https://github.com/omerbsezer/Generative_Models_Tutorial_with_Demo
Generative Models Tutorial with Demo: Bayesian Classifier Sampling, Variational Auto Encoder (VAE), Generative Adversial Networks (GANs), Popular GANs Architectures, Auto-Regressive Models, Important Generative Model Papers, Courses, etc..
https://github.com/omerbsezer/Generative_Models_Tutorial_with_Demo
auto-regressive-model bayesian-classifiers cyclegan dcgan gans gaussian-mixture-models generative-adversarial-network generative-model tutorial tutorial-code variational-autoencoder variational-inference
Last synced: 12 months ago
JSON representation
Generative Models Tutorial with Demo: Bayesian Classifier Sampling, Variational Auto Encoder (VAE), Generative Adversial Networks (GANs), Popular GANs Architectures, Auto-Regressive Models, Important Generative Model Papers, Courses, etc..
- Host: GitHub
- URL: https://github.com/omerbsezer/Generative_Models_Tutorial_with_Demo
- Owner: omerbsezer
- Archived: true
- Created: 2019-01-17T14:06:16.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2019-01-21T14:57:50.000Z (over 7 years ago)
- Last Synced: 2025-04-02T07:26:01.126Z (over 1 year ago)
- Topics: auto-regressive-model, bayesian-classifiers, cyclegan, dcgan, gans, gaussian-mixture-models, generative-adversarial-network, generative-model, tutorial, tutorial-code, variational-autoencoder, variational-inference
- Language: Jupyter Notebook
- Homepage:
- Size: 12.9 MB
- Stars: 335
- Watchers: 14
- Forks: 41
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Generative Models Tutorial
Generative models are interesting topic in ML. Generative models are a subset of unsupervised learning that generate new sample/data by using given some training data. There are different types of ways of modelling same distribution of training data: Auto-Regressive models, Auto-Encoders and GANs. In this tutorial, we are focusing theory of generative models, demonstration of generative models, important papers, courses related generative models. It will continue to be updated over time.
 [Blog Open-AI]
[Blog Open-AI]
**Keywords:** Bayesian Classifier Sampling, Variational Auto Encoder (VAE), Generative Adversial Networks (GANs), Popular GANs Architectures, Auto-Regressive Models, Important Generative Model Papers, Courses, etc..
**NOTE: This tutorial is only for education purpose. It is not academic study/paper. All related references are listed at the end of the file.**
# Table Of Content
- [What is Generative Models?](#whatisGM)
- [Preliminary (Recall)](#Preliminary)
- [Sampling from Bayesian Classifier](#BayesianClassifier)
- [Unsupervised Deep Learning vs Supervised Deep Learning (Recall)](#UDLvsSDL)
- [Gaussian Mixture Model (GMM)](#GMM)
- [Expectation-Maximization (EM)](#EM)
- [AutoEncoders](#AutoEncoders)
- [Variational Inference (VI)](#VI)
- [Variational AutoEncoder (VAE)](#VAE)
- [Latent Space](#LatentSpace)
- [Cost Function of VAE](#CostFunctionofVAE)
- [Generative Adversial Networks (GANs)](#GANs)
- [GANs Cost Function](#GANsCostFunction)
- [Discriminator Cost Function](#DiscriminatorCost)
- [Generator Cost Function](#GeneratorCost)
- [DCGAN](#DCGAN)
- [Fractionally-Strided Convolution](#FractionallyStridedConvolution)
- [CycleGAN](#CycleGAN)
- [Pix2Pix](#Pix2Pix)
- [PixelDTGAN](#PixelDTGAN)
- [PoseGuided](#PoseGuided)
- [SRGAN](#SRGAN)
- [StackGAN](#StackGAN)
- [TPGAN](#TPGAN)
- [Anime Generation](#AnimeGeneration)
- [3DGAN](#3DGAN)
- [Age-cGAN](#AgecGAN)
- [AnoGAN](#AnoGAN)
- [DiscoGAN](#DiscoGAN)
- [DTN](#DTN)
- [IcGAN](#IcGAN)
- [MGAN](#MGAN)
- [MidiNet](#MidiNet)
- [PerceptualGAN](#PerceptualGAN)
- [Auto-Regressive Models](#AutoRegressiveModels)
- [PixelRNN](#PixelRNN)
- [PixelCNN](#PixelCNN)
- [PixelCNN++](#PixelCNNPlus)
- [Generative Model in Reinforcement Learning](#GenerativeModelInRL)
- [Generative Adversarial Imitation Learning](#GenerativeAdversarialImitation)
- [Important Papers](#ImportantPapers)
- [Courses](#Courses)
- [References](#References)
- [Notes](#Notes)
## What is Generative Models?
- Generative models are a subset of unsupervised learning that generate new sample/data by using given some training data (from same distribution). In our daily life, there are huge data generated from electronic devices, computers, cameras, iot, etc. (e.g. millions of images, sentences, or sounds, etc.)
- In generative models, a large amount of data in some domain firstly is collected and then model is trained with this large amount of data to generate data like it.
- There are [lots of applications](https://medium.com/@jonathan_hui/gan-some-cool-applications-of-gans-4c9ecca35900) for generative models:
- Image Denoising,
- Image Enhancement,
- [Image Inpainting](https://github.com/pathak22/context-encoder),
- [Super-resolution (upsampling): SRGAN](https://arxiv.org/pdf/1609.04802.pdf),
- [Generate 3D objects: 3DGAN](http://papers.nips.cc/paper/6096-learning-a-probabilistic-latent-space-of-object-shapes-via-3d-generative-adversarial-modeling.pdf), [Video](https://youtu.be/HO1LYJb818Q)
- Creating Art:
- [Create Anime Characters](https://arxiv.org/pdf/1708.05509.pdf)
- [Transform images from one domain (say real scenery) to another domain (Monet paintings or Van Gogh):CycleGAN](https://github.com/junyanz/CycleGAN)
- [Creating Emoji: DTN](https://arxiv.org/pdf/1611.02200.pdf)
- [Pose Guided Person Image Generation](https://papers.nips.cc/paper/6644-pose-guided-person-image-generation.pdf)
- [Creating clothing images and styles from an image: PixelDTGAN](https://arxiv.org/pdf/1603.07442.pdf)
- [Face Synthesis: TP-GAN](https://arxiv.org/pdf/1704.04086.pdf)
- [Image-to-Image Translation: Pix2Pix](https://github.com/phillipi/pix2pix)
- Labels to Street Scene
- Aerial to Map
- Sketch to Realistic Image
- [High-resolution Image Synthesis](https://tcwang0509.github.io/pix2pixHD/)
- [Text to image: StackGAN](https://github.com/hanzhanggit/StackGAN), [Paper](https://arxiv.org/pdf/1612.03242v1.pdf)
- [Text to Image Synthesis](https://arxiv.org/pdf/1605.05396.pdf)
- [Learn Joint Distribution: CoGAN](https://arxiv.org/pdf/1606.07536.pdf)
- [Transfering style (or patterns) from one domain (handbag) to another (shoe): DiscoGAN](https://github.com/carpedm20/DiscoGAN-pytorch)
- [Texture Synthesis: MGAN](https://arxiv.org/pdf/1604.04382.pdf)
- [Image Editing: IcGAN](https://github.com/Guim3/IcGAN)
- [Face Aging: Age-cGAN](https://arxiv.org/pdf/1702.01983.pdf)
- [Neural Photo Editor](https://github.com/ajbrock/Neural-Photo-Editor)
- [Medical (Anomaly Detection): AnoGAN](https://arxiv.org/pdf/1703.05921.pdf)
- [Music Generation: MidiNet](https://arxiv.org/pdf/1703.10847.pdf)
- [Video Generation](https://youtu.be/Pt1W_v-yQhw)
- [Image Blending: GP-GAN](https://github.com/wuhuikai/GP-GAN)
- [Object Detection: PerceptualGAN](https://arxiv.org/pdf/1706.05274v2.pdf)
- Natural Language:
- Artical Spinning
- Generative models are also promising in the long term future because it has a potential power to learn the natural features of a dataset automatically.
- Generative models are mostly used to generate images (vision area). In the recent studies, it will also used to generate sentences (natural language processing area).
- It can be said that Generative models begins with sampling. Generative models are told in this tutorial according to the development steps of generative models: Sampling, Gaussian Mixture Models, Variational AutoEncoder, Generative Adversial Networks.
## Preliminary (Recall)
- **Bayesian Rule**: p(z|x)= p(x|z) p(z) /p(x)
- **Prior Distribution**: "often simply called the prior, of an uncertain quantity is the probability distribution that would express one's beliefs about this quantity before some evidence is taken into account." (e.g. p(z))
- **Posterior Distribution:** is a probability distribution that represents your updated beliefs about the parameter after having seen the data. (e.g. p(z|x))
- **Posterior probability = prior probability + new evidence (called likelihood)**
- **Probability Density Function (PDF)**: the set of possible values taken by the random variable
- **Gaussian (Normal) Distribution**: A symmetrical data distribution, where most of the results lie near the mean.
- **Bayesian Analysis**:
- Prior distribution: p(z)
- Gather data
- "Update your prior distribution with the data using Bayes' theorem to obtain a posterior distribution."
- "Analyze the posterior distribution and summarize it (mean, median, etc.)"
- It is expected that you have knowledge of neural network concept (gradient descent, cost function, activation functions, regression, classification)
- Typically used for regression or classification
- Basically: fit(X,Y) and predict(X)
## Sampling from Bayesian Classifier
- We use sampling data to generate new samples (using distribution of the training data).
- If we know the probability distribution of the training data , we can sample from it.
- Two ways of sampling:
- **First Method**: Sample from a given digit/class
- Pick a class, e.g. y=2
- If it is known p(x|y=2) is Gaussian
- Sample from this Gaussian using Scipy (mvn.rvs(mean,cov))
- **Second Method**: Sample from p(y)p(x|y) => p(x,y)
- If there is graphical model (e.g. y-> x), and they have different distribution,
- If p(y) and p(x|y) are known and y has its own distribution (e.g. categorical or discrete distribution)
- Sample
## Unsupervised Deep Learning vs Supervised Deep Learning (Recall)
- **Unsupervised Deep Learning**: trying to learn structure of inputs
- **Example1**: If the structure of poetry/text can be learned, it is possible to generate text/poetry that resembles the given text/poetry.
- **Example2**: If the structure of art can be learned, it is possible to make new art/drawings that resembles the given art/drawings.
- **Example3**: If the structure of music can be learned, it is possible to create new music that resembles the given music.
- **Supervised Deep Learning**: trying to map inputs to targets
## Gaussian Mixture Model (GMM)
- Single gaussian model learns blurry images if there are more than one gaussian distribution (e.g. different types of writing digits in handwriting).
- To get best result, GMM have to used to model more than one gaussian distribution.
- GMM is latent variable model. With GMM, multi-modal distribution can be modelled at the same time.
- Multiple gaussians in different proportions are fitted into the GMM.
- 2 clusters: p(x)=p(z=1) p(x|z=1) + p(z=2) p(x|z=2). In figure, there are 2 different proportions gaussian distributions.
 [Udemy GAN-VAE]
[Udemy GAN-VAE]
### Expectation-Maximization (EM)
- GMM is trained using Expectation-Maximization (EM)
- EM is iterative algorithm that let the likelihood improves at each step.
- The aim of EM is to reach maximum likelihood.
## AutoEncoders
- A neural network that predicts (reconstructs) its own input.
- It is a feed forward network.
- W: weight, b:bias, x:input, f() and g():activation functions, z: latent variable, x_hat= output (reconstructed input)

- Instead of fit(X,Y) like neural networks, autoencoders fit(X,X).
- It has 1 input, 1 hidden, 1 output layers (hidden layer size < input layer size; input layer size = output layer size)
- It forces neural network to learn compact/efficient representation (e.g. dimension reduction/ compression)
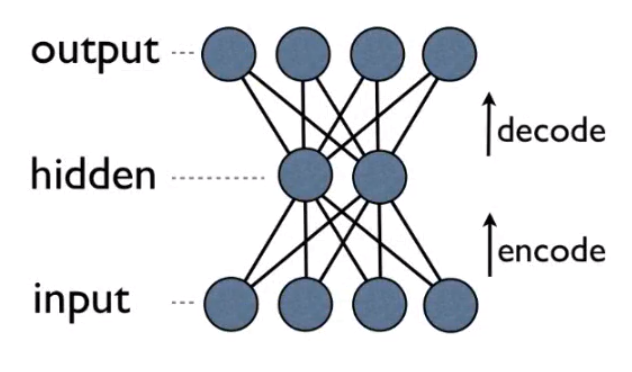 [Udemy GAN-VAE]
[Udemy GAN-VAE]
## Variational Inference (VI)
- Variational inference (VI) is the significant component of Variational AutoEncoders.
- VI ~ Bayesian extension of EM.
- In GMM/K-Means Clustering, you have choose the number of clusters.
- VI-GMM (Variational inference-Gaussian Mixture Model) automatically finds the number of cluster.
[Udemy GAN-VAE]
## Variational AutoEncoder (VAE)
- VAE is a neural network that learns to generate its input.
- It can map data to latent space, then generate samples using latent space.
- VAE is combination of autoencoders and variational inference.
- It doesn't work like tradional autoencoders.
- Its output is the parameters of a distribution: mean and variance, which represent a Gaussian-PDF of Z (instead only one value)
- VAE consists of two units: Encoder, Decoder.
- The output of encoder represents Gaussian distributions.(e.g. In 2-D Gaussian, encoder gives 2 mean and 2 variance/stddev)
- The output of decoder represents Bernoulli distributions.
- From a probability distribution, new samples can be generated.
- For example: let's say input x is a 28 by 28-pixel photo
- The encoder ‘encodes’ the data which is 784-dimensional into a latent (hidden) representation space z.
- The encoder outputs parameters to q(z∣x), which is a Gaussian probability density.
- The decoder gets as input the latent representation of a digit z and outputs 784 Bernoulli parameters, one for each of the 784 pixels in the image.
- The decoder ‘decodes’ the real-valued numbers in z into 784 real-valued numbers between 0 and 1.
 [Udemy GAN-VAE]
### Latent Space
- Encoder: x-> q(z) {q(z): latent space, coded version of x}
- Decoder: q(z)~z -> x_hat
- Encoder takes the input of image "8" and gives output q(z|x).
- Sample from q(z|x) to get z
- Get p(x_hat|x), sample from it (this is called posterior predictive sample)
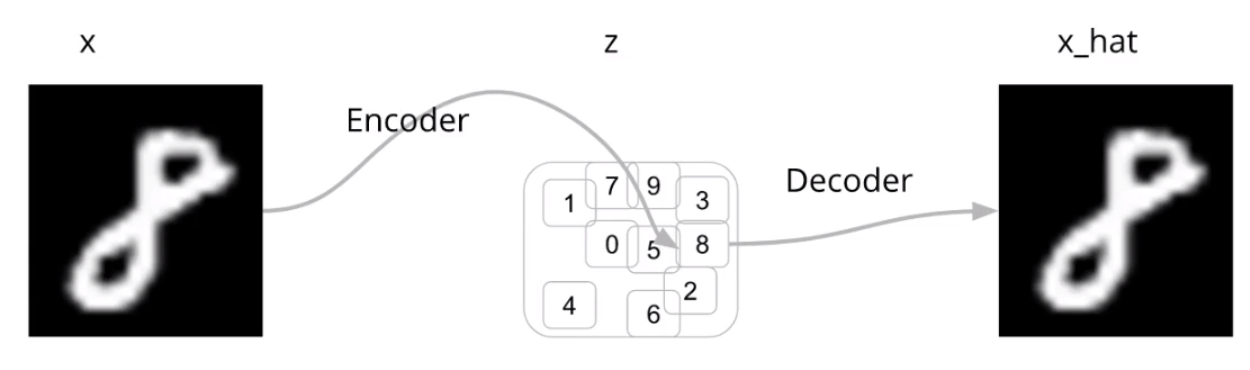
### Cost Function of VAE
- Evidence Lower Bound (ELBO) is our objective function that has to be maximized.
- ELBO consists of two terms: Expected Log-Likelihood of the data and KL divergence between q(z|x) and p(z).
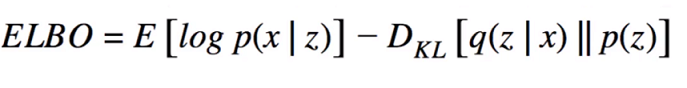
- Expected Log-Likelihood is negative cross-entropy between original data and recontructed data.
- "Expected Log-Likelihood encourages the decoder to learn to reconstruct the data. If the decoder’s output does not reconstruct the data well, it will incur a large cost in this loss function".
- If the input and output have Bernoulli distribution, Expected Log-Likelihood can be calculated like this:
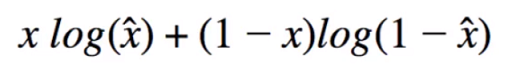
- "KL divergence measures how much information is lost (in units of nats) when using q to represent p. It is one measure of how close q is to p".
- KL divergence provides to compare 2 probability distributions.
- If the two probability distributions are exactly same (q=p), KL divergence equals to 0.
- If the two probability distributions are not same (q!=p), KL divergence > 0 .
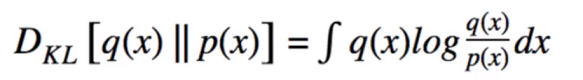
- Cost function consists of two part: How the model's output is close to target and regularization.
- COST = (TARGET-OUTPUT) PENALTY-REGULARIZATION PENALTY == RECONSTRUCTION PENALTY - REGULARIZATION PENALTY
## Generative Adversial Networks (GANs)
- GANs are interesting because it generates samples exceptionally good.
- GANs are used in different applications (details are summarized following sections).
- GANs are different form other generative models (Bayesian Classifier, Variational Autoencoders, Restricted Boltzmann Machines). GANs are not dealing with explicit probabilities, instead, its aim is to reach Nash Equilibrium of a game.
- RBM generate samples with Monte Carlo Sampling (thousands of iterations are needed to generate, and how many iterations are needed is not known). GANs generate samples with in single pass.
- There are 2 different networks in GANs: generator and discriminator, compete against each other.
- Generator Network tries to fool the discriminator.
- Disciminator Network tries not to be fooled.
- Paper: Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, [Generative Adversarial Networks](https://arxiv.org/abs/1406.2661)
 [Blog Open-AI]
[Blog Open-AI]
#### Discriminator Cost Function
- Generator and Discriminator try to optimize the opposite cost functions.
- Discriminator classifies images as a real or fake images with binary classification.
- t: target; y: output probability of the discriminator.
- Real image: t=1; fake image: t=0; y= p(image is real | image) between (0,1)
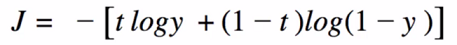
- Binary cost function evaluates discriminator cost function.
- x: real images only, x_hat: fake images only
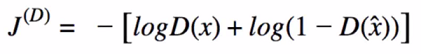
- G(z): fake image from generator, x: real image
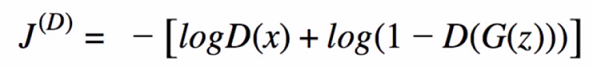
- Total cost: summing to individual negative log-likelihoods (batches of data in training)
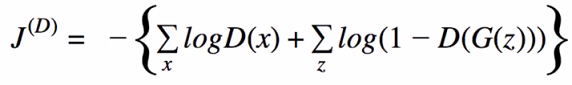
- Estimate of the expected value over all possible data
- Discrimator Cost Function:
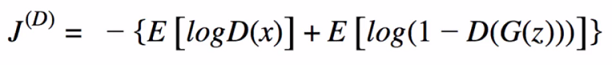
#### Generator Cost Function
- Relation between Generator and Discriminator Cost Functions:
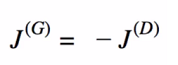
- In game theory, this situation is called "zero-sum game". Sum of all players in the game is 0.
- Theta_G: parameters of generator; Theta_D: parameters of discriminator
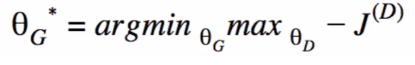
- Pseudocode of GANs:
- In the first step: Generator generates some of the real samples and fake samples.
- In the second step: Gradient descent of the discriminator is run one iteration.
- In the third step: Gradient descent of the generator is run one iteration.
- Repeat this until seeing the good samples.
- Some of the researches run third step twice to get better results.

### DCGAN
- Paper: Radford, A., Metz, L., and Chintala, S., [Unsupervised representation learning with deep convolutional generative adversarial networks](https://arxiv.org/abs/1511.06434v2)
- DCGAN architecture produces high quality and high resolution images in a single pass.
- DCGANs contain batch normalization (batch norm: z=(x-mean)/std, batch norm is used between layers).
- DCGANs also contain only all-convolutional layers instead of contaning convolution, pooling, linear layers together.
- It optimizes using ADAM optimizer (adaptive gradient desdent algorithm)
- Discriminator uses Leaky-ReLU (Rectified Linear Unit), generator uses normal ReLU.
 [Udemy GAN-VAE]
- Typical Convolution: input size is bigger or equal than output size (Stride>1).
- Deconvolution: input size is smaller than output size (Stride<1).
#### Fractionally-Strided Convolution
- Stride size is smaller than 1.
- If stride=2 is used while convolution operation, output image size is 1/2 original image size.
- If stride=1/2 is used while convolution operation, output image size is 2x original image size.
- With fractionally-strided convolution (deconvolution), output image size is bigger than input image size.
### CycleGAN
- [Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks](https://arxiv.org/pdf/1703.10593.pdf)
- Their algorithm translate an image from one to another:
- Transfer from Monet paintings to landscape photos from Flickr, and vice versa.
- Transfer from zebras to horses, and vice versa.
- Transfer from summer to winter photos, and vice versa.
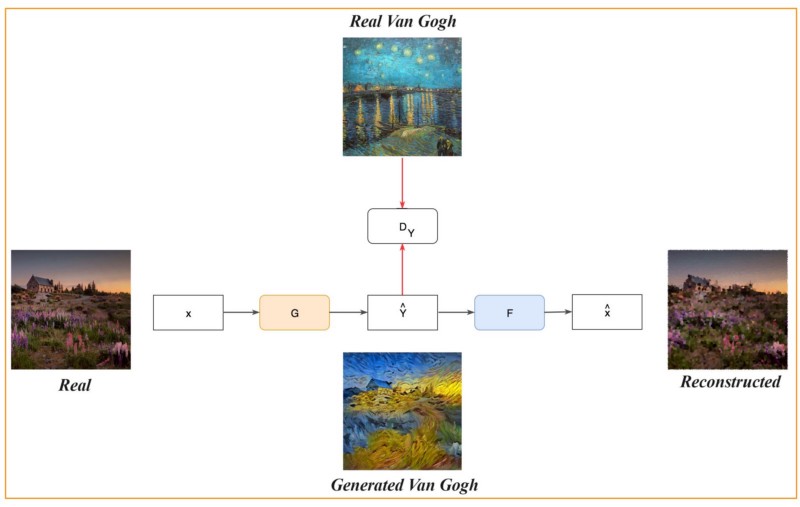
### Pix2Pix
- [Image-to-Image Translation with Conditional Adversarial Networks](https://arxiv.org/pdf/1611.07004.pdf)
- Pix2Pix is an image-to-image translation algorithm: aerials to map, labels to street scene, labels to facade, day to night, edges to photo.

### PixelDTGAN
- [Pixel-Level Domain Transfer](https://arxiv.org/pdf/1603.07442.pdf)
- PixelDTGAN generates clothing images from an image.
- "The model transfers an input domain to a target domain in semantic level, and generates the target image in pixel level."
- "They verify their model through a challenging task of generating a piece of clothing from an input image of a dressed person"
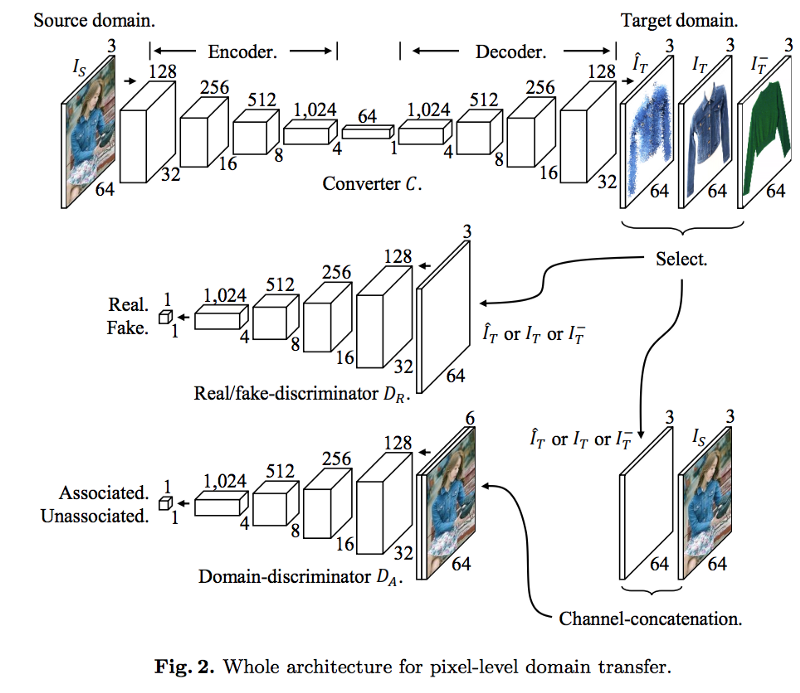
### PoseGuided
- [Pose Guided Person Image Generation](https://papers.nips.cc/paper/6644-pose-guided-person-image-generation.pdf)
- "This paper proposes the novel Pose Guided Person Generation Network (PG2 that allows to synthesize person images in arbitrary poses, based on an image of that person and a novel pose"
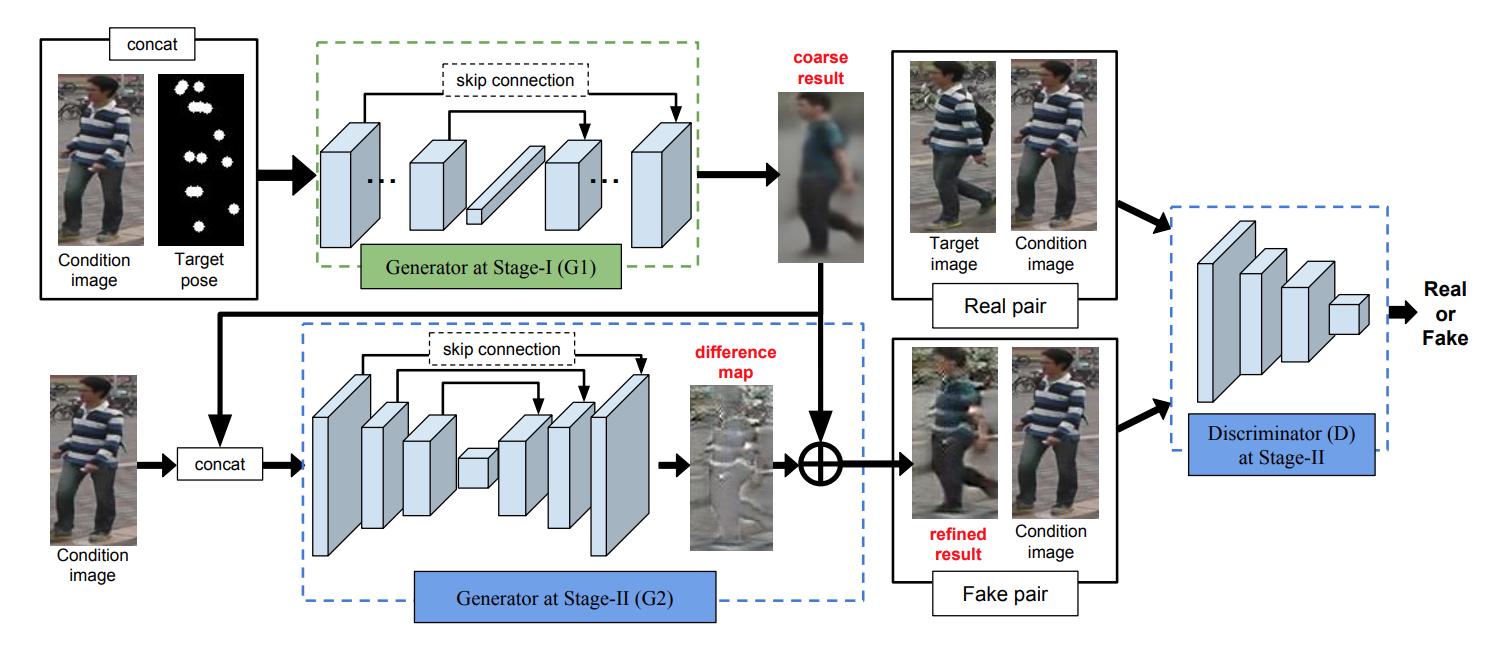
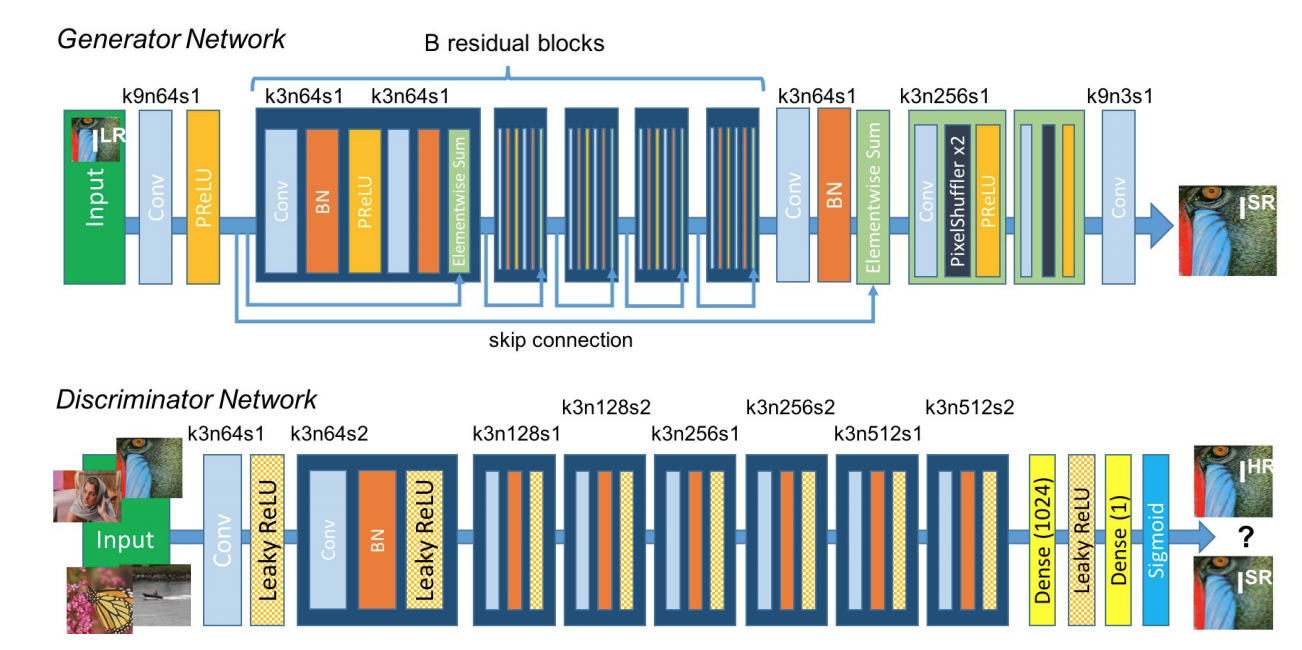
### SRGAN
- [Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network](https://arxiv.org/pdf/1609.04802.pdf)
- SRGAN: "a generative adversarial network (GAN) for image super-resolution (SR)"
- They generate super-resolution images from the lower resolution images.
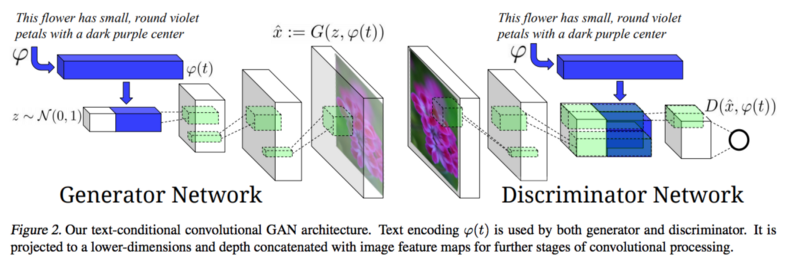
### StackGAN
- [StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks](https://arxiv.org/pdf/1612.03242v1.pdf)
- Stacked Generative Adversarial Networks (Stack-GAN): "to generate photo-realistic images conditioned on text descriptions".
- Input: sentence, Output: multiple images fitting the description.
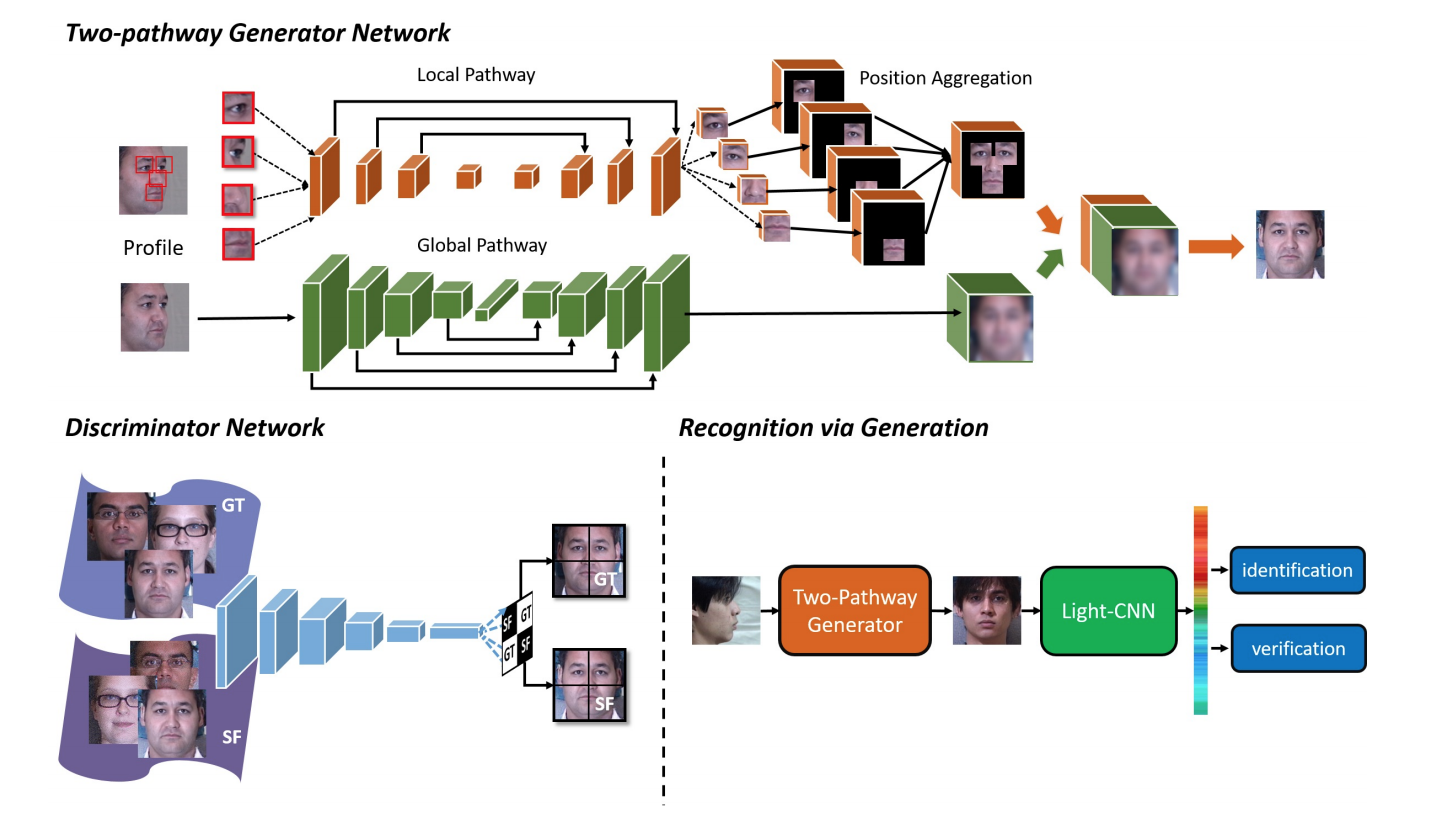
### TPGAN
- [Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis](https://arxiv.org/pdf/1704.04086.pdf)
- "Synthesis faces in different poses: With a single input image, they create faces in different viewing angles."
### Anime Generation
- [Towards the Automatic Anime Characters Creation with Generative Adversarial Networks](https://arxiv.org/pdf/1708.05509.pdf)
- "They explore the training of GAN models specialized on an anime facial image dataset."
- They build website for their implementation (https://make.girls.moe)
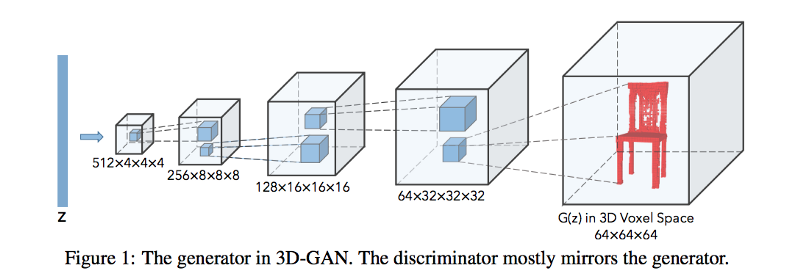
### 3DGAN
- [Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling](http://papers.nips.cc/paper/6096-learning-a-probabilistic-latent-space-of-object-shapes-via-3d-generative-adversarial-modeling.pdf)
- This paper proposed creating 3D objects with GAN.
- "They demonstrated that their models are able to generate novel objects and to reconstruct 3D objects from images"
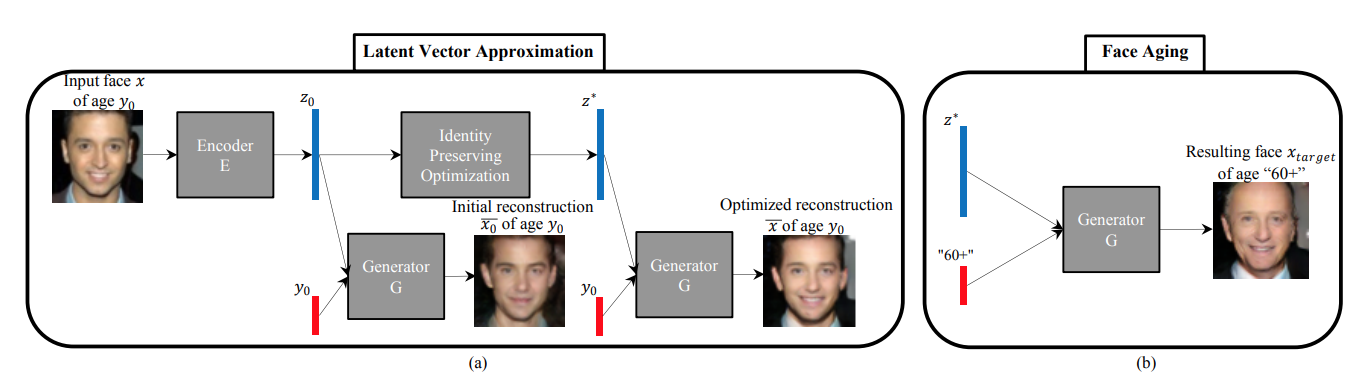
### Age-cGAN
- [FACE AGING WITH CONDITIONAL GENERATIVE ADVERSARIAL NETWORKS](https://arxiv.org/pdf/1702.01983.pdf)
- They proposed the GAN-based method for automatic face aging.
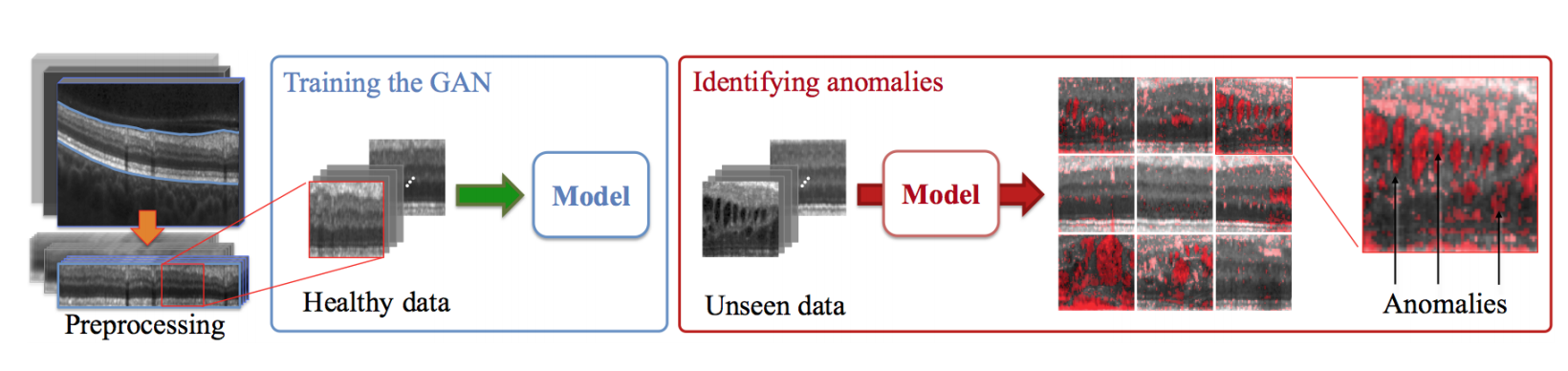
### AnoGAN
- [Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery](https://arxiv.org/pdf/1703.05921.pdf)
- "A deep convolutional generative adversarial network to learn a manifold of normal anatomical variability".
### DiscoGAN
- [Learning to Discover Cross-Domain Relations with Generative Adversarial Networks](https://arxiv.org/pdf/1703.05192.pdf)
- Proposed method transfers style from one domain to another (e.g handbag -> shoes)
- "DiscoGAN learns cross domain relationship without labels or pairing".

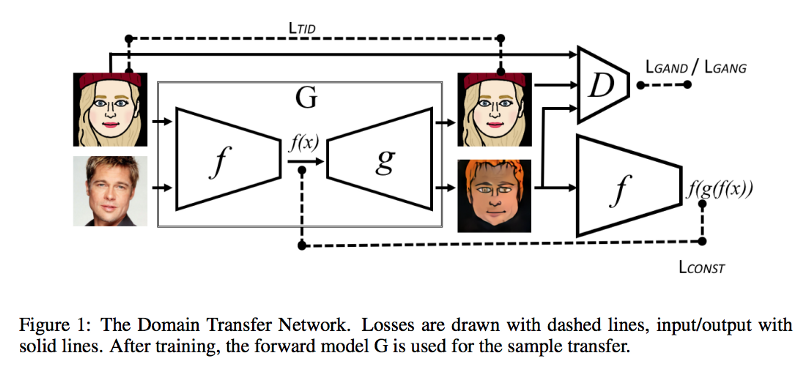
### DTN
- [Unsupervised Cross-Domain Image Generation](https://arxiv.org/pdf/1611.02200.pdf)
- Proposed method is to create emoji from pictures.
- "They can synthesize an SVHN image that resembles a given MNIST image, or synthesize a face that matches an emoji."
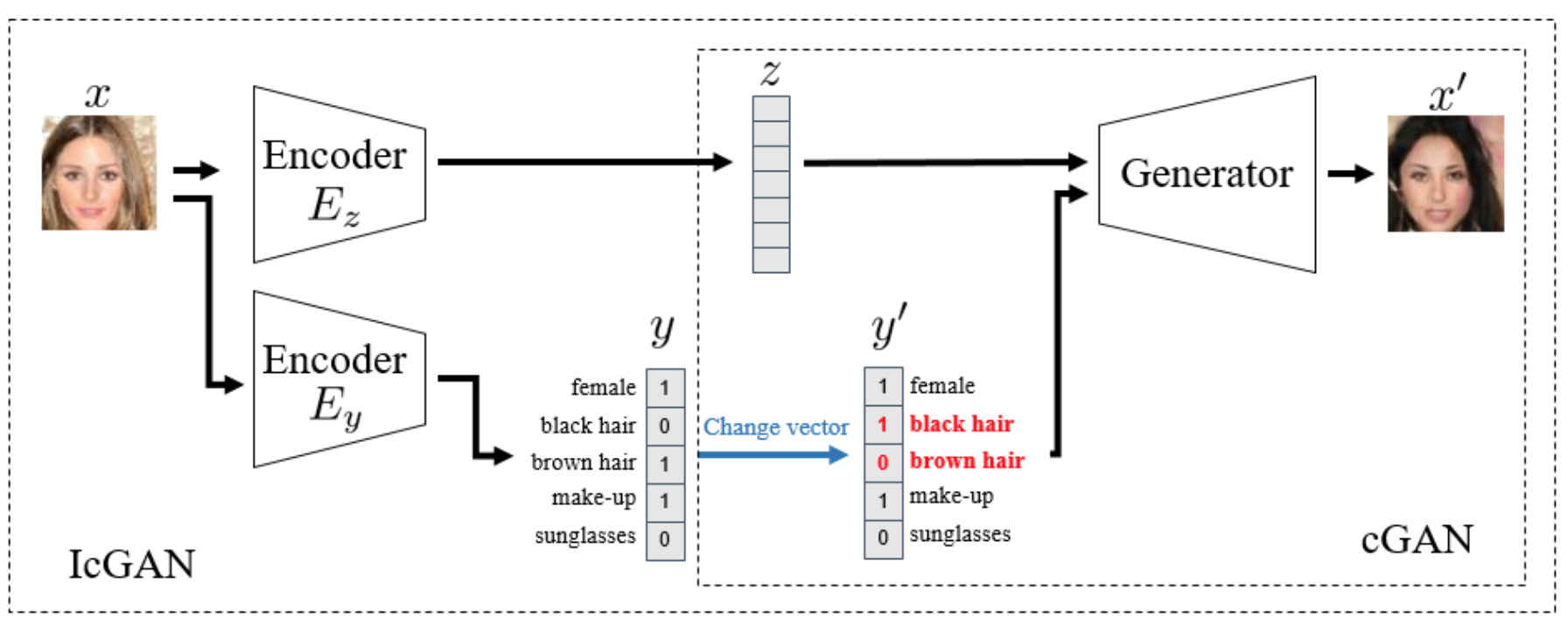
### IcGAN
- [Invertible Conditional GANs for image editing](https://arxiv.org/pdf/1611.06355.pdf)
- "They evaluate encoders to inverse the mapping of a cGAN, i.e., mapping a real image into a latent space and a conditional representation".
- Proposed method is to reconstruct or edit images with specific attribute.
### MGAN
- [Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks](https://arxiv.org/pdf/1604.04382.pdf)
- "Markovian Generative Adversarial Networks (MGANs), a method for training generative neural networks for
efficient texture synthesis."
- "They apply this idea to texture synthesis, style transfer, and video stylization."

### MidiNet
- [MIDINET: A CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORK FOR SYMBOLIC-DOMAIN MUSIC GENERATION](https://arxiv.org/pdf/1703.10847.pdf)
- "They propose a novel conditional mechanism to exploit available prior knowledge, so that the model can generate melodies either from scratch, by following a chord sequence, or by conditioning on the melody of previous bars"
- "MidiNet can be expanded to generate music with multiple MIDI channels"
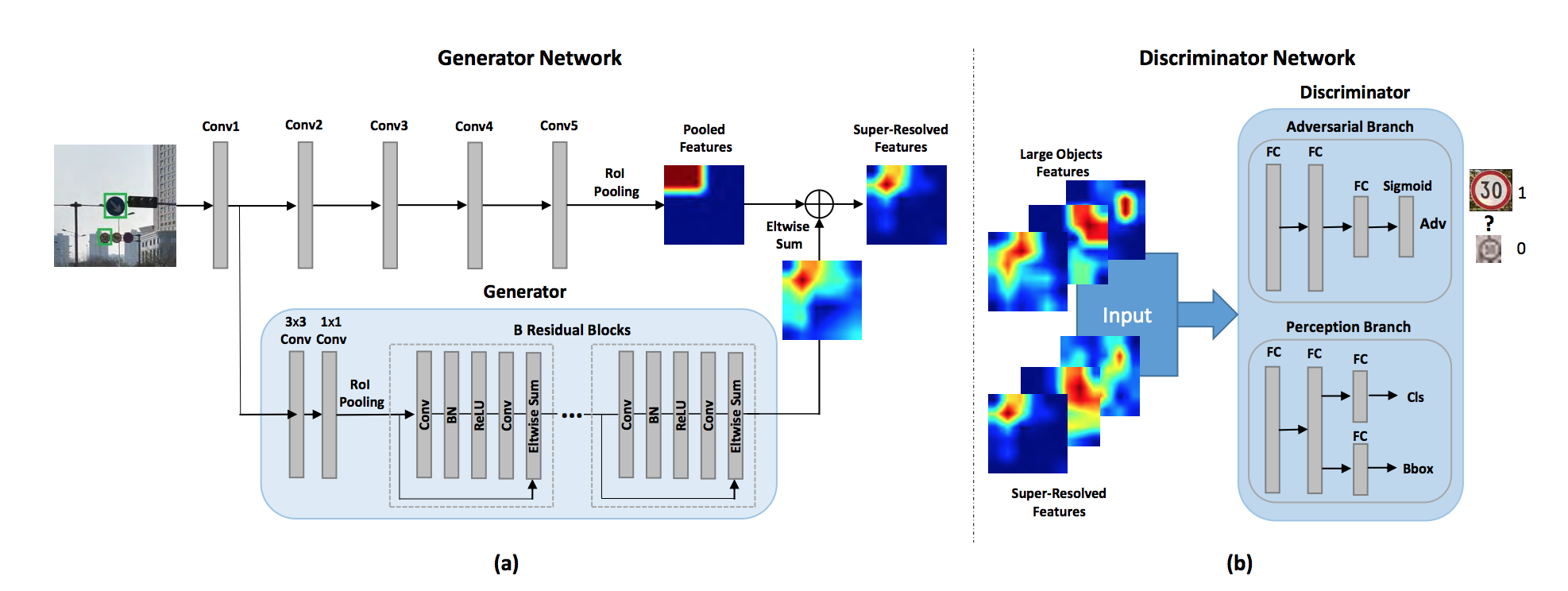
### PerceptualGAN
- [Perceptual Generative Adversarial Networks for Small Object Detection](https://arxiv.org/pdf/1706.05274v2.pdf)
- "Proposed method improves small object detection through narrowing representation difference of small objects from the large ones"
## Auto-Regressive Models
- "The basic difference between Generative Adversarial Networks (GANs) and Auto-regressive models is that GANs learn implicit data distribution whereas the latter learns an explicit distribution governed by a prior imposed by model structure" [Sharma].
- Some of the advantages of Auto-Regressive Models over GANs:
- **Provides a way to calculate likelihood**: They have advantage of returning explicit probability densities. Hence it can be applied in the application areas related compression and probabilistic planning and exploration.
- **The training is more stable than GANs**:"Training a GAN requires finding the Nash equilibrium". Training of PixelRNN, PixelCNN are more stable than GANs.
- **It works for both discrete and continuous data**:"It’s hard to learn to generate discrete data for GAN, like text" [Sharma].
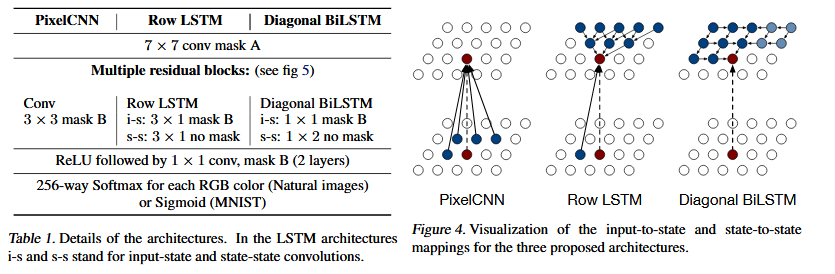
### PixelRNN
Paper: Oord et al., [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759.pdf) (proposed from Google DeepMind)
- It is used for image completion applications.
- "It uses probabilistic density models (like Gaussian or Normal distribution) to quantify the pixels of an image as a product of conditional distributions."
- "This approach turns the modeling problem into a sequence problem wherein the next pixel value is determined by all the previously generated pixel values".
- There are four different methods to implement PixelRNN:
- Row LSTM
- Diagonal BiLSTM
- Fully Convolutional Network
- Multi Scale Network.
- Cost function: "Negative log likelihood (NLL) is used as the loss and evaluation metric as the network predicts(classifies) the values of pixel from values 0–255."
### PixelCNN
- Papers: Oord et al., [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759.pdf); Oord et al., [Conditional Image Generation with PixelCNN Decoders](https://arxiv.org/pdf/1606.05328.pdf) (proposed from Google DeepMind).
- "The main drawback of PixelRNN is that training is very slow as each state needs to be computed sequentially. This can be overcome by using convolutional layers and increasing the receptive field."
- "PixelCNN lowers the training time considerably as compared to PixelRNN."
- "The major drawback of PixelCNN is that it’s performance is worse than PixelRNN. Another drawback is the presence of a Blind Spot in the receptive field"
### PixelCNN++
- Paper: Salimans et al.,[PIXELCNN++: IMPROVING THE PIXEL CNN WITH DISCRETIZED LOGISTIC MIXTURE LIKELIHOOD AND OTHER MODIFICATIONS](https://arxiv.org/pdf/1701.05517.pdf)
- PixelCNN++ improves the performance of PixelCNN (proposed from OpenAI)
- Modifications:
- Discretized logistic mixture likelihood
- Conditioning on whole pixels
- Downsampling
- Short-cut connections
- Dropout
- "PixelCNN++ outperforms both PixelRNN and PixelCNN by a margin. When trained on CIFAR-10 the best test log-likelihood is 2.92 bits/pixel as compared to 3.0 of PixelRNN and 3.03 of gated PixelCNN."
- Details are in the paper [PIXELCNN++: IMPROVING THE PIXEL CNN WITH DISCRETIZED LOGISTIC MIXTURE LIKELIHOOD AND OTHER MODIFICATIONS](https://arxiv.org/pdf/1701.05517.pdf).
## Generative Model in Reinforcement Learning
### Generative Adversarial Imitation Learning
Paper: Jonathan Ho, Stefano Ermon, [Generative Adversarial Imitation Learning](https://arxiv.org/abs/1606.03476)
- "The standard reinforcement learning setting usually requires one to design a reward function that describes the desired behavior of the agent. However, in practice this can sometimes involve expensive trial-and-error process to get the details right. In contrast, in imitation learning the agent learns from example demonstrations (for example provided by teleoperation in robotics), eliminating the need to design a reward function. This approach can be used to learn policies from expert demonstrations (without rewards) on hard OpenAI Gym environments, such as Ant and Humanoid." [Blog Open-AI].
- "Popular imitation approaches involve a two-stage pipeline: first learning a reward function, then running RL on that reward. Such a pipeline can be slow, and because it’s indirect, it is hard to guarantee that the resulting policy works well. This work shows how one can directly extract policies from data via a connection to GANs" [Blog Open-AI].
 [Blog Open-AI]
[Blog Open-AI]
## Important Papers
- Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, [Generative Adversarial Networks](https://arxiv.org/abs/1406.2661)
- Radford, A., Metz, L., and Chintala, S., [Unsupervised representation learning with deep convolutional generative adversarial networks](https://arxiv.org/abs/1511.06434v2)
- Jonathan Ho, Stefano Ermon, [Generative Adversarial Imitation Learning](https://arxiv.org/abs/1606.03476)
- Ledig et al., [Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network](https://arxiv.org/pdf/1609.04802.pdf),
- Jiajun Wu et al., [Learning a Probabilistic Latent Space of Object
Shapes via 3D Generative-Adversarial Modeling](http://papers.nips.cc/paper/6096-learning-a-probabilistic-latent-space-of-object-shapes-via-3d-generative-adversarial-modeling.pdf)
- Jin et al., [Towards the Automatic Anime Characters Creation with Generative Adversarial Networks](https://arxiv.org/pdf/1708.05509.pdf)
- Zhu et al., [Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks](https://arxiv.org/pdf/1703.10593.pdf)
- Taigman et al., [UNSUPERVISED CROSS-DOMAIN IMAGE GENERATION](https://arxiv.org/pdf/1611.02200.pdf)
- MA et al., [Pose Guided Person Image Generation](https://papers.nips.cc/paper/6644-pose-guided-person-image-generation.pdf)
- Yoo et al., [Pixel-Level Domain Transfer](https://arxiv.org/pdf/1603.07442.pdf)
- Huang aet al., [Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis](https://arxiv.org/pdf/1704.04086.pdf)
- Isola et al., [Image-to-Image Translation with Conditional Adversarial Networks](https://arxiv.org/pdf/1611.07004.pdf)
- Wang et al., [High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs](https://arxiv.org/pdf/1711.11585.pdf)
- Zhang et al., [StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks](https://arxiv.org/pdf/1612.03242v1.pdf)
- Reed et al., [Generative Adversarial Text to Image Synthesis](https://arxiv.org/pdf/1605.05396.pdf)
- Liu et al., [Coupled Generative Adversarial Networks](https://arxiv.org/pdf/1606.07536.pdf)
- Kim et al., [Learning to Discover Cross-Domain Relations with Generative Adversarial Networks](https://arxiv.org/pdf/1703.05192.pdf)
- Li et al., [Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks](https://arxiv.org/pdf/1604.04382.pdf)
- Perarnau et al., [Invertible Conditional GANs for image editing](https://arxiv.org/pdf/1611.06355.pdf)
- Antipov et al., [FACE AGING WITH CONDITIONAL GENERATIVE ADVERSARIAL NETWORKS](https://arxiv.org/pdf/1702.01983.pdf)
- Schlegl et al., [Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery](https://arxiv.org/pdf/1703.05921.pdf)
- Yang et al., [MIDINET: A CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORK FOR SYMBOLIC-DOMAIN MUSIC GENERATION](https://arxiv.org/pdf/1703.10847.pdf)
- Wu et al., [GP-GAN: Towards Realistic High-Resolution Image Blending](https://arxiv.org/pdf/1703.07195.pdf)
- Li et al., [Perceptual Generative Adversarial Networks for Small Object Detection](https://arxiv.org/pdf/1706.05274v2.pdf)
- Oord et al., [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759.pdf)
- Oord et al., [Conditional Image Generation with PixelCNN Decoders](https://arxiv.org/pdf/1606.05328.pdf)
- Salimans et al.,[PIXELCNN++: IMPROVING THE PIXEL CNN WITH DISCRETIZED LOGISTIC MIXTURE LIKELIHOOD AND OTHER MODIFICATIONS](https://arxiv.org/pdf/1701.05517.pdf)
- Springenberg et al., [Striving for Simplicity: The All Convolutional Net](https://arxiv.org/abs/1412.6806)
## Courses
- [Stanford Generative Model Video](https://www.youtube.com/watch?v=5WoItGTWV54)
- [Udemy GAN-VAE: Deep Learning GANs and Variational Autoencoders](https://www.udemy.com/deep-learning-gans-and-variational-autoencoders/learn/v4/t/lecture/7494546?start=0)
## References
- [Blog Open-AI](https://blog.openai.com/generative-models/#going-forward)
- [Sharma, PixelRNN/PixelCNN](https://towardsdatascience.com/auto-regressive-generative-models-pixelrnn-pixelcnn-32d192911173)
- [Udemy GAN-VAE: Deep Learning GANs and Variational Autoencoders](https://www.udemy.com/deep-learning-gans-and-variational-autoencoders/learn/v4/t/lecture/7494546?start=0)
- [GAN Applications](https://medium.com/@jonathan_hui/gan-some-cool-applications-of-gans-4c9ecca35900)
- https://jaan.io/what-is-variational-autoencoder-vae-tutorial/
## Notes
- [Tensorflow-Generative-Model-Collections-Codes](https://github.com/hwalsuklee/tensorflow-generative-model-collections)
- [GAN Applications](https://github.com/nashory/gans-awesome-applications)
- [GMM-Scikit Learn Library](https://scikit-learn.org/stable/modules/mixture.html)