Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/musyoku/variational-autoencoder
Chainer implementation of Variational AutoEncoder (VAE) M1 / M2 / M1+M2
https://github.com/musyoku/variational-autoencoder
Last synced: 2 months ago
JSON representation
Chainer implementation of Variational AutoEncoder (VAE) M1 / M2 / M1+M2
- Host: GitHub
- URL: https://github.com/musyoku/variational-autoencoder
- Owner: musyoku
- Created: 2016-04-11T14:52:19.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2016-08-10T16:42:32.000Z (over 8 years ago)
- Last Synced: 2024-08-02T12:21:59.365Z (5 months ago)
- Language: Python
- Homepage:
- Size: 161 KB
- Stars: 23
- Watchers: 1
- Forks: 5
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## Semi-Supervised Learning with Deep Generative Models
Chainer implementation of Variational AutoEncoder(VAE) model M1, M2, M1+M2
[この記事](http://musyoku.github.io/2016/07/02/semi-supervised-learning-with-deep-generative-models/)で実装したコードです。
### Requirements
- Chainer 1.8+
- sklearn
To visualize results, you need
- matplotlib.patches
- PIL
- pandas
#### Download MNIST
run `mnist-tools.py` to download and extract MNIST.
#### How to label my own dataset?
You can provide label information by filename.
format:
`{label_id}_{unique_filename}.{extension}`
regex:
`([0-9]+)_.+\.(bmp|png|jpg)`
e.g. MNIST

## M1
#### Parameters
| params | value |
|:-----------|------------:|
| OS | Windows 7 |
| GPU | GeForce GTX 970M |
| ndim_z | 2 |
| encoder_apply_dropout | False |
| decoder_apply_dropout | False |
| encoder_apply_batchnorm | True |
| decoder_apply_batchnorm | True |
| encoder_apply_batchnorm_to_input | True |
| decoder_apply_batchnorm_to_input | True |
| encoder_units | [600, 600] |
| decoder_units | [600, 600] |
| gradient_clipping | 1.0 |
| learning_rate | 0.0003 |
| gradient_momentum | 0.9 |
| gradient_clipping | 1.0 |
| nonlinear | softplus|
#### Result
##### Latent space
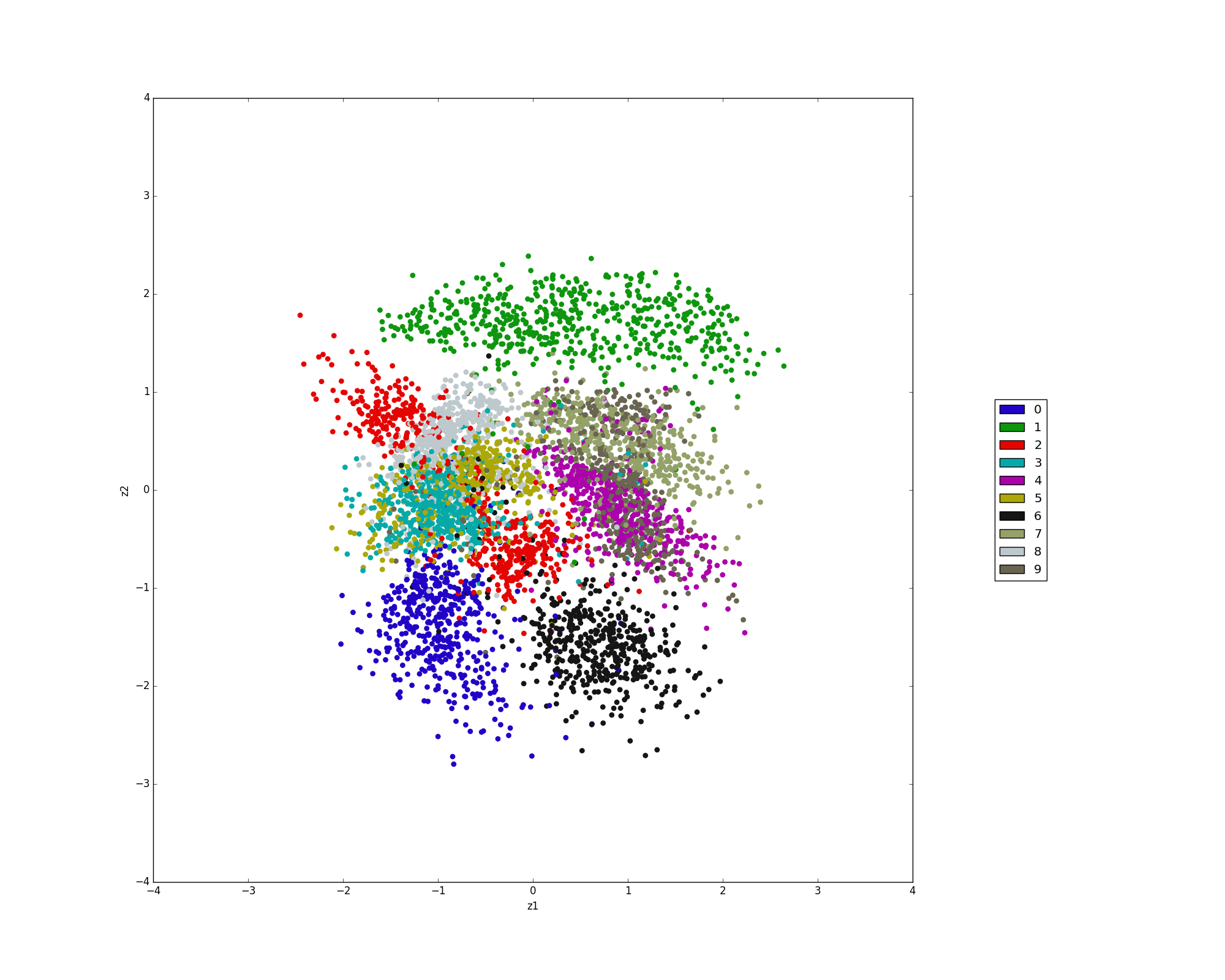
## M2
##### Parameters
| params | value |
|:-----------|------------:|
| OS | Windows 7 |
| GPU | GeForce GTX 970M |
| ndim_z | 50 |
| encoder_xy_z_apply_dropout | False |
| encoder_x_y_apply_dropout | False |
| decoder_apply_dropout | False |
| encoder_xy_z_apply_batchnorm_to_input | True |
| encoder_x_y_apply_batchnorm_to_input | True |
| decoder_apply_batchnorm_to_input | True |
| encoder_xy_z_apply_batchnorm | True |
| encoder_x_y_apply_batchnorm | True |
| decoder_apply_batchnorm | True |
| encoder_xy_z_hidden_units | [500] |
| encoder_x_y_hidden_units | [500] |
| decoder_hidden_units | [500] |
| batchnorm_before_activation | True |
| gradient_clipping | 5.0 |
| learning_rate | 0.0003 |
| gradient_momentum | 0.9 |
| gradient_clipping | 1.0 |
| nonlinear | softplus|
#### Result
##### Classification
###### Training details
| data | # |
|:-----------|------------:|
| labeled | 100 |
| unlabeled | 49900 |
| validation | 10000 |
| test | 10000 |
| * | # |
|:-----------|------------:|
| epochs | 490 |
| minutes | 1412 |
| weight updates per epoch | 2000 |
###### Validation accuracy:
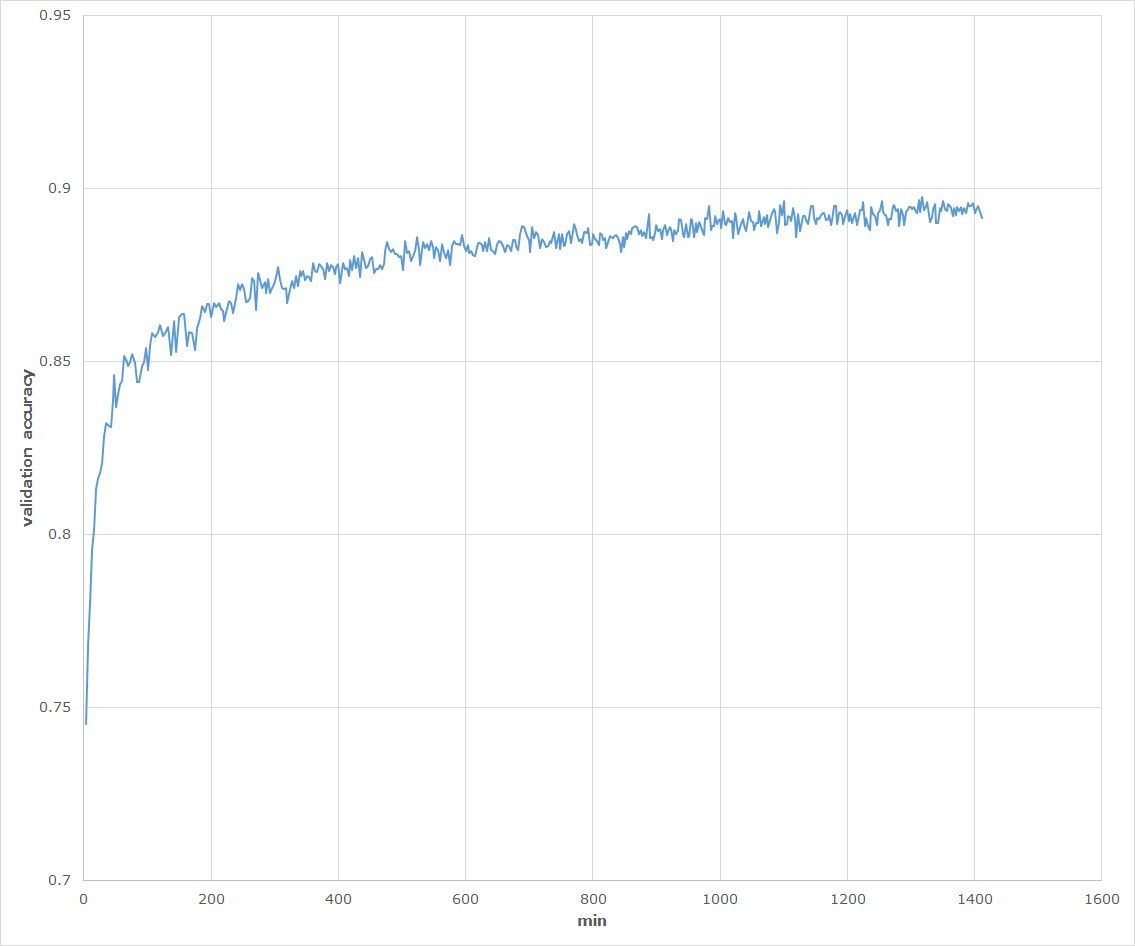
###### Test accuracy: **0.9018**
##### Analogies
run `analogy.py` after training
Model was trained with...
| data | # |
|:-----------|------------:|
| labeled | 100 |
| unlabeled | 49900 |

| data | # |
|:-----------|------------:|
| labeled | 10000 |
| unlabeled | 40000 |

| data | # |
|:-----------|------------:|
| labeled | 50000 |
| unlabeled | 0 |

## M1+M2
##### Parameters
##### M1
| params | value |
|:-----------|------------:|
| OS | Windows 7 |
| GPU | GeForce GTX 970M |
| ndim_z | 2 |
| encoder_apply_dropout | False |
| decoder_apply_dropout | False |
| encoder_apply_batchnorm | True |
| decoder_apply_batchnorm | True |
| encoder_apply_batchnorm_to_input | True |
| decoder_apply_batchnorm_to_input | True |
| encoder_units | [600, 600] |
| decoder_units | [600, 600] |
| gradient_clipping | 1.0 |
| learning_rate | 0.0003 |
| gradient_momentum | 0.9 |
| gradient_clipping | 1.0 |
| nonlinear | softplus|
We trained M1 for 500 epochs before starting training of M2.
| * | # |
|:-----------|------------:|
| epochs | 500 |
| minutes | 860 |
| weight updates per epoch | 2000 |
##### M2
| params | value |
|:-----------|------------:|
| OS | Windows 7 |
| GPU | GeForce GTX 970M |
| ndim_z | 50 |
| encoder_xy_z_apply_dropout | False |
| encoder_x_y_apply_dropout | False |
| decoder_apply_dropout | False |
| encoder_xy_z_apply_batchnorm_to_input | True |
| encoder_x_y_apply_batchnorm_to_input | True |
| decoder_apply_batchnorm_to_input | True |
| encoder_xy_z_apply_batchnorm | True |
| encoder_x_y_apply_batchnorm | True |
| decoder_apply_batchnorm | True |
| encoder_xy_z_hidden_units | [500] |
| encoder_x_y_hidden_units | [500] |
| decoder_hidden_units | [500] |
| batchnorm_before_activation | True |
| gradient_clipping | 5.0 |
| learning_rate | 0.0003 |
| gradient_momentum | 0.9 |
| gradient_clipping | 1.0 |
| nonlinear | softplus|
#### Result
##### Classification
###### Training details
| data | # |
|:-----------|------------:|
| labeled | 100 |
| unlabeled | 49900 |
| validation | 10000 |
| test | 10000 |
| * | # |
|:-----------|------------:|
| epochs | 600 |
| minutes | 4920 |
| weight updates per epoch | 5000 |
###### Validation accuracy:
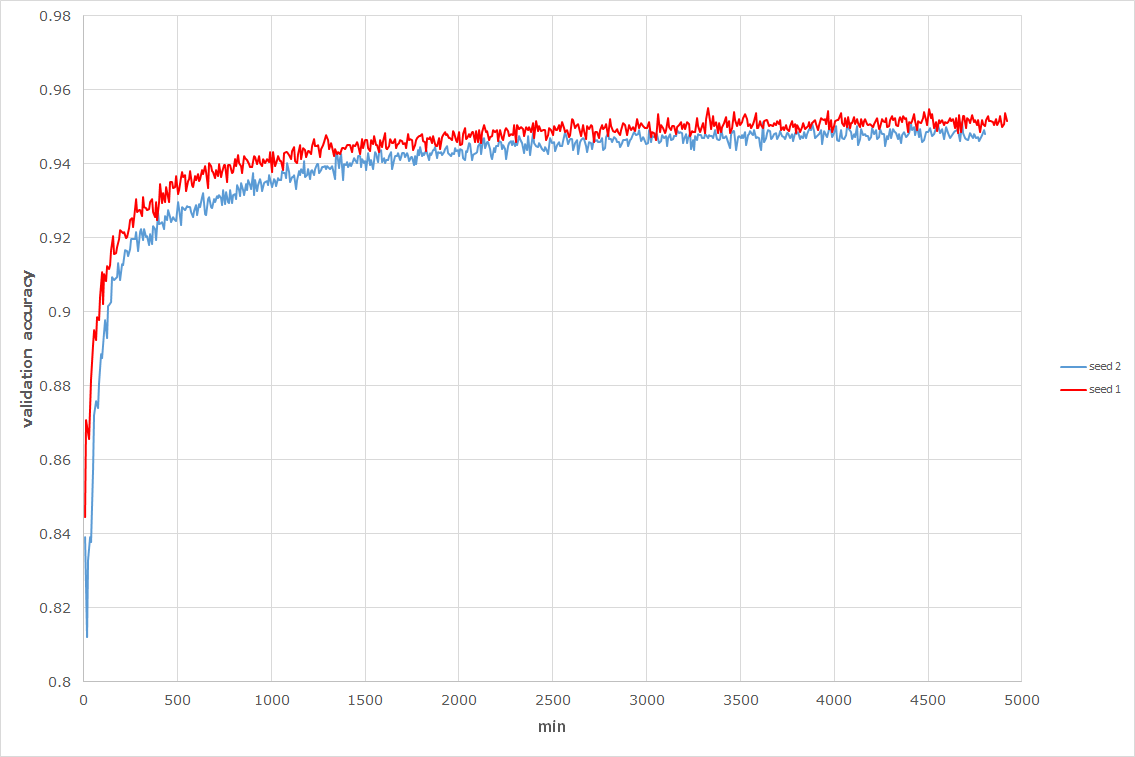
###### Test accuracy
seed1: **0.954**
seed2: **0.951**