https://github.com/nihalbaig0/Bertelsmann-Scholarship---Introduction-to-AI-in-Business-Nanodegree-Program-2020
Last synced: 2 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/nihalbaig0/Bertelsmann-Scholarship---Introduction-to-AI-in-Business-Nanodegree-Program-2020
- Owner: nihalbaig0
- Created: 2020-12-05T04:53:08.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2021-01-07T18:12:50.000Z (over 4 years ago)
- Last Synced: 2024-10-28T17:39:12.558Z (7 months ago)
- Size: 29.3 KB
- Stars: 6
- Watchers: 3
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-resources - AI Track Notes
README
# Bertelsmann Scholarship
## Introduction to AI in Business Nanodegree Program 2020
## Table of Contents
- [Introduction to AI in Business Nanodegree Program 2020](#introduction-to-ai-in-business-nanodegree-program-2020)
- [Table of Contents](#table-of-contents)
- [**Lesson 2: Introduction to AI and Machine Learning**](#lesson-2-introduction-to-ai-and-machine-learning)
- [**Lesson 3: Using AI and Machine Learning in Business**](#lesson-3-using-ai-and-machine-learning-in-business)
- [**Lesson 1: Data Fit and Annotation**](#lesson-1-data-fit-and-annotation)
- [**Optional Project: Create a Medical Image Annotation Job**](#optional-project-create-a-medical-image-annotaion-job)
- [**Lesson 1: Measuring Business Impact and Mitigating Bias**](#lesson-1-measuring-business-impact-and-mitigating-bias)
- [**AMA Session 1**](#ama-session-1)
## **Lesson 2: Introduction to AI and Machine Learning**
> ### Overview
### Lesson Outline
- Overview of AI
- Machine Learning
- Neural Networks
- Current State of AI
- AI -> Artificial Intelligence
-> Augmented Intelligence
> ### What is AI
*Artificial Intelligence is the science and engineering of making computers behave in ways that , until recently , we thought required human intelligence .* - Anderw Moore
> ### What can AI DO ?
- Facial Recognition
- Automatic Text Recognition (Computer Vision)
- Semantic Segmentation can take every single pixel in an image and assign it to a particular object.
- Social media case
- Speech recognition
- In 2017 Microsoft team achieved 5.1% word error rate on a dataset of telephone conversations on par with humans.
- Challenges :
- noisy environments
- accented speech
- speaking styles and languages with limited training data
- Audio Recognition
- recognizing mechanical failure listening to engines
- Filter out hate speech
- Advice on quality of your writing
> ### The AI Universe
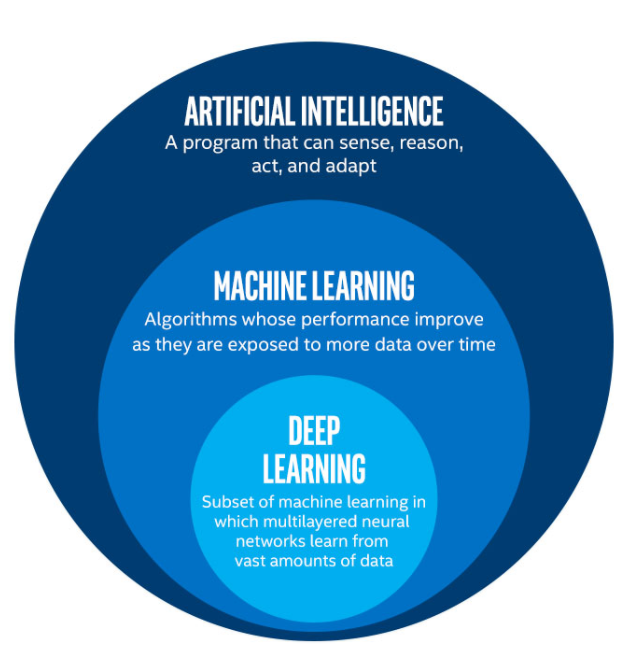
- What do people mean when they refer to AI ?
*The term AI is a aspirational , a moving target based on those capabilities that human posses but which machine do not* - Zachary Lipton
> ### Why Deep Learning
- Supercomputer measure their performance in FLOPS or calculation per second
- Global data sphere reading at a 175 zettabytes of information.
- Why AI is relevent
- Compute power
- Cost
- Data Availability
- FlOps - floating point operations, which computers use to do any calculation (from storing text to doing multiplication!)
> ### Industry Application
- How will AI effect Industry ?
*I thinks that Ai technology, especially deep learning has now advanced to the point where we see a surprisingly clear path for it to transform every major industry* - Andrew Ng
- Add $15.7 trillion to global economy by 2030 (PWC)
- Labor productivity improvements and product enhancements (PWC)
- Sectors with great potential
- Retail : pricing and promotion and customer service management
- Consumer goods: supply-chain management , demand forecasting
- Finance : marketing and sales , assesing and managing risk
> ### Affecting Industry
- AI can distinguish between crops and weeds so that only weeds are sprayed , reducing herbicide usage by > 90%
> ### Machine Learning Concepts
What is Machine Learning ?
*Computer algorithm athat improve automatically through experience* -Tom Mitchell
- Supervised Learning:
- Classification
- Regression
- Unsupervised Learnings:
- Clustering
- Association
- Reinforcement Learning
- Real-time
- Offline
> ### Supervised Learning
- data -> label
- Classification : Categorizing unstructered data into particular categories of class
- Regression : output numerical or continuous
- Supervised Learning use cases
- Image classification
- Optical character recognition
- Face recognition
- Sentiment analysis
- Natural Language Processing
- Machine Translation
- Audio Transciption
- Event Detection
> ### Unsupervised Learning
- Unsupervised Learning finds patterns in data
- Unsupervised Learning use cases
- Cluster customers paths through an ecommerce website
> ### Supervised vs. Unsupervised Learning
- Discrete data is data that you can count and it has a finite amount, say the number of image classes or clothing item types.
- Continuous data is often numerical data that takes a large range of values.
| | Supervised | Unsupervised |
| :--- | :----: | ---: |
|**Discreet** | Classification | Clustering |
| **Continuous** | Regression | Dimentionality Reduction |
> ### Reinforcement Learning
- An area of Machine Learning concerned with how machine learning agents ought to take action in an environment so as to maximize a specific outcome.
**Example**
So when you are teaching a two-year-old about different animals hey this is a cat and this is a dog and this is a cow and they may have a picture book in fornt of them.Then you get them out to and actual barnyard and they see a cow for the first time they look at you and be like cow? (asking) . you're going to say " Yeah , honey that's a cow" . That reinforces it for that child and they learn what a cow is.
*Wonderful example by the instructor* **Alyssa Simpson Rohwerger**
You can read about reinforcement learning in this [article](https://en.wikipedia.org/wiki/Tay_(bot) "Twitter bot")
- Human in the Loop (HITL) refers to having a human-moderator or data annotator that can help with quality control of a product.
> ### Neural Networks
- A neural network makes decision based on information.
- Add weights to increase influence of a certain input.
- Weights and threshold determine decision making models .
- Each layer of a neural network makes decision based on the decisions made in the prior layers.
[Optical Recognition](https://en.wikipedia.org/wiki/Optical_character_recognition "Optical Recognition") in action
> ### Current State of AI
- What can AI do well right now?
- Specific, narrow tasks
- unstructured data
- Better than the best human
- Othello
- Scrabble
- Backgammon
- Chess
- Jeopardy! Question answering
- Shogi
- Arimaa
- Go
- Heads-up n-limit hold'em poker
- Similarly to most humans
- Optical character recognition
- Classification of images
- Handwriting recognition
- Facial recognition (best algorithm about as good as the best humans in 2018)
- Worse than most humans
- Captions & visual descriptions of imagery
- Various robotics tasks(Stable bipedal locomotion)
- General speech recognition
- Complex logical reasoning
- Tasks that are difficult without contextual knowledge
- Translation
- Explainability
- Self-driving cars
- Translation
*We are at the brink of being able to take an AI, [have it] look over our shoulders, and then [it will] make us maybe 10 or 50 times as effective at these repetitive things* - Sebastian Thrun
> ### Outro
**Lesson Summary**
- AI: "The science and engineering of making computers behave in ways that, until recently, we thought required human intelligence."
- Machine learning techniques and terminology such as deep learning, neural neworks, classification, and clustering.
- State of the art AI is powerful and superhuman only in narrow and discrete use cases. It's used in every industry for a wide variety of applications and use cases.
**[⬆ back to top](#table-of-contents)**
## Related Articles :
[Reinforcement Learning 101](https://link.medium.com/guOUIkTaWbb "Reinforcement Learning 101")
[Why Deep Learning over Traditional Machine Learning](https://towardsdatascience.com/why-deep-learning-is-needed-over-traditional-machine-learning-1b6a99177063 "Why Deep Learning over Traditional Machine Learning")
[Unsupervised Learning: Dimensionality Reduction](https://towardsdatascience.com/unsupervised-learning-dimensionality-reduction-ddb4d55e0757 "Unsupervised Learning: Dimensionality Reduction")
[Artificial Intelligence vs. Machine Learning vs. Deep Learning: Essentials](https://serokell.io/blog/ai-ml-dl-difference "Artificial Intelligence vs. Machine Learning vs. Deep Learning: Essentials")
[Deep Learning vs Machine Learning](https://www.zendesk.com/blog/machine-learning-and-deep-learning/ "Deep Learning vs Machine Learning")
[Deep Learning vs Machine Learning:A Simple Explanation](https://hackernoon.com/deep-learning-vs-machine-learning-a-simple-explanation-47405b3eef08 "Deep Learning vs Machine Learning:A Simple Explanation")
[AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the Difference?](https://www.ibm.com/cloud/blog/ai-vs-machine-learning-vs-deep-learning-vs-neural-networks "AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the Difference?")
[Everything you need to know about Neural Networks](https://hackernoon.com/everything-you-need-to-know-about-neural-networks-8988c3ee4491 "Everything you need to know about Neural Networks")
[Everything you need to know about Neural Networks and Backpropagation — Machine Learning Easy and Fun](https://towardsdatascience.com/everything-you-need-to-know-about-neural-networks-and-backpropagation-machine-learning-made-easy-e5285bc2be3a "Everything you need to know about Neural Networks and Backpropagation — Machine Learning Easy and Fun")
[An Introduction to Artificial Intelligence for Business Leaders](https://towardsdatascience.com/https-medium-com-aiprescience-an-introduction-to-artificial-intelligence-for-business-leaders-93b6fe3d2163 "An Introduction to Artificial Intelligence for Business Leaders")
[Deep Learning vs. Machine Learning – the essential differences you need to know!](https://www.analyticsvidhya.com/blog/2017/04/comparison-between-deep-learning-machine-learning/#:~:text=The%20most%20important%20difference%20between,data%20to%20understand%20it%20perfectly "Deep Learning vs. Machine Learning – the essential differences you need to know!")
[GUIDE TO UNSUPERVISED MACHINE LEARNING: 7 REAL LIFE EXAMPLES](https://theappsolutions.com/blog/development/unsupervised-machine-learning/ "GUIDE TO UNSUPERVISED MACHINE LEARNING: 7 REAL LIFE EXAMPLES")
[Artificial Intelligence, Machine Learning, Deep Learning — Characteristics and Differences](https://medium.com/swlh/artificial-intelligence-machine-learning-deep-learning-characteristics-and-differences-ddb4bda470c4 "Artificial Intelligence, Machine Learning, Deep Learning — Characteristics and Differences")
[Why Deep Learning over Traditional Machine Learning?](https://towardsdatascience.com/why-deep-learning-is-needed-over-traditional-machine-learning-1b6a99177063 "Why Deep Learning over Traditional Machine Learning?")
## Related Videos
[AI VS ML VS DL VS Data Science](https://www.youtube.com/watch?v=k2P_pHQDlp0 "AI VS ML VS DL VS Data Science")
[How Neural Networks Work - Weights and Loss - Part 1](https://www.youtube.com/watch?v=oFTpK_v9llw "How Neural Networks Work - Weights and Loss - Part 1")
[Deep Learning - Overview, Practical Examples, Popular Algorithms](https://www.analyticssteps.com/blogs/deep-learning-overview-practical-examples-popular-algorithms "Deep Learning - Overview, Practical Examples, Popular Algorithms")
[Reinforcement Learning Series Intro](https://www.youtube.com/watch?v=nyjbcRQ-uQ8&list=PLZbbT5o_s2xoWNVdDudn51XM8lOuZ_Njv "Reinforcement Learning Series Intro")
## **FAQ** :
- In the comparison between supervised and unsupervised learning they mentioned Dimensionality Reduction which is continuous and unsupervised. But I can not understand the term Dimensionality Reduction and what it means.
- Ans: I am working in a gaming company. In order to analyse churn of a player, there are many dimensions (parameters) which plays a role in churn of a customer. Let's say difficulty of the level, Loading speed, whether advertisement is there or not, whether it is repetitive, etc... There may be 20-30 dimensions with which the churn will be based on. But if you see correlation of churn and every dimentions, for many dimentions, the correlation will be very low. So I'm order to reduce the complexity, we will do dimensionality reduction!
- How does dimensionality reduction fall under unsupervised continuous?
- Ans: As an approach dimensionality reduction allows us to reduce the features/variables used to model. Simply put it allows us to get to the essence of the data. As Nick stated it can be used in both supervised and unsupervised contexts. However it is used mostly in unsupervised data because the algorithm has no labelled dataset to begin with so we need unsupervised learning to uncover the relationships. Let us know if this makes sense.
- Are dimensionality reduction use to speed up training and make more meaningful model?
- In some cases the number of dimensions will be very large. I will give you one more real-life example. I am wokring in a gaming company. In order to analyse churn of a player, there are many dimensions (parameters) which plays a role in churn of a customer. Let's say difficulty of the level, Loading speed, whether advertisement is there or not, whether it is repetitive, etc... There may be 20-30 dimensions with which the churn will be based on. But if you see correlation of churn and every dimentions, for many dimentions, the correlation will be very low. So I'm order to reduce the complexity, we will do dimensionality reduction thereby increasing the processing speed mainly!
- It's interesting you mention a meaningful model. In most cases a model using dimensional transformation will be less explainable than one using the raw features. This is because the composite features generated may not easily correspond to real values. As an example, consider a case where you're looking to forecast house price based on a number of features, including # of rooms, # sq ft, # total rooms. There is likely a correlation between these values so these three features could be reduced into a single dimension which is less interpretable
- What is 'weights' and threshold. If you can give examples of weights and threshold it will be great!
- Ans: weights are actually parameters which define the strength of the connection between units.For example, here "Am I free" has more weightage for our decision to go to a work colleague's party
- Can someone tell me why in the question about when to update the classification model, the answer “The model accuracy stayed the same over time” is not a correct answer? I mean wouldn’t you want to increase your accuracy? Or is there another layer to this I am not gettin?
- The model only gets more accurate while training. Afterwards when you apply it it just does what you taught before. But it will not get any feedback if it was right or wrong. If you want it to get more accurate, you have to feed it with more information it can learn from. So I guess there are two different kinds of input you can get to your model: one is such what the model learns from and the other is that the model only applies what it already knows. So I guess if I want the model to get more accurate while applying I would probably have to add information of the learning type, maybe like a feedback button if my model was right or wrong... but not sure about that,
**[⬆ back to top](#table-of-contents)**
## **Lesson 3: Using AI and Machine Learning in Business**
> ### Overview
Applications of AI
- Face recognition
- Retail inventory management
- E-commerce search relevance
- Customer support automation
- Data categorization/classification
- Agricultural automation
- Manufacturing efficiency and quality control
- Optical Character Recognition (OCR)
- Autonomous vehicles
- Sentiment analysis of social media posts/mentions
> ### AI Approach
- Data Ingestion -> Data Cleaning & Transformation -> Model Training -> Testing and Validation -> Model Selection -> Model Training (Loop) ->Testing and Validation(Loop)->Deployment
**An approach that realizes business value starts with the problem**
Step-1
- Business Problem
- Definition , value , stakeholders , priority, investment
Notes:
- Hardest part
Step-2
- Data
- Availability, provenance, security, coverage, cleaning, augmentation, annotation, refreshing, pipeline development
Step-3
- Model Building
- Feature extraction, hyperparameters, tuning, selection, benchmarking
Step-4
- Deploy & Measure
- Business value measurement, AB testing, versioning, business process integration
Step-5
- Active Learning & Tuning
- Bias mitigation, ground truth & success monitoring, version control
> ### Business Needs
- Business needs drive data needs, not the other way around
Example
*Starting with data is like trying to pack your suitcase when you don't know where you're going or for how long.*
- Production systems actively learn from humans
- You will need human in the loop process to give feedback to your model
> ### The Business Case
- The business problem for adobe is find the right image for customer fast.
- As a product manager it is important to write down all possible steps and try to clarify what each step is trying to accomplish.
Sequential steps to use computer vision to accomplish the task of improving conversion:(Not the only way)
- Generate appropriate search query
- Enter search query
- Apply filters to narrow results
- Identify images with the corresponding visual aesthetic qualities.
Another tool:
- Identifying the AI value and spending time writing down the details what actively needs to be accomplished by that user.
- This also helps you identify what data is needed to accomplish a specific task.
> ### Project Statement
- What problem are we solving? We are helping marketers find the right stock images for marketing collateral, in order to improve conversion and sales.
- How does AI add value? It can tag images with the right qualities, thus making image search more efficient.
- What data are needed? Stock images tagged with aesthetic qualities.
- Scope? When I need to find a stock photo for marketing colateral, I want to select the best option on all variables so I can improve ad conversion and sales.
- How do we measure success? Users can find the best stock image quickly.
> ### Breaking it All Down
- Narrowing the business problem: break it down
One ecommerce problem:
- Improve site conversion
- Improve search results
- Improve click throught on top 10 search results returned
- Improve % of hero images which feature the product
Another ecommerce problem:
- Improve customer experience & repeat customer business
- Improve store experience
- Improve % of shelves fully stocked at 100%
- Understand which products are under-stocked
- Delineate between stocked and empty shelves and identify products missing
Using AI in business :
- Deploy for targeted use cases
- To realize business value, AI technologies must be deployed to deliver specific, measurable business outcomes for targeted use cases.
- Business problem before data
- It's rarely a good idea to start with a decision to clean up data. It's almost always better to start with a business case and then evaluate options for how to achieve success in that special case.
- Success depends on the data
- Out AI systems are only as good as the data we put into them.
> ### Metrics
What makes a metric effective?
- Easily measurable
- Directly correlated to business performance
- Predictive of future business outcomes
- Isolated to factors controlled by the group it's measuring.
- Comparable to competitor's metrics
> ### Metrics Quiz
how would you design a metric to measure the outcome of finding the right stock images?
- Time spend between searching and purchasing
- Number of images purchased per user
- Net Promoter Score (NPS) rating for search results
- % of stock imagery purchased overall
All four could be answer. It depends on what's most meaningful for adobe's business.
> ### Metrics Example: LinkedIn
Improving job search and job listings at Linkedin
- Classified companies by industry
- Improved quality of job recommendations
- Increased collective InMail response rates by 45%
- Total number of continuing, two way conversatoins started in Linkedin Recruiter doubled
( They used NLP for performance increase)
> ### Need for AI
- Not all projects need AI
Key considerations :
- Do you have an impactful business problem that warrants solving?
- Can you quantify the business value clearly and simply?
- Does the problem have a large volume of associated data?
- Is that data well organized and is it complete?
The Data is most critical piece of this problem here.
- How much data do you have?
- Does the dataset match the problem?
- Is the dataset complete?
- Is the data annotated correctly for the ML team?
**Spending a lot of time actaully looking through your dataset and samples of it in detail is absolutely critical as the product manager**
> ### Need for AI Example
Do we need Tradional Machine Learning approach or Deep Learning approach?
- It really depends on the problem you are solving and the data available to solve that problem.
Need for deep learning vs traditional ML
- Deep learning outperforms with large datasets. ML will work better with smaller datasets.
- Deep learning techniques will require more powerful infrastructure.
- Deep learning is about learning features rather than manually engineering them
- Deep learning shines when applied to complex/multidimensinal problems: image classification, natural language processing, speech recognition.
You need to think about your data pipeline once you deploy to production.Setting up a data pipeline for training not just once but continiously is super critical for the product long-term success.
Typically versioning or continuous learning can update or improve your model based on new information.
> ### Things to Remember
- Start with the business value
- Break it down into a small and specific component of the process that you want to improve.
- Get real with the data
- use production data to ensure that the training data match the reality of the real-world deployment.
- Learning is key to value
- Learning from new data ensures constant improvement
Customer support use case
- Autodesk automated their customer service and support using chatbot that uses NLP to interect with customers and help them resetting their password. If it was not password reset the chat was routed to a live support system for resolution.
**There is no magic solution when deploying machine learning technology. It's a mix of keeping humans in the loop and gradually expanding the use case overtime**
> ### Team Overview
Needs of the team:
- Business need
- Infrastructure
- Useability
- Algorithm
- Data
- Performance
- Quality
Reality: Cross-functinal teams are critical for driving business outcomes.
- Product Design
- Engineer
- DevOps
- QA
- Data Eng.
- Data sci.
In order to have a successful product launch, you need folks representative of all these different types of skill set.
> ### Key Roles
Product Owner
- Business case owner
- Bridges from stakeholders to team
- Owns maximization of product value
- Ensures that the team builds the right product
Designer
- Owns human-computer interaction design
- Visual design, information architecture, interaction desing
- Useability/accessibility
Software Engineer
- Builds product infrastructure
- Problem solver in software development
- Frontend/backend
Data Engineer
- Builds data infrastructure
- Gets model into production
- Ensures entire pipeline can support rapid developlemt and iteration after launch
- Model management
Data Scientist
- Build & selects models
- Guides the team on the state-of-the-art technology
- Structures the problem to achieve the business metrics
- Uses data to answer business questions
Quality Assurance
- Owns quality assurance of the product
- Ensures product release is ready
- Scalability testing
- Functional testing
Development and Operations (DevOps)
- Ensures infrastracture reliability
- Manages scalibility and performance
- Mitigates security risks
- Ensures development and ML team can work efficiently
> ### Project Management
- Scrum is highly recommended.
- This process can take days, weeks or months depending on the factors.
- As the team you will do backlog planning, sprint meetings,backlogs
- A scrum teams sprint can last from one to four weeks.
> ### Summary
- Start with the business problem
- Make sure you have the right data
- Build an interdisciplinary team
- Learn and iterate...fast
**[⬆ back to top](#table-of-contents)**
## Related Articles :
[What is Scrum?](https://www.atlassian.com/agile/scrum "What is Scrum?")
[The Scrum Primer](https://scrumprimer.org/ "The Scrum Primer")
[11 steps of Scrum](https://luminousmen.com/post/11-steps-of-scrum "11 steps of Scrum")
[How to measure NPS](https://www.qualtrics.com/uk/experience-management/customer/measure-nps/ "How to measure NPS")
## Related Videos :
[Scrum Methodology | Agile Scrum Framework | Scrum Master Tutorial | Edureka
](https://www.youtube.com/watch?v=8dGdIcyDk1w "Scrum Methodology | Agile Scrum Framework | Scrum Master Tutorial | Edureka
")
## **FAQ** :
- Does anyone know how the net promoter score works and what it is good for? Thanks in advance.
- Long story short you can measure the satisfaction of the customers. For example if you range your Net Promoter Score from 1 to 10 , clients in range from 1-3 are considered Detractors and from 7-10 are considered Promoters. The others (4-6) are in the neutral area
- [What is Net Promoter Score (NPS)? Everything you need to know](https://www.qualtrics.com/uk/experience-management/customer/net-promoter-score/?rid=ip&prevsite=en&newsite=uk&geo=TR&geomatch=uk "What is Net Promoter Score (NPS)? Everything you need to know")
- I understand the concept of how deep learning improves in accuracy when a model is fed more data-however, how is this different to more traditional machine learning algorithms? Surely more data is better there as well?
- DL has more capability to detect patterns in data since it has multiple layers to process data and grasp features. Whereas, a traditional ML might not detect patterns so successfully although you feed it large amounts of data. So, it can be a waste of computation time.
- [Parametric and Nonparametric Machine Learning Algorithms](https://machinelearningmastery.com/parametric-and-nonparametric-machine-learning-algorithms/ "Parametric and Nonparametric Machine Learning Algorithms")
- [Deep Learning vs. Machine Learning](https://towardsdatascience.com/deep-learning-vs-machine-learning-e0a9cb2f288 "Deep Learning vs. Machine Learning")
- Can somebody enlighten me on the actual worth of the Net Promoter Score metric ? I hear contradicting opinions, some ( research papers) stating that it is not a reliable metric in some cases.
- Hi! I also think it is a bit tricky. You remember the meme about recommending Windows? :slightly_smiling_face: There was an awesome reply that people don't recommend operating systems to each other in regular conversations. It's true for NPS as well. I'm not going to promote a company among my friends just because I like it. Sometimes I do, yes, but very rarely. Maybe when they ask for advice, like which running shoe is the best.
- Pros: It's easy to measure and highly correlated with business growth. Cons:white_frowning_face:: Doesn't answer the context for the data points 1-10. Also, often too small sample of participants in this (voluntary) survey.
- Have a question regarding the Business Case issue: I didn't quite get why steps 5-8 are better to accomplish the task to find a photo for marketing collateral. Thank you for your ideas!
- I think steps 5-8 are the best match for the task because gathering photos based on high (or low) conversion is not necessarily a computer vision task. You could do that just by associating the converted value with its image identifier, for example. Based on the previously given visual criteria, the Computer Vision algorithm would do exactly what's described in 5 to 8, specially step 8.
- In terms of reinforcement learning, doesn't the recommendation of having a Human In The Middle to restrict bias adversely affect one of the main benefits of AI, namely being able to conduct activity at scale faster than humans could?
- Depends. Human intervention is good if its to improve how the model learns. It would be a waste of time and money if you let it run when the data is becoming skewed. Obviously you should let the model do as much as it can on its own, but only if you are getting meaningful data.
The above I mentioned is very generic, but without a scenario it's hard to give a definate reply. A lot of this is up to your product manager and data analyst to decide how far you let the model run without intervention.
- Hi everyone, I just finished the intro to AI in business. Can anyone help me with the difference between Clustering and Association in Unsupervised Learning?
- Clustering is when similar attributes are grouped together (if you have more than two legs, you're more likely to be an animal). Association is a method for discovering interesting relationships (if you buy onions and potatoes in a store, you're likely to also buy burgers).
- In Association we want to find possible groups of products that are related to each other. for example, we found out that in a shopping store, people who buy breeds usually buy milk and sugar too. in this situation we use Association Rules to identify these kinds of relation then we can put these related products close to each other on the shelves. But in clustering, the aim is to identify the group of people with similar interests for samples all those who have bought milk and cola are in one cluster..
**[⬆ back to top](#table-of-contents)**
## **Lesson 1: Data Fit and Annotation**
> ### Answering Questions with Data
- A good product manager will know a lot about their product and how it might be improved with machine learning techniques
Example : Improved Search Result
- Return relevent results
- Return results, tailored to individial preferences
> ### As Good as the Data
- How a model performs depends heavily on the training data you give it
Data Size
- Do you have enough data?
- Just a few data point will create bias and accuracy in the resulted model
- A good data set that has many examples of the different classes of data will help the model generalize better when faced with new user data
Garbage in, Garbage out
*In computer science, garbage in, garbage out (GIGO) describes the concept that flawed, or nonsense input data produces nonsense output or garbage.*
- Data Size
- If you are using a deep learning algorithm, as opposed to some traditional machine learning techniques, data size is even more important.
- Deep learning (neural networks) often need to see many examples of every possible category before they can learn to distinguish between different classes of data and find general patterns in some data. If you have too few data points _or_ your data is not evenly distributed between different categories that you want to distinguish, you could get some significant [sampling bias](https://en.wikipedia.org/wiki/Sampling_bias "sampling bias") in your end predictions; predictions that are biased towards classifying all data into one class, for example, or predictions that have learned to find patterns that are irrelevant to the task at hand.
Data Distribution and Pattern Detection:
- Credit card fraud detection: most credit card transactions are valid, and so these datasets often have thousands of valid examples and very few examples of fraudulent transaction data, so you'd need to take steps to account for this imbalance otherwise a model will likely learn to classify all new data as valid since that is the most likely choice.
- You might think of building a classifier to distinguish wolves from dogs. If all wolves are images with a snowy background, a machine learning model might mistakenly conflate snow with wolves, and you'll need more, varied data to create an accurate model.
> ### Data Fit
Ensuring Data Fit
- Use production data to ensure the training data matches real-world scenerios
- Determine the success criteria for a trained model:
- Precision
- Recall
- F1 score
- If not met -> re-train, go back to the data
- Precision indicates how often the model is correct when it predicts the positive label
- Recall indicates how many of the true positives your model predicted
- F1 score is a combination of precision and recall
- A [confusion matrix](https://en.wikipedia.org/wiki/Confusion_matrix#Table_of_confusion "confusion matrix") displays the number of true positives, true negatives, false positives, and false negatives given some number of input data points n.
- The accuracy, for example, will be the number of true positives + true negatives divided by the total number of data points.
- precision is defined as the number of true positives (truly fraudulent transaction data, in this case) over all positives, and will be the higher when the amount of false positives is low.
- recall is defined as the number of true positives over true positives plus false negatives and will be higher when the number of false negatives is low.
- F1 score = 2 * (Precision * Recall) / (Precision + Recall)
> ### Data Collection & Relevance Quiz
- Say you are building a product that aims to recognize the make and model of a car (ex. Toyota Camry, 2001) in images of different streets and roads. How might you collect or create data that is useful for this task?
- Ideally collect data from your product,say images that your company has taken and submit them to car experts.
One of my favorite articles that involves detailed, car-data collection, is a [paper](https://www.pnas.org/content/114/50/13108 "paper") by Timnit Gebru et al, about building a car dataset and using it to estimate the characteristics of certain geographical areas. Their method for data collection and creation (which uses a combination of approaches) is detailed [in this appendix](https://www.pnas.org/content/pnas/suppl/2017/11/27/1700035114.DCSupplemental/pnas.1700035114.sapp.pdf "in this appendix").
- Say you are building a customer experience bot that aims to group types of restaurant reviews. Your manager has asked you to flag common issues like cleanliness and service at different restaurants. What kind of data would be most relevant to this task?
- Text reviews sorted into specific complaint categories like hygiene and service
> ### Data Completeness
Data Completeness
- What is the problem you're trying to solve and how does it benefit your end users?
- What data will help you solve that problem?
- Collect data and observe relationships; patterns and similarities
- Identify potential anomalies or missing data
- Conduct research and get the best data to serve your use case
> ### Appen's Data Annotation Platform
Adding Annotations via a Platform
- To annotate a new data source that perhaps only includes images of flowers and no other identifying labels or features, you'll have to a data annotation platform. These platforms will send unlabeled data to some human annotators who can classify or provide features for the data and send it back to you in a tabular format.
- Some cloud service providers like AWS provide data annotation services as do specific companies; data annotation tooling is what the company, Figure Eight does and so we will use their platform as an example, but the skills you learn here about designing labels and creating a dataset will be applicable, across different platforms.
> ### Template Jobs Quiz
What are the default, possible, output labels for a Sentiment Analysis data labeling job?
- Positive
- Negative
- Neutral
> ### Case Study: Parking Signs & Figure Eight
- Data annotation platform
- Uploading data
- Designing an annotation job
- Creating test questions
- Monitoring results
> ### The Platform
----
> ### Job Design
- CML - Custom Markup Language (an HTML based language)
> ### Instructions & Examples
types of parking sign images
- different kinds of parking sign
- images from the actual dataset (marked)
- hard to see parking sign
- there are no parking sign(other signs may be there)
- No sign at all
> ### Example Design Quiz
Which two kinds of examples should you include in your instructions for any data annotation? (Check two answers.)
- At least one example for each possible data annotation
- Ambiguous or tricky annotation
> ### Test Questions
- You want to create a set of test question for a job which is essentially ground truth data. Where you provide an answer to an question
- When a contributor misses a test question they are shown the correct ans after they submit.
Along with a reason why they were incorrect
- One thing to note about your test question is that you do want to make sure you have a pretty even answer distribution.
You want to make sure:
- You are testing contributors on all possible answer type and you are not training them to lean more to a specific ans.
- You want to train them to look out for everything that might appear in a training dataset.
- Launching a subset of data is recommended
- What the contributors miss the model may also miss
> ### Auditing Results
- Auditing the test quetion gives you a chance to identify where contributors misunderstand the job . Go back update the instruction. update the design . Create more test question.
- Then you can design if you want to launch another test or you got the expected result in first try
> ### Planning for Failure
Designing for the Unknown
- How do you handle cases the model hasn't seen before?
- Design an option with the least negative impact
> ### Planning for Longevity
- If your data does not change , you can use a static model (no need for updates)
- For ever-evolcing data, which is common, you should use a dynamic model
- Continously trained on new data
- So, it can keep learning
- For frequently changing data, you may need to change the annotation job and update your data to include more relevant definitions or examples
> ### Summary of Topics
- The underlying data determines the efficacy and accuracy of a model
- Data completeness and product fit are important considerations when using machine learning in a product
- You can build a dataset by designing a data annotation job
- You should update your data annotations or model, as needed, according to changes in the underlying data
## **Related Articles**
[What’s the deal with Accuracy, Precision, Recall and F1?](https://towardsdatascience.com/whats-the-deal-with-accuracy-precision-recall-and-f1-f5d8b4db1021 "What’s the deal with Accuracy, Precision, Recall and F1?")
[What is Data Annotation and What are its Advantages?](https://medium.com/anolytics/what-is-data-annotation-and-what-are-its-advantages-95766213351e "What is Data Annotation and What are its Advantages?")
[Simple guide to confusion matrix terminology](https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/#:~:text=A%20confusion%20matrix%20is%20a,related%20terminology%20can%20be%20confusing "Simple guide to confusion matrix terminology")
## **Related Videos**
[Confusion Matrix | How to evaluate classification model | Machine Learning Basics](https://www.youtube.com/watch?v=jr_BcU4QlNE "Confusion Matrix | How to evaluate classification model | Machine Learning Basics")
## **FAQ** :
- recall and precision is clear but what is the origin of f1 metric?
- F1 Score is needed when you want to seek a balance between Precision and Recall. Right…so what is the difference between F1 Score and Accuracy then? We have previously seen that accuracy can be largely contributed by a large number of True Negatives which in most business circumstances, we do not focus on much whereas False Negative and False Positive usually has business costs (tangible & intangible) thus F1 Score might be a better measure to use if we need to seek a balance between Precision and Recall AND there is an uneven class distribution (large number of Actual Negatives).
- I wonder if there is a general rule of the right size of dataset you need for specific project types?
- there is no general rule. or the better say it depends. An other rule is "there is no data like more data" The bigger the dataset (with a good qualitiy) the better the results. It also depents on the complexity of your goal. If you just have two classes you need less data than the case you have 100 classes. If you have not only classification but also position recognition, you will again need more examples.What you normaly do is to have a seperate dataset the NN does not see during training. There will be a point in Training when the result on this seperate set starts to decreasing. than you run into overfiting (to you training data). If the metrics at this point in time, on you seperate controll data set not good enough. you will need more training data. At last give a thought on the number of parameters you have in your NN. Each of this has to be adjusted multiple times. your dataset has to ensure this.Hope it was at least a little bit helpful to you (edited)
## **Optional Project: Create a Medical Image Annotation Job**
## **Related Articles**
## **Related Videos**
[How to use Appen for Data Annotation](https://www.youtube.com/watch?v=Av1ibav03JM&%3Bfeature=youtu.be "How to use Appen for Data Annotation")
[Appen Video Tutorials](https://success.appen.com/hc/en-us/sections/201955376-Video-Tutorials "Appen Video Tutorials")
## **FAQ** :
## **AMA Session 1**
You can find all question and answers in this [link](https://docs.google.com/document/d/1k1BKAZ9TPxb5oamY-Mbzk_yAoQNL2LjmJQk523RaxFk/edit "link")
> ### Concepts
- Overview of Modeling
- Training Data
- Model Evaluation
- Transfer Learning and Automated ML
> ### Activation Functions
- Serve as the decision boundary to pass on information
- Would like to pass a continuous value instead of strictly 0 or 1
- Important for data flow in the model
- Decision valaue suddenly umps to 1 whe we reach out threshold
- This does not allow for a range of output values and restricts our ability to be uncertain
- The sigmoid function is continuous and returns a range of values from 0 to 1
- Model training will update weights to find the optimal parameters that handles all cases through Back Propagation
- The node is called Perceptron
- Multi-layer Perceptron
- Basic perceptron model
- Simple data types
- Convolution Neural Network
- Convolution and pooling
- Common in computer vision
- Long-Short Term Memory Network
- Can save internal state
- Common in NLP
Further reading on [activation functions](https://medium.com/the-theory-of-everything/understanding-activation-functions-in-neural-networks-9491262884e0 "activation functions")
### Backpropagation & Updating the Weights of a Network
As a neural network trains, it starts off randomly guessing appropriate weights and will often produce the incorrect outputs, with some error that can be measured as the difference between a model-output value and a true output label or value. For a model to improve, it needs a way to:
Identify the source of its error (which model weights are responsible for the error?)
Update those weights to a new, better value
The first step, of identifying the weights causing an output error, is referred to as backpropagation. Essentially, backpropagation looks at the output of a model and goes backwards through the nodes and layers of a network to find the source or error.
Then, there is a second step, updating the weights such that their value is either increased or decreased in response to the error they caused.
The cycle of backpropagation and updating weights continues until a model is trained or until it has sufficiently low error!
> ### Perceptron Math
> ### Modeling, Key Points
Overview of Modeling:Summary
- Neural networks are a series of layers comprised of computational nodes
- Activation functions act as decision boundaries for a node
> ### Training Data
Data in ML
----
Learn by example
- Data defines model behavior and performance
- Model parameters are updated based on training data
- A model will NOT learn if it's not in the data
- Bad data = bad model
> ### A Pet Model
- If the model is given unknown data as long as the data is similar to training data then it is able to infer the content of the data
- If the model is not given a particular type of data it will never be able to infer other types of data. Only after being trained on a given type of class of data will the model begin to make prediction on that type of data
> ### Training Data is Key
- Models will only learn about data that they are trained with
- Ensure that the data used to train a model reflects real-world data
- Use a diverse set of data to build a roboust model
The Right Data
---
Diversify your data
- Data that encompasses all likely scenarios
- Photos from the real world (not just a studio)
- Audio collected with background noise
- Text of various writing styles
- Equal amount of different types of data
- Correctly labeled data
Common Issues with Training Data
- Unbalance or biased data
- Data does not reflect real world data
- Mislabeled data
- Insufficient data
- There is no clear cut rule as how much data will be needed we generally want to start with a few 100 examples of each target class and then scale up the amount of training data until we reach desired accuracy
> ### Training Data Quiz
- What data would you need to train a voice assistant for a hotel concierge service?
- 10 hours of audio data of concierge desk conversations and 50 hours of audio data of the most common guest-concierge interactions with data collected froma studio, from a hotel room, and with sufficient ambient noise.
> ### Training Data Summary
- Training data will make or break a machine learning model
- Ensure there is a variety of data and that the data reflects real world scenerios
- Unbalanced data will cause a model to skew towards a particular outcome
- Mislabed or dirty data will significantly impact model performance
> ### Model Evaluation
- Need robust metrics to know how our model wil perform after deployment
- Knowing which metrics to measure will help guide model development
- Model performance will determine the overall success of AI products
- training data (80%) -> test data(20%)
- It is important that the training data and test data both should be as balanced as possible.
- Having unbalanced data in the test data may skew our perspective on the model performance
- Training data (80%) -> validation data (10%) -> test data (10%)
- Validation data is used during training to help inform updates to model parameters and is different from test data
- The test data is never seen by the model until after the training is compelete
Evaluation test
- Precision and Recall
- Modeled precision answers the question of when the model makes a prediction how likely is that prediction to be correct?
- Precision tells us what percentage of all the predictions were correct
- Recall tells us what percentage of the real occurrences were recalled by the model
- F1 score combines the precision and the recall to produce and overall performance measure of the model
- Generally F1-score above 0.75 or 0.8 will be considered decent. However , it will depend on the intended application and how critical the performance of the model is to the success of the product
- The confusion matrix is a grid which shows all the predicted labels relative to all the true labels. When looking at the chart the values accross the row should add up to a 100 percent while columns have no limitaions
- Why are training and test data separate?
- We use training data when a model is learning. In our cat/dog/gerbil example, this is the data a model can use to learn and find patterns that distinguish the different classes of images.
- After training, we need a way to test how well a trained model generalizes. The idea is: we want a trained model to perform well on new inputs, that it hasn’t seen before. This is where test data becomes useful! Because a model hasn’t seen it during training, we can test it on this dataset and evaluate its performance.
> ### Model Evaluation Quiz
What is the F1 score?
Precision = 0.75
Recall = 0.75
F1 Score = ( 2 * 0.75 * 0.75) / (0.75+0.75) = 0.75
> ### Model Evaluation, Key Points
- The model should never see the test data until model evaluation
- Precision and recall are the key metrics when evaluating a model
- F1 score provides an overall measure of model performance
- A confusion matrix can help identify where a model is failing
> ### Transfer Learning
- We can leverage existing trained models to solve new problems
- In order to do transfer learning we take the first N layers of pretrained network.The number N is generally all except the last few layers.Then we copy these layers into the new model.Then we will attach new layers of network behind the old one.
- Fine tuning is the same process but you also retrain the earlier layers.
> ### Automated ML
Less math please!
- Services to automatically create models from data
- Allows for quick prototyping
- Benefit of enterprise support
- Much less hassle and complexity
Neural Architecture Search
-Automatically determine best architecture for data types
- Consists of architecture blocks that can be configured together for optimization
- Handled by the ML service provider
> ### Automated ML vs Custom Modeling
Automated Machine Learning
### Pros :
- Easy to get started
- Robust enterprise support
- Cheap for quick development
### Cons:
- Limited use cases
- Difficult to extend
- Data is accessible to provider
Custom Modeling
### Pros :
- Complete customizability
- Unlimited use cases
- Full control over parameter tuning
### Cons :
- Expensive to get started
- Requires ML expertise
- Limited means of external support
> ### Automated ML, Summary
- Transfer learning uses knowledge from previous models
- Pretrained models can be found online for use with transfer learning
- Automated ML makes it easy to create models
- For more complex models a custom development may be required
> ### Outro
- AutoML aids us to help model build faster
## **Lesson 1: Measuring Business Impact and Mitigating Bias**
> ### Introduction to Business Impact
Key topics
- Benefits & challenges of AI initiatives
- Define and measure success metrics
- A/B Testing & Versioning
- Monitor & mitigate Bias
- Continuous Learning
- Compliance & ethics
- Scale
> ### Case Studies and Challenges
- Companies are building better recommendation system , better search engine , Chat bots for customer service using AI
- AI also helps increasing internal efficiencys and adding more automations. Manufacturing and supply chain industry is in the forefront.
- AI helps in fraud Detection and disease prediction
- The overall benefits of AI can be put into 2 braod buckets. It sorrounds improving operations and delivering a superior customer experience.
Challenges in AI for companies:
- Number one challenge is implementation complexities.
- People's skills in defining roles and responsibilities is another challenge.
- Questions around how to measure and provide business values
- Getting the right data for AI projects is also time consuming and costly
- Protecting Privacy and ensuring their security is also a big hurdle.
> ### Measuring Success
- Defining your business goal and success metrics is first step. Then continuously monitor your success metrics
- For different industries you may have different business goal
- Next Revisit you success metrics
- Customer experience
- Revenue gain
- Customer engagement
- Business process automation
- Better & faster decision making
> ### Outcome vs. Output
- AI products must be deployed to deliver specific and measurable business outcomes.
- You may not want to consider a model with highest accuracy which is not delivering the right business outcome.
Outcome
- Generate Revenue
- Improve Customer Experience
- Increase user satisfaction
- Automate & save cost
Output
- Accuracy
- Execution Time
- Recall
- Precision
**Monitor the accuracy,performance and fairness of your AI models and understand the reasoning behind the results**
> ### Chatbot Example
Key Success Metrics
- Number of active users
- Number of bot sessions initiated
- Average chat sessions
- Average chats handled by bot
- Number of new users using bots daily, weekly, monthly
Associated business matrics
- Conversion rate
- Customer support savings
- Increase in Net Promoter Score
- Cost per acquisition
- Lift in engagement
- Customer retention rate
Measure , Learn , Evolve
- User adoption and Retention
- How many users in the population are interacting with the chatbot?
- How many users come back to the bot to resolve the issuse?
- User engagement
- What is the intensity and depth of the engagement?
- Is the chatbot able to address more complex problems?
- Are their specific scenerios where chatbot is more successful than others?
- Conversion rate
- Self service rate
- User satisfaction
- Make sure you are collecting customer satisfaction by asking them to rate the interaction so you know if the bot is effective of not
> ### A/B Testing & Versioning
- A/B testing helps you make more data-driven decisions
Designing A/B Test for Models
- Deciding on a performance metric
- Deciding on test type based on your performance metric
- Choosing a minimum effect size you want to detect
- Determining the sample size
- Running the test until sample size is reached
What else should you consider?
- Cost benefit analysis
- Is x% accuracy gain beneficial for business?
- What if this slightly better model requires a much larger investment?
- Run the test long enough to capture any seasonality effects
- Control the experiment to avoid "novelty effect" - initial positive reaction that wears off
- It is very common to send about 20% of your customers to a new model (v2, a "challenger" model) and 80% to a well-tested model (v1, a "controlled" model). This way, you can get some good experimental data and really see if the v2 of your model does indeed work better; if it does, you can then switch all user traffic (100%) to that new model.
- You can repeat this process as necessary, and as you continually improve different versions of a model.
> ### Monitor Bias
- Monitoring and mitigating bias should be should be an ongoing initiative as you launch and scale your AI product
What is Bias?
- AI system are only as good as the data we put into them
- Bad data can contain racial , gender, and ideological biases
- Ecommerce comapnies influence these user behavious by introducing bias in the data and the subsequent product recommendation
### Unacceptable biases :
- Alexa and Google Assistant are 30% less likely to understand non-American accents
- AI Assistants Struggle To Understand Women
- Bias Issues are in face Recognition Systems
### Different types of Bias:
- Model Bias
- When the model itself generate biased outcome
- Data Bias
- Introduced through unbalanced selection of sorts data
- Annotation Bias
- which is introduced by Humans annotating and generating the human data
- The Bias is in the training data, and it comes from Humans
We need diversity where subjective opinions matter
- Sentiment Analysis
- Search Relevance
- Data Categorization
- Content Moderation
- Image Moderation
- Audio/Text Collection for Speech AI
---
- If you are building a voice Assistant you have to collect data from different race , age groups and gender
- In content modulation where you want to remove inarppropiate content
- So if you are building a product that should work universally, you need to collect diverse opinion and train your data accordingly