https://github.com/mymusise/trading-gym
A Trading environment base on Gym
https://github.com/mymusise/trading-gym
drl gym python3 reinforcement-learning rl trading
Last synced: 7 months ago
JSON representation
A Trading environment base on Gym
- Host: GitHub
- URL: https://github.com/mymusise/trading-gym
- Owner: mymusise
- Created: 2019-01-21T11:19:45.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2019-06-25T07:21:50.000Z (over 6 years ago)
- Last Synced: 2025-04-15T11:06:51.922Z (7 months ago)
- Topics: drl, gym, python3, reinforcement-learning, rl, trading
- Language: Python
- Homepage:
- Size: 271 KB
- Stars: 85
- Watchers: 9
- Forks: 24
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Trading-Gym

Trading-Gym is a trading environment base on Gym. For those who want to custom everything.
## install
```
$ pip install trading-gym
```
Creating features with `ta-lib` is suggested, that will improve the performance of agent and make it easy to learn. You should install `ta-lib` before it. Take Ubuntu x64 for example.
```
$ wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz
$ tar -zxvf ta-lib-0.4.0-src.tar.gz
$ cd ta-lib/
$ ./configure --prefix=$PREFIX
$ make install
$ export TA_LIBRARY_PATH=$PREFIX/lib
$ export TA_INCLUDE_PATH=$PREFIX/include
$ pip install TA-Lib
```
[See more](https://github.com/mrjbq7/ta-lib).
# Examples
## quick start
```
from trading_gym.env import TradeEnv
import random
env = TradeEnv(data_path='./data/test_exchange.json')
done = False
obs = env.reset()
for i in range(500):
action = random.sample([0, 1, 2], 1)[0]
obs, reward, done, info = env.step(action)
env.render()
if done:
break
```
## A sample train with stable-baselines
```
from trading_gym.env import TradeEnv
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import DQN
from stable_baselines.deepq.policies import MlpPolicy
data_path = './data/fake_sin_data.json'
env = TradeEnv(data_path=data_path, unit=50000, data_kwargs={'use_ta': True})
env = DummyVecEnv([lambda: env])
model = DQN(MlpPolicy, env, verbose=2, learning_rate=1e-5)
model.learn(200000)
obs = env.reset()
for i in range(8000):
action, _states = model.predict(obs)
obs, rewards, done, info = env.step(action)
env.render()
if done:
break
```
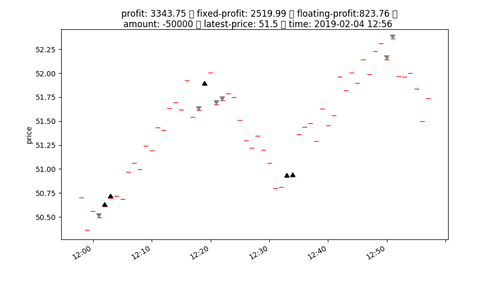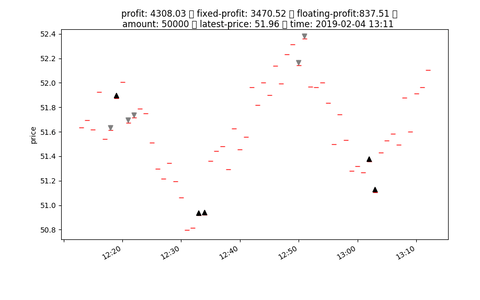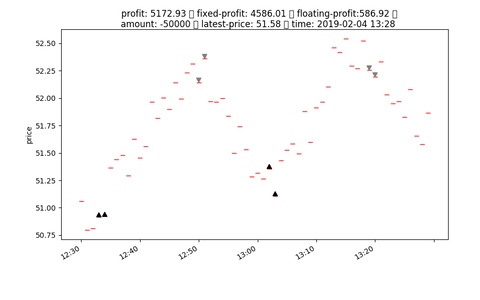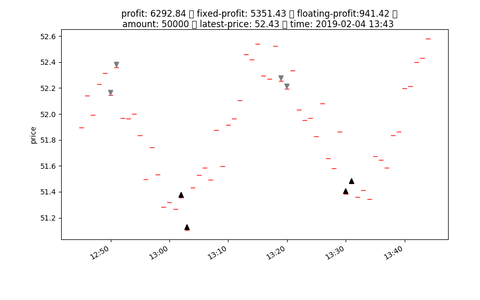
## input format
```
[
{
"open": 10.0,
"close": 10.0,
"high": 10.0,
"low": 10.0,
"volume": 10.0,
"date": "2019-01-01 09:59"
},
{
"open": 10.1,
"close": 10.1,
"high": 10.1,
"low": 10.1,
"volume": 10.1,
"date": "2019-01-01 10:00"
}
]
```
## actions
| Action | Value |
| ------ | ----- |
| PUT | 0 |
| HOLD | 1 |
| PUSH | 2 |
## observation
- **native obs**: shape=(*, 51, 6), return 51 history data with OCHL
```
env = TradeEnv(data_path=data_path)
```
- **obs with ta**: shape=(*, 10), return obs using talib.
- - default feature: `['ema', 'wma', 'sma', 'sar', 'apo', 'macd', 'macdsignal', 'macdhist', 'adosc', 'obv']`
```
env = TradeEnv(data_path=data_path, data_kwargs={'use_ta': True})
```
# Custom
### **custom obs**
```
def custom_obs_features_func(history, info):
close = [obs.close for obs in history]
return close
env = TradeEnv(data_path=data_path,
get_obs_features_func=custom_obs_features_func,
ops_shape=(1))
```
### **custom reward**
```
def custom_reward_func(exchange):
return exchange.profit
env = TradeEnv(data_path=data_path,
get_reward_func=custom_reward_func)
```
Param `exchange` is entity of [Exchange](docs/exchange.md)
# Reward
- reward = fixed_profit
- profit = fixed_profit + floating_profit
- floating_profit = (latest_price - avg_price) * unit
- unit = int(nav / buy_in_price)
- avg_price = ((buy_in_price * unit) + charge) / unit
- fixed_profit = SUM([every floating_profit after close position])