https://github.com/mr-won/operating_system
컴퓨터공학과 운영체제 정리입니다.
https://github.com/mr-won/operating_system
operating-system
Last synced: about 1 year ago
JSON representation
컴퓨터공학과 운영체제 정리입니다.
- Host: GitHub
- URL: https://github.com/mr-won/operating_system
- Owner: mr-won
- Created: 2023-02-23T16:10:52.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2025-03-14T02:21:51.000Z (over 1 year ago)
- Last Synced: 2025-03-18T02:27:11.693Z (over 1 year ago)
- Topics: operating-system
- Language: Java
- Homepage:
- Size: 1.82 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## 리버싱용 운영체제 복습
# Operating_System
컴퓨터공학과 운영체제 정리입니다.
### 23.06 운영체제 종강

```
운영체제의 의의, cpu 스케줄링 알고리즘, 디스크 스케줄링 알고리즘, 교착상태, 가상메모리, 파일 시스템 등
유닉스,리눅스,윈도우 등 운영체제의 이론과 실제를 배울 수 있었던 과목
```
## 1.1 운영체제란?
```
운영체제란 Operating System(OS) 컴퓨터를 운영하기 위한 수법과 절차를 모은 소프트웨어 체계입니다.
운영체제의 가장 기본적인 역할 중의 하나는 사용자로 하여금 하드웨어인 입.출력 장치를 편리하게 사용할 수 있게 하는 것이다.
만약 운영체제가 없다면 일반 사용자는 키보드, 마우스, 모니터, 프린터 등을 사용할 수 없어서 컴퓨터는 무용지물이 된다.
운영체제는 시스템 콜이라고 부르는 서비스 요청 접속 창구를 라이브러리 형태로 제공한다.
사용자는 시스템 콜 라이브러리를 호출하는 프로그램을 작성하여 실행함으로써 운영체제가 제공하는 서비스를 받을 수 있다.
자주 사용되는 운영체제 서비스는 미리 작성되어 시스템에 탑재되어 있는 프로그램을 실행시켜 호출할 수 있는데 이러한 프로그램을 시스템 명령어라 부른다.
```
## 1.2 운영체제의 유형(발전과정)
### 1. 단일 프로그래밍 일괄 처리 시스템(Single-stream Batch(일괄로 묶다) Processing)
```
단일 프로그래밍 일괄 처리 시스템 환경에서 사용자는 컴퓨터에 접근할 수 없었으므로 프로그램을 천공 카드에
작성하여 관리자에게 제출하였고, 운영체제는 오직 하나의 프로그램만을 적재하여 차례차례 실행시켰다.
적재된 프로그램이 오직 하나 밖에 없었으므로, 사용자 프로그램이 입출력을 요구했을 때 운영체제는 입출력이
완료될 때까지 프로세서를 기다려야 했으므로 허비하는 시간(Idle Time)이 많았다.
```
### 2. 다중 프로그래밍 일괄 처리 시스템(Multiprogramming Batch Programming)
```
다중 프로그래밍 일괄 처리 시스템에서는 사용자 프로그램을 동시에 여러 개 적재시켜 실행중인 프로그램이
입출력을 요구하면 그 입출력 작업이 진행되는 동안에 다른 프로그램을 실행시켜줌으로써 프로세서의 유후 시간을 줄였다.
그러나 적재된 프로그램들의 완료 시간이 다른 프로그램의 입출력 요구 빈도에 따라 큰 영향을 받으므로 각 프로그램들의 완료시간
편차가 심하다.
```
### 3. 시분할 시스템(Time-Sharing System)
```
시분할 시스템은 여러 개의 프로그램을 짧은 시간(타임 퀀텀) 동안 조금씩 번갈아 가면서 처리함으로써 사용자에게
시스템을 독차지하고 있다는 느낌을 준다.
시분할 시스템은 다수의 사용자들이 단말기를 통해서 컴퓨터에 동시 접속하는 대화적 처리 환경에 적합하다.
```
### 4. 병렬 처리 시스템(Parallel Processing Systems)
```
병렬 처리 시스템은 여러 개의 처리기(CPU)를 이용하여 여러 개의 프로그램들을 병렬로 처리한다.
병럴 처리 시스템의 목적은 성능 향상과 신뢰성 향상(결함 허용)에 있다.
병렬 처리(Parallel Processing)은 어느 시점을 기준으로 보았을 때 2개 이상의 프로그램을 처리하는 것을 말하고,
병행 처리(Concurrent Processing)는 어느 시점을 기준으로 보았을 때는 오직 하나의 프로그램만을 처리하지만,
이들을 번갈아 처리함으로써 일정 기간 동안 결국 여러 개의 프로그램을 처리하는 것을 말한다.
병렬 처리를 위한 다중 처리기 시스템은 분산 처리 시스템의 일종으로 강결합(Tightly-coupled System)이라 부르기도 한다.
다중 처리기 시스템은 처리기들 사이의 버스 연결 방식에 따라 단일 공유 버스, 다중 버스, 크로스바 스위치 버스, 계층적 버스
다중 포트 메모리 버스 등으로 분류된다.
처리기들이 독립적이지 않고 주어진 기계 명령어에 대하여 서로 긴밀하게 협조하여 서로 다른 데이터에 대한 동일한 연산 처리를
수행하는 다중 처리기 형태가 있는데 배열(혹은 벡터) 처리기가 그 대표적인 예이다.
```
### 병렬 처리 시스템의 종류
```
병렬 처리 시스템은 대칭형과 비대칭형으로 나뉘는데 대칭형은 CPU가 모두 운영체제를 이용하게 될 때(경쟁 상황일 때)
역할의 범위가 동등하여 운영체제의 부담이 커지게 된다.
이러한 운영체제의 부담을 줄이기 위해서 비대칭 시스템이 있는데 비대칭 시스템은 마스터-슬레이브 관계가 되어
마스터인 경우에만 운영체제를 사용할 수 있게 되어 운영체제의 구현이 간단해지는 장점이 있다.
하지만 마스터가 고장나면 대책이 없다.
```
### 4. 분산 처리 시스템의 일종인 강결합 시스템(시스템 버스, 메모리 등이용)
```
1. 단일 공유 버스 : CPU들이(처리기들)이 하나의 버스를 공유하여 메모리에 접근하므로 경쟁 구도, 배타적인 성향을 띠며
CPU를 추가해도 성능은 갈 수록 저하된다. 어느 순간 없는게 더 나을 수도 있다.
2. 다중 버스 : CPU가 여러 개의 버스를 공유한다. 1:1 느낌 하지만 모든 버스가 사용중이면 기다려야 한다.
3. 크로스바 스위치 버스 : 교차 지점에 스위치를 갖다두어 물리적인 버스의 수를 줄였다.
4. 계층적 버스 : 로컬 버스(Local Bus와 시스템버스(Global bus)로 나누고 전용 메모리 처리기를 로컬 버스에 두고
커버가 안되는 메모리를 컴파일러가 배분하고 배치하게 된다
5. 다중 포트 메모리 : 예로 CPU -> VRAM -> GPU 를 들 수 있다. VRAM은 포트가 두개로 CPU와 GPU와의 버스 경쟁 없이
VRAM의 내용을 읽어서 모니터에 디스플레이할 수 있는 장점이 있다.
```
### 분산 처리 시스템(Distributed Computing Systems)
```
분산 처리 시스템은 독립된 시스템들이 버스가 아닌 네트워크로 연결되어 병렬 처리 환경을 제공한다.
분산 처리 시스템의 목적 및 효과로서 성능향상, 자원공유, 신뢰성 향상, 점진적 확장 등을 들 수 있다.
분산 처리 시스템은 위치 투명성, 접근 투명성, 고장 투명성, 중복 및 이동 투명성 등의 기능이 제공되어야 한다.
(어디 있는 지,중복인지, 이동이 되었는 지, 고장이 났는 지를 사용자는 그 내용을 인식할 필요가 없다는 뜻)
분산 처리 시스템은 네트워크로 연결되므로, 버스로 연결되는 강결합 시스템에 대비되는 개념으로
약결합 시스템 혹은 클러스터 시스템이라고 부른다.
분산 처리 시스템의 연결 형태에는 하이퍼 큐브, 완전 연결, 성형, 링형 등이 있다.
```
### 분산 처리 시스템의 연결 형태
```
1. 하이퍼 큐브 : 노드 간의 평균 거리가 짧고 경로 배정이 비교적 간단하다. 노드 하나의 연결된 노드 수를 n이라고 할 때 총 노드의 수는
2의 n승이 된다.
2. 완전 연결 : 모든 노드들이 직접 1:1 통신을 할 수 있도록 연결한 연결 형태이다. 사이트 간 통신 속도가 빠르고 연결 경로가 많아
통신 신뢰성이 높다는 장점이 있다. 하지만 초기 설치 비용과 확장 비용이 크다.
3. 성형 : 중앙에 중계 시스템을 두는 형태로 초기 설치, 확장이 쉽지만 중개 역할이 고장나면 안되서 신뢰성이 낮다.
4. 링형 : 성형 연결의 단점과 장점을 절충한 형태로 연결 반경이 좁고 새로운 노드 추가가 용히하나 두 개 이상의 노드가 다운되면 전체
네트워크가 양분된다.
```
## 컴퓨터의 주요 구성 요소
```
컴퓨터의 주요 구성 요소는 시스템 버스, 즉 어드레스 버스, 데이터 버스, 제어 버스 등 3 종류의 버스로 연결되어 있다.
```
## 주기억 장치(Main Memory)
```
주기억장치는 비트(Bit) 8개의 묶음으로 이루어진 바이트(byte) 단위로 주소가 배정된다.
읽기 쓰기는 바이트 단위의 배수로 가능한데, 어떤 CPU는 한꺼번에 접근하려는 바이트들의 시작주소가 특정 조건을
만족하도록 하는 메모리 얼라이먼트(Memory Alignment)를 요구하기도 한다.
```
## 기계 명령어(Machine Instruction)
```
기계 명령어(Machine Instruction)은 연산코드(Operation code)와 피연산자(Operand)로 구성되고, 연산코드 부분의
크기는 연산 종류의 개수를, 피연산자 부분의 크기는 최대 메모리 용량을 결정한다.
피연산자는 연산코드에 따라 주소, 상수, 레지스터 번호 등 다양하게 해석된다.
```
## 기계 사이클(Machine Cycle)
```
기계 사이클은 CPU가 반복적으로 처리하는 동작의 패턴으로서, 명령어 인출(Fetch), 명령어 해석(Decode),
피연산자 인출(Operand), 연산 처리(Execution) 주기 등 크게 4개의 주 스텝으로 구성된다.
하나의 명령어 연산이 완료되면 CPU는 자동적으로 PC 레지스터가 가르키는 다음 명령어 처리를 개시한다.
```
## 레지스터(Register)
```
레지스터(Register)란 소량의 데이터를 특별한 용도로 저장하는 곳으로, 크게 CPU 레지스터와 특수 레지스터(SFR),
입-출력 레지스터로 분류된다.
CPU 레지스터는 주로 연산을 위한 피연산자의 임시 저장 용도로, 특수 목적 레지스터는 컴퓨터의 상태 설정 등 특수 용도로,
그리고 입 출력 레지스터는 주변 장치와의 입 출력 창구 용도로 사용된다.
```
## 주소 지정 모드(Addressing mode)
```
주소 지정 모드는 피연산자를 해석할 수 있는 유형을 말하고, 직접(Direct), 간접(Indirect), 절대(Absolute)
상대(Relative), 주소(Address), 상수(Constant) 관점에서 분류된다.
```
## 인터럽트(Interrupt)
```
인터럽트가 발생하면 CPU는 처리 중이던 명령어 순서를 보관한 후, 사전에 설정된 주소로 점프하여 새로운 처리를 시작하게 되는데,
이 부분을 인터럽트 서비스 루틴(ISR: Interrupt Service Routine) 혹은 인터럽트 핸들러(Interrupt Handler)라 부른다.
```
## 인터럽트 벡터(Interrupt Vector)
```
인터럽트들은 고유의 번호에 의해 식별되고, 이들 인터럽트들에 대응되는 인터럽트 핸들러들의 주소가 표 형태로 기록된
부분을 인터럽트 벡터(Interrupt Vector)라 한다.
인터럽트 벡터는 CPU에 따라 고정된 경우와 설정 가능한 경우가 있고, 그 크기는 보통 수십 ~ 수백 개 정도의 인터럽트를
지원할 수 있다.
```
## 인터럽트 우선순위(Interrupt Priority)
```
여러 개의 인터럽트가 동시에 발생하거나, 인터럽트 핸들러 처리 도중 다른 인터럽트가 발생하면 CPU 우선순위에 따라
처리 순서를 결정한다.
```
## 인터럽트 사이클(Interrupt Cycle)
```
CPU는 기계 사이클 마지막 주기인 인터럽트 사이클(Interrupt Cycle)에서 인터럽트 발생을 조사한다.
```
## 인터럽트 유형
```
1. 디바이스 인터럽트 : 입출력 장치 등과 같이 CPU 외부 하드웨어로 부터 발생하고 대부분의 인터럽트가 여기에 해당된다.
2. 오류 인터럽트 : 0으로 나누는 등의 연산 불가 상황에서 오류 인터럽트 루틴에 가서 대응한다.
3. 소프트웨어 인터럽트 : 기계 명령어에 의해 프로그램에서 인위적으로 발생되는 인터럽트를 소프트웨어 인터럽트라 하고
트랩이라고 부르기도 한다.
```
## 이중 모드 연산(Dual Mode Operation)
```
사용자 모드(사용자 프로그램 실행 모드)와 시스템 모드(운영체제 실행 모드)가 식별되는 경우를 이중 모드 연산
(Dual Mode Operation)이라 하고, 시스템 모드에서만 실행 가능한 기계 명령어를 특권 명령어(Privileged Instruction)라 한다.
```
## 입출력 장치
```
장치 구동기(IO Device Driver) : 상태, 명령, 데이터 레지스터, 키보드
상태 레지스터 : 입력 장치인 경우 입력되어있는 가의 여부 표시, 출력 장치인 경우 이전 데이터의 출력이 완료 되었는가를 표시
명령 레지스터 : 입력 혹은 출력의 기본 명령과 기타 해당 장치 고유의 명령을 저장함으로써 명령을 전달한다.
비동기적 입력(키보드 등) : 언제 들어올 지 모르는 명령을 처리
동기적 입력(디스크 등) : 입력 명령에 따라 입력
출력은 언제나 동기적
데이터 레지스터 : 입력된 데이터나 출력될 데이터를 보관한다.
```
## 입출력 장치의 식별
```
CPU에서 메모리에 접근하는 것(주소 공간을 식별
식별 방법
1. 메모리 대응 입출력 : 레지스터 이름 -> 입출력 포트 번호(수치)
메모리 접근 명령와 동일한 기계 명령어(load, save)를 사용하여 입출력을 진행함
2. 격리된 입출력 : 메모리 주소 공간과 입출력 포트공간이 같을 때는
입출력 레지스터가 주기억 장치 영역과 완전히 분리되어
다른 기계 명령어(in, out)을 사용하여 입출력을 진행함
```
## 컴퓨터 저장장치
```
레지스터 :
캐시 : CPU -> Memory의 데이터를 복사해두어서 다음에 같은 데이터를 가져올 때는 캐시메모리에서 가져온다.
캐시 메모리는 비싸서 10% 차지 캐시가 다 차면 오래된 데이터를 비우고 새로운 데이터를 넣는다.적으로 일반적으로는 캐시는 cpu와 주기억장치 사이에서 주기억장츼를 돕는 저장장치를 말한다.
주기억장치 : DRAM (Dynamic Random Access Memory): 일정 시간 지나면 저장되어 있는 것이 점점 사라짐 주기적으로 읽어줘야 해서 속도의 제한이 걸린다. 직접도를 더 높일 수 있어서 사용함..... 속도가 느리고
SRAM (Static Random Access Memory) : Refresh가 필요없고 전원이 공급되는 한 저장값이 안정적으로 유지된다. 속도가 빠르다.
전자 디스크 : SSD(Solid State Disk) : 하드디스크와 DRAM의 장점을 갖춘 플래시 메모리 기술 기반의 디스크
자기 디스크 :
광 디스크 :
자기 테이프
```
## 직접 입 출력 & 간접 입 출력
```
직접 입출력 : 운영체제가 응용프로그램과 하드웨어 사이에서 데이터를 가공없이 그대로 전달
간접 입출력 : 운영체제가 응용프로그램과 하드웨어 사이에서 데이터를 가공해서 전달(대부분)
문자단위 입출력 : 바이트 단위 입출력(키보드, LAN 등),
블록 입출력 : 디스크의 512바이트 단위 입출력과 같이 일정한 크기의 블록 단위 입출력
```
## 프로그램 입/출력
```
한 번에 이루어 질 수 있는 입출력량은 주변장치에 따라 다르나, 일반적으로 단말기와 같이 1바이트 단위로
이루어지는 경우를 문자 입출력 장치, 하드 디스크와 같이 수십~수백바이트 단위로 이루어지는 경우를
블록 입출력 장치라고 함
```
## 프로그램 입출력 혹은 바쁜 대기 입출력(Programmed I/O or Busy Waiting I/O)
```
운영체제(CPU)가 입출력 상태 레지스터 값을 지속적으로 읽어서 입 출력의 진행 완료 유휴 등의
상태를 확인하여 완료나 유휴 상태가 되면 입출력을 진행
```
## 인터럽트 기반 입출력(Interrupt-driven I/O)
```
운영체제는 입출력 명령 레지스터에 입출력 명령을 기록한 후 다른 사용자 프로그램으로 점프함으로써
입출력이 진행되는 동안 CPU는 다른 일을 수행. 입출력이 완료되어 CPU에게 인터럽트가 전달되면
CPU는 해당 인터럽트 핸들러에서 다음 입출력을 진행한 다음, 수행 중이던 원래 사용자 프로그램으로 복귀
```
## DMA 입 출력(DMA I/O)
```
운영체제는 입력 버퍼나 출력 데이터의 주소, 입출력 데이터 크기, 입력 혹은 출력 명령 등 세 가지를 DMA 처리기에
설정하고 다른 사용자 프로그램으로 점프. DMA는 CPU 대신 인터럽트 기반으로 입출력을 진행하고, 전체 입출력이
완료되면 CPU에 완료 인터럽트를 전달
```
## 입출력 채널
```
여러 개의 입 출력 장치를 관장하여 입출력을 처리하는 처리기를 입출력 채널이라고 하고,
실렉터 채널, 멀티플렉서 채널, 블록 멀티플렉서 채널 등 세 가지 유형이 있음
(DMA는 하나의 장치만 관리할 수 있는 단순 입출력 채널이라고 보면 됨)
실렉터 채널(Selector Channel)은 입출력 명령을 하나씩 받아 처리, 즉 여러 장치에 대한 동시 입출력을 하지 않는데,
그 이유는 입출력 장치들의 속도가 디스크와 같이 고속이기 때문임
멀티플렉서 채널(Multiplexor Channel)은 입출력 명령을 여러 개 받아서 동시 진행 가능
장치들이 키보드, 프린터 등과 같이 저속인 경우에만 가능
블록 멀티플렉서 채널(Block Multiplexor Channel)은 여러 개의 입출력 명령으로 구성된 명령어 집합(Block)을 받아
자동으로 차례차례 처리. 실렉터 채널과 멀티플렉서 채널 양쪽의 특성을 모두 가짐)
```
## 프로세스의 정의
```
프로세스 : 프로그래밍 언어로 작성된 후, 운영체제의 도움으로 주기억장치에 적재되어 실행중인프로그램
```
## 운영체제가 관리하는 프로세스 속성들
```
프로세스 고유번호(PID), 프로세스 메모리 정보, 프로세스 상태, 프로세스 진행지점,
프로세스 문맥, 프로세스 우선순위, 프로세스 자원목록, 회계정보 등
프로세스 문맥(Process Context) : 현재 진행중인 프로세스의 연산 명령어들에 의해
CPU 안에서 생산되어 보관 중인 값들을 프로세스 문맥이라고 한다.
문맥은 CPU가 진행 중이던 프로세스를 떠날 때 보관되었다가 나중에 처리를 재개하기 직전에
복원되어야 한다. 이를 문맥 교환이라고 한다.
```
## 프로세스 관리 블록
```
프로세스가 운영체제에 의해 하나의 관리 개체로 등록됨을 의미한다.
운영체제가 프로세스 관리를 위해 필요한 모든 정보를 기록하는 표를 PCB라고 하는데,
그 수는 곧 생성 가능한 최대 프로세스 수를 의미한다.
PCB는 주로 위에서 언급한 전형적인 프로세스 속성들이 저장된다.
```
## 프로세스 상태 (상태 천이)
```
운영체제는 프로세스의 처리과정에서 프로세스의 활동에 따라 해당 프로세스를 적절한 상태로 천이 시킨다.
실행 상태가 아닌 모든 프로세스는 해당 상태의 대기열에 관리된다.
프로세스 상태
준비 상태
실행 상태 dispatch : CPU를 어디에 할당할 지 배정하는 행위
대기 상태 Block State CPU 입출력을 기다리는
보류 상태 CPU 배정 대상에서 제외, 시간을 기다리는
대기-보류 상태 큐(대기열) FIFO 큐의 개념 1순위 대기 상태에서 너무 오래 있으면 보류 상태로 만든다.
종료 상태 : 완료 요청을 받고 제거 준비로 메모리에 남아있는 상태를 좀비(Zombie)라고 한다.
```
## 스레드 (Thread)
```
프로그램이 실행되는 흐름 줄기
보통 프로세스는 하나의 실행 줄기, 즉 하나의 스레드를 가짐(단일 스레드 프로세스)
```
## 다중 스레드 프로세스(Multi-thread Process)
```
운영체제의 요청으로 스레드가 여러 개가 있을 수 있다.
CPU가 반드시 여러 개일 필요는 없음
CPU가 하나이거나 여러 개일 경우에는 스레드를 병렬 처리됨
1+2+3+4 하려고 했는데 1+2 를 하나의 스레드로 3+4를 하나의 스레드로 나눠서 한다.
스레드가 각각 독립적으로 실행된다.(cpu가 하나씩 붙어서) -> 병렬 처리 (처리 시간을 단축시킬 수 있음)
CPU가 각자 기계 사이클을 실행한다.
```
## 스레드 생성 및 제거
```
운영체제에게 스레드 생성을 요청할 수 있다. pthread_create(스레드할 함수)
pthread_exit() 해당 스레드를 소멸 자동 변수는 참조하는 메모리를 별도로 분리해서 얽히지않지만
전역변수에 여러 스레드가 접근할 때는 경쟁 상황이 발생한다.
thread_join 스레드가 종료될 때까지 기다림
```
## 새로운 프로세스 생성과 제거
```
새로운 프로세서(Child)의 생성은 이미 생성되어 실행 중인 다른 프로세서(Parent 프로세서)가 운영체제에게 요청함으로써 이루어진다.
정상적인 프로세서 제거는 해당 프로세스 스스로가 운영체제에 요청함으로써 이루어짐
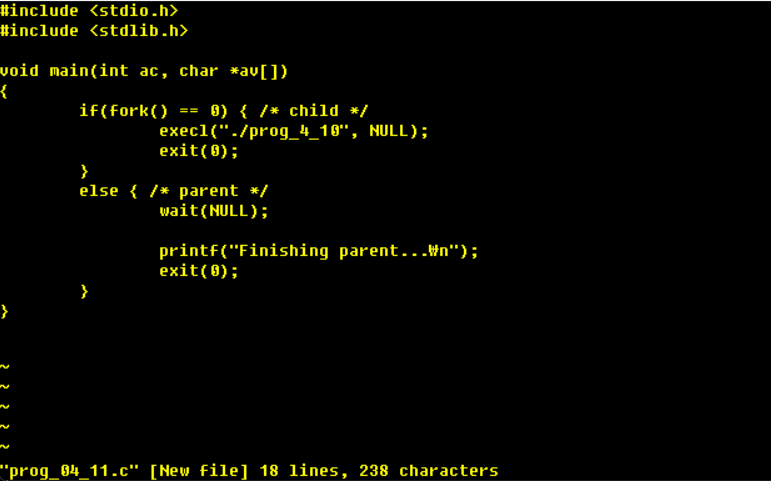
fork 부모는 fork > 0 자식은 fork = 0 if(fork = 0)이라면 새로운 프로그램을 적재하면 프로그램을 덮어쓰게 됨
```
## 4장 프로세스 및 스레드 관리 과제
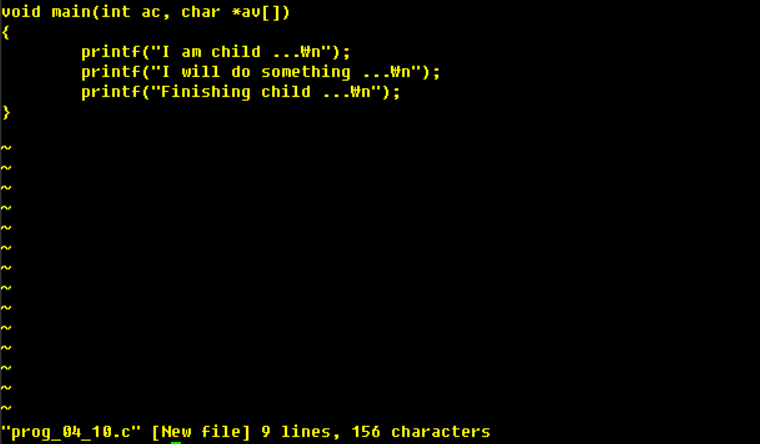
### prog_04_10.c
### prog_04_11.c
## 프로세스 간 통신(Inter-Process Communication : IPC)
```
프로세스들은 완전히 분리 독립되어 있어서 서로 간에 간섭하거나 정보를 주고 받을 수 없다.
거대한 프로그램을 여러 개의 작은 프로그램으로 분리할 경우, 이들 사이에는 통신할 수 있는 수단이
필요하게 되는데,이를 프로세스 간 통신(IPC, Inter-Process Communication)이라 부른다.
IPC의 대표적인 예로, 파이프, 메시지 큐, 공유 메모리, 세마포, 소켓 등을 들 수 있다.
```
## 프로세스 통제(Process Control)
```
운영체제는 사용자에게 실행 중인 프로그램을 통제할 수 있는 수단을 제공한다.
프로세스 통제의 전형적인 유형으로 강제 종료, 일시 중지, 실행 재개, 약속 처리, 우선순위 변경 등을
들 수 있다.
유닉스 리눅스에서는 프로세스 통제를 위해 kill() 시스템 콜과 kill 명령어를 제공한다.
```
## 단계별 처리 스케줄링
```
장기 스케줄링 : 대기 중인 프로그램들 중, 먼저 시작시킬 프로세스를 선택
중기 스케줄링 : 적재된 프로세스들 중, 처리를 잠시 보류할 프로세스를 선택
단기 스케줄링 : 준비 상태의 프로세스들 중, CPU를 먼저 할당할 프로세스를 선택
```
## CPU 스케줄링 전략의 목표 및 기준
```
사용자 관점에서의 CPU 스케줄링 목표 지표 3가지
응답(반응) 시간(Response Time) : 사용자 데이터 입력 후, 출력이 이루어질 때까지의 소요 시간(부분 시간)
반환 시간(Turnaround Time) : 프로그램 제출(혹은 시작) 후, 끝날 때까지 소요되는 총 시간 (전체 시간)
대기 시간(Waiting Time) : 프로세스들이 준비 상태로 대기열에서 기다린 시간의 총합
시스템 관점에서의 CPU 스케줄링 목표 지표
CPU 이용률(CPU Utilization) : 총 경과 시간 대비 CPU가 순수하게 사용자 프로세스를 수행한 시간의 비
-> 시스템을 운영하기 위해 하는 쓸 때 없는 작업(문맥 교환 등)
처리율(Throughput) : 단위 시간당 처리하는 프로세스의 개수
사용자 관점과 시스템 관점의 CPU 스케줄링 목표 지표는 상호 배타적 관계에 있는 경우가 일반적임
기타
가용성(Availability) : 전체 시간(서비스 시간 + 고장 시간 + 유지 보수 시간) 대비 서비스 시간의 비율로서 신뢰성(Reliability)이나
가동률과 유사한 개념이다.
-> 특정 자원에 대하여 즉시 접근할 수 있는 정도(즉시 접근 가능 빈도 비율)
```
## CPU 스케줄링이 이루어지는 시기
```
1. 프로세스가 입출력을 요구할 때(printf(), gets())
진행 중이던 프로세스가 입출력을 요구하면, 운영체제는 입출력 진행 동안 마냥 기다릴 수 없으므로 다른 프로세스를
선택해서 CPU를 보내야한다 <- 비선점 CPU 스케줄링
2. 프로세스가 종료를 요구할 때 (exit())
프로그램의 진행 절차상 모든 처리가 끝나 종료를 선언하면, 운영체제는 다른 프로세스를 선택하여 cpu를 보내야 한다.
<- 비선점 CPU 스케줄링
3. 높은 우선 순위의 프로세스가 나타났을 때
높은 우선순위의 프로세스가 입출력을 마치고 준비상태로 전환되면, 운영체제는 현재 실행중인 프로세스를 보류하고, 더 높은
우선순위의 프로세스에게 CPU를 보낼 수 있다.
-> 선점 cpu 스케줄링
4. 주어진 CPU 실행시간이 초과되었을 때
현재 실행 중인 프로세스에게 허용된 최대 실행시간(타임 퀀텀, 타임 슬라이스)이 초과되었을때 CPU는 다른 프로세스를 선택하여 cpu를 보낼 수 있다.
-> 선점 cpu 스케줄링
비선점(Non-preemption) cpu 스케줄링 : cpu가 실행하고 있다가 다른 프로세스로 가는 데, 그 이유가 프로세스 자체적으로 cpu가 필요 없어져서
강제로 뺏은 게 아니다.
선점(Preemption : 빼앗다.) cpu 스케줄링 : 자율적 CPU 반납 + 타율적 cpu 반납, 더 실행 할 수 있는 데 높은 우선순위나 실행 시간이 초과되는 경우와
같은 환경에서 강제로 뺏은 경우.
용어 : 계산 위주 성향(CPU Bounds) 프로세스, 입 출력 성향(I/O Bounds) 프로세스
비선점형 CPU 스케줄링 : 입출력이나 종료 등에 의한 자율적 CPU 반납만 실행 - 초창기
선점형 CPU 스케줄링 : 더 높은 우선순위나 프로세스나 시간 초과 등에 의한 타율적(강제적) CPU 반납도 시행 - 시분할
```
## CPU 스케줄링 전략들
```
선입 선처리(FCFS : First-Come First-Served) 스케줄링 : 평균 대기 시간 : (0 + 30 + 33) / 3 = 21 평균 응답 시간 : (30 + 33 + 39) / 3 = 34
호위 효과(Convoy Effect) 먼저 온 거를 먼저 처리하게 될 때 먼저 온 것이 많은 시간을 할애하면 그 뒤의 작은 작업은 손해
FCFS(First-Come First-Served) : 비선점형 CPU 스케줄링으로 호위 효과에 의해 입출력 장치나 CPU 이용률이 낮아질 수 있다.
CPU 버스트 시간 반응시간(CPU를 사용하는 주기)
```
## 최단 작업 우선(SJF : Shortest Job First) 스케줄링
```
SPN(Shortest Process Next)
CPU 버스트가 가장 짧은 프로세스에게 cpu를 먼저 할당하는 전략 평균 대기 시간: (0 + 3 + 9) / 3 = 4, 평균 응답 시간 = (3 + 9 + 39) / 3 = 17
비선점형 cpu 스케줄링으로, 평균 대기 시간 및 평균 응답 시간은 매우 우사하지만, CPU 혹은 입출력장치의 이용률 저하 현상과 큰 프로세스 에 대한 cpu 할당이
지연되는 기아(Starvation) 현상이 나타날 수 있다.
기아(Starvation) 현상 : CPU 버스트 시간이 긴 프로세스는 짧은 프로세스보다 서비스를 못 받고 지연되는 상황이 계속된다.
```
## 최단 잔여 시간 우선(SRTF: Shortest Remaining Time First) 스케줄링
```
SRTF : SJF의 선점형 스케줄링 전략으로, 평균 대기 시간 및 평균 응답 시간을 더욱 개선하고 cpu나 입출력장치의 이용률 저하 현상을 억제하지만, 큰 프로세스의 기아 현상은 더욱 악화시킬 수 있다.
```
## 최고 응답률 우선(HRRF: Highest Response Ratio First) 스케줄링
```
SJF나 SRTF 스케줄링의 기아 현상을 예방하기 위하여, CPU 버스트 시간 대비 상대적 응답 시간인
응답률이 높은 프로세스를 먼저 처리한다.
```
## 라운드로빈(RR: Round Robin) 스케줄링
```
대화식 시스템에 적합하고, 타임 퀀텀의 크기가 목표 성능 지표에 영향을 미친다.
```
## 다단계 큐(MQ: Multi-level Queue) 스케줄링
```
MQ는 프로세스 특성별로 준비 큐 독립적으로 운영하고, 각 준비 큐에는 서로 다른 우선 순위와 타임퀀텀을
설정한다. 각 준비 큐 내에서는 fcfs, rr 등 다른 스케줄링 전략을 적용한다.
```
## 다단계 피드백 큐(MFQ: Multi-level Feedback Queue) 스케줄링
```
프로세스 실행이 타임 퀀텀을 소진하지 못하면 입출력 성향 쪽으로 높은 우선순위와 짧은 퀀텀을 부여
타임 퀀텀을 모두 소진하면 계산 성향 쪽으로 낮은 우선 순위와 긴 타임 퀀텀을 부여합니다.
```
## 병행처리와 병렬처리, 그리고 경쟁상황
```
다중 프로그래밍 환경에서는 여러 프로세스들이 동일 자원(동일 변수)에 접근하기 위해 경쟁한다.
접근 경쟁 상황은 병행 처리와 병렬 처리 형태의 두 가지 형태로 나타난다.
```
## 병행처리와 경쟁상황
```
병행 처리(Concurrent Processing) : 하나의 CPU가 여러 개의 프로세스를 조금씩 빠른 속도로 번갈아 가면서 처리하는 형태
병행처리 경쟁 상황(Race Condition) : 공유 변수가 포함된 수식 계산을 완전히 마치지 못한 상태에서 CPU 스케줄링이 일어날 때 발생
```
## 병렬처리와 경쟁상황
```
병렬 처리(Parallel Processing) : 두 개 이상의 CPU가 여러 프로세스들을 분담하여 독립적으로 동시에 처리하는 형태
병렬 처리와 경쟁 상황 : 병렬 처리 환경에서 공유 변수를 참조하는 프로세스들이 처리될 때 발생
```
## 임계영역과 상호배제
```
임계영역(Critical Section) : 프로그램에서 경쟁상황이 일어날 수 있는 부분
상호배제(Mutual Exclusion) : 관련된 임계구역에는 오직 하나의 프로세스만이 진입하게 하는 것
상호배제 장치의 요건 : 계속진행, 상호배제, 대기한정
상호배제 장치는 소프트웨어와 하드웨어 등 두 가지 방법으로 구현할 수 있음
```
## 미완성 소프트웨어 상호배제 시도들
```
공통 깃발 체크 방법 : 기계 명령어 수준의 경쟁상황으로 인해 임계영역을 보호하지 못한다.
```
## 자기 깃발 표시 방법
```
자기 깃발 표시 방법 : 역시 기계 명령어 수준의 경쟁상황으로 인해 임계영역을 보호하지 못하거나, 아예 진입이 불가능함
```
## 차례 지키기 방법
```
차례 지키기 방법 : 상호배제 자체는 이루어지지만, 임계영역이 비어있어도 진입할 수 없는 경우가 발생한다. (계속진행을 만족하지 못한다, 대기한정 역시도 충족 X)
```
## 교착 상태(Deadlocks)
```
고장난 자물쇠 -> 나가지도 못하고, 나오지도 못함
진퇴양난 -> 영원히 기다리는 상황
주요 원인 : 고장이나 기타 이유로 인한 자원의 부족
컴퓨터 자원의 유형 : 하드웨어 자원(cpu, 메모리)과 소프트웨어(세마포) 자원
선점 가능한 자원과 선점 불가능한 자원(메모리 관점)
공유 가능 자원(사운드 카드)과 배타적 사용 자원
```
## 컴퓨터의 자원 관리 모델
```
요청 -> 사용 -> 반납
프로세스들은 운영체제에게 필요한 자원을 요청(malloc(), 객체 생정자 new(메모리 공간을 할당))
자원 요청은 시스템 콜을 사용하여 이루어짐
유닉스/리눅스의 대표적인 자원 요청 시스템 콜은 open(), 자원 반납 시스템 콜은 close(), free(), java는 다른 주소 를 가리키는 순간 원래 있던 자원(dangling 객체, garbage)을 자동적으로 반납함
205쪽 두 프로세스 간 교착 상태 발생하는 이유 : p1 a.txt, p2 b.txt 처리하다가 p1이 a.txt 쓰다가 운영체제에게 b.txt 쓰려고할 때 p2가 쓰고 있기 때문에 p1은 b.txt를 달라고 계속 요청하는 상황(교착상태)
p2는 b.txt 쓰다가 운영체제에게 a.txt 쓰려고 요청할 때 p1이 쓰고 있기 때문에 p2는 a.txt를 달라고 계속 요청하는 상황(교착상태)
```
## 교착 상태(Deadlock)
```
교착 상태의 필요조건 (조건필수) 공통적으로 나타나는 4가지 특징들
4가지 특징이 있으면 교착상태가 될수도 안될 수도 있다.
1. 자원의 배타적 사용(Mutual Exclusion) : 자원 공유 x 독점
2. 자원의 점유 대기(Hold & Wait) : 자원을 가지고 있으면서 또 요청을 한다.
3. 자원 비선점(No Preemption)
4. 자원에 대한 환형 대기(Circular Wait) : 자원을 기다리는 관계가 환형을 이룬다.
```
## 교착 상태 예방(Prevention)
```
교착 상태 예방(Prevention) : 교착 상태가 일어나지 않게 하는 사전적인 처리
1. 자원의 배타적 사용 조건 제거(X) : 컴퓨터 자원의 대부분은 배타적으로 사용되어야 함<- 도입 불가
2. 자원의 점유 대기 조건 제거 : 사용될 자원 전체를 한꺼번에 할당할 수 있을때까지 기다림
여러 종류의 자원이 필요한 프로세스의 기아 상태 가능성
자원을 미리 확보함으로써 활용도 저하 <- 도입 곤란
3. 자원의 비선점 조건 제거
자원이 부족하면 이지 점유 중인 자원을 강제 회수
롤 백(진행하다가 중간에 자원을 뺏아가는 비용이 크다.) 등 큰 비용 방안 <- 도입 곤란
4. 자원에 대한 환형 대기 조건 제거
모든 자원에 일련 번호를 부여하고, 자원의 카테고리에서 자원을 쓸려면 내부적으로 순서에 관계없이 일련 번호 순서대로 자원을 확보하고 진행한다. 자원 점유 순서를 우선 확보한다. 현실적으로 적용할 수 있는 방안이다.
```
## 교착 상태 회피(Avoidance) 자원 요청할때 그때그때마다
```
자원을 할당할 때마다 그때그때 회피하는 방법)
안전(Safe) 상태와 불안전(Unsafe)
안전 상태 : 자원 할당이 이루어지더라도 교착 상태가 결코 일어나지 않는 상태
현재 남은 자원이 부족하더라도 점유 중인 프로세스 종료로 자원이 반납되어 모든 자원 할당 요구를 만족하는 시나리오가 존재하면 완전 상태
불안전 상태 : 자원 할당이 이루어진 후, 이후의 모든 자원 할당을 만족시킬 시나리오가 존재하지 않는 경우
자원 할당 그래프의 예약 간선
현재 요청된 자원을 할당했다는 가정 하의 자원 할당 그래프
예약 간섭이 포함된 자원 할당 그래프로부터 안정 상태 여부 판별
안정 상태가 아니라면 자원 요청 보류
Dijstra 은행가 Banker's algorithm
현황 관리표로 자원에 대한 잠재 수요 및 재고 현황으로부터 안전 상태 판별
주고 난 후에 상황 파악 재고가 없으면 다 불만족이면 거절을 해야한다.
p0가 2개 요청해서 만족이 된 경우에는 교착상태가 아니므로 허용해야 한다.
p0는 언젠가 프로세스가 끝나고 현재 할당량 3개를 p1에게 줘서 p1이 끝날 수 있고
p1이 끝나고 방출된 p2에게 주면 되니까 운영체제가 기다리게 한다.(영원히는 x)
```
```
2023-05-18일까지 과제
다음과 같이 과제를 제출하기 바랍니다.
- 과제 내용 : 교과서 160쪽 prog_06_12와 185쪽 prog_06_62를 분석 및 실험한 결과를 보고서로 작성하여 제출
* 경쟁 상황 및 상호 배제 실험입니다.
* 교과서 소스를 수정하거나 삽입한 부분을 첨부 파일에 파란색으로 표시하였으니 이를 반영하기 바랍니다.
* 스레드 관련 헤더 파일은 algo.gwnu.ac.kr의 유닉스 운영체제 기준이므로, 다른 유닉스나 리눅스에서는 잘 살펴서 수정하기 바랍니다.
* 실행 파일을 여러 번 실행하여 결과를 관찰합니다.
- 제 출 일 : 5월 18일 목요일 수업 시간
```
## 단일 프로그래밍 메모리 관리
```
특징
메모리에 오직 하나의 프로세스만 존재
굳이 논리주소와 물리주소를 분리하거나 이곳저곳에 분산 적재할 필요성 없음
메모리의 사용자 영역에 연속 할당
다만, 프로그램의 크기가 메모리 용량을 초과할 경우에 대한 처리 방안 필요
운영체제 보호
사용자 프로세스가 운영체제 영역 침범 방지
경계 레지스터에 경계 값을 설정하고, 주소가 이 범위를 벗어나면 예외 발생으로 프로세스 중단시킴
오버레이(중첩, Overlay)
프로그램의 크기가 메모리 용량을 초과하는 경우 처리 방법
프로그램을 여러 개의 작은 부분으로 분리
분리된 부분을 필요할 때마다 동일 장소에 교체하여 적재(동적 적재, Dynamic Loading)
개발자의 설계에 따라 운영체제에 요청하여 삭제
즉 프로그램의 분리 및 운영은 소프트웨어 개발자의 설계에 의해
고정 분할과 가변 분할
고정 분할 : 메모리를 몇 개의 부분으로 고정 분할하여 프로세스를 적재
목적 코드들은 특정 분할을 목표로 작성되거나 임의의 분할에 적재될 수 있도록 재배치 가능(Relocation)하게 작성되어야 함
다중 프로그래밍(Multi-Programming) 환경에서는 어떤 형태로든 메모리를 분할하여 할당해야함
메모리를 분할하여, 프로세스를 하나의 분할에 연속적으로 적재하는 방법으로 고정 분할과 가변 분할이 있음
운영체제 및 다른 프로세스 보호
다중 프로그래밍 환경에서는 운영체제 뿐만 아니라 프로세스들끼리도 보호가 필요함
각 프로세스별로 자신의 영역을 벗어나 참조하는 것을 방지하기 위해서는 주소의 상하한을 설정하여 관리해야 함
즉 상하한 경계 레지스터를 활용함
고정 분할의 크기
프로세스의 크기와 분할의 크기가 정확하게 일치하지 않아 메모리 일부가 낭비되는 내부 단편화(빈공간이 생겨서 남는 메모리가 남는)문제 발생
내부 단편화를 최소화하기 위해서는 분할의 크기를 가급적 다양하게 함 (크기를 다양하게 해서 크기가 일치하는 쪽으로 주면 해소됨)
분할을 너무 많게 하면 각 분할의 크기가 작아질 수 밖에 없음
분할을 너무 크게 하면 분할의 수가 적어져서 다중 프로그래밍 정도(적재할 수 있는 프로세스의 수)가 낮아짐
할당된 내에서 못쓰는 공간이 발생한다.
가변 분할
메모리 전체를 풀로 보고 필요할 때마다 정확한 크기로 분할하여 할당
프로세스들이 분할된 할당 하나에 연속적으로 적재된다는 점은 고정 분할과 동일
목적 코드들(프로그램들)은 (비어있는 공간이 어디에 있고 언제 빌지)어느 주소에 적재될 지 예측할 수 없으므로 반드시 재배치가 가능해야 함
할당과 반납이 반복되면서 사용도가 극히 작은 빈 공간(홀 Hole)이 존재하는 외부 단편화 문제 대두
메모리 군데 군데 작은 자투리로 비어있는 쓸모없는 공간이 발생할 수 있다.
(병합과 통합 절차 필요)
독립적으로 할당이 가능한 곳인데 못 쓰는 현상 외부에 독립적으로 낭비되는 공간
가변 분할의 병합, 통합
인접한 빈 분할들의 병합(Coalescing)
할당되었던 분할이 반납되어 빈 분할이 되었을 때, 앞이나 뒤에 인접한 빈 분할이 존재하면 이들을 병합하여 하나의 큰 빈 분할로 관리
외부 단편화 문제를 최소화시킬 수 있음
분산된 빈 분할들의 통합(Compaction)
여기저기 흩어져 있는 작은 분할들을 이동시켜서 하나의 큰 분할로 관리
빈 분할 뿐만 아니라, 사용 중인 분할들도 이동이 불가피
모든 프로세스들에 대한 실행을 중단하고 재배치 작업이 필요함
사용하는 메모리를 위로 옮기거나 아래로 옮기는 등 이동해서 빈 공간을 합칠 수 있다.
```
## 가변 분할의 할당 정책
```
최적 적합(Best-fit) 할당 : 가장 가까운 거 가장 남는 공간이 적은 것
최악 적합(Worst-fit) 할당 : 넣을 수 있으면서 가장 남는 공간이 많은 것
최초 적합(First-fit) 할당 : 검색하는것도 시간 걸리니까 바로 넣음
순차 적합(Next-fit) 할당 : 한 번 검색 한 다음에는 아까 할당한 것 다음부터 검색을 하는 방식 메모리 전체적으로 골고루 영향을 준다. 메모리 활용도가 고른 분포를 가지게 될 것이다.
```
## 비연속 할당
```
메모리 여러 군데를 합쳐서 총 사이즈만 맞춰주면 되는 할당
페이징, 세그멘테이션
프로그램을 원래 모양 그래도 적재하지 않음
프로그램을 여러 개의 논리적 조각으로 분리하여 메모리의 이곳저곳에 분산하여 적재
비연속 적재(할당) 정책
프로그램의 일부만 적재하는 방버(가상 메모리)으로의 발전이 용이
페이징과 세그멘테이션은 프로그램을 논리적으로 나누는 방법의 차이
페이징
개념 : 프로그램을 일정한 크기의 작은 조각으로 분리하고, 각각의 조각을 페이지(Page)라 함
페이지의 크기는 운영체제 시스템에 따라 512 ~ 8k 바이트
메모리 또한 페이지와 동일한 크기로 분할하여 각 분할을 페이지 프레임(Page Frame)이라 함
프로그램의 페이지를 임의의 빈 페이지 프레임에 적재하고, 그 정보를 페이지 테이블로 관리
페이지 테이블의 위치는 PTBR(Page Table Base Register)에 설정
프로그램의 동일한 조각 페이지
페이지와 동일한 크기의 메모리 조각은 페이지 프레임
방법론 적재할 때 프로그램을 적재할 때 비어있는 페이지 프레임의 물리 메모리로 적재
-> 뒤죽박죽이니까 비연속 할당임
페이지랑 프레임을 매핑하는 것을 페이지 테이블로 관리
2번 번호를 가진 페이지는 몇번 프레임에 매핑이 되는지를 페이지 테이블로 관리한다.
페이지 매핑 테이블
논리주소 -> 매핑
0 ~ 999 0번페이지
1000 ~ 1999 1번페이지
2000 ~ 2999 2번페이지
만약에 주소가 2475다 그럼 맨 앞자리 2를 보고 페이지 테이블을 보고 7에 매핑되네
2475를 7475로 바꿔주고 프레임 7번 주소를 본다.
논리주소와 물리주소는 다르게 된다. 중간에 페이지 테이블에서 매칭되는 숫자로 주소를 변환하기 때문
남은 짜투리는 어떻게 해석되는가 2번 페이지에서 475만큼 떨어지는 공간을 의미한다. <- 이 개념을 offset이라고 한다. 또는 Displacement(변위) 즉 2번 페이지 시작점으로 부터의 거리가 475를 의미한다. 십진수로 해석한 것을
2진수에서 offset 계산
논리 주소의 물리 주소 변환
CPU가 올린 논리 주소(기계 명령어 내의 피연산자 주소)는 MMU에 의해 대응되는 물리 주소로 변환됨
논리 주소는 프로그램의 페이지 번호와 그 페이지 내에서의 거리로 구성됨
즉 MMU는 논리 주소의 페이지 번호를 해당 페이지가 적재된 페이지 프레임 번호로 대치하면 됨
1K = 10bit가 짜투리 부분
2진수를 십진수로 변환하면 논리주소는 11277 = 1024 * 11 + 13
페이징을 위한 MMU 메모리 관리 장치(Memory Management Unit)구조
MMU의 절차에 따라 논리 주소를 물리 주소로 변환함
페이지 크기가 2의 N이므로 페이지 번호, 페이지 내 거리, 페이지 프레임 번호를 다루기가 용이
성능 개선을 위한 페이지 MMU 구조
페이징의 가장 큰 단점은 메모리를 접근할 때마다 페이지 테이블을 참조해야 함
즉 두 번의 메모리 참조가 일어남 <- 성능이 절반으로 저하됨
이를 해결하기 위해, 한번 참조된 페이지 테이블 내용을 연관 메모리(Associative Memory) 소자로 구성된 TLB(Translation Lookaside Buffer)미리 보는 버퍼에 캐시시킴
TLB 검색에서 실패한 경우에만 페이지 테이블을 참조
TLB에서 성공한 비율을 적중률(Hit Ratio)라고하는데, 적은 용량으로 90%이상의 효과를 얻을 수 있음
메모리에 접근할 때마다 TLB에서 성공하면 속도가 빠른 것 페이지 테이블을 참조하지 않고 TLB에서 참조하면 <- 적중률 Hit ratio라고 한다.
TLB (캐시 메모리에서 접근할 것인가) 페이지 테이블을 참조할 것인가
TLB에서 참조하는 것이 더 빠르다. HIT RATIO 가 높다.
페이징 시스템
장점
마지막 페이지에서의 내부 단편화 외에 단편화에 따른 메모리 낭비가 없음
페이지 크기가 클수록 마지막 페이지의 내부 단편화는 커짐
논리 주소와 물리 주소가 분리되므로, 모든 프로세스가 논리 주소 공간을 공유할 수 있고,
재배치가 불필요함
예를 들어 모든 프로그램의 목적 코드가 0번지부터 시작하더라도 대응되는 물리 주소는 다름으로 전혀 문제가 없음
단점
페이지 테이블을 위한 메모리 낭비가 존재함
페이지 크기가 작으면 페이지 테이블 엔트리 수도 늘어나므로 페이지 테이블 크기도 증가함
논리 주소의 물리 주소 변환을 위한 성능 저하가 존재함
페이지의 보호와 공유
페이지 테이블에 보호 비트(읽기, 쓰기, 실행 등)을 설정하여 해당 페이지 보호
여러 페이지 테이블에서 동일한 페이지 프레임을 참조함으로써 여러 프로세스가 페이지 공유 가능
즉 페이지 보호와 공유가 매우 용이함
기계명령어 Text, 변수 Data, 지역 변수 Stack영역
프로그램을 여러개 띄우면 기계명령어는 공유 즉 프레임 위치를 공유
데이터 부분만 프레임 위치를 다르게 설정하면 되니까 공유가 쉽다.
공유 메모리 보안모드도 기계 명령어는 읽기와 실행만 가능하도록 쓰기는 불가능하도록하게 하고
기계명령어가 fetch될 때 즉 실행될 때 페이지 테이블에 저장하도록 하게 해서 보안성을 높임
세그멘테이션
전체적인 할당 및 관리 방식은 페이징과 동일
다만, 프로그램을 규격화된 페이지로 나누지 않고, 프로그램 이미지의 논리적인 특성에 따라 큰 덩어리 즉, 세그먼트 단위로 분리
대표적인 세그먼트로 텍스트(Text), 데이터(전역 변수 부분), 스택(지역 변수 및 제어 스택 부분)등이 있다.
각 세그먼트의 크기는 매우 다름
따라서, 세그먼트 테이블에는 해당 세그먼트가 적재된 시작 주소와 크기를 명시
세그먼트 번호에 따라서 MMU가 세그먼트 테이블에서 시작과 크기를 정해서 매핑하게 함
페이징과 방식은 동일
세그먼트의 보호 및 공유
기본적인 방법은 페이징과 동일
즉, 세그먼트 테이블에 보호 비트를 설정할 수 있고, 할당된 세그먼트를 여러 프로세스가 공유 가능
세그먼트는 큰 덩어리를 따로따로 떼어서 적재한다.
세그먼트의 장점
페이지화된 세그먼트(Segementation with Paging)
페이징의 단점은 적재 단위가 너무 작아 보호와 공유 관리를 위한 부담이 있음
세그먼테이션의 단점은 가변 분할 방식의 메모리 할당 정책으로 외부 단편화 발생
페이지화된 세그먼테이션은 분리된 각 세그먼트를 페이지 단위로 재구성하여 할당하고 적재함
페이징과 세그먼테이션의 장점만을 취한 방법
논리 주소에서 세그먼트 번호와 페이지 번호를 도출하고,
세그먼트 테이블 및 페이지 테이블을 참조하여 물리 주소로 변환
세그먼트 테이블 참조 -> 그 세그먼트에 맞는 페이지 테이블을 참조 -> 성능 저하(오버헤드)
그것은 심각하지 않다. 변환하는 부분은 연관메모리(Associate Memory) 병렬로 메모리 매핑 (캐싱)
한 번 참조된 부분은 locality PLB에 의해서 성능 저항이 페이징에 비해 떨어지는 게 없다.
```
## 가상 메모리(Virtual Memory)
```
사용자들이 실제 물리 메모리보다 훨씬 크게 사용하는 메모리
프로그램 전체가 적재되어야 한다는 전체 하에서는 불가능
프로그램 일부만 적재하려면, 프로그램의 분리 적재가 불가피
페이징 기법에 기반
프로그램의 적재되지 않은 부분은 디스크에 존재
디스크와 메모리를 오가며 필요한 부분만이 적재됨(Swapping, 스와핑)
```
## 요구 페이징(Demand Paging)
```
페이징 기법의 확장으로, 페이지에 대한 참조가 일어날 때 실시간으로 적재
페이지에 대한 참조 인식 및 적재는 인터럽트 매커니즘을 이용
페이지 테이블에 해당 페이지의 적재 여부를 표시하고, 만약 적재되지 않은 페이지에 대한 참조가
일어나면 인터럽트(페이지 부재 트립, Page Fault Trap)가 발생
해당 인터럽트 핸들러에서 페이지 적재(Swap in)
참조가 일어나지 않은 페이지는 디스크에 저장하고(Swap out), 할당되었던 페이지 프레임 회수
페이지 부재 트랩 처리 과정(ISR: 인터럽트 서비스 루틴)
페이지 참조 시 부재 페이지일 경우 발생하는 인터럽트의 하나 (인터럽트 루틴은 운영체제 내에서)
부재가 일어난 부분을 읽어들어야 한다.
페이지 프레임을 할당하고, 그 곳에 디스크에 존재하는 해당 페이지를 입력
부재 페이지 처리부담으로 인한 성능 저하는 불가
```
## 페이지 교체(Page Replacement)
```'
최적 페이지 교체 (OPT)
개념 : 교체 대상 페이지로 이래에 사용되지 않거나 가장 오랫동안 사용되지 않을 페이지를 선택
MIN(Minimal) 페이지 교체라고도 함
미래를 예측하는 일은 불가능하기 때문에 구현 불가 <- 비교 대상 방법으로서의 의미
FIFO : 적제된 지 오래된 페이지를 선택하여 교체
페이지별 적재 시간을 관리할 장치가 필요(큐 혹은 타임 스탬프)
벨러디(Belady's anomaly) 모순 현상이 나타날 수 있음,
NUR(Not Used Recently) : 근래 사용되지 않는 페이지를 선택하는 방법으로 '가장'이란 제한을 두지 않음
즉, 가급적 근래 사용되지 않은 페이지를 선택하여 교체함
근사 LRU(LRU Approximation)페이지 교체라고 부르기도 함
기본 NUR 페이지 교체
-> 페이지 별로 참조 여부를 표시하는 참조 비트(Reference Bit)를 관리
참조 비트를 주기적으로 청소
일정 기간 동안 참조된 페이지와 참조되지 않은 페이지로 구분할 수 있음
이중 참조 되지 않은 페이지 중에서 희생양(랜덤하게)을 선택함
부가적 참조 비트(Additional Reference Bits) 사용 NUR 페이지 교체
참조 비트를 여러 개 두어 보다 정교한 참조 패턴을 관리
참조 회수 카운트 비트 사용
이를테면 8개의 참조 비트를 두고, 시간대 별 참조 여부를 SHIFT로 표시
00001111 : 초반 4번의 참조를 의미
11110000 : 최근 4번의 참조를 의미
결과를 8비트 정수로 보아 가장 적은 수의 페이지를 선택하여 교체
변경과 참조 비트 사용 (R : 참조비트, C : 변경비트)
페이지 하나 당 비트 두 개를 가지고 보호할 것인지 희생한 것인지를 결정
변경 비트 : 적재된 후 변경이 있었는 지 표시 (디스크에서 올라온 페이지의 정보와 디스크의 정보를 비교해서
페이지가 변경이 일어나면 디스크에 쓰기 작업이 필요한데 메모리에 페이지가 적재된 후에 변경이 없다면
디스크에 쓰기 작업이 필요 없다.) 변경이 있는 페이지를 희생양으로 삼는 것이 좋다.
참조 비트 : 지난 일정 기간 동안 참조가 있었는지 표시
변경 및 참조 모두 없는 경우(00), 단순 참조만 있는 경우(10), 변경만 된 경우(10)
참조 및 변경 모두 있는 경우(11)로 분류하고, 그 결과를 2비트 정수로 보아 가장 적은 수를
가진 페이지를 선택하여 교체
희생양으로 삼아야 할 순위 (참조가 있으면 쫒아내면 안됨)
참조와 변경이 없는 00 이 1순위
참조없고 변경이 있는 01 이 2순위
참조있고 변경이 없는 10 이 3순위
참조와 변경이 있는 11 이 4순위 (보호)
변경이 일어나는 경우 왼쪽으로 1 쉬프트
참조가 일어나면 최상단비트를 1로, 참조가 안 일어나면 0 삽입
앞쪽에 1인경우 최근에 참조가 많이 일어난 경우 -> 쫒아내면 안됨
뒤쪽에 1인경우 옛날에 참조가 일어난 경우 -> 쫒아낸다.
수가 크면 앞쪽 높은자리 수가 1인 경우가 많다 최근에 참조가 일어났다 -> 보호해야 한다.
수가 작다면 뒤쪽에 낮은자리 수가 1인 경우가 많다. 옛날에 참조가 일어났다. -> 희생해야 한다.
2진수로 바꾸면 큰 수면 보호, 작으면 희생
2차 기회(Second Chance) 페이지 교체 (시계 페이지 교체)
FIFO 교체 기법에서, 교체 대상인 페이지(가장 오래된 페이지)에 대한 참조가 있었다면 메모리에 머무를 수 있는
기회를 최소한 한번 더 부여
즉, 적재된 지 오래되었다고 해서 최근 한창 참조 중인 페이지를 교체하는 경우를 예방
참조가 계속 이루어지면 메모리에 머무를 수 있는 기회가 계속 주어짐
다만, 모든 페이지에 대한 참조가 일어났다면 해당 페이지를 선택하여 교체
LFU(Least Frequently Used)와 MFU(Most Frequently Used)
전체적인 참조 횟수를 기반으로 희생 페이지 선택(계수 기반 페이지 교체)
LFU는 참조 횟수가 가장 적은 페이지를 선택 쓸모가 없는거
MFU는 참조 횟수가 가장 많은 페이지를 참조 쓸만큼 써서 쓸모가 없어졌다.
참조 횟수에 대한 정확한 카운팅이 어려움
최근 운영체제는 RC 변경, 참조 비트를 주로 사용한다.
비트의 수에 대한 부담도 줄어들기 때문.
```
## 페이지 버퍼링
```
페이지 버퍼링
페이지 교체 시점이 되어서야 희생 페이지를 선택하고 교체 작업을 진행하면 해당 프로세스의
진행 시간이 그만큼 지연됨 페이지의 부재를 해결할 수 있음
평상 시 몇 개의 가용 (비어있는) 페이지 프레임을 미리 확보해 두면(풀, POOL), 페이지 교체 시간을 단축시킬 수 있음
풀에서 할당된 수 만큼의 페이지 프레임은 사후에 희생 페이지를 선택하여 보충 (디스크 i/o가 한가할 때)
페이지 클리닝(Page Cleaning)
적재된 이 후 변경이 이루어진 페이지(Dirty Page)를 미리 디스크 복사본과 일치시켜(쓰기 작업, Cleaning 작업)
풀로 관리하면, 페이지 교체 시 출력 작업이 불필요하여 페이지 교체시간을 크게 단축시킬 수 있음
페이지 재할당
페이지 풀에 관리 중인 페이지 프레임들이 어느 프로세스의 어느 페이지였는지를 관리
에 대한 적재가 필요할 때 그대로 할당할 수 있음
```
## 페이지 프레임 할당(Allocation of Page Frames)
```
페이지 프레임 할당 시 고려 사항
각 프로세스에게 얼마만큼의 페이지 프레임을 할당할 것인가
페이지 교체 시 희생 페이지를 어디서 구할 것인가?
최소 할당 페이지 프레임 수
기계 명령어(instruction) 구조 측면
기계 명령어 자체의 크기 : 대부분의 기계 명령어는 2바이트 이상이므로 이들이
두 페이지에 걸쳐 위치할 가능성이 높음 -> 최소한 두 페이지 적재 필요
피연산자의 최대 수
기계 명령어의 피연산자가 두 개인 경우, 이들 피연산자들이 서로 다른 페이지에
존재할 가능성이 있음 -> 최소 두 페이지 적재 필요
주소 지정 모드
간접 주소 모드는 메모리를 두 번 접근하여 최종 피연산자 값을 얻음
이 경우 직접 주소, 간접 주소가 서로 다른 페이지일 가능성이 있음
피연산자 별로 두 페이지 적재 필요
최소한 총 6페이지 이상이 적재되어야 함
성능 향상 측면
페이지 부재 처리는 상당한 처리 부담을 동반
할당 페이지 프레임이 절대적으로 부족하여 페이지 부재 빈도가 높아지는 상황에서는 어떠한
방법으로도 보완 불가능
즉, 페이지 부재 빈도가 적절한 범위를 벗어나지 않기 위해서는 최소한 페이지 프레임이 할당되어야 함
최소한의 페이지 프레임 수를 찾는 방법으로 작업 집합 및 페이지 부재
```
## 균등 할당과 비례 할당
```
균등 할당 : 시스템 전체의 메모리 크기를 고려하여 모든 프로세스에게 동일한 수의 페이지 프레임을 할당
비례 할당 : 프로그램의 전체 크기나 우선 순위 등 특정 지표를 기준으로 비례하여 할당
불필요한 페이지가 적재되지 않도록
```
## 지역 할당과 전역 할당
```
지역 할당
희생 페이지를 해당 프로세스 내에서 구함
이를테면 5개의 페이지 프레임이 할당된 프로세스에 페이지 교체가 필요하면
이미 할당된 5개의 페이지 중에서 희생 페이지를 선택
프로세스에게 할당되는 페이지 프레임 수가 일정하게 유지되므로 고정할당이라고도 함
전역 할당
교체할 페이지를 적재된 모든 페이지를 대상으로 하여 선택
프로세스에게 할당되는 페이지 프레임 수가 줄어들거나 늘어날 수 있으므로 가변 할당이라고도 함
다양한 요소를 고려할 수 있음
자신의 처리시간이 영향을 받아 예측성이 떨어짐
```
## 스래싱(Threashing)
```
스래싱 : 페이지 부재가 너무 자주 일어나, 프로세스의 실행 보다는 페이지 교체에 더 많은 시간을 보내는 현상
스레싱의 원인 : 다중 프로그래밍 정도(메모리에 올리는 프로그램의 수)가 너무 높아
프로세스에게 할당된 페이지 프레임 수가 너무 적음
-> 페이지 부재 빈도가 급격하게 높아짐 (너무 많은 프로그램을 메모리에 올리게 되면)
스레싱의 예방 : 각 프로세스가 필요로 하는 최소한 페이지 프레임을 할당
이를 위해서는 지역 할당 전략을 접목해야 함 <- 작업 집합과 페이지 부재 빈도 이론
```
## 작업 집합
```
어느 프로세스가 특정 시간 동안 참조한 페이지들의 집합
W(t, 델타t) : t~델타t ~ t 사이에 참조된 페이지들의 집합
시간 t를 기준으로 델타t 동안 참조된 페이지들의 집합
델타t동안 참조된 참조집합
```
## 파일 시스템
```
파일이나 폴더에 이름을 부여하여 사용자로 하여금 하드 디스크, USB, 메모리, CD-ROM, DVD 등과 같은
저장 장치의 복잡한 하드웨어 구조에 관계 없이 편리하게 관리할 수 있또록 변환해 주는 운영체제 기능
파일의 개념 : 종이 문서에 대응되는 컴퓨터 저장하는 문서의 저장단위
파일 시스템에서 이루어지는 관리 단위
파일의 속성들 : 파일 이름, 소유자, 보안 모드, 접근 시간, 파일 크기, 파일 공간
파일과 디렉터리(폴더)
운영체제는 파일들의 논리적 저장 체계를 디렉터리로 연결하여 구성
현재 어떤 파일들이 보관되어 있는 지를 디렉터리에 관리
즉, 디렉터리는 운영체제에 의해 관리되는 파일 정보를 보관하고 있는 특수 파일
따라서, 디렉터리의 내용은 운영체제 만이 수정하고 변경할 수 있음
다만, 디렉터리의 생성과 삭제는 사용자의 요청에 따라 운영체제에 의해 이루어짐
사용자는, 운영체제가 작성한 디렉터리의 내용으로부터 파일들을 검색
```
## 경로명과 파일연산
```
경로명 : 파일시스템 내에서 어느 파일을 유일하게 지칭하는 문자열연결
디렉터리 연결 체계 + 최정 파일 이름
절대 경로명 : 뿌리 디렉터리부터 열거되는 경로명, 디렉터리 연결이 이루어질수록 경로명이 길어짐
상대 경로명 : 현재 작업 중인 디렉터리부터 시작되는 경로명, 경로명이 짧아서 다루기가 용이
```
## 디렉터리 연산
```
디렉터리 연산 중, 개방과 읽기, 위치 조정 등은 파일과 동일한 연산을 사용한다.
디렉터리 내용에 대한 사용자의 직접적인 출력(쓰기 및 변경)은 불가능하고, 파일의 생성이나 삭제 시
운영체제가 자동적으로 해당 목록을 추가하거나 삭제함으로써 디렉터리의 관리를 대행해 준다.
디렉터리의 생성과 삭제는 유닉스-리눅스의 mkdir(), rmdir()의 예와 같이 파일 연산과 식별되는 시스템 콜로
이루어지고, 비어있지 않는 디렉터리는 삭제될 수 없다. 디렉터리를 생성하거나 삭제하기 위해 해당 시스템 콜을
호출하는 프로그램을 작성하는 사용자들의 번거로움을 덜어주기 위해 일반적인 운영체제 환경은 그런 시스템 콜을
대행해주는 명령어를 제공한다. 윈도우즈의 경우 마우스 우클릭 메뉴로 제공되고 리눅스, 유닉스의 경우
mkdir, rmdir 명령어로 제공된다.
```
## 파일 타입
```
저장 바이트의 인코딩에 따른 분류
텍스트(Text, 문자)파일
문자를 의미하는 코드들을 저장하는 파일
문자 코드는 아스키 코드, 유니 코드 등 다양함
문자 코드에 따라 2바이트가 문자 하나를 의미하는 경우가 있음
이진(바이너리, Binary) 파일
이미지, 동영상 등과 같이 문자 코드가 아닌 0, 1의 비트 패턴에 의미를 두는 내용을 저장하는 파일
한글이나 파워 포인트 등의 파일의 내용은 개념적으로 문서이지만 저장 내용에는 단순한 문자 코드 외에
글씨체, 레이아웃, 색깔, 폰트 등 다양한 부수 정보가 0/1의 비트패턴임
```
## 파일 내용 접근 방식에 따른 분류
```
순차 접근(Sequential Access) 파일
내용을 읽기 위해서는 반드시 처음부터 순차적으로 접근해야 하는 파일
파일을 저장하고 있는 미디어나(a), 파일 내용 구성상(b) 어쩔 수 없는 경우
예시 : 테이프, 불규칙한 규격의 레코드로 구성된 디스크
직접 접근(Direct Access) = 상대 접근(Relative Access) 파일
파일 저장 미디어나 내용의 구성상, 순서에 상관없이 파일 내 어떤 레코드라도 직접 접근할 수 있는 파일
임의 접근(Random Acess) 파일이라고 함
예시 : 규격화된 규격이고 저장된 내용이 규칙적인 레코드일 때
색인(Indexed Access) 접근 파일
index : 찾아보기, 첨자, 색인
예시 : 색인파일(순차 접근) -> 마스터파일(직접 접근)
```
## 디렉터리 구조
```
1단계 디렉터리
시스템 전체적으로 디렉터리가 단 하나밖에 없는 경우
관리되는 모든 파일들의 이름이 유일하게 식별되어야 함
파일 이름이 길어지고 검색이 어려워 짐
2단계 디렉터리
사용자 목록을 관리하는 디렉터리와 사용자별 파일 관리 디렉터리로 구성
사용자별로 파일 이름이 같아도 무방함
각 사용자는 로그인 시 자동으로 자신의 디렉터리에 연결
계층(트리, tree) 디렉터리
디렉터리 연결 깊이가 3 이상으로 구성
디렉터리의 자유로운 확장/축소 가능(운영체제는 디렉터리의 생성/삭제 서비스 제공)
파일 시스템 내 모든 디렉터리와 파일들은 경로명으로 유일하게 식별함
최상위 디렉터리를 뿌리(루트, root) 디렉터리라 함
디스크를 초기화(포맷)하면 최초에 뿌리 디렉터리만 생성됨
비순환 그래프(Acyclic Graph) 디렉터리
파일/디렉터리 접근 경로를 여러 개 설정 가능
장점 : 경로명을 단순화시킬 수 있음
예 : 윈도우즈의 바로가기, 유닉스/리눅스의 심볼릭(Symbolic, Soft)링크, 하드(Hard) 링크
```
## 보안과 파일 보호(File Protection)
```
정보 보안의 목적
비밀성
무결성
가용성
정보 보안 서비스
인증
접근 제어
데이터 기밀
데이터 무결성
부인 봉쇄
정보 보안 매커니즘(방법, 수단)
암호화 매커니즘(Encryption Mechanism)
대칭키, 비대칭키 RSA 알고리즘
접근 통제 행렬(Access Control Matrix)
접근 주체(사용자)와 접근 객체(파일)을 행과 열에 나열하여 교차 지점에 접근 권한을 설정
이 방법의 단점은 비어 있는 교차 지점이 많아 공간을 낭비
접근 통제 리스트(Access Control List)
접근 객체(파일)별로 접근 권한이 있는 사용자를 리스트 형태로 관리
접근 통제 행렬의 단점을 보완하고 있으나, 공유 파일 등에는 모든 사용자를 나열해야 하므로
여전히 비 현실적
이를 해결하기 위해 대부분의 상용 운영체제는 접근주체를 '파일 소유지', '소유자와의 동일 그룹'
'소유자와 관계없는 제 3자'등과 같이 간소화시켜서 적용
유닉스/ 리눅스의 경우 모든 파일에 rwx 즉 총 9비트를 사용하여 사용자 별로 접근권한을 부여
암호에 의한 파일보호는 파일마다 암호를 설정하여 접근 시 암호를 확인하도록 한다.
접근 통제 행렬(Access Control Matrix)은 모든 파일과 사용자 사이의 접근 권한 관계를 테이블 형로 표시하므로
그 용량이 매우 크다.
접근 통제 리스트(ACL)는 파일별로 접근 권한이 있는 사용자들만을 리스트로 표시하여 접근 행렬의 단점을 보완한다.
디스크 공간 구성
마스터 블록(Master Block) : 512Byte
물리 디스크 전체에 관한 정보 수록
전형적으로, 디스크를 나누어 독립된 파일 시스템을 구축하기 위한 파티션 정보 기록
보통 물리 디스크의 맨 첫 섹터에 위치
부트 블록(Boot Blcok)
파티션의 맨 첫 섹터에 위치
해당 파티션에 설치된 운영체제의 부트 프로그램
IPL(Initial Program Loader)라고도 함
수퍼 블록(Super Block)
파티션의 두 번째에 위치
파일 시스템을 관리하기 위한 정보 기록(비어있는 블록들의 정보 등)
디렉터리 블록(Directory Block)
디렉터리 용으로 사용될 블록들
데이터 블록(Data Block)
파일의 내용 기록에 사용될 블록들
```