https://github.com/openzim/gutenberg
Scraper for downloading the entire ebooks repository of project Gutenberg
https://github.com/openzim/gutenberg
gutenberg offline scraper zim
Last synced: about 1 year ago
JSON representation
Scraper for downloading the entire ebooks repository of project Gutenberg
- Host: GitHub
- URL: https://github.com/openzim/gutenberg
- Owner: openzim
- License: gpl-3.0
- Created: 2014-07-09T09:45:46.000Z (almost 12 years ago)
- Default Branch: main
- Last Pushed: 2025-03-27T23:15:03.000Z (about 1 year ago)
- Last Synced: 2025-03-28T08:06:43.697Z (about 1 year ago)
- Topics: gutenberg, offline, scraper, zim
- Language: Python
- Homepage: https://download.kiwix.org/zim/gutenberg
- Size: 125 MB
- Stars: 144
- Watchers: 15
- Forks: 45
- Open Issues: 36
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Funding: .github/FUNDING.yml
- License: LICENSE
Awesome Lists containing this project
README
# Gutenberg Offline
This scraper downloads the whole [Project
Gutenberg](https://www.gutenberg.org) library and puts it in a
[ZIM](https://openzim.org) file, a clean and user friendly format for
storing content for offline usage.
[](https://www.codefactor.io/repository/github/openzim/gutenberg)
[](https://www.gnu.org/licenses/gpl-3.0)
[](https://codecov.io/gh/openzim/gutenberg)
[](https://pypi.org/project/gutenberg2zim/)
[](https://pypi.org/project/gutenberg2zim/)
[](https://ghcr.io/openzim/gutenberg)
> [!WARNING]
> This scraper is now known to have a serious flaw. A critical bug https://github.com/openzim/gutenberg/issues/219 has been discovered which leads to incomplete archives. Work on https://github.com/openzim/gutenberg/issues/97 (complete rewrite of the scraper logic) now seems mandatory to fix these annoying problems. We however currently miss the necessary bandwidth to address these changes. Help is of course welcomed, but be warned this is going to be a significant project (at least 10 man.days to change the scraper logic so that we can fix the issue I would say, so probably the double since human is always bad at estimations).
## Getting Started
The recommended way to run the Gutenberg scraper is using Docker, as it comes with all required dependencies pre-installed.
### Running with Docker
1. **Run the scraper with Docker**:
```bash
docker run -it --rm -v $(pwd)/output:/output ghcr.io/openzim/gutenberg:latest gutenberg2zim
```
The `-v $(pwd)/output:/output` option mounts the `output` folder in your current directory to the `/output` folder inside the container (which is the working directory). This ensures that the ZIM file is saved to your local machine.
2. **Show available options**:
To view all the available options for `gutenberg2zim`, run:
```bash
docker run ghcr.io/openzim/gutenberg:latest gutenberg2zim --help
```
### Arguments
Customize the content download with the following options. For example, to download books in English or French with IDs 100 to 200 and only in PDF format:
```bash
docker run -it --rm -v $(pwd)/output:/output ghcr.io/openzim/gutenberg:latest gutenberg2zim -l en,fr -f pdf --books 100-200 --bookshelves --title-search
```
This will download books in English and French that have the Id 100 to
200 in the HTML (default) and PDF format.
The -it flags allow you to see progress.
The --rm flag removes the container after completion.
You can find the full arguments list below:
```bash
-h --help Display this help message
-y --wipe-db Empty cached book metadata
-F --force Redo step even if target already exist
-l --languages= Comma-separated list of lang codes to filter export to (preferably ISO 639-1, else ISO 639-3)
-f --formats= Comma-separated list of formats to filter export to (epub, html, pdf, all)
-e --static-folder= Use-as/Write-to this folder static HTML
-z --zim-file= Write ZIM into this file path
-t --zim-title= Set ZIM title
-n --zim-desc= Set ZIM description
-d --dl-folder= Folder to use/write-to downloaded ebooks
-u --rdf-url= Alternative rdf-files.tar.bz2 URL
-b --books= Execute the processes for specific books, separated by commas, or dashes for intervals
-c --concurrency= Number of concurrent process for processing tasks
--dlc= Number of concurrent *download* process for download (overwrites --concurrency). if server blocks high rate requests
-m --one-language-one-zim= When more than 1 language, do one zim for each language (and one with all)
--no-index Do NOT create full-text index within ZIM file
--check Check dependencies
--prepare Download rdf-files.tar.bz2
--parse Parse all RDF files and fill-up the DB
--download Download ebooks based on filters
--zim Create a ZIM file
--title-search Add field to search a book by title and directly jump to it
--bookshelves Add bookshelves
--optimization-cache= URL with credentials to S3 bucket for using as optimization cache
--use-any-optimized-version Try to use any optimized version found on optimization cache
```
## Contributing Code
Main coding guidelines are from the [openZIM Wiki](https://github.com/openzim/overview/wiki).
### Setting Up the Environment
Here we will setup everything needed to run the source version from your machine, supposing you want to modify it. If you simply want to run the tool, you should either install the PyPi package or use the Docker image. Docker image can also be used for development but needs a bit of tweaking for live reload of your code modifications.
### Install the dependencies
First, ensure you use the proper Python version, inline with the requirement of `pyproject.toml` (you might for instance use `pyenv` to manage multiple Python versions in parallel).
You then need to install the various tools/libraries needed by the scraper.
The setup is divided into two categories: one for simply running the scraper and another for setting up a development environment for contributing and making improvements
**For Users Running the Scraper**:
### GNU/Linux
```
sudo apt update && sudo apt install -y python3-pip p7zip-full zip zim-tools curl jpegoptim pngquant
```
### Fedora
```
sudo dnf install -y python3-pip jpegoptim pngquant p7zip curl zip zim-tools
```
### Arch linux
```
sudo pacman -S python-pip libxml2 jpegoptim pngquant p7zip curl zip zim-tools
```
#### macOS
```
brew install jpegoptim pngquant p7zip curl zip zim-tools
```
**For Developers Contributing & Modifying**;
#### GNU/Linux
```
sudo apt update && sudo apt install -y python3-pip libxml2-dev libxslt-dev jpegoptim pngquant p7zip-full curl zip zim-tools
```
### Fedora
```
sudo dnf install -y python3-pip libxml2-devel libxslt-devel jpegoptim pngquant p7zip curl zip zim-tools
```
### Arch linux
```
sudo pacman -S python-pip libxml2 libxslt jpegoptim pngquant p7zip curl zip zim-tools
```
#### macOS
```
brew install libxml2 libxslt jpegoptim pngquant p7zip curl zip zim-tools
```
### Setup the package
First, clone this repository.
```bash
git clone git@github.com:openzim/gutenberg.git
cd gutenberg
```
If you do not already have it on your system, install `hatch` to build the software and manage virtual environments (you might be interested by our detailed [Developer Setup](https://github.com/openzim/_python-bootstrap/blob/main/docs/Developer-Setup.md) as well).
```bash
pip3 install hatch
```
Start a hatch shell: this will install software including dependencies in an isolated virtual environment.
```bash
hatch shell
```
That's it. You can now run `gutenberg2zim` from your terminal.
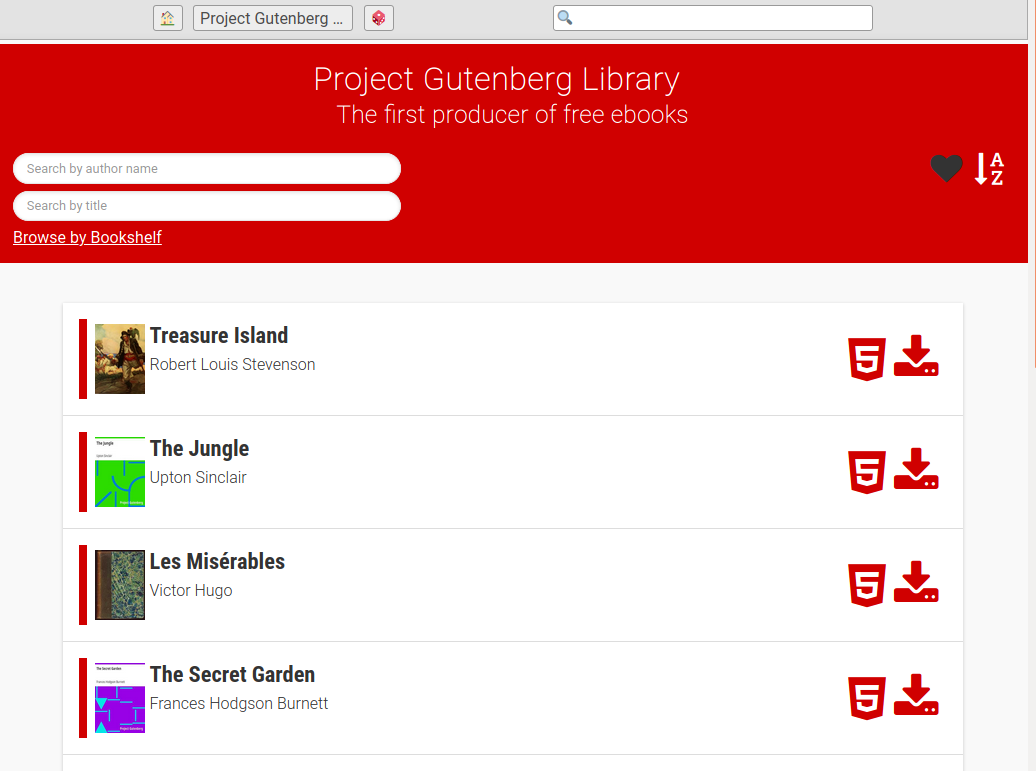
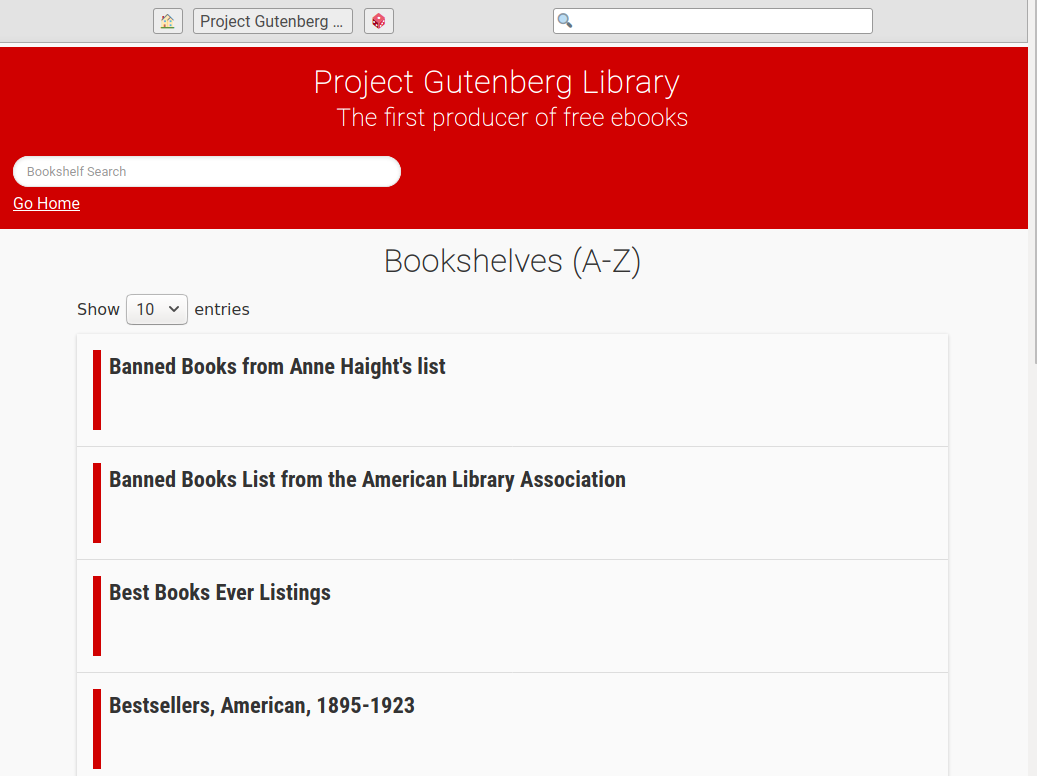
## Screenshots
## License
[GPLv3](https://www.gnu.org/licenses/gpl-3.0) or later, see
[LICENSE](LICENSE) for more details.