIT, Adobe Research, CMU
In CVPR 2021

Anycost GAN generates consistent outputs under various computational budgets.
## Demo

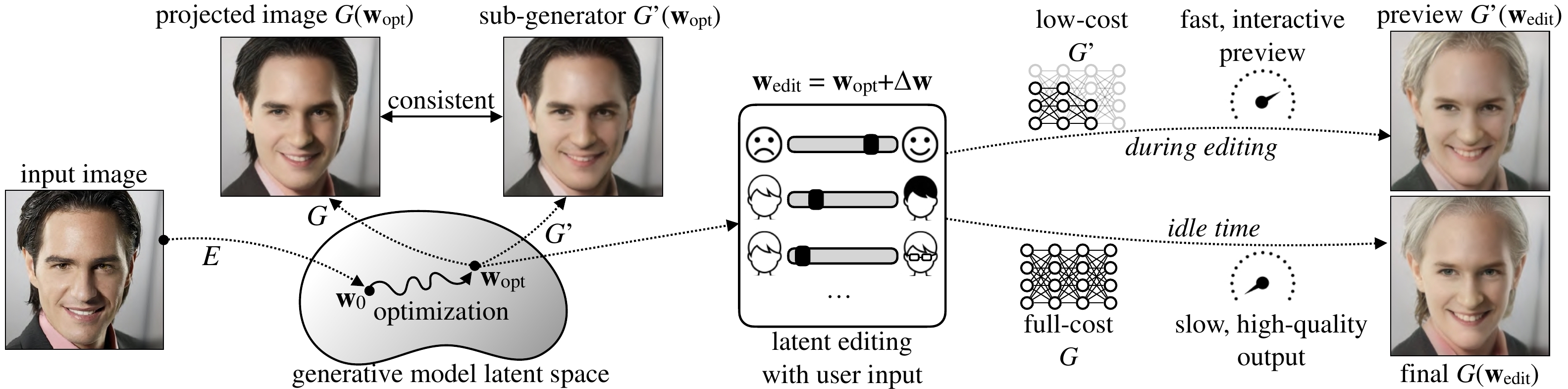
Here, we can use the Anycost generator for **interactive image editing**. A full generator takes **~3s** to render an image, which is too slow for editing. While with Anycost generator, we can provide a visually similar preview at **5x faster speed**. After adjustment, we hit the "Finalize" button to synthesize the high-quality final output. Check [here](https://youtu.be/_yEziPl9AkM?t=90) for the full demo.
## Overview
Anycost generators can be run at *diverse computation costs* by using different *channel* and *resolution* configurations. Sub-generators achieve high output consistency compared to the full generator, providing a fast preview.
With (1) Sampling-based multi-resolution training, (2) adaptive-channel training, and (3) generator-conditioned discriminator, we achieve high image quality and consistency at different resolutions and channels.
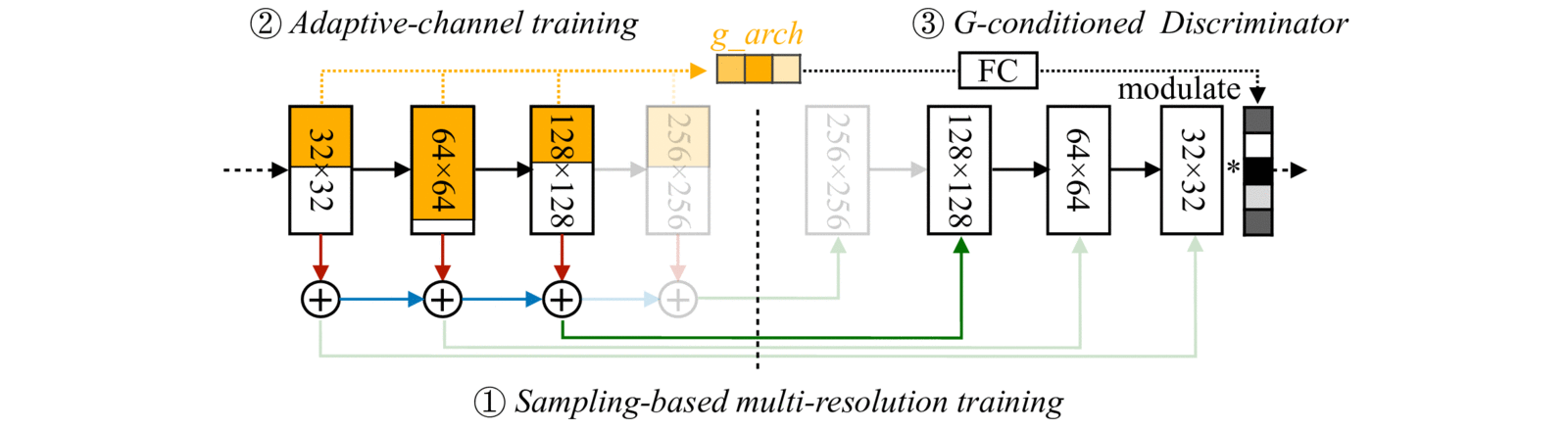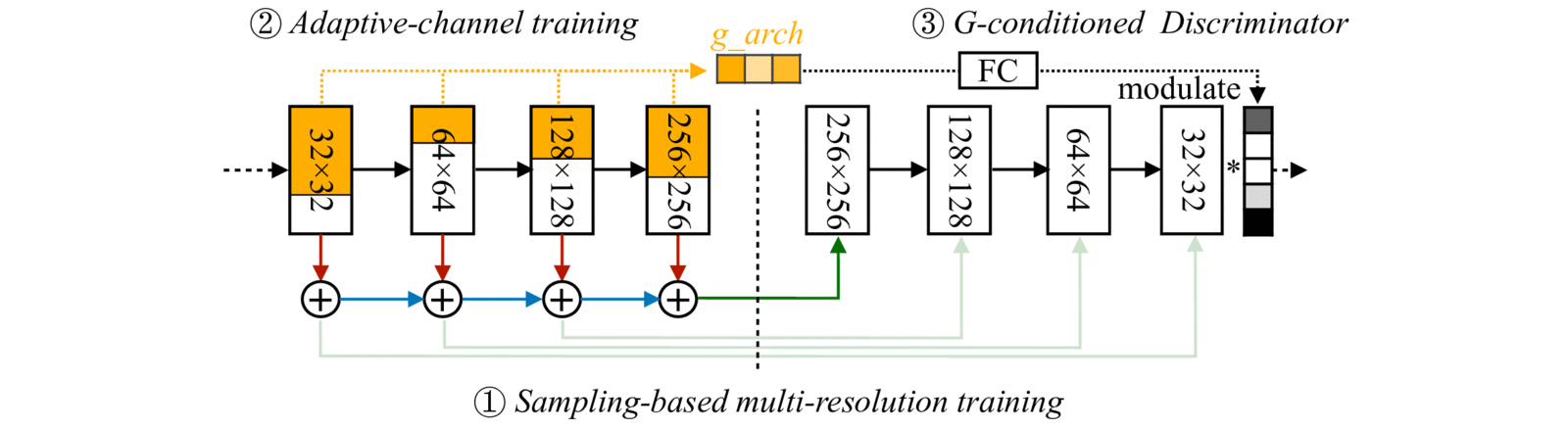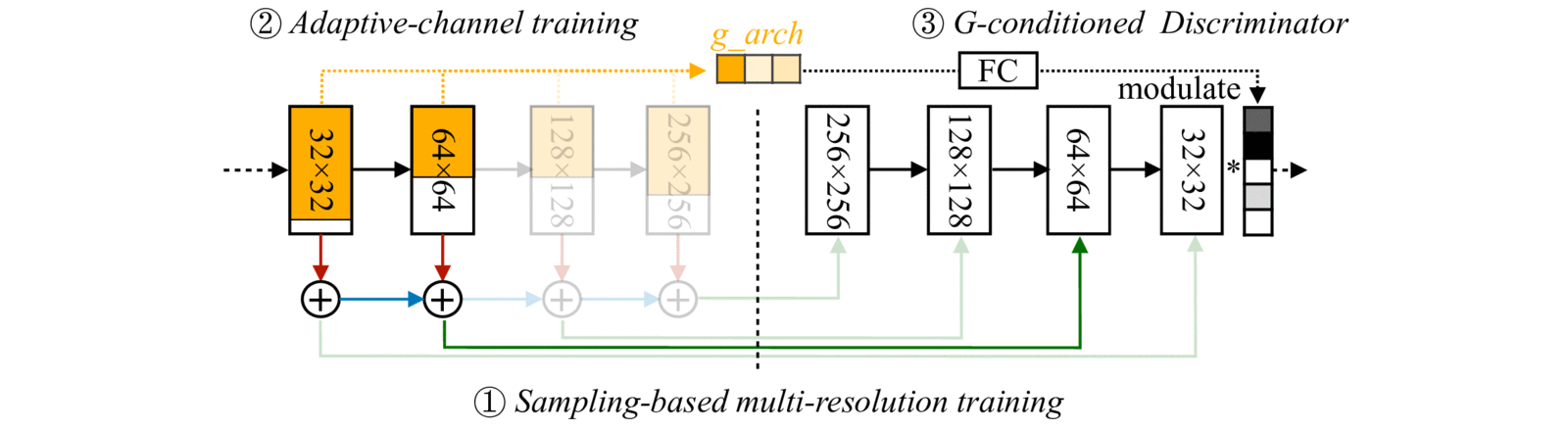
## Results
Anycost GAN (uniform channel version) supports 4 resolutions and 4 channel ratios, producing visually consistent images with different image fidelity.

The consistency retains during image projection and editing:


## Usage
### Getting Started
- Clone this repo:
```bash
git clone https://github.com/mit-han-lab/anycost-gan.git
cd anycost-gan
```
- Install PyTorch 1.7 and other dependeinces.
We recommend setting up the environment using Anaconda: `conda env create -f environment.yml`
### Introduction Notebook
We provide a jupyter notebook example to show how to use the anycost generator for image synthesis at diverse costs: `notebooks/intro.ipynb`.
We also provide a colab version of the notebook: [](https://colab.research.google.com/github/mit-han-lab/anycost-gan/blob/master/notebooks/intro_colab.ipynb). Be sure to select the GPU as the accelerator in runtime options.
### Interactive Demo
We provide an interactive demo showing how we can use anycost GAN to enable interactive image editing. To run the demo:
```bash
python demo.py
```
If your computer contains a CUDA GPU, try running with:
```bash
FORCE_NATIVE=1 python demo.py
```
You can find a video recording of the demo [here](https://youtu.be/_yEziPl9AkM?t=90).
### Using Pre-trained Models
To get the pre-trained generator, encoder, and editing directions, run:
```python
import models
pretrained_type = 'generator' # choosing from ['generator', 'encoder', 'boundary']
config_name = 'anycost-ffhq-config-f' # replace the config name for other models
models.get_pretrained(pretrained_type, config=config_name)
```
We also provide the face attribute classifier (which is general for different generators) for computing the editing directions. You can get it by running:
```python
models.get_pretrained('attribute-predictor')
```
The attribute classifier takes in the face images in FFHQ format.
After loading the Anycost generator, we can run it at a wide range of computational costs. For example:
```python
from models.dynamic_channel import set_uniform_channel_ratio, reset_generator
g = models.get_pretrained('generator', config='anycost-ffhq-config-f') # anycost uniform
set_uniform_channel_ratio(g, 0.5) # set channel
g.target_res = 512 # set resolution
out, _ = g(...) # generate image
reset_generator(g) # restore the generator
```
For detailed usage and *flexible-channel* anycost generator, please refer to `notebooks/intro.ipynb`.
### Model Zoo
Currently, we provide the following pre-trained generators, encoders, and editing directions. We will add more in the future.
For Anycost generators, by default, we refer to the uniform setting.
| config name | generator | encoder | edit direction |
| ------------------------------ | ------------------ | ------------------ | ------------------ |
| anycost-ffhq-config-f | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| anycost-ffhq-config-f-flexible | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| anycost-car-config-f | :heavy_check_mark: | | |
| stylegan2-ffhq-config-f | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
`stylegan2-ffhq-config-f` refers to the official StyleGAN2 generator converted from the [repo](https://github.com/NVlabs/stylegan2).
### Datasets
We prepare the [FFHQ](https://github.com/NVlabs/ffhq-dataset), [CelebA-HQ](https://github.com/switchablenorms/CelebAMask-HQ), and [LSUN Car](https://github.com/fyu/lsun) datasets into a directory of images, so that it can be easily used with `ImageFolder` from `torchvision`. The dataset layout looks like:
```
├── PATH_TO_DATASET
│ ├── images
│ │ ├── 00000.png
│ │ ├── 00001.png
│ │ ├── ...
```
Due to the copyright issue, you need to download the dataset from official site and process them accordingly.
### Evaluation
We provide the code to evaluate some metrics presented in the paper. Some of the code is written with [`horovod`](https://github.com/horovod/horovod) to support distributed evaluation and reduce the cost of inter-GPU communication, which greatly improves the speed. Check its website for a proper installation.
#### Fre ́chet Inception Distance (FID)
Before evaluating the FIDs, you need to compute the inception features of the real images using scripts like:
```bash
python tools/calc_inception.py \
--resolution 1024 --batch_size 64 -j 16 --n_sample 50000 \
--save_name assets/inceptions/inception_ffhq_res1024_50k.pkl \
PATH_TO_FFHQ
```
or you can download the pre-computed inceptions from [here](https://www.dropbox.com/sh/bc8a7ewlvcxa2cf/AAD8NFzDWKmBDpbLef-gGhRZa?dl=0) and put it under `assets/inceptions`.
Then, you can evaluate the FIDs by running:
```bash
horovodrun -np N_GPU \
python metrics/fid.py \
--config anycost-ffhq-config-f \
--batch_size 16 --n_sample 50000 \
--inception assets/inceptions/inception_ffhq_res1024_50k.pkl
# --channel_ratio 0.5 --target_res 512 # optionally using a smaller resolution/channel
```
#### Perceptual Path Lenght (PPL)
Similary, evaluting the PPL with:
```bash
horovodrun -np N_GPU \
python metrics/ppl.py \
--config anycost-ffhq-config-f
```
#### Attribute Consistency
Evaluating the attribute consistency by running:
```bash
horovodrun -np N_GPU \
python metrics/attribute_consistency.py \
--config anycost-ffhq-config-f \
--channel_ratio 0.5 --target_res 512 # config for the sub-generator; necessary
```
#### Encoder Evaluation
To evaluate the performance of the encoder, run:
```bash
python metrics/eval_encoder.py \
--config anycost-ffhq-config-f \
--data_path PATH_TO_CELEBA_HQ
```
### Training
We provide the scripts to train Anycost GAN on FFHQ dataset.
- Training the original StyleGAN2 on FFHQ
```
horovodrun -np 8 bash scripts/train_stylegan2_ffhq.sh
```
The training of original StyleGAN2 is time-consuming. We recommend downloading the converted checkpoints from [here](https://www.dropbox.com/sh/l8g9amoduz99kjh/AAAY9LYZk2CnsO43ywDrLZpEa?dl=0) and place it under `checkpoint/`.
- Training Anycost GAN: mult-resolution
```
horovodrun -np 8 bash scripts/train_stylegan2_multires_ffhq.sh
```
Note that after each epoch, we evaluate the FIDs of two resolutions (1024&512) to better monitor the training progress. We also apply distillation to accelearte the convergence, which is not used for the ablation in the paper.
- Training Anycost GAN: adaptive-channel
```
horovodrun -np 8 bash scripts/train_stylegan2_multires_adach_ffhq.sh
```
Here we set a longer training epoch for a more stable reproduction, which might not be necessary (depending on the randomness).
**Note**: We trained our models on Titan RTX GPUs with 24GB memory. For GPUs with smaller memory, you may need to reduce the resolution/model size/batch size/etc. and adjust other hyper-parameters accordingly.
## Citation
If you use this code for your research, please cite our paper.
```
@inproceedings{lin2021anycost,
author = {Lin, Ji and Zhang, Richard and Ganz, Frieder and Han, Song and Zhu, Jun-Yan},
title = {Anycost GANs for Interactive Image Synthesis and Editing},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021},
}
```
## Related Projects
**[GAN Compression](https://github.com/mit-han-lab/gan-compression) | [Once for All](https://github.com/mit-han-lab/once-for-all) | [iGAN](https://github.com/junyanz/iGAN) | [StyleGAN2](https://github.com/NVlabs/stylegan2)**
## Acknowledgement
We thank Taesung Park, Zhixin Shu, Muyang Li, and Han Cai for the helpful discussion. Part of the work is supported by NSF CAREER Award #1943349, Adobe, SONY, Naver Corporation, and MIT-IBM Watson AI Lab.
The codebase is build upon a PyTorch implementation of StyleGAN2: [rosinality/stylegan2-pytorch](https://github.com/rosinality/stylegan2-pytorch). For editing direction extraction, we refer to [InterFaceGAN](https://github.com/genforce/interfacegan).