Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/muthukamalan/vitcifar
training vision-transformer from stratch and attentions
https://github.com/muthukamalan/vitcifar
Last synced: 23 days ago
JSON representation
training vision-transformer from stratch and attentions
- Host: GitHub
- URL: https://github.com/muthukamalan/vitcifar
- Owner: Muthukamalan
- License: unlicense
- Created: 2024-10-20T19:47:30.000Z (3 months ago)
- Default Branch: main
- Last Pushed: 2024-10-20T20:39:18.000Z (3 months ago)
- Last Synced: 2024-10-21T00:24:23.596Z (3 months ago)
- Language: Python
- Size: 383 KB
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
---
title: VizAttn
emoji: 🐈
colorFrom: red
colorTo: green
sdk: gradio
sdk_version: 4.44.1
app_file: app.py
pinned: false
license: mit
---
# ViT
- GitHub source repo⭐:: [VitCiFar](https://github.com/Muthukamalan/VitCiFar)
As we all know Transformer architecture, taken up the world by Storm.
In this Repo, I practised (from scratch) how we implement this to Vision. Transformers are data hungry don't just compare with CNN (not apples to apple comparison here)
#### Model

**Patches**
```python
nn.Conv2d(
in_chans,
emb_dim,
kernel_size = patch_size,
stride = patch_size
)
```
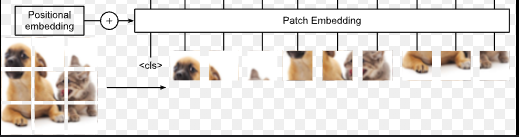

> [!NOTE] CASUAL MASK
> Unlike in words, we don't use casual mask here.
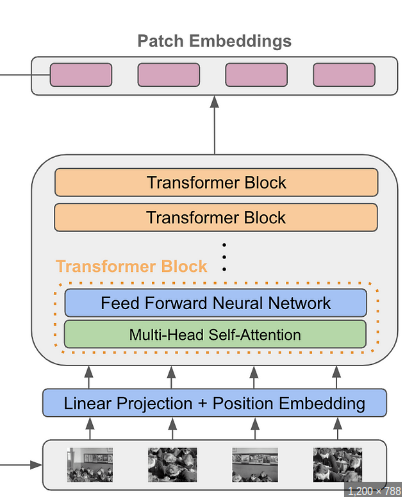
At Final Projection layer,
- pooling (combine) and projected what peredicted layer
- Add One Token before train transformer-block after then pick that token pass it to projection layer (like `BERT` did) << ViT chooses
```python
# Transformer Encoder
xformer_out = self.enc(out) # [batch, 65, 384]
if self.is_cls_token:
token_out = xformer_out[:,0] # [batch, 384]
else:
token_out = xformer_out.mean(1)
# MLP Head
projection_out = self.mlp_head(token_out) # [batch, 10]
```
#### Context Grad-CAM
[Xplain AI](https://github.com/jacobgil/pytorch-grad-cam)
- register_forward_hook:: hook will be executed during the forward pass of the model