https://github.com/modelscope/evalscope
A streamlined and customizable framework for efficient large model evaluation and performance benchmarking
https://github.com/modelscope/evalscope
evaluation llm performance rag vlm
Last synced: 6 months ago
JSON representation
A streamlined and customizable framework for efficient large model evaluation and performance benchmarking
- Host: GitHub
- URL: https://github.com/modelscope/evalscope
- Owner: modelscope
- License: apache-2.0
- Created: 2023-12-07T06:10:49.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2025-05-13T12:21:29.000Z (about 1 year ago)
- Last Synced: 2025-05-13T13:27:41.273Z (about 1 year ago)
- Topics: evaluation, llm, performance, rag, vlm
- Language: Python
- Homepage: https://evalscope.readthedocs.io/en/latest/
- Size: 58.2 MB
- Stars: 941
- Watchers: 8
- Forks: 103
- Open Issues: 55
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - modelscope/evalscope - Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH 和 HumanEval。EvalScope 支持各种类型的模型评估,包括 LLMs、多模态 LLMs、嵌入模型和重排模型,也适用于多种评估场景,例如端到端 RAG 评估、竞技场模式和模型推理性能压力测试。此外,EvalScope 与 ms-swift 训练框架无缝集成,只需点击一下即可启动评估,提供从模型训练到评估的完整端到端支持。EvalScope架构包含以下模块:模型适配器、数据适配器、评估后端和性能评估器。评估后端支持多种模式,包括原生评估框架、OpenCompass、VLMEvalKit、RAGEval 和第三方评估任务。 (A01_文本生成_文本对话 / 大语言对话模型及数据)
- awesome-production-machine-learning - EvalScope - EvalScope is a streamlined and customizable framework for efficient large model evaluation and performance benchmarking. (Evaluation and Monitoring)
- AwesomeResponsibleAI - EvalScope
- Awesome-Long-Chain-of-Thought-Reasoning - EvalScope
- awesome-LLM-resources - EvalScope
- awesome-opensource-ai - EvalScope (ModelScope) - Streamlined and customizable framework for efficient large model (LLM, VLM, AIGC) evaluation and performance benchmarking. One-stop evaluation solution with 80+ benchmarks. Apache 2.0 licensed.  (9. Evaluation, Benchmarks & Datasets)
- awesome-agent-harness - GitHub - 2967-f4b400?style=flat-square)](https://github.com/modelscope/evalscope) | benchmark, framework, llm | Customizable framework for large-model benchmarking and performance evaluation. | (Catalog / Evaluation Harnesses & Benchmarks)
README

中文   |   English  





📖 Chinese Documentation   |   📖 English Documentation
> ⭐ If you like this project, please click the "Star" button in the upper right corner to support us. Your support is our motivation to move forward!
## 📝 Introduction
EvalScope is a powerful and easily extensible model evaluation framework created by the [ModelScope Community](https://modelscope.cn/), aiming to provide a one-stop evaluation solution for large model developers.
Whether you want to evaluate the general capabilities of models, conduct multi-model performance comparisons, or need to stress test models, EvalScope can meet your needs.
## ✨ Key Features
- **📚 Comprehensive Evaluation Benchmarks**: Built-in multiple industry-recognized evaluation benchmarks including MMLU, C-Eval, GSM8K, and more.
- **🧩 Multi-modal and Multi-domain Support**: Supports evaluation of various model types including Large Language Models (LLM), Vision Language Models (VLM), Embedding, Reranker, AIGC, and more.
- **🚀 Multi-backend Integration**: Seamlessly integrates multiple evaluation backends including OpenCompass, VLMEvalKit, RAGEval to meet different evaluation needs.
- **⚡ Inference Performance Testing**: Provides powerful model service stress testing tools, supporting multiple performance metrics such as TTFT, TPOT.
- **📊 Interactive Reports**: Provides WebUI visualization interface, supporting multi-dimensional model comparison, report overview and detailed inspection.
- **⚔️ Arena Mode**: Supports multi-model battles (Pairwise Battle), intuitively ranking and evaluating models.
- **🔧 Highly Extensible**: Developers can easily add custom datasets, models and evaluation metrics.
🏛️ Overall Architecture
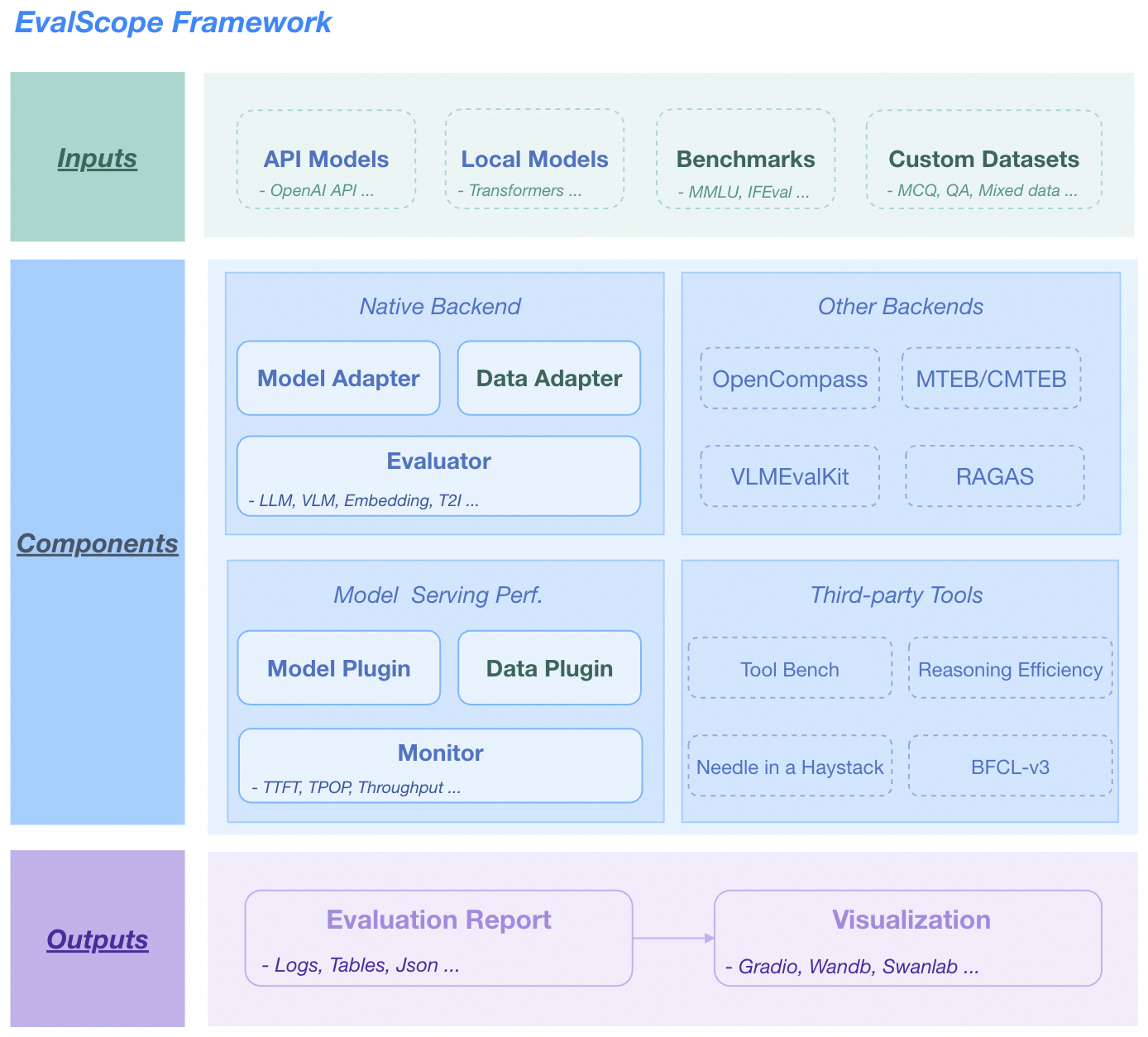
EvalScope Overall Architecture.
1. **Input Layer**
- **Model Sources**: API models (OpenAI API), Local models (ModelScope)
- **Datasets**: Standard evaluation benchmarks (MMLU/GSM8k etc.), Custom data (MCQ/QA)
2. **Core Functions**
- **Multi-backend Evaluation**: Native backend, OpenCompass, MTEB, VLMEvalKit, RAGAS
- **Performance Monitoring**: Supports multiple model service APIs and data formats, tracking TTFT/TPOP and other metrics
- **Tool Extensions**: Integrates Tool-Bench, Needle-in-a-Haystack, etc.
3. **Output Layer**
- **Structured Reports**: Supports JSON, Table, Logs
- **Visualization Platform**: Supports Gradio, Wandb, SwanLab
## 🎉 What's New
> [!IMPORTANT]
> **Version 1.0 Refactoring**
>
> Version 1.0 introduces a major overhaul of the evaluation framework, establishing a new, more modular and extensible API layer under `evalscope/api`. Key improvements include standardized data models for benchmarks, samples, and results; a registry-based design for components such as benchmarks and metrics; and a rewritten core evaluator that orchestrates the new architecture. Existing benchmark adapters have been migrated to this API, resulting in cleaner, more consistent, and easier-to-maintain implementations.
- 🔥 **[2025.12.26]** Added support for Terminal-Bench-2.0, which evaluates AI Agent performance on 89 real-world multi-step terminal tasks. Refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/third_party/terminal_bench.html).
- 🔥 **[2025.12.18]** Added support for SLA auto-tuning model API services, automatically testing the maximum concurrency of model services under specific latency, TTFT, and throughput conditions. Refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/sla_auto_tune.html).
- 🔥 **[2025.12.16]** Added support for audio evaluation benchmarks such as Fleurs, LibriSpeech; added support for multilingual code evaluation benchmarks such as MultiplE, MBPP.
- 🔥 **[2025.12.02]** Added support for custom multimodal VQA evaluation; refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/advanced_guides/custom_dataset/vlm.html). Added support for visualizing model service stress testing in ClearML; refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/examples.html#clearml).
- 🔥 **[2025.11.26]** Added support for OpenAI-MRCR, GSM8K-V, MGSM, MicroVQA, IFBench, SciCode benchmarks.
- 🔥 **[2025.11.18]** Added support for custom Function-Call (tool invocation) datasets to test whether models can timely and correctly call tools. Refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/advanced_guides/custom_dataset/llm.html#function-calling-format-fc).
- 🔥 **[2025.11.14]** Added support for SWE-bench_Verified, SWE-bench_Lite, SWE-bench_Verified_mini code evaluation benchmarks. Refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/third_party/swe_bench.html).
- 🔥 **[2025.11.12]** Added `pass@k`, `vote@k`, `pass^k` and other metric aggregation methods; added support for multimodal evaluation benchmarks such as A_OKVQA, CMMU, ScienceQA, V*Bench.
- 🔥 **[2025.11.07]** Added support for τ²-bench, an extended and enhanced version of τ-bench that includes a series of code fixes and adds telecom domain troubleshooting scenarios. Refer to the [usage documentation](https://evalscope.readthedocs.io/en/latest/third_party/tau2_bench.html).
- 🔥 **[2025.10.30]** Added support for BFCL-v4, enabling evaluation of agent capabilities including web search and long-term memory. See the [usage documentation](https://evalscope.readthedocs.io/en/latest/third_party/bfcl_v4.html).
- 🔥 **[2025.10.27]** Added support for LogiQA, HaluEval, MathQA, MRI-QA, PIQA, QASC, CommonsenseQA and other evaluation benchmarks. Thanks to @[penguinwang96825](https://github.com/penguinwang96825) for the code implementation.
- 🔥 **[2025.10.26]** Added support for Conll-2003, CrossNER, Copious, GeniaNER, HarveyNER, MIT-Movie-Trivia, MIT-Restaurant, OntoNotes5, WNUT2017 and other Named Entity Recognition evaluation benchmarks. Thanks to @[penguinwang96825](https://github.com/penguinwang96825) for the code implementation.
- 🔥 **[2025.10.21]** Optimized sandbox environment usage in code evaluation, supporting both local and remote operation modes. For details, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/user_guides/sandbox.html).
- 🔥 **[2025.10.20]** Added support for evaluation benchmarks including PolyMath, SimpleVQA, MathVerse, MathVision, AA-LCR; optimized evalscope perf performance to align with vLLM Bench. For details, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/vs_vllm_bench.html).
- 🔥 **[2025.10.14]** Added support for OCRBench, OCRBench-v2, DocVQA, InfoVQA, ChartQA, and BLINK multimodal image-text evaluation benchmarks.
- 🔥 **[2025.09.22]** Code evaluation benchmarks (HumanEval, LiveCodeBench) now support running in a sandbox environment. To use this feature, please install [ms-enclave](https://github.com/modelscope/ms-enclave) first.
- 🔥 **[2025.09.19]** Added support for multimodal image-text evaluation benchmarks including RealWorldQA, AI2D, MMStar, MMBench, and OmniBench, as well as pure text evaluation benchmarks such as Multi-IF, HealthBench, and AMC.
- 🔥 **[2025.09.05]** Added support for vision-language multimodal model evaluation tasks, such as MathVista and MMMU. For more supported datasets, please [refer to the documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset/vlm.html).
- 🔥 **[2025.09.04]** Added support for image editing task evaluation, including the [GEdit-Bench](https://modelscope.cn/datasets/stepfun-ai/GEdit-Bench) benchmark. For usage instructions, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/user_guides/aigc/image_edit.html).
- 🔥 **[2025.08.22]** Version 1.0 Refactoring. Break changes, please [refer to](https://evalscope.readthedocs.io/en/latest/get_started/basic_usage.html#switching-to-version-v1-0).
More
- 🔥 **[2025.07.18]** The model stress testing now supports randomly generating image-text data for multimodal model evaluation. For usage instructions, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/examples.html#id4).
- 🔥 **[2025.07.16]** Support for [τ-bench](https://github.com/sierra-research/tau-bench) has been added, enabling the evaluation of AI Agent performance and reliability in real-world scenarios involving dynamic user and tool interactions. For usage instructions, please refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset/llm.html#bench).
- 🔥 **[2025.07.14]** Support for "Humanity's Last Exam" ([Humanity's-Last-Exam](https://modelscope.cn/datasets/cais/hle)), a highly challenging evaluation benchmark. For usage instructions, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset/llm.html#humanity-s-last-exam).
- 🔥 **[2025.07.03]** Refactored Arena Mode: now supports custom model battles, outputs a model leaderboard, and provides battle result visualization. See [reference](https://evalscope.readthedocs.io/en/latest/user_guides/arena.html) for details.
- 🔥 **[2025.06.28]** Optimized custom dataset evaluation: now supports evaluation without reference answers. Enhanced LLM judge usage, with built-in modes for "scoring directly without reference answers" and "checking answer consistency with reference answers". See [reference](https://evalscope.readthedocs.io/en/latest/advanced_guides/custom_dataset/llm.html#qa) for details.
- 🔥 **[2025.06.19]** Added support for the [BFCL-v3](https://modelscope.cn/datasets/AI-ModelScope/bfcl_v3) benchmark, designed to evaluate model function-calling capabilities across various scenarios. For more information, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/third_party/bfcl_v3.html).
- 🔥 **[2025.06.02]** Added support for the Needle-in-a-Haystack test. Simply specify `needle_haystack` to conduct the test, and a corresponding heatmap will be generated in the `outputs/reports` folder, providing a visual representation of the model's performance. Refer to the [documentation](https://evalscope.readthedocs.io/en/latest/third_party/needle_haystack.html) for more details.
- 🔥 **[2025.05.29]** Added support for two long document evaluation benchmarks: [DocMath](https://modelscope.cn/datasets/yale-nlp/DocMath-Eval/summary) and [FRAMES](https://modelscope.cn/datasets/iic/frames/summary). For usage guidelines, please refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset/index.html).
- 🔥 **[2025.05.16]** Model service performance stress testing now supports setting various levels of concurrency and outputs a performance test report. [Reference example](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/quick_start.html#id3).
- 🔥 **[2025.05.13]** Added support for the [ToolBench-Static](https://modelscope.cn/datasets/AI-ModelScope/ToolBench-Static) dataset to evaluate model's tool-calling capabilities. Refer to the [documentation](https://evalscope.readthedocs.io/en/latest/third_party/toolbench.html) for usage instructions. Also added support for the [DROP](https://modelscope.cn/datasets/AI-ModelScope/DROP/dataPeview) and [Winogrande](https://modelscope.cn/datasets/AI-ModelScope/winogrande_val) benchmarks to assess the reasoning capabilities of models.
- 🔥 **[2025.04.29]** Added Qwen3 Evaluation Best Practices, [welcome to read 📖](https://evalscope.readthedocs.io/en/latest/best_practice/qwen3.html)
- 🔥 **[2025.04.27]** Support for text-to-image evaluation: Supports 8 metrics including MPS, HPSv2.1Score, etc., and evaluation benchmarks such as EvalMuse, GenAI-Bench. Refer to the [user documentation](https://evalscope.readthedocs.io/en/latest/user_guides/aigc/t2i.html) for more details.
- 🔥 **[2025.04.10]** Model service stress testing tool now supports the `/v1/completions` endpoint (the default endpoint for vLLM benchmarking)
- 🔥 **[2025.04.08]** Support for evaluating embedding model services compatible with the OpenAI API has been added. For more details, check the [user guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/mteb.html#configure-evaluation-parameters).
- 🔥 **[2025.03.27]** Added support for [AlpacaEval](https://www.modelscope.cn/datasets/AI-ModelScope/alpaca_eval/dataPeview) and [ArenaHard](https://modelscope.cn/datasets/AI-ModelScope/arena-hard-auto-v0.1/summary) evaluation benchmarks. For usage notes, please refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset/index.html)
- 🔥 **[2025.03.20]** The model inference service stress testing now supports generating prompts of specified length using random values. Refer to the [user guide](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/examples.html#using-the-random-dataset) for more details.
- 🔥 **[2025.03.13]** Added support for the [LiveCodeBench](https://www.modelscope.cn/datasets/AI-ModelScope/code_generation_lite/summary) code evaluation benchmark, which can be used by specifying `live_code_bench`. Supports evaluating QwQ-32B on LiveCodeBench, refer to the [best practices](https://evalscope.readthedocs.io/en/latest/best_practice/eval_qwq.html).
- 🔥 **[2025.03.11]** Added support for the [SimpleQA](https://modelscope.cn/datasets/AI-ModelScope/SimpleQA/summary) and [Chinese SimpleQA](https://modelscope.cn/datasets/AI-ModelScope/Chinese-SimpleQA/summary) evaluation benchmarks. These are used to assess the factual accuracy of models, and you can specify `simple_qa` and `chinese_simpleqa` for use. Support for specifying a judge model is also available. For more details, refer to the [relevant parameter documentation](https://evalscope.readthedocs.io/en/latest/get_started/parameters.html).
- 🔥 **[2025.03.07]** Added support for the [QwQ-32B](https://modelscope.cn/models/Qwen/QwQ-32B/summary) model, evaluate the model's reasoning ability and reasoning efficiency, refer to [📖 Best Practices for QwQ-32B Evaluation](https://evalscope.readthedocs.io/en/latest/best_practice/eval_qwq.html) for more details.
- 🔥 **[2025.03.04]** Added support for the [SuperGPQA](https://modelscope.cn/datasets/m-a-p/SuperGPQA/summary) dataset, which covers 13 categories, 72 first-level disciplines, and 285 second-level disciplines, totaling 26,529 questions. You can use it by specifying `super_gpqa`.
- 🔥 **[2025.03.03]** Added support for evaluating the IQ and EQ of models. Refer to [📖 Best Practices for IQ and EQ Evaluation](https://evalscope.readthedocs.io/en/latest/best_practice/iquiz.html) to find out how smart your AI is!
- 🔥 **[2025.02.27]** Added support for evaluating the reasoning efficiency of models. Refer to [📖 Best Practices for Evaluating Thinking Efficiency](https://evalscope.readthedocs.io/en/latest/best_practice/think_eval.html). This implementation is inspired by the works [Overthinking](https://doi.org/10.48550/arXiv.2412.21187) and [Underthinking](https://doi.org/10.48550/arXiv.2501.18585).
- 🔥 **[2025.02.25]** Added support for two model inference-related evaluation benchmarks: [MuSR](https://modelscope.cn/datasets/AI-ModelScope/MuSR) and [ProcessBench](https://www.modelscope.cn/datasets/Qwen/ProcessBench/summary). To use them, simply specify `musr` and `process_bench` respectively in the datasets parameter.
- 🔥 **[2025.02.18]** Supports the AIME25 dataset, which contains 15 questions (Grok3 scored 93 on this dataset).
- 🔥 **[2025.02.13]** Added support for evaluating DeepSeek distilled models, including AIME24, MATH-500, and GPQA-Diamond datasets,refer to [best practice](https://evalscope.readthedocs.io/en/latest/best_practice/deepseek_r1_distill.html); Added support for specifying the `eval_batch_size` parameter to accelerate model evaluation.
- 🔥 **[2025.01.20]** Support for visualizing evaluation results, including single model evaluation results and multi-model comparison, refer to the [📖 Visualizing Evaluation Results](https://evalscope.readthedocs.io/en/latest/get_started/visualization.html) for more details; Added [`iquiz`](https://modelscope.cn/datasets/AI-ModelScope/IQuiz/summary) evaluation example, evaluating the IQ and EQ of the model.
- 🔥 **[2025.01.07]** Native backend: Support for model API evaluation is now available. Refer to the [📖 Model API Evaluation Guide](https://evalscope.readthedocs.io/en/latest/get_started/basic_usage.html#api) for more details. Additionally, support for the `ifeval` evaluation benchmark has been added.
- 🔥🔥 **[2024.12.31]** Support for adding benchmark evaluations, refer to the [📖 Benchmark Evaluation Addition Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/add_benchmark.html); support for custom mixed dataset evaluations, allowing for more comprehensive model evaluations with less data, refer to the [📖 Mixed Dataset Evaluation Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/collection/index.html).
- 🔥 **[2024.12.13]** Model evaluation optimization: no need to pass the `--template-type` parameter anymore; supports starting evaluation with `evalscope eval --args`. Refer to the [📖 User Guide](https://evalscope.readthedocs.io/en/latest/get_started/basic_usage.html) for more details.
- 🔥 **[2024.11.26]** The model inference service performance evaluator has been completely refactored: it now supports local inference service startup and Speed Benchmark; asynchronous call error handling has been optimized. For more details, refer to the [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/index.html).
- 🔥 **[2024.10.31]** The best practice for evaluating Multimodal-RAG has been updated, please check the [📖 Blog](https://evalscope.readthedocs.io/zh-cn/latest/blog/RAG/multimodal_RAG.html#multimodal-rag) for more details.
- 🔥 **[2024.10.23]** Supports multimodal RAG evaluation, including the assessment of image-text retrieval using [CLIP_Benchmark](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/clip_benchmark.html), and extends [RAGAS](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/ragas.html) to support end-to-end multimodal metrics evaluation.
- 🔥 **[2024.10.8]** Support for RAG evaluation, including independent evaluation of embedding models and rerankers using [MTEB/CMTEB](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/mteb.html), as well as end-to-end evaluation using [RAGAS](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/ragas.html).
- 🔥 **[2024.09.18]** Our documentation has been updated to include a blog module, featuring some technical research and discussions related to evaluations. We invite you to [📖 read it](https://evalscope.readthedocs.io/en/refact_readme/blog/index.html).
- 🔥 **[2024.09.12]** Support for LongWriter evaluation, which supports 10,000+ word generation. You can use the benchmark [LongBench-Write](evalscope/third_party/longbench_write/README.md) to measure the long output quality as well as the output length.
- 🔥 **[2024.08.30]** Support for custom dataset evaluations, including text datasets and multimodal image-text datasets.
- 🔥 **[2024.08.20]** Updated the official documentation, including getting started guides, best practices, and FAQs. Feel free to [📖read it here](https://evalscope.readthedocs.io/en/latest/)!
- 🔥 **[2024.08.09]** Simplified the installation process, allowing for pypi installation of vlmeval dependencies; optimized the multimodal model evaluation experience, achieving up to 10x acceleration based on the OpenAI API evaluation chain.
- 🔥 **[2024.07.31]** Important change: The package name `llmuses` has been changed to `evalscope`. Please update your code accordingly.
- 🔥 **[2024.07.26]** Support for **VLMEvalKit** as a third-party evaluation framework to initiate multimodal model evaluation tasks.
- 🔥 **[2024.06.29]** Support for **OpenCompass** as a third-party evaluation framework, which we have encapsulated at a higher level, supporting pip installation and simplifying evaluation task configuration.
- 🔥 **[2024.06.13]** EvalScope seamlessly integrates with the fine-tuning framework SWIFT, providing full-chain support from LLM training to evaluation.
- 🔥 **[2024.06.13]** Integrated the Agent evaluation dataset ToolBench.
## ❤️ Community & Support
Welcome to join our community to communicate with other developers and get help.
[Discord Group](https://discord.com/invite/D27yfEFVz5) | WeChat Group | DingTalk Group
:-------------------------:|:-------------------------:|:-------------------------:
 |
|  |
| 
## 🛠️ Environment Setup
We recommend using `conda` to create a virtual environment and install with `pip`.
1. **Create and Activate Conda Environment** (Python 3.10 recommended)
```shell
conda create -n evalscope python=3.10
conda activate evalscope
```
2. **Install EvalScope**
- **Method 1: Install via PyPI (Recommended)**
```shell
pip install evalscope
```
- **Method 2: Install from Source (For Development)**
```shell
git clone https://github.com/modelscope/evalscope.git
cd evalscope
pip install -e .
```
3. **Install Additional Dependencies** (Optional)
Install corresponding feature extensions according to your needs:
```shell
# Performance testing
pip install 'evalscope[perf]'
# Visualization App
pip install 'evalscope[app]'
# Other evaluation backends
pip install 'evalscope[opencompass]'
pip install 'evalscope[vlmeval]'
pip install 'evalscope[rag]'
# Install all dependencies
pip install 'evalscope[all]'
```
> If you installed from source, please replace `evalscope` with `.`, for example `pip install '.[perf]'`.
> [!NOTE]
> This project was formerly known as `llmuses`. If you need to use `v0.4.3` or earlier versions, please run `pip install llmuses<=0.4.3` and use `from llmuses import ...` for imports.
## 🚀 Quick Start
You can start evaluation tasks in two ways: **command line** or **Python code**.
### Method 1. Using Command Line
Execute the `evalscope eval` command in any path to start evaluation. The following command will evaluate the `Qwen/Qwen2.5-0.5B-Instruct` model on `gsm8k` and `arc` datasets, taking only 5 samples from each dataset.
```bash
evalscope eval \
--model Qwen/Qwen2.5-0.5B-Instruct \
--datasets gsm8k arc \
--limit 5
```
### Method 2. Using Python Code
Use the `run_task` function and `TaskConfig` object to configure and start evaluation tasks.
```python
from evalscope import run_task, TaskConfig
# Configure evaluation task
task_cfg = TaskConfig(
model='Qwen/Qwen2.5-0.5B-Instruct',
datasets=['gsm8k', 'arc'],
limit=5
)
# Start evaluation
run_task(task_cfg)
```
💡 Tip: `run_task` also supports dictionaries, YAML or JSON files as configuration.
**Using Python Dictionary**
```python
from evalscope.run import run_task
task_cfg = {
'model': 'Qwen/Qwen2.5-0.5B-Instruct',
'datasets': ['gsm8k', 'arc'],
'limit': 5
}
run_task(task_cfg=task_cfg)
```
**Using YAML File** (`config.yaml`)
```yaml
model: Qwen/Qwen2.5-0.5B-Instruct
datasets:
- gsm8k
- arc
limit: 5
```
```python
from evalscope.run import run_task
run_task(task_cfg="config.yaml")
```
### Output Results
After evaluation completion, you will see a report in the terminal in the following format:
```text
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Model Name | Dataset Name | Metric Name | Category Name | Subset Name | Num | Score |
+=======================+================+=================+=================+===============+=======+=========+
| Qwen2.5-0.5B-Instruct | gsm8k | AverageAccuracy | default | main | 5 | 0.4 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Easy | 5 | 0.8 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Challenge | 5 | 0.4 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
```
## 📈 Advanced Usage
### Custom Evaluation Parameters
You can fine-tune model loading, inference, and dataset configuration through command line parameters.
```shell
evalscope eval \
--model Qwen/Qwen3-0.6B \
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}' \
--generation-config '{"do_sample":true,"temperature":0.6,"max_tokens":512}' \
--dataset-args '{"gsm8k": {"few_shot_num": 0, "few_shot_random": false}}' \
--datasets gsm8k \
--limit 10
```
- `--model-args`: Model loading parameters such as `revision`, `precision`, etc.
- `--generation-config`: Model generation parameters such as `temperature`, `max_tokens`, etc.
- `--dataset-args`: Dataset configuration parameters such as `few_shot_num`, etc.
For details, please refer to [📖 Complete Parameter Guide](https://evalscope.readthedocs.io/en/latest/get_started/parameters.html).
### Evaluating Online Model APIs
EvalScope supports evaluating model services deployed via APIs (such as services deployed with vLLM). Simply specify the service address and API Key.
1. **Start Model Service** (using vLLM as example)
```shell
export VLLM_USE_MODELSCOPE=True
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-0.5B-Instruct \
--served-model-name qwen2.5 \
--port 8801
```
2. **Run Evaluation**
```shell
evalscope eval \
--model qwen2.5 \
--eval-type openai_api \
--api-url http://127.0.0.1:8801/v1 \
--api-key EMPTY \
--datasets gsm8k \
--limit 10
```
### ⚔️ Arena Mode
Arena mode evaluates model performance through pairwise battles between models, providing win rates and rankings, perfect for horizontal comparison of multiple models.
```text
# Example evaluation results
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
```
For details, please refer to [📖 Arena Mode Usage Guide](https://evalscope.readthedocs.io/en/latest/user_guides/arena.html).
### 🖊️ Custom Dataset Evaluation
EvalScope allows you to easily add and evaluate your own datasets. For details, please refer to [📖 Custom Dataset Evaluation Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/custom_dataset/index.html).
## 🧪 Other Evaluation Backends
EvalScope supports launching evaluation tasks through third-party evaluation frameworks (we call them "backends") to meet diverse evaluation needs.
- **Native**: EvalScope's default evaluation framework with comprehensive functionality.
- **OpenCompass**: Focuses on text-only evaluation. [📖 Usage Guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/opencompass_backend.html)
- **VLMEvalKit**: Focuses on multi-modal evaluation. [📖 Usage Guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/vlmevalkit_backend.html)
- **RAGEval**: Focuses on RAG evaluation, supporting Embedding and Reranker models. [📖 Usage Guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/index.html)
- **Third-party Evaluation Tools**: Supports evaluation tasks like [ToolBench](https://evalscope.readthedocs.io/en/latest/third_party/toolbench.html).
## ⚡ Inference Performance Evaluation Tool
EvalScope provides a powerful stress testing tool for evaluating the performance of large language model services.
- **Key Metrics**: Supports throughput (Tokens/s), first token latency (TTFT), token generation latency (TPOT), etc.
- **Result Recording**: Supports recording results to `wandb` and `swanlab`.
- **Speed Benchmarks**: Can generate speed benchmark results similar to official reports.
For details, please refer to [📖 Performance Testing Usage Guide](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/index.html).
Example output is shown below:

## 📊 Visualizing Evaluation Results
EvalScope provides a Gradio-based WebUI for interactive analysis and comparison of evaluation results.
1. **Install Dependencies**
```bash
pip install 'evalscope[app]'
```
2. **Start Service**
```bash
evalscope app
```
Visit `http://127.0.0.1:7861` to open the visualization interface.

Settings Interface

Model Comparison

Report Overview

Report Details
For details, please refer to [📖 Visualizing Evaluation Results](https://evalscope.readthedocs.io/en/latest/get_started/visualization.html).
## 👷♂️ Contributing
We welcome any contributions from the community! If you want to add new evaluation benchmarks, models, or features, please refer to our [Contributing Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/add_benchmark.html).
Thanks to all developers who have contributed to EvalScope!
## 📚 Citation
If you use EvalScope in your research, please cite our work:
```bibtex
@misc{evalscope_2024,
title={{EvalScope}: Evaluation Framework for Large Models},
author={ModelScope Team},
year={2024},
url={https://github.com/modelscope/evalscope}
}
```
## ⭐ Star History
[](https://star-history.com/#modelscope/evalscope&Date)