https://github.com/omicsdi/specifications
Description about the resource, file formats, etc
https://github.com/omicsdi/specifications
new-use-cases omicsdi-architecture omicsdi-xml specifications
Last synced: 5 months ago
JSON representation
Description about the resource, file formats, etc
- Host: GitHub
- URL: https://github.com/omicsdi/specifications
- Owner: OmicsDI
- Created: 2015-03-09T15:05:56.000Z (over 11 years ago)
- Default Branch: master
- Last Pushed: 2022-04-21T19:58:13.000Z (about 4 years ago)
- Last Synced: 2025-02-05T15:17:55.850Z (over 1 year ago)
- Topics: new-use-cases, omicsdi-architecture, omicsdi-xml, specifications
- Homepage:
- Size: 42.3 MB
- Stars: 9
- Watchers: 16
- Forks: 5
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Omics Discovery Index
[](https://gitter.im/PSI-PROXI/datadiscoveryindex?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
OmicsDI
=========
Contents
----------
1. [Essentials](#1-essentials)
1.1. [Objectives](#11-objectives)
1.2. [What is OmicsDI](#12-what-is-omicsdi)
* [Databases](#2-databases)
2.1. [Major Partners?](#21-major-partners)
2.2. [Which databases are part of OmicsDI](#22-which-databases-are-part-of-omicsdi)
2.3. [OmicsDI Architecture?](#23-Omicsdi-architecture)
2.4. [OmicsDI XML](#24-omicsDI-xml)
* [Web services and Web Application](#3-web-services-and-web-application)
3.1. [Access to the web-services](#31-access-to-the-web-services)
3.2. [Web Application](#32-web-application)
* [Support](#4-support)
3.1 [Get involved](#41-get-involved)
3.2. [Contact](#42-contact)
* [License](#5-license)
1. Essentials
--------------
### 1.1. Objectives
* Provide data discovery index for ‘omics’ datasets (genomics, proteomics and metabolomics).
* Integrate databases and repositories from the US and Europe.
* Provide the infrastructure to add new databases/repositories and to search, navigate, and find “high-quality”, relevant datasets.
### 1.2. What is OmicsDI?
In the age of systems biology and data integration, omics data (proteomics/genomics/metabolomics) represents an essential
component to understand the “whole picture” of life. Access to this data is now a crucial component in biomedical research and
requires substantial investment and infrastructure. Several public repositories have been developed, each with different
purposes in mind such as: [PRIDE] (http://www.ebi.ac.uk/pride/archive/), [PeptideAtlas] (http://www.peptideatlas.org/),
[MassIVE](http://massive.ucsd.edu/ProteoSAFe/), [Metaboligths](http://www.ebi.ac.uk/metabolights/), [Metabolomics Workbench](http://www.metabolomicsworkbench.org/),
[EGA](https://www.ebi.ac.uk/ega/). While there is often integration between repositories for the same data type, discovery
of datasets across multiple omics datatypes remains a tedious task requiring different query strategies across multiple
resources. The aim of OmicsDI is to address these issues by providing a central infrastructure for searching, storing
and visualizing omics datasets.
2. Databases
-------------
## 2.1. Major Partners
- **ProteomeXchange**: The ProteomeXchange Consortium is a collaboration of currently three major mass spectrometry proteomics
data repositories, PRIDE at EMBL-EBI in Cambridge (UK), PeptideAtlas at ISB in Seattle (US), and MassIVE at UCSD (US),
offering a unified data deposition and discovery strategy across all three repositories. ProteomeXchange is a distributed
database infrastructure; the potentially very large raw data component of the data is only held at the original submission
database, while the searchable metadata is centrally collected and indexed. All ProteomeXchange data is fully open after
release of the associated publication.
- **MetabolomeXchange**: MetabolomeXchange is a collaboration of 4 major metabolomics repositories, with a total of 10 partners
contributing. MetabolomeXchange was inspired by and is implementing similar coordination strategies to ProteomeXchange.
The founding partners are MetaboLights at EMBL-EBI(UK),Metabolomics Repository Bordeaux(FR), Golm Metabolome Database and
the Metabolomics Workbench (US). The Metabolomics Workbench is a NIH funded collaboration of 6 Regional Comprehensive
Metabolomics Resource Cores. MetabolomeXchange started accepting metadata submissions in summer 2014, and reached 200 public
datasets in March 2015.
- **The European Genome-Phenome Archive**: The European Genome-Phenome Archive (EGA) provides a service for the permanent
archiving and distribution of personally identifiable genetic and phenotypic data resulting from biomedical research projects.
Data at EGA was collected from individuals whose consent agreements authorise data release only for specific research use by
researchers. Strict protocols govern how information is managed, stored and distributed by the EGA project.
The EGA comprises a public metadata section, allowing searching and identifying relevant studies, and the controlled access
data section. Access to the data section for a particular study is only granted after validation of a research proposal through
the relevant ethics approval.
### 2.2. Which databases are part of OmicsDI?
Currently six different databases in two continents are part of the OmicsDI consortium:
- [PRIDE](http://www.ebi.ac.uk/pride/archive/): The **PR**oteomics **IDE**ntification database. (EMBL-EBI, UK)(Proteomics)
- [PeptideAtlas](http://www.peptideatlas.org/): A multi-organism, publicly accessible compendium of peptides identified in a large set of tandem mass spectrometry proteomics experiments. (System Biology Inst, Seattle, US)(Proteomics)
- [MassIVE](http://massive.ucsd.edu/ProteoSAFe/): The **Mass** spectrometry **I**nteractive **V**irtual **E**nvironment, is a community resource to promote the global, free exchange of mass spectrometry data. (UCSD, US)(Proteomics)
- [Metaboligths](http://www.ebi.ac.uk/metabolights/): The Metabolomics Database. (EMBL-EBI, UK)(Metabolomics)
- [Metabolomics Workbench](http://www.metabolomicsworkbench.org/): UCSD Metabolomics Workbench, a resource sponsored by the Common Fund of the National Institutes of Health. (UCSD, US) (Metabolomics)
- [EGA](https://www.ebi.ac.uk/ega/): The European Genome-phenome Archive. (EMBL-EBI, UK)(Genomics)
### 2.3. OmicsDI Architecture?
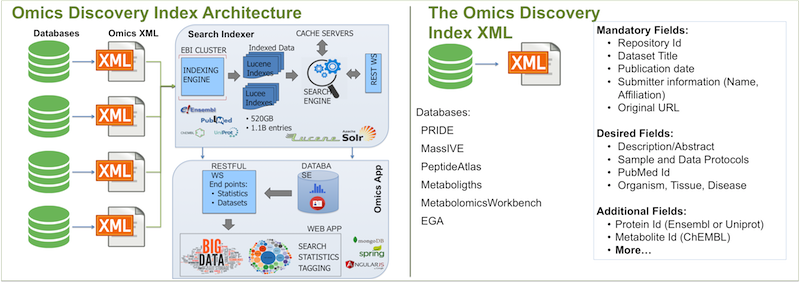
The architecture of the Omics Discovery Index started with an XML [see here](#24-omicsDI-xml) files that contains
the information from each dataset in the database. Each file is retrieved from the providers every night and if a new dataset was
added the system will add it.
Each file is indexed using the EBI Search Indexing System and the final information is exposed using web-services. The EBI Search System also
contain the index of other major databases such as Uniprot, ENSEMBL, Pubmed allowing the user cross-link the biological information with
those resources [see here](#24-omicsDI-xml) .
### 2.4. OmicsDI XML?
The [OmicsDI XML](https://github.com/BD2K-DDI/specifications/blob/master/docs/schema/README.md) is used to export every database (including all the datasets) to a common structure [Full Description](https://github.com/BD2K-DDI/specifications/blob/master/docs/schema/README.md).
The XML structure (in short) is the following:
```xml
Database Name
Database Description
Number of the release
Release Date
Number of entries
Name of the Dataset
Description of the dataset
Repository
Omics Type
```
- Cross references to other database entities is used to link for example external sources in the dataset. The **dbkey** correspond
with the entity in the database and the **dbname** correspond with the database id. Some examples:
- If the dataset is from a Human sample, the cross reference should be:
- If the proteomics experiment identified/quantified a UNIPROT id P31946, the cross reference should be:
- If the dataset was published in a scientific journal and is indexed in pubmed, the cross reference should be:
A full description of the XML Schema version 1.0 can be found [here] (https://github.com/BD2K-DDI/specifications/blob/master/docs/schema/README.md). A complete list of all databases databases for reference can be found in [this site](http://www.ebi.ac.uk/ebisearch/). Some files from Proteomics/Metabolomics Data can be found [here]().
3. Web services and Web Application
-----------------------
### 3.1. Access to the web-services
Most data in the Omics Discovery Index can be accessed programmatically using a [RESTful API](http://wwwdev.ebi.ac.uk/Tools/ddi/ws/) allowing for integration with other resources.
The API implementation is based on the Spring Rest Framework.
**Web browsable API**
- The query results returned by the API are available in JSONformat. This ensures that they can be viewed by human and
accessed programmatically by computer.
- The main RESTful API page provides a simple web-based user interface, which allows developers can familiarise
themselves with the API and get a better sense of the OmicsDI data before writing single line of code.
- Many resources are hyperlinked so that it's possible to navigate the API in the browser.
As a result, developers can familiarise themselves with the API and get a better sense of the [OmicsDI](http://wwwdev.ebi.ac.uk/Tools/ddi/ws/) data.
### 3.2. Web Application
The main goal of OmicsDI project is to have a way to search interesting datasets across omics repositories.
The main web application and web service [see here](http://wwwdev.ebi.ac.uk/Tools/ddi/) allow the user to search and navigate through the OmicsDI datasets.
The OmicsDI web application has two main different way of navigate the data: (i) using the home page navigation blocks or (ii) the search box.
4. Support
----------
### 4.1. Get involved
If you are interested in the project and add your resource to the Index please type an issue [here](https://github.com/BD2K-DDI/specifications/issues/)
### 4.2. Contact
Visit the [OmicsDI](http://wwwdev.ebi.ac.uk/Tools/ddi/) website.
Visit the [GitHub](https://github.com/BD2K-DDI/) page for the source code and the libraries.
Visit the [Specification](https://github.com/BD2K-DDI/specifications) page to make comments and requests.
5. License
----------
[Apache 2](http://www.apache.org/licenses/LICENSE-2.0)