https://github.com/monchin/tablers
A blazingly fast PDF table extraction library with python API powered by Rust
https://github.com/monchin/tablers
pdf python rust table-extraction
Last synced: 4 months ago
JSON representation
A blazingly fast PDF table extraction library with python API powered by Rust
- Host: GitHub
- URL: https://github.com/monchin/tablers
- Owner: monchin
- License: mit
- Created: 2025-12-09T07:27:48.000Z (7 months ago)
- Default Branch: master
- Last Pushed: 2026-02-23T13:43:59.000Z (4 months ago)
- Last Synced: 2026-02-23T20:50:41.571Z (4 months ago)
- Topics: pdf, python, rust, table-extraction
- Language: Rust
- Homepage: https://monchin.github.io/tablers/
- Size: 13.1 MB
- Stars: 4
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- License: LICENSE
- Agents: AGENTS.md
Awesome Lists containing this project
README


⚡ Tablers
A blazingly fast PDF table extraction library with python API powered by Rust




---
## Features
- 🚀 **Blazingly Fast** - Core algorithms written in Rust for maximum performance
- 🐍 **Pythonic API** - Easy-to-use Python interface with full type hints
- 📄 **Edge Detection** - Accurate table detection using line and rectangle edge analysis
- 📝 **Text Extraction** - Extract text content from table cells with configurable settings
- 📤 **Multiple Export Formats** - Export tables to CSV, Markdown, and HTML
- 🔐 **Encrypted PDFs** - Support for password-protected PDF documents
- 💾 **Memory Efficient** - Lazy page loading for handling large PDF files
- 🖥️ **Cross-Platform** - Works on Windows, Linux, and macOS
## Why Tablers?
This project draws significant inspiration from the table extraction modules of [pdfplumber](https://github.com/jsvine/pdfplumber) and [PyMuPDF](https://github.com/pymupdf/PyMuPDF). Compared to `pdfplumber` and `PyMuPDF`, `tablers` has the following advantages:
- **High Performance**: Utilizes Rust for high-performance PDF processing
- **More Configurable**: Supports customizable table filter settings (`min_rows`, `min_columns`, `include_single_cell`, e.g., see [this issue](https://github.com/pymupdf/PyMuPDF/issues/3987))
- **Clean Python Dependencies**: No external python dependencies required
## Benchmark
Performance comparison of tablers, pymupdf and pdfplumber for PDF table extraction:
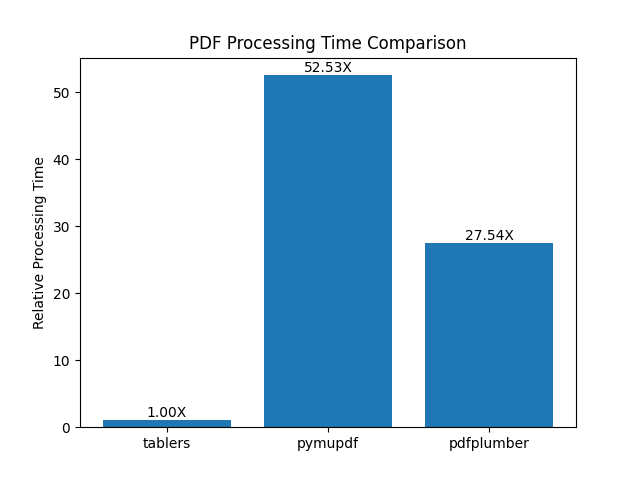
For more details, please refer to the [tablers-benchmark](https://github.com/monchin/tablers-benchmark) repository.
## Note
This solution is primarily designed for text-based PDFs and does not support scanned PDFs.
## Installation
```bash
pip install tablers
```
## Quick Start
### Basic Table Extraction
```python
from tablers import Document, find_tables
# Open a PDF document
doc = Document("example.pdf")
# Extract tables from each page
for page in doc.pages():
tables = find_tables(page, extract_text=True)
for table in tables:
print(f"Found table with {len(table.cells)} cells")
for cell in table.cells:
print(f" Cell: {cell.text} at {cell.bbox}")
doc.close()
```
### Using Context Manager
```python
from tablers import Document, find_tables
with Document("example.pdf") as doc:
page = doc.get_page(0) # Get first page
tables = find_tables(page, extract_text=True)
for table in tables:
print(f"Table bbox: {table.bbox}")
```
For more advanced usage, please refer to the [documents](https://monchin.github.io/tablers/).
## Requirements
- Python >= 3.10
- Supported platforms: Windows (x64), Linux (x64) with glibc >= 2.28, macOS (ARM64)
## License
This project is licensed under the MIT License - see the [LICENSE](https://github.com/monchin/tablers/blob/master/LICENSE) file for details.
## Acknowledgments
- [pdfplumber](https://github.com/jsvine/pdfplumber) - PDF parsing library
- [PyMuPDF](https://github.com/pymupdf/PyMuPDF) - PDF parsing library
- [pdfium-render](https://github.com/ajrcarey/pdfium-render) - Rust bindings for PDFium
- [PyO3](https://github.com/PyO3/pyo3) - Rust bindings for Python