Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/omerbsezer/MusicGeneration
Music generation with LSTM model (Keras)
https://github.com/omerbsezer/MusicGeneration
deep-learning lstm-neural-networks music-generation
Last synced: about 1 month ago
JSON representation
Music generation with LSTM model (Keras)
- Host: GitHub
- URL: https://github.com/omerbsezer/MusicGeneration
- Owner: omerbsezer
- Archived: true
- Created: 2018-08-12T14:19:19.000Z (about 6 years ago)
- Default Branch: master
- Last Pushed: 2018-08-19T20:32:48.000Z (about 6 years ago)
- Last Synced: 2024-04-06T19:32:19.680Z (5 months ago)
- Topics: deep-learning, lstm-neural-networks, music-generation
- Language: Python
- Homepage:
- Size: 108 KB
- Stars: 3
- Watchers: 3
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Music Generation
With trained DL model (LSTM), new sequences of time series data can be predicted. In this project, it will be implemented a model which inputs a sample jazz music and samples/generates a new music. Code is adapted from Andrew Ng's Course 'Sequential models'.
## Run
* To run code, download music21 toolkit from [http://web.mit.edu/music21/](http://web.mit.edu/music21/). "pip install music21".
* Run main.py
## Input File and Parameters
Model is trained with "data/original_music"
* "X, Y, n_values, indices_values = load_music_utils()"
* Number of training examples: 60,
* Each of training examples length of sequence:30
* Our music generation system will use 78 unique values.
* X: This is an (m, Tx , 78) dimensional array. We have m training examples, each of which is a snippet of Tx=30Tx=30 musical values. At each time step, the input is one of 78 different possible values, represented as a one-hot vector. Thus for example, X[i,t,:] is a one-hot vector representating the value of the i-th example at time t.
* Y: This is essentially the same as X, but shifted one step to the left (to the past).
* n_values: The number of unique values in this dataset. This should be 78.
* indices_values: python dictionary mapping from 0-77 to musical values.
## LSTM Model
LSTM model structure is:
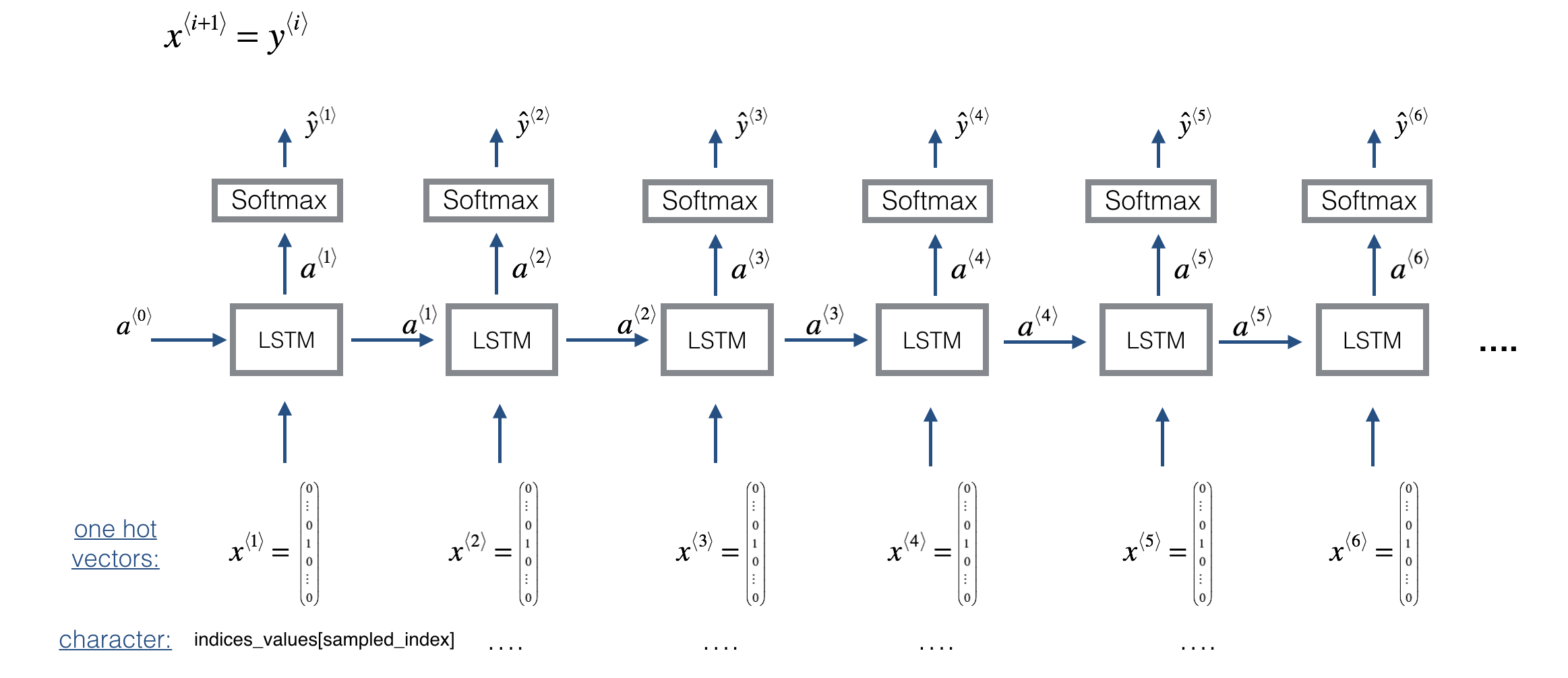
Model is implemented with "djmodel(Tx, n_a, n_values)" function.
## Predicting and Sampling
Adding model, predicting and sampling feature, model structure is:

Music Inference Model is similar trained model and it is implemented with "music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100)" function. Music is generated with "redict_and_sample" function.
Finally, your generated music is saved in output/my_music.midi.
## References
* Andrew Ng, Sequential Models Course, Deep Learning Specialization